克服大模型(LLM)部署障碍,全面理解LLM当前状态
近日,CMU Catalyst 团队推出了一篇关于高效 LLM 推理的综述,覆盖了 300 余篇相关论文,从 MLSys 的研究视角介绍了算法创新和系统优化两个方面的相关进展。
在人工智能(AI)的快速发展背景下,大语言模型(LLMs)凭借其在语言相关任务上的杰出表现,已成为 AI 领域的重要推动力。然而,随着这些模型在各种应用中的普及,它们的复杂性和规模也为其部署和服务带来了前所未有的挑战。LLM 部署和服务面临着密集的计算强度和巨大的内存消耗,特别是在要求低延迟和高吞吐量的场景中,如何提高 LLM 服务效率,降低其部署成本,已经成为了当前 AI 和系统领域亟需解决的问题。
来自卡内基梅隆大学的 Catalyst 团队在他们的最新综述论文中,从机器学习系统(MLSys)的研究视角出发,详细分析了从前沿的 LLM 推理算法到系统的革命性变革,以应对这些挑战。该综述旨在提供对高效 LLM 服务的当前状态和未来方向的全面理解,为研究者和实践者提供了宝贵的洞见,帮助他们克服有效 LLM 部署的障碍,从而重塑 AI 的未来。

论文链接:https://arxiv.org/abs/2312.15234
综述概览
该综述系统地审视了现有 LLM 推理技术,覆盖了 300 余篇相关论文,从算法创新和系统优化两个方面展开介绍。论文以此为基础,对现有工作设计了一套清晰且详尽的分类法,突出了各种方法的优势和局限性,逐类别搜集整理并介绍了每种方法的相关论文。除此之外,论文还对当前的主流?LLM 推理框架在系统设计与实现方面进行了深入的对比和分析。最后,作者对未来如何继续提高 LLM 推理效率进行了展望,在技术层面提出了六大潜在发展方向。
分类法
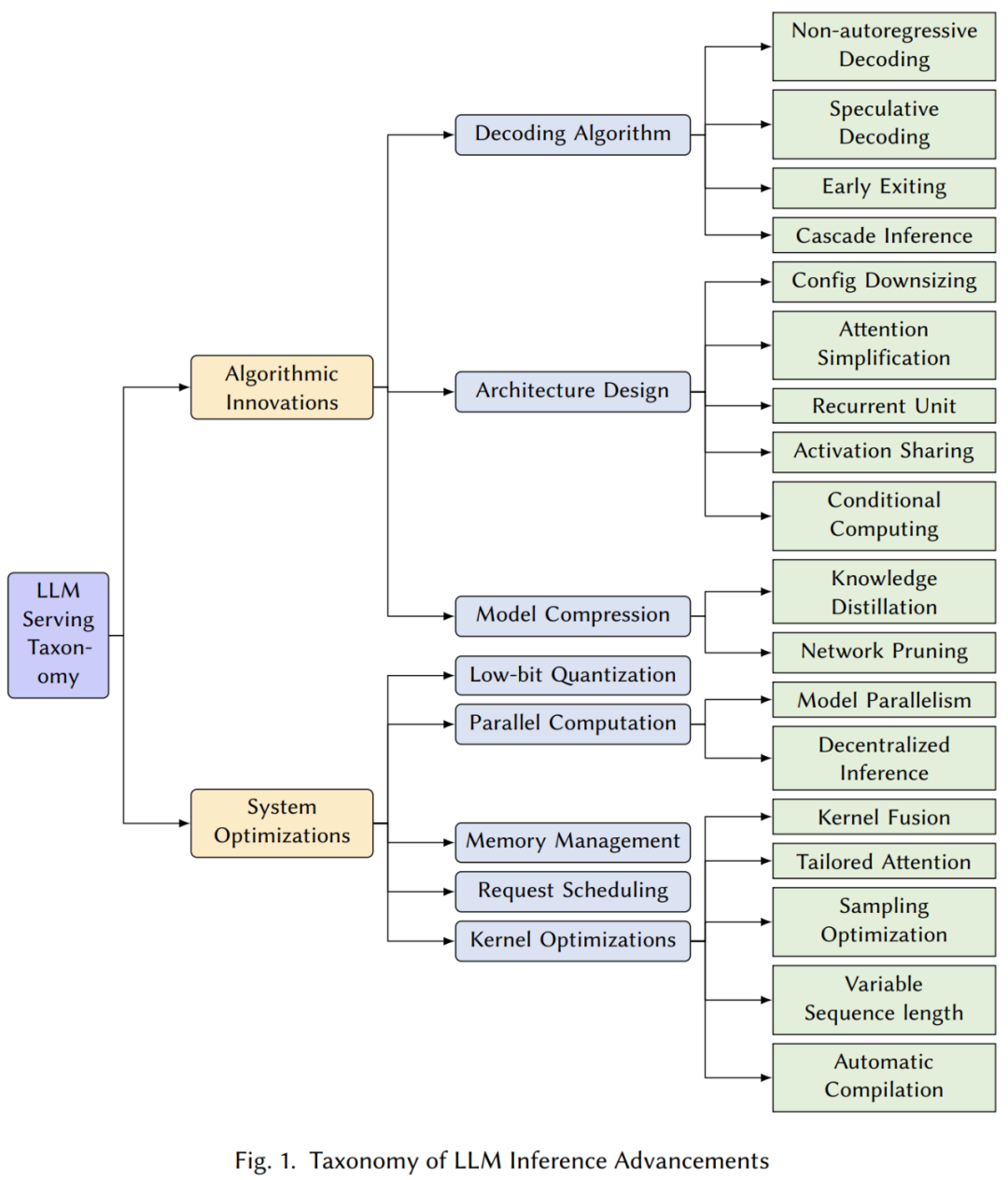
算法创新
这一节对提出的各种算法和技术进行了全面分析,旨在改进大规模 Transformer 模型推理的原生性能缺陷,包括解码算法、架构设计、和模型压缩等等。
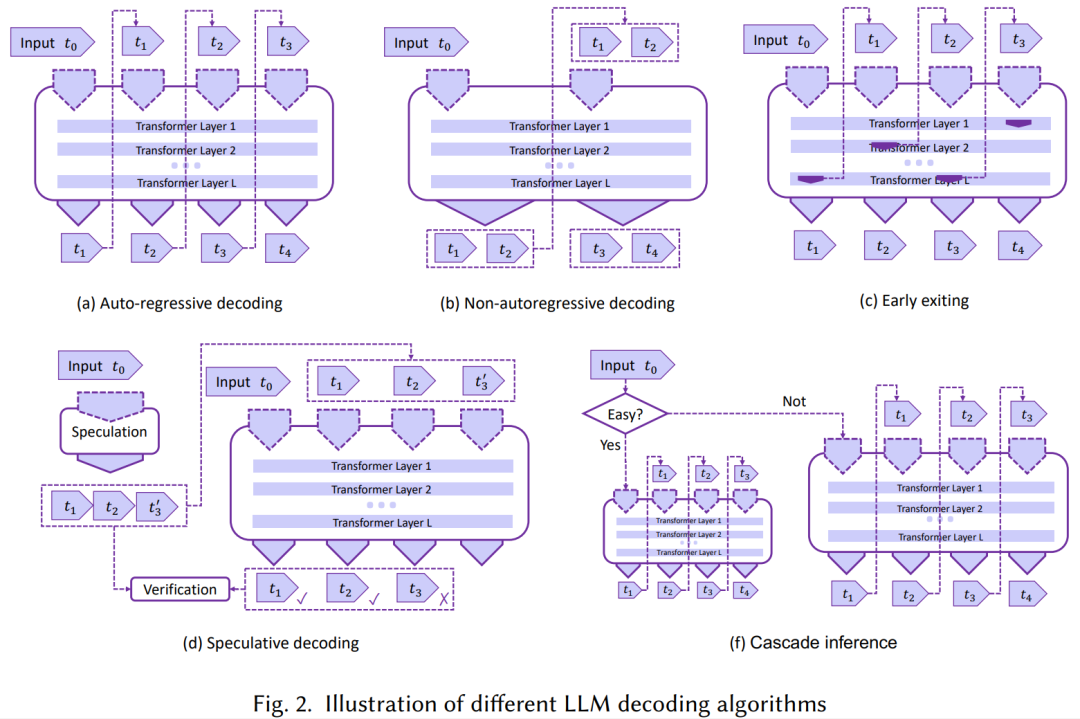
解码算法:在这一部分中,我们回顾了在图 2 中展示的几种 LLMs 推理优化过程的新颖解码算法。这些算法旨在减少计算复杂度,并提高语言模型推理在生成任务中的总体效率,包括:
-
非自回归解码:现有 LLMs 的一个主要限制是默认的自回归解码机制,它逐个顺序生成输出 token。为解决这一问题,一种代表性的工作方向是非自回归解码 [97, 104, 108,271],即放弃自回归生成范式,打破单词依赖并假设一定程度的条件独立性,并行解码输出 token。然而,尽管这类方法解码速度有所提高,但大多数非自回归方法的输出质量仍不如自回归方法可靠。
