切割wav文件至小段wav保存
发布时间:2024年01月24日
audition手动切割
1.载入wav文件

2.点击移到下一个按钮??
3.然后选中截取的文件长短如图示
4.点击键盘快捷键大写M,然后会在左侧下面出现列表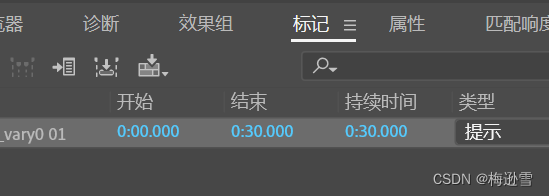
5. 重复3和4步骤,得到一些列标记短音频
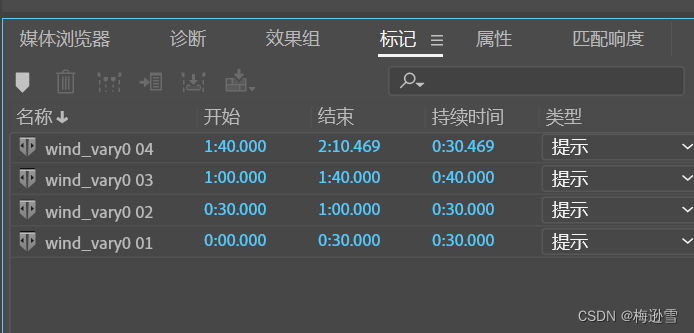
6. 全选短音频,点击下载按钮![]()

7.编辑输出文件名字

8.点击导出,就可以得到busnoise01.wav,?busnoise02.wav,?busnoise03.wav, ......
一系列单独文件。注意上面第一行,文件名,小方格不选。否则名字会有之前留下的字。
——————————————————
代码切割,(还没跑过,不知道是否准确)
将wav格式的语音文件切成20秒一个的小文件 python
wav?语音?文件?python
下面是一个简单的Python代码示例,可以将一个WAV格式的语音文件切成20秒一个的小文件:
import os
import wave
def split_wav(filename, chunk_size=20):
"""
将WAV格式的语音文件切成20秒一个的小文件
:param filename: 输入文件路径
:param chunk_size: 切割大小,单位为秒
"""
with wave.open(filename, 'rb') as wav_file:
framerate = wav_file.getframerate()
chunk_size = chunk_size * framerate # 计算要切割的采样点数
frames = wav_file.readframes(-1)
n_chunks = len(frames) // chunk_size
for i in range(n_chunks):
chunk = frames[i*chunk_size:(i+1)*chunk_size]
outfile = os.path.splitext(filename)[0] + f'_{i+1}.wav'
with wave.open(outfile, 'wb') as chunk_wav:
chunk_wav.setnchannels(wav_file.getnchannels())
chunk_wav.setsampwidth(wav_file.getsampwidth())
chunk_wav.setframerate(framerate)
chunk_wav.writeframes(chunk)
# 处理最后一个不足规定大小的chunk
if len(frames) % chunk_size > 0:
chunk = frames[n_chunks*chunk_size:]
outfile = os.path.splitext(filename)[0] + f'_{n_chunks+1}.wav'
with wave.open(outfile, 'wb') as chunk_wav:
chunk_wav.setnchannels(wav_file.getnchannels())
chunk_wav.setsampwidth(wav_file.getsampwidth())
chunk_wav.setframerate(framerate)
chunk_wav.writeframes(chunk)
if __name__ == '__main__':
split_wav('input.wav', 20)
该代码使用Python内置的wave模块读取WAV文件,并按照指定的块大小(20秒)切割成多个小文件,文件名按照原文件名加上序号。其中,frames是WAV文件的采样点,根据采样点数计算出要切割成多少块。实际进行切割时,使用了Python的切片操作。切割后的每一块都写入新的WAV文件中。最后,处理最后一个不足规定大小的chunk。
请注意,该代码没有考虑WAV文件的采样位深和声道数等因素。如果需要处理非标准的WAV文件,可能需要进行调整。
文章来源:https://blog.csdn.net/qq_35243382/article/details/135815498
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EasyExcel解决导出字符串变成数字问题
- 力扣刷题记录(14)LeetCode:763、56、738
- leecode题解Golang版本:LCR 015. 找到字符串中所有字母异位词
- 【2023华为od-C卷-第三题-数据单元的变量替换】(JavaScript&Java&Python&C++)
- 安科瑞ACX10S-YHW新能源智能电瓶车充电桩 户外充电桩 ——安科瑞 顾烊宇
- 深入理解Java虚拟机---内存分配
- Tomcat 安装和运行教程
- 云渲染如何使用?其实很简单,只需3步就搞定了!
- 病情聊天机器人,利用Neo4j图数据库和Elasticsearch全文搜索引擎相结合
- 大模型中的Chat Completion模型和参数