如何使用 C++ 开发 Redis 模块
在本文中,我将总结 Tair 在使用 C++ 开发 Redis 模块时遇到的一些问题,并将其提炼为最佳实践。目的是为 Redis 模块的用户和开发人员提供帮助。其中一些最佳实践也可以应用于 C 编程语言和其他编程语言。
介绍
从 Redis 5.0 开始,支持模块插件来增强 Redis 的能力。这些插件允许开发新的数据结构,实现命令侦听和过滤,以及扩展新的网络服务。可以肯定地说,模块的引入大大提高了 Redis 的灵活性,降低了 Redis 开发的复杂性。
Redis社区中涌现出众多模块,覆盖各个领域,丰富了生态。这些模块中的大多数都是使用 C 编程语言开发的。但是,Redis 模块也支持使用 C++ 和 Rust 等其他语言进行开发。本文旨在总结 Tair 在使用 C++ 开发 Redis 模块时遇到的问题,并将其作为最佳实践进行介绍。其目的是为 Redis 模块的用户和开发人员提供帮助,其中一些最佳实践也适用于 C 和其他语言。
Redis 模块的工作原理
Redis内核是用C语言开发的,自然而然地就引出了在C编程语言环境下开发插件时要考虑动态链接库。虽然 Redis 确实使用动态链接库,但有几个关键点需要注意:
- Redis 内核公开并导出各种 API 供模块使用。这些 API 包括 Redis 核心数据库结构的内存分配接口和操作接口。请务必了解,这些 API 是由 Redis 本身解析和绑定的,而不是由动态连接器解析和绑定的。
- Redis 内核使用 dlopen 显式加载模块,而不是依赖于动态链接器的隐式加载。这意味着当模块需要实现特定接口时,Redis 会自动调用模块的入口函数来初始化 API、注册数据结构以及执行其他必要的功能。
装载
Redis内核中模块加载的逻辑如下:
int moduleLoad(const char *path, void **module_argv, int module_argc, int is_loadex) {
int (*onload)(void *, void **, int);
void *handle;
struct stat st;
if (stat(path, &st) == 0) {
/* This check is best effort */
if (!(st.st_mode & (S_IXUSR | S_IXGRP | S_IXOTH))) {
serverLog(LL_WARNING, "Module %s failed to load: It does not have execute permissions.", path);
return C_ERR;
}
}
// Open the module so.
handle = dlopen(path,RTLD_NOW|RTLD_LOCAL);
if (handle == NULL) {
serverLog(LL_WARNING, "Module %s failed to load: %s", path, dlerror());
return C_ERR;
}
// Obtain the symbolic address of the onload function in the module.
onload = (int (*)(void *, void **, int))(unsigned long) dlsym(handle,"RedisModule_OnLoad");
if (onload == NULL) {
dlclose(handle);
serverLog(LL_WARNING,
"Module %s does not export RedisModule_OnLoad() "
"symbol. Module not loaded.",path);
return C_ERR;
}
RedisModuleCtx ctx;
moduleCreateContext(&ctx, NULL, REDISMODULE_CTX_TEMP_CLIENT); /* We pass NULL since we don't have a module yet. */
// Call onload to initialize the module.
if (onload((void*)&ctx,module_argv,module_argc) == REDISMODULE_ERR) {
serverLog(LL_WARNING,
"Module %s initialization failed. Module not loaded",path);
if (ctx.module) {
moduleUnregisterCommands(ctx.module);
moduleUnregisterSharedAPI(ctx.module);
moduleUnregisterUsedAPI(ctx.module);
moduleRemoveConfigs(ctx.module);
moduleFreeModuleStructure(ctx.module);
}
moduleFreeContext(&ctx);
dlclose(handle);
return C_ERR;
}
/* Redis module loaded! Register it. */
//... irrelevant code is omitted ...
moduleFreeContext(&ctx);
return C_OK;
}API binding
In the initialization function of the module, RedisModule_Init should be called explicitly to initialize the APIs exported by the Redis kernel. Example:
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (RedisModule_Init(ctx, "helloworld", 1, REDISMODULE_APIVER_1) == REDISMODULE_ERR)
return REDISMODULE_ERR;
// ... irrelevant code is omitted ...
}RedisModule_Init 是 redismodule.h 中定义的一个函数,用于导出和绑定 Redis 内核公开的每个 API。
static int RedisModule_Init(RedisModuleCtx *ctx, const char *name, int ver, int apiver) {
void *getapifuncptr = ((void**)ctx)[0];
RedisModule_GetApi = (int (*)(const char *, void *)) (unsigned long)getapifuncptr;
// Bind the APIs exported by Redis.