-
投机式推理:另一类工作是通过投机执行思想 [47] 实现并行解码。自回归 LLM 推理过程中的每个解码步骤都可以被视为带有条件分支的程序执行语句,即决定接下来生成哪个 token。投机式推理 [51, 155] 先使用较小的草稿模型进行多步解码预测,然后让 LLM 同时验证这些预测以实现加速。然而,将投机解码应用于 LLMs 时仍然存在一些实际挑战,例如,如何使解码预测足够轻量且准确,以及如何借助 LLMs 实现高效的并行验证。SpecInfer [177] 首次引入基于 tree-based speculative decoding 和 tree attention,并提出了一个低延迟 LLM 服务系统实现,该机制也被后续多个工作 [48, 118, 168, 185, 229, 236, 274, 310] 直接采用。
-
提前退出:这类方法主要利用 LLMs 的深层多层结构,在中间层提前推出推理,中间层输出可以通过分类器转化成输出的 token,从而降低推理开销 [117, 147, 163, 167, 234, 272, 282, 291, 308],它们也被称为自适应计算 [68, 219]。
-
级联推理:这类方法级联了多个不同规模的 LLM 模型,用于分别处理不同复杂度的推理请求,代表性工作包括 CascadeBERT [157] 和 FrugalGPT [53]。
架构设计:
-
配置缩小:直接缩小模型配置。
-
注意力简化:最近出现了很多研究工作,它们主要是将之前的长序列高效注意力机制 [240] 应用在 LLM 上,以缩短上下文,减少 KV 缓存,以及注意力复杂度,同时略微降低解码质量(如滑动窗口 [129, 299]、哈希 [198]、dilated [74]、动态选择等等)。表 1 中总结了一些近期的热门方法和之前的工作之间的对应关系。

-
激活共享:这类方法主要是通过共享 attention 计算的中间激活来降低推理内存开销,代表性工作包括 MQA [220] 和 GQA [32]。
-
条件计算:这类方法主要是指稀疏专家混合模型(Sparse MoE),比如最近大火的 Mistrial 7Bx8 模型就属于此类。
-
循环单元:尽管 Transformer 已经替代了 RNN 模型,但考虑到注意力机制的二次复杂性,人们始终未曾放弃将 recurrent unit 机制重新引入 LLM 的尝试,比如 RWKV [200]、RetNet [235],以及状态空间模型 [91, 102, 103, 176] 等等。
