斯坦福开发WikiChat:几乎不会产生幻觉的模型
简介
像ChatGPT和GPT-4这样的大型语言模型(LLM)聊天机器人经常会出现错误,特别是当你要求的信息是最新的(“告诉我关于2024年超级碗的事情。”)或者涉及较不流行的主题时(“推荐一些你喜欢的外国导演的好电影。”)。WikiChat使用维基百科和以下的7阶段流程来确保其回答是基于事实的。WikiChat基于英文维基百科信息。当它需要回答问题时,会先在维基百科上找到相关的、准确的信息,然后再给出回答,保证给出的回答既有用又可靠。在混合人类和LLM的评估中,WikiChat达到了97.3%的事实准确性,同时也普遍高于其他模型。它几乎不会产生幻觉,并且具有高对话性和低延迟。 主要特点
主要特点
- 高度准确:因为它直接依赖于维基百科这个权威且更新频繁的信息源,所以WikiChat在提供事实和数据时非常准确。
- 减少“幻觉”:LLM在谈论最新事件或不太流行的话题时容易产生错误信息。WikiChat通过结合维基百科数据,减少了这种信息幻觉的发生。
- 对话性强:尽管重视准确性,WikiChat仍然能够维持流畅、自然的对话风格。
- 适应性强:它可以适应各种类型的查询和对话场景。
- 高效性能:通过优化,WikiChat在回答问题时更快速,同时减少了运行成本。
工作原理
WikiChat利用模型蒸馏技术,将基于GPT-4的模型转化为更小、更高效的LLaMA模型(70亿参数),以提高响应速度和降低成本。WikiChat的工作流程涉及多个阶段,包括检索、摘要、生成、事实核查等,每个阶段都经过精心设计以保证整体对话的准确性和流畅性。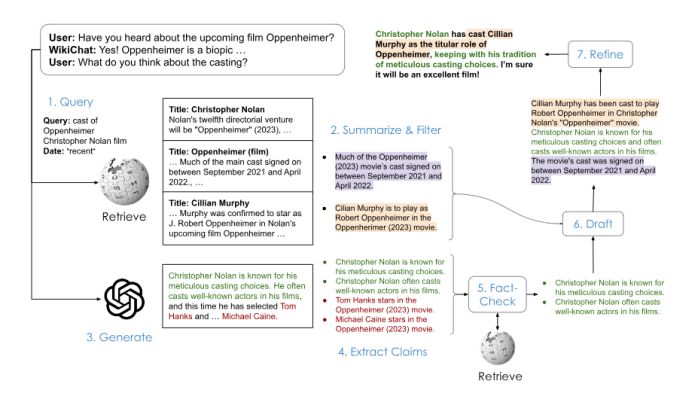 1、检索信息: 当与用户进行对话时,WikiChat首先判断是否需要访问外部信息。例如,当用户提出具体问题或需要更全面的回答时。WikiChat生成一个搜索查询,以捕捉用户的兴趣,并根据这个查询从知识库(如维基百科)中检索相关信息。2、摘要和过滤: 检索到的信息可能包含相关和不相关的部分。WikiChat会提取相关部分,并将其摘要成要点,同时过滤掉无关内容。3、生成LLM响应: 接下来,使用大型语言模型(如GPT-4)生成对话历史的回应。这一步骤生成的内容通常既有趣又相关,但它本质上是不可靠的,因为它可能包含未经验证的或错误的信息。4、事实核查: WikiChat将LLM的回应分解为多个声明,并对每个声明进行事实核查。它使用检索系统从知识库中获取每个声明的证据,并基于这些证据对声明进行验证。只有那些被证据支持的声明才会被保留。5、形成回应: 最后,WikiChat使用经过筛选和验证的信息来形成一个吸引人的回应。这个过程分为两个步骤:首先生成草稿回应,然后根据相关性、自然性、非重复性和时间正确性对其进行优化和改进。
1、检索信息: 当与用户进行对话时,WikiChat首先判断是否需要访问外部信息。例如,当用户提出具体问题或需要更全面的回答时。WikiChat生成一个搜索查询,以捕捉用户的兴趣,并根据这个查询从知识库(如维基百科)中检索相关信息。2、摘要和过滤: 检索到的信息可能包含相关和不相关的部分。WikiChat会提取相关部分,并将其摘要成要点,同时过滤掉无关内容。3、生成LLM响应: 接下来,使用大型语言模型(如GPT-4)生成对话历史的回应。这一步骤生成的内容通常既有趣又相关,但它本质上是不可靠的,因为它可能包含未经验证的或错误的信息。4、事实核查: WikiChat将LLM的回应分解为多个声明,并对每个声明进行事实核查。它使用检索系统从知识库中获取每个声明的证据,并基于这些证据对声明进行验证。只有那些被证据支持的声明才会被保留。5、形成回应: 最后,WikiChat使用经过筛选和验证的信息来形成一个吸引人的回应。这个过程分为两个步骤:首先生成草稿回应,然后根据相关性、自然性、非重复性和时间正确性对其进行优化和改进。
在混合人类和大语言模型评估方法下的表现
1、高事实准确性:在模拟对话中,WikiChat的最佳系统达到了97.3%的事实准确性。这意味着它在回答问题或提供信息时,几乎所有的回应都是基于事实和真实数据的。
2、与GPT-4的比较:当涉及到头部知识(即常见或流行的主题)、尾部知识(即不常见或较少被讨论的主题)和最近的知识(即最新发生的事件或信息)时,WikiChat相比于GPT-4在事实准确性上分别提高了3.9%,38.6%和51.0%。这表明WikiChat在处理不同类型的信息时都有显著的改进,特别是在处理较少讨论的主题和最新信息方面。3、与基于检索的聊天机器人的比较:与之前最先进的基于检索的聊天机器人相比,WikiChat不仅在事实准确性上表现更好,而且在提供信息量和吸引用户参与方面也表现得更加出色。这意味着WikiChat能够提供更丰富、更有趣的对话体验。
总结
总体来说,WikiChat在处理复杂、动态和多样化的信息需求时的优越性能,尤其是在准确性和用户参与度方面的显著提升。
项目地址:https://github.com/stanford-oval/WikiChat
在线体验:https://wikichat.genie.stanford.edu
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 09-Python服务链路追踪案例
- 在数据中查找峰值
- 求职招聘小程序平台运营版系统源码 全开源源代码 附带完整的安装与部署教程
- LC106. 从中序与后序遍历序列构造二叉树
- 米哈游游戏构建开发工程师面经
- k8s图形化管理工具之rancher
- MySQL语法练习-DML语法练习
- java面试题-mysql关键字select、from、where等执行的顺序
- Unity寻路A星算法
- 【Sentinel 控制台无应用显示-如何排查】