REDISMODULE_GET_API(Alloc);
REDISMODULE_GET_API(TryAlloc);
REDISMODULE_GET_API(Calloc);
REDISMODULE_GET_API(Free);
REDISMODULE_GET_API(Realloc);
REDISMODULE_GET_API(Strdup);
REDISMODULE_GET_API(CreateCommand);
REDISMODULE_GET_API(GetCommand);
// ... irrelevant code is omitted ...
}让我们先看看REDISMODULE_GET_API在做什么。它是一个宏定义,实质上调用RedisModule_GetApi函数:
#define REDISMODULE_GET_API(name) \
RedisModule_GetApi("RedisModule_" #name, ((void **)&RedisModule_ ## name))RedisModule_GetApi看起来像是 Redis 内部公开的 API,但我们现在正在执行 API 绑定。绑定前如何获取RedisModule_GetApi函数的地址?答案是,当 Redis 内核调用模块的 OnLoad 函数时,它会通过 RedisModuleCtx 传递 RedisModule_GetApi 函数的地址。您可以在上面看到用于加载模块的代码。在调用 Onload 函数之前,Redis 使用 moduleCreateContext 初始化 RedisModuleCtx,并将其传递给模块。
在 moduleCreateContext 中,Redis 中定义的 RM_GetApi 函数的地址分配给 RedisModuleCtx 的 getapifuncptr 成员。
void moduleCreateContext(RedisModuleCtx *out_ctx, RedisModule *module, int ctx_flags) {
memset(out_ctx, 0 ,sizeof(RedisModuleCtx));
// Pass the GetApi address to the module.
out_ctx->getapifuncptr = (void*)(unsigned long)&RM_GetApi;
out_ctx->module = module;
out_ctx->flags = ctx_flags;
// ... irrelevant code is omitted ...
}因此,我们可以使用 RedisModuleCtx 来获取模块中的 GetApi 函数。为什么我们用这么一个“奇怪”的方法,((void**)ctx)[0],而不是直接用ctx->getapifuncptr?原因是 RedisModuleCtx 是 Redis 内核中定义的数据结构,其内部结构对模块(不透明指针)不可见。因此,我们可以利用 getapifuncptr 是 RedisModuleCtx 的第一个成员这一事实,直接取第一点。
void *getapifuncptr = ((void**)ctx)[0];
RedisModule_GetApi = (int (*)(const char *, void *)) (unsigned long)getapifuncptr;以下结构显示了 getapifuncptr 是 RedisModuleCtx 的第一个成员这一事实。
struct RedisModuleCtx {
// getapifuncptr is the first member.
void *getapifuncptr; /* NOTE: Must be the first field. */
struct RedisModule *module; /* Module reference. */
client *client; /* Client calling a command. */
// ... irrelevant code is omitted ...
};在弄清楚RM_GetApi是如何导出的之后,让我们来看看RM_GetApi在做什么:
int RM_GetApi(const char *funcname, void **targetPtrPtr) {
/* Lookup the requested module API and store the function pointer into the
* target pointer. The function returns REDISMODULE_ERR if there is no such
* named API, otherwise REDISMODULE_OK.
*
* This function is not meant to be used by modules developer, it is only
* used implicitly by including redismodule.h. */
dictEntry *he = dictFind(server.moduleapi, funcname);
if (!he) return REDISMODULE_ERR;
*targetPtrPtr = dictGetVal(he);
return REDISMODULE_OK;
}RM_GetApi的内部实现非常简单——根据要绑定的函数名,在全局哈希表(server.mo duleapi)中找到对应的函数地址,找到后将地址分配给targetPtrPtr。那么 dict 中的内容从何而来呢?
当 Redis 内核启动时,它会通过 moduleRegisterCoreAPI 函数注册其公开的模块 API。具体流程如下:
/* Register all the APIs we export. Keep this function at the end of the
* file so that's easy to seek it to add new entries. */
void moduleRegisterCoreAPI(void) {
server.moduleapi = dictCreate(&moduleAPIDictType);
server.sharedapi = dictCreate(&moduleAPIDictType);
// Register functions to the global hash table.
REGISTER_API(Alloc);
REGISTER_API(TryAlloc);
REGISTER_API(Calloc);
REGISTER_API(Realloc);
REGISTER_API(Free);
REGISTER_API(Strdup);
REGISTER_API(CreateCommand);
// ... irrelevant code is omitted ...