模型压缩:
-
知识蒸馏:这类方法以大型的教师模型为监督,训练一个小型的学生模型。大多数之前的方法都在探索白盒蒸馏 [106, 133, 214, 233, 255],需要访问整个教师模型的参数。由于基于 API 的 LLM 服务(如 ChatGPT)的出现,一些黑盒蒸馏模型吸引了很多关注 [238,59, 273, 201, 313],这些模型通常具有更少的模型参数,与原始 LLMs(如 GPT-4 [195])相比,在各种下游任务上表现出了相当的性能。
-
网络剪枝:过去几年中,网络剪枝方法 [180, 215, 215] 已被广泛研究,但并非所有方法都可以直接应用于 LLMs,需要考虑重新训练可能带来的过高计算成本,以及评估剪枝是否可以在底层系统实现上取得效率提升。大致上可以分为结构化剪枝 [80, 149, 174, 216, 172] 和半结构化稀疏化 [40, 87, 232, 251, 276] 等。
系统优化
本节研究 LLM 推理系统优化技术,以加速 LLM 推理,而不改变 LLM 计算语义。这一工作的目标是通过改进用于大型语言模型推理的底层系统和框架来提高系统效率,包括低比特量化、并行计算、内存管理、请求调度、和内核优化等等,详细内容可以参见论文原文。
软件框架
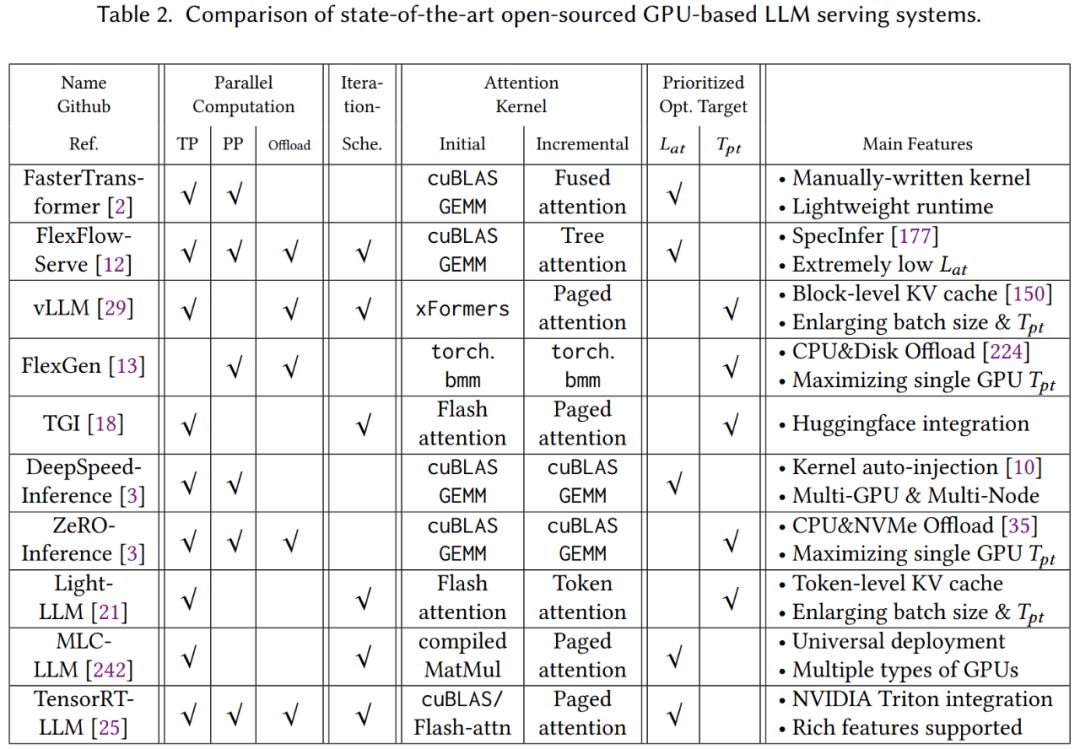
论文还对一些目前最先进的基于 GPU 的开源 LLM 推理系统进行了深入的分析,并从多个方面总结了它们在设计与实现伤的差异。
未来方向
-
专用硬件加速器的发展:生成型 LLM 服务效率的显著提升可能在很大程度上依赖于专用硬件加速器的发展和提升,尤其是软硬协同设计方法。例如,让内存单元更加接近处理单元,或是针对 LLM 算法数据流优化芯片架构,这些硬件优化可以在很大程度上为 LLM 推理在软件层面带来便利和机会。
-
高效有效的解码算法:开发更高效的解码算法可以显著提高服务效率。受对实时应用更快生成速度的需求驱动,一个有前途的方向是广义的投机式推理(generalized speculative inference),不仅会带来显著加速,同时保持相同的生成质量。正如 SpecInfer 中所指出的,广义的投机式推理中,用于生成草稿 token 的小模型可以被替换为任何快速的 token 生成方法,比如自定义函数、召回方法、甚至早停机制和非自回归解码等等。
-
