BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】
发布时间:2024年01月04日
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。
本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras。
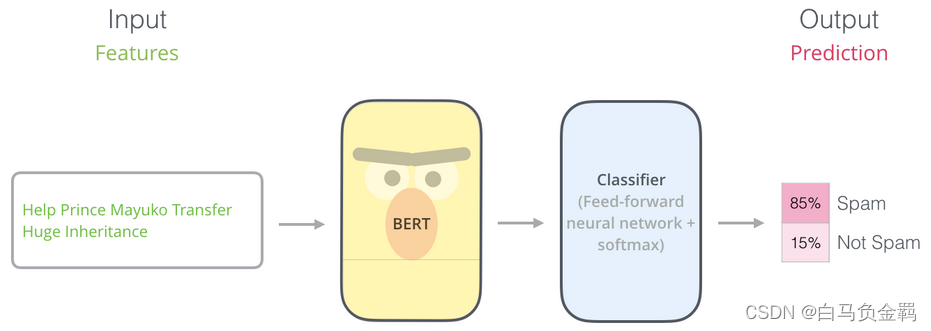
一、数据准备
首先,载入必要的packages/libraries。
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
import numpy as np
import pandas as pd
import seaborn as sn
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt接下来,导入数据,这是一个CSV文件,里面包含了很多邮件文本(参见【1】)。
df = pd.read_csv("spam.csv")
df.head(5)这里我们输出前5条数据作为演示:
文章来源:https://blog.csdn.net/baimafujinji/article/details/135376830
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- json for modern c++
- TYPE-C接口取电芯片介绍和应用场景
- 【笔记】Spring的事务是如何回滚的/Spring的事务管理是如何实现的
- 设置 Visual Studio 字体/背景/行号 - C语言零基础入门教程
- Python中生成JSON数据的强大工具
- Android开发中pcm格式的音频转换为wav格式之一
- 【Leetcode 36】有效数独 —— 哈希表|矩阵
- Datawhale 12月组队学习 leetcode基础 day3 递归
- Halcon自带图片素材保存的位置
- 数据结构OJ实验14-哈希查找