}其中,REGISTER_API本质上是一个宏定义,由moduleRegisterApi函数在内部实现。moduleRegisterApi 函数将导出的函数名称和函数指针添加到 duleapi server.mo。
int moduleRegisterApi(const char *funcname, void *funcptr) {
return dictAdd(server.moduleapi, (char*)funcname, funcptr);
}
#define REGISTER_API(name) \
moduleRegisterApi("RedisModule_" #name, (void *)(unsigned long)RM_ ## name)那么问题来了——为什么 Redis 要花这么多精力来实现 API 导出绑定机制?理论上,模块动态库中的代码仍然可以通过直接使用动态连接器的符号解析和重定位机制来调用 Redis 公开的可见符号。虽然这是可行的,但会存在符号冲突。例如,如果其他模块也暴露了与 Redis API 相同的函数名称,则依赖于全局符号解析机制和序列来区分(全局符号干预)。另一个原因是 Redis 可以通过这种绑定机制更好地控制不同版本的 API。
最佳实践
入口函数禁用 C++ mangle
从前面的模块加载机制可以看出,模块必须严格保证入口函数名称符合 Redis 的要求。因此,当我们用 C++ 编写模块代码时,我们必须首先禁用 C++ mangle。否则,将报告错误“模块不导出 RedisModule_OnLoad()”。
示例代码如下:
#include "redismodule.h"
extern "C" __attribute__((visibility("default"))) int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
// Init code and command register
return REDISMODULE_OK;
}接管内存统计信息
Redis 需要准确统计数据结构在运行时使用的内存(原子变量 used_memory 用于内部加减),这就要求模块必须使用与 Redis 内核相同的内存分配接口。否则,模块中的内存分配可能不会被计算在内。
REDISMODULE_API void * (*RedisModule_Alloc)(size_t bytes) REDISMODULE_ATTR;
REDISMODULE_API void * (*RedisModule_Realloc)(void *ptr, size_t bytes) REDISMODULE_ATTR;
REDISMODULE_API void (*RedisModule_Free)(void *ptr) REDISMODULE_ATTR;
REDISMODULE_API void * (*RedisModule_Calloc)(size_t nmemb, size_t size) REDISMODULE_ATTR;对于一些简单的模块,显式调用这些 API 没有问题。但是,对于一些稍微复杂一点的模块,尤其是那些依赖某些第三方库的模块,用模块接口替换库中的所有内存分配就比较困难了。如果我们使用 C++ 来开发 Redis 模块,那么让随处可见的容器分配器(new/delete/make_shared)C++被统一内存分配接管就显得尤为重要了。
new/operator new/placement new
首先,我将解释它们之间的区别:new 是一个关键字,和 sizeof 一样,我们不能修改它的特定功能。新负责三件事:
- 分配空间(使用运算符 new)。
- 初始化对象(使用 placement new 或 type casts),即调用对象的构造函数。
- 返回对象指针。
运算符 new 是可以分配空间的运算符,就像 +/- 一样。我们可以重写它们并修改我们分配空间的方式。
placement new 是运算符 new 的重载形式(即参数形式不同)。例:
void * operator new(size_t, void *location) {
return location;
}可以看出,要修改 new 使用的默认内存分配,我们可以使用两种方法。
放置 新
它无非是手动模拟关键字 new 的行为。首先,使用模块 API 分配一块内存,然后调用该内存上对象的构造函数。
Object *p=(Object*)RedisModule_Alloc(sizeof(Object));
new (p)Object();请注意,析构函数还需要特殊处理:
p->~Object();
RedisModule_Free(p);由于 placement new 没有全局行为,需要手动处理每个对象的分配,因此它仍然无法完全解决复杂 C++ 模块的内存分配问题。
运算符 new
C++ 具有运算符 new 的内置实现。默认情况下,glibc malloc 用于分配内存。C++为我们提供了一个重载机制,即我们可以实现自己的算子 new,并用 RedisModule_Alloc 替换内部的 malloc。
实际上,说运算符 new 重载(同一级别的函数名相同,而参数不同)或重写(派生的函数名和参数必须相同,返回值必须相同,类型协变除外)是不合适的。我认为“覆盖”在这里更合适,因为 C++ 编译器的内置运算符 new 是作为弱符号实现的。以GCC为例:
