[全连接神经网络]Transformer代餐,用MLP构建图像处理网络
一、MLP-Mixer
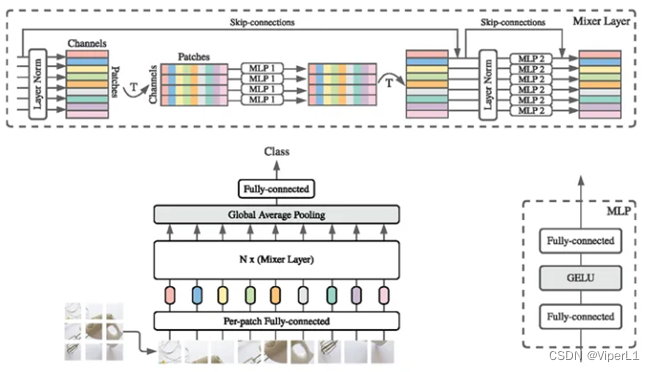
????????使用纯MLP处理图像信息,其原理类似vit,将图片进行分块(patch)后展平(fallten),然后输入到MLP中。理论上MLP等价于1x1卷积,但实际上1x1卷积仅能结合通道信息而不能结合空间信息。根据结合的信息不同分为channel-mixing MLPs和token-mixing MLPs。
?????? 总体结构如下图,基本上可以视为以mlp实现的vit。
?二、RepMLP
????????传统卷积仅能处理局部领域信息,不具备捕获长程依赖的能力,其特性被称为归纳偏置(inductive bias)或局部先验性质(local prior)。而Transformer虽然可以使用自注意力捕获长程依赖,却无法有效获取局部先验信息。全连接(FC)结构与Transformer类似,可以捕获长程依赖(每个输入和输出都有连接)但是缺乏局部先验性质。而RepVGG则是通过将MLP和CNN的优点结合在一起实现高质量的特征提取。其核心是结构重参数技术(structural reparameterization technique)。
????????训练时的RepMLP与预测时截然不同。训练时,每一层都会添加平行的卷积+BN分支,而预测时会将卷积分支等效为MLP分支。

????????训练阶段由三部分组成:Global Perceptron、Partition Perceptron、Local Perceptron。其中Global Perceptron相当于vit中的patch-embed,通过将特征图分成7x7的小块来节省运算开销。但是这种切割会让每个patch失去位置信息,所以使用两个FC为patch添加位置信息;其操作如下:①使用avgpool将每个分区池化得到一个像素;②送入带一个BN的两层MLP中;将结果reshape后与原特征图相加,流程如下:

????????Partition Perceptron层包含FC和BN,由Global Perceptron切割后的特征图还会经过一组1x1的组卷积进一步降低参数量,然后由FC3进行处理后最终得到输出特征图。
?????? Local Perceptron类似一个ASPP空洞卷积组,可以丰富特征图的空间信息,得到的结果与Partition Perceptron的特征图相加即可得到完整的输出。其结构如下:

三、ResMLP

????????ResMLP仅使用Linear Layers和GELU,不适用任何正则化层(Batch Norm)和自注意力(self-attention)。每个Block由sublayer+feedforward sublayer组成。
?????? Sublayer由线性层和残差链接组成,即上图左边的部分;而feedforward sublayer则是上图右边的部分,由两个线性层和残差链接组成,中间使用GELU作为激活。其可以描述为下面公式:
![]()
![]()
![]()
????????其中sublayer中包含两次转置操作,其原因是要将channel维度换道最后一维以进行融合,融合过后再换回来。
?????? ResMLP Block分为两种形式(一种全尺寸和一种轻量化结构),结构如图,全尺寸ResMLP效果略好于ResNet,轻量化Block效果持平ResNet。

?四、gMLP
????????gMLP的g代表gating(闸门),论文提出在视觉领域自注意力机制并不是那么重要,gMLP的性能可以与基于Transformer的DeiT模型相当。gMLP的Block结构如下图所示:

????????gMLP为同向网络(具有相同结构),就其模块结构而言,Channel Projection可以获取通道信息,Spatial Gating Unit可以获取空间信息。
五、CycleMLP
????????CycleMLP的特点是构建基于密集预测的MLP架构。传统的诸如MLP-Mixer,ResMLP,gMLP存在一些问题:①均为同向性网络,不会产生金字塔结构,也不会产生多尺度特征图;②spatial FC的计算复杂度与尺寸呈平方关系,难以训练高分图。
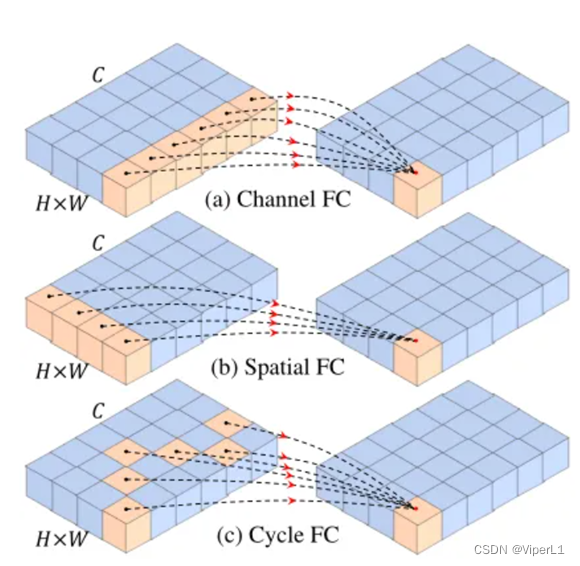
??????? 如上图所示,Cycle FC层类似于Spatial FC,且棋遵循金字塔结构(即随着层数的加深,特征分辨率逐渐减少,也就是token不断减少)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Docker Compose介绍及部署
- Linux域名IP映射
- Human Perception of Visual Information (2)
- 2024年华数杯国际赛A题赛题
- JOSEF约瑟 JGL-15静态带时限过流继电器 柜内安装,板前接线
- 学习笔记——C++中的循环结构 while语句
- 《网络是怎样连接的》2.1节图表(自用)
- cfa一级考生复习经验分享系列(十四)
- 8.2 open3d处理点云详解(python)
- innovus:ccopt_design流程