cuda线程模型
发布时间:2024年01月04日
#include "../common/common.h"
#include <cuda_runtime.h>
#include <stdio.h>
/*
* Display the dimensionality of a thread block and grid from the host and
* device.
*/
__global__ void checkIndex()
{
printf( "gridDim:(%d, %d, %d) blockDim:(%d, %d, %d) threadIdx:(%d, %d, %d) blockIdx:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, threadIdx.x, threadIdx.y, threadIdx.z, blockIdx.x, blockIdx.y, blockIdx.z);
// printf("threadIdx:(%d, %d, %d)\n", threadIdx.x, threadIdx.y, threadIdx.z);
// printf("blockIdx:(%d, %d, %d)\n", blockIdx.x, blockIdx.y, blockIdx.z);
// printf("blockDim:(%d, %d, %d)\n", blockDim.x, blockDim.y, blockDim.z);
// printf("gridDim:(%d, %d, %d)\n", gridDim.x, gridDim.y, gridDim.z);
}
int main(int argc, char **argv)
{
// define total data element
int nElem = 6;
// define grid and block structure
dim3 block(3);
dim3 grid((nElem + block.x - 1) / block.x);
// check grid and block dimension from host side
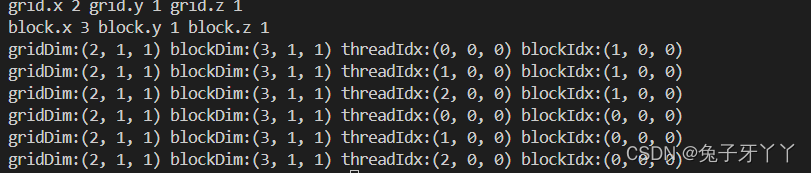
printf("grid.x %d grid.y %d grid.z %d\n", grid.x, grid.y, grid.z);
printf("block.x %d block.y %d block.z %d\n", block.x, block.y, block.z);
// check grid and block dimension from device side
checkIndex<<<grid, block>>>();
// reset device before you leave
CHECK(cudaDeviceReset());
return(0);
}
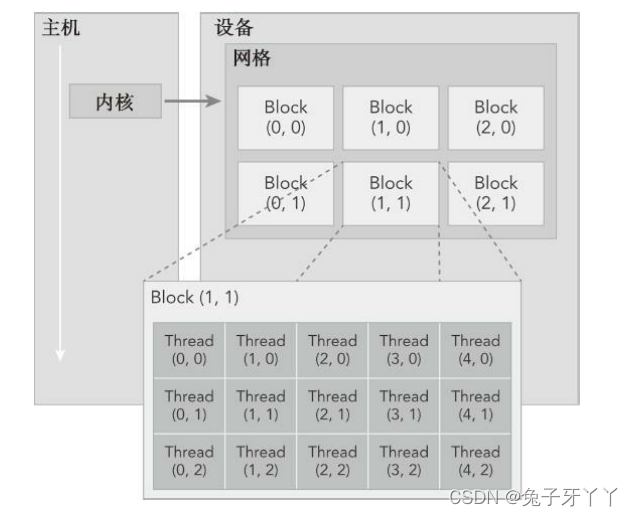
线程模型
当核函数在主机端启动时,它的执行会移动到设备上,此时设备中会产生大量的线程
并且每个线程都执行由核函数指定的语句。了解如何组织线程是CUDA编程的一个关键部
分。CUDA明确了线程层次抽象的概念以便于你组织线程。这是一个两层的线程层次结
构,由线程块和线程块网格构成,如图2-5所示。
内存管理
由一个内核启动所产生的所有线程统称为一个网格。同一网格中的所有线程共享相同
的全局内存空间。一个网格由多个线程块构成,一个线程块包含一组线程,同一线程块内
的线程协作可以通过以下方式来实现。

CUDA可以组织三维的网格和块。图2-5展示了一个线程层次结构的示例,其结构是
一个包含二维块的二维网格。网格和块的维度由下列两个内置变量指定。
·blockDim(线程块的维度,用每个线程块中的线程数来表示)
·gridDim(线程格的维度,用每个线程格中的线程数来表示)
它们是dim3类型的变量,是基于uint3定义的整数型向量,用来表示维度。当定义一个
dim3类型的变量时,所有未指定的元素都被初始化为1。dim3类型变量中的每个组件可以
通过它的x、y、z字段获得。如下所示。
gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z




文章来源:https://blog.csdn.net/qq_43570025/article/details/135374717
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决达梦数据库服务启动失败,错误 2: 系统找不到指定的文件
- 使用插件管理 GBASE南大通用 数据库
- git stash 命令详解
- 网页版收银系统与应用版相比有哪些优势
- 知识笔记(九十六)———在vue中使用echarts
- 【FPGA/verilog -入门学习9】verilog基于查找表的8位格雷码转换
- Spring Boot Banner 教程:自定义启动画面的艺术
- 数据安全传输基础设施平台(一)
- python图像二值化处理
- 【GNSS】LAMBDA 模糊度搜索 MATLAB 工具箱使用笔记