长上下文 / 序列场景优化:随着应用场景变得更加复杂,处理更长的上下文或序列的需求不断增长。服务长序列负载的 LLM 需要解决算法和系统两方面的挑战。在算法方面,它们依然面临长度泛化失效问题,甚至可能出现 “loss in the middle” 的情况。目前的解法主要是通过召回增强、序列压缩和缓存来尽可能缩短序列长度并保存相关信息。
-
探索替代基础架构:尽管 Transformer 模型和自注意力机制目前主导着 LLM 领域,但探索替代架构是未来研究的一个有前景的方向。例如,一些最新研究探索了无注意力方法,使用纯 MLP(多层感知机)架构来替代注意力机制,可能会改变目前 LLM 推理优化的格局。
-
在复杂环境中的部署探索:随着 LLM 应用的扩展,探索并优化它们在各种复杂环境中的部署成为一个关键的未来方向。这一探索不仅限于传统的基于云的部署,还包括边缘计算、混合计算(cloud+edge)、去中心化计算以及廉价的可抢占资源等。
-
特定需求的自动适应:应用特定需求的多样性创造了一系列创新的 LLM 服务优化机会,例如模型微调(parameter-efficient fine-tuning)、向量数据库检索、多模态负载等等。这些独特的挑战也要求将 LLM 服务技术自动且顺利地集成到现有 IT 基础设施中,将优化空间扩展到整个 LLM 生命周期。
总结
总的来说,该综述不仅是对当前 LLM 服务优化研究的全面概述,也为未来在这一领域的探索和发展指明了方向。通过深入了解这些先进的解决方案,研究者和实践者可以更好地理解和应对在实际应用中部署大型语言模型时面临的挑战。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- redis系列:01 数据类型及操作
- Intel开发环境Quartus、Eclipse与WSL的安装
- 2024-2031年全球生物质成型燃料行业经营模式及竞争趋势预测报告
- 【JaveWeb教程】(6)Web前端基础:一篇文章教你轻松搞定网络异步请求Ajax与Axios,附详细示例代码
- 设计模式-代理模式
- Adobe Photoshop AI正版来了,手把手教你注册
- 【SpringBoot】org.junit.runners.model.InvalidTestClassError 单元测试类报错(已解决)
- 深入了解Spring MVC工作流程
- AI新工具(20240119):Coach 微软推出独立 AI 工具辅助提高学习者阅读能力,Tweetify长文转换
- spring boot中使用atomikos实现分布式事务