_GLIBCXX_WEAK_DEFINITION void *
operator new (std::size_t sz) _GLIBCXX_THROW (std::bad_alloc)
{
void *p;
/* malloc (0) is unpredictable; avoid it. */
if (sz == 0)
sz = 1;
while (__builtin_expect ((p = malloc (sz)) == 0, false))
{
new_handler handler = std::get_new_handler ();
if (! handler)
_GLIBCXX_THROW_OR_ABORT(bad_alloc());
handler ();
}
return p;
}这样,当我们实现一个强符号版本时,它将覆盖编译器自己的实现。
以基本运算符 new/operator delete 为例:
void *operator new(std::size_t size) {
return RedisModule_Alloc(size);
}
void operator delete(void *ptr) noexcept {
RedisModule_Free(ptr);
}由于运算符 new 具有全局行为,因此可以“一劳永逸”地解决使用 new/delete(make_shared 内部也使用 new)分配内存的所有问题。
跨多个模块的操作员新可见性
由于运算符 new 具有全局可见性(编译器不允许将运算符 new 隐藏在命名空间下),因此如果 Redis 加载多个用 C++ 编写的模块,我们需要注意此行为的影响。
现在假设有两个模块,即 module1 和 module2,其中 module1 重载运算符 new。由于运算符 new 本质上是一个特殊函数,当 module1 被 Redis 加载(使用 dlopen)时,动态连接器会将 module1 实现的运算符 new 函数添加到全局符号表中,因此当加载 module2 并稍后进行符号重定位时,module2 也会将自己运算符 new 链接到 module1 实现的运算符 new。
如果 module1 和 module2 都是我们自己开发的,一般不会有问题。但是,如果 module1 和 module2 是由不同的开发者开发的,或者即使它们都提供了不同的算子新实现,那么只有先加载的实现才会生效(全局合规干预),后面加载的实现的行为可能会异常。
静态链接/动态链接 C++ 标准库
静态链接
有时,我们的模块可能会使用高级 C++ 版本编写和编译。为了防止模块在分发时不被目标平台上对应的 C++ 环境支持,我们通常将 C++ 标准库以静态链接的方式编译到模块中。以Linux平台为例。我们希望将 libstdc++ 和 ibgcc_s静态链接到模块中。通常,如果 Redis 只加载一个 C++ 模块,就不会有问题。但是,如果同时存在两个 C++ 模块,并且采用静态链接 C++ 标准库的方法,则会出现模块异常。具体来说,加载的模块不能正常使用 C++ 流,进而不能正常打印信息、使用正则表达式等(怀疑是 C++ 标准库定义的一些全局变量重复初始化导致此类异常)
?
动态链接
因此,在此方案中(Redis 加载多个 C++ 库),建议所有模块都使用动态链接。如果还在担心分发时C++版本的兼容性问题,可以将 libstdc++.so 和 ibgcc_s.so 打包在一起,然后使用 $ORIGIN 修改 rpath 来指定指向您版本的链接。
使用块机制提高并发处理能力
Redis 是一种单线程模型(worker 单线程),这意味着 Redis 在执行一个命令时不会处理和响应另一个命令。对于一些耗时的模块命令,我们还是希望这个命令能在后台运行,这样Redis就可以继续读取和处理下一个客户端的命令。
如图 1 所示,cmd1 在 Redis 中执行,并在主线程将 cmd1 放入队列后直接返回(无需等待 cmd1 完成执行)。此时,主线程可以继续处理下一个命令 cmd2。执行 cmd1 后,会再次在主线程中注册一个事件。这样,cmd1 的后续处理就可以在主线程中继续进行,例如将执行结果发送到客户端、写入 AOF、将副本传播到客户端。
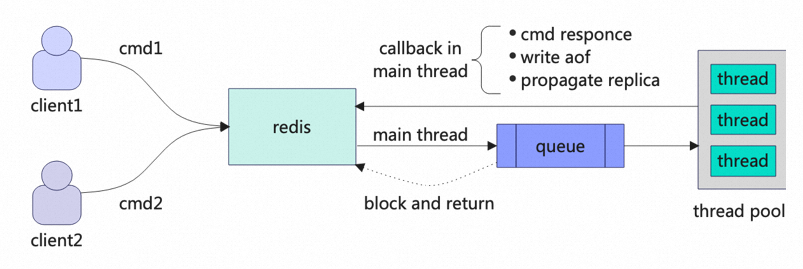
图1 典型的异步处理模型
虽然块看起来很漂亮,功能强大,但需要小心处理,例如:
? 虽然命令是异步执行的,但仍需要写入 AOF 并同步复制到辅助数据库。如果命令提前写入AOF,并复制到备库,则后续命令执行失败时无法回滚。
? 由于辅助数据库不允许执行块命令,因此主数据库需要将块命令重写为非阻塞命令,并复制到辅助数据库。
? 在异步执行过程中,我们不能只关注打开密钥时的密钥名,因为原始密钥可能在异步线程执行之前就已经被删除了,然后又创建了另一个同名的密钥。也就是说,当前密钥不再是原始密钥。
? 设计块命令是否支持事务和 lua。
? 如果使用线程池,应注意线程池中同一密钥的顺序保留执行(即同一密钥的处理不能乱序)。
避免与其他模块的符号冲突
因为Redis可以同时加载多个模块,而这些模块可能来自不同的团队和个人,所以有一定概率不同的模块会定义相同的函数名。为了避免符号冲突导致的未定义行为,建议每个模块隐藏除 Onload 和 Unload 函数之外的所有符号,并将一些标志实现传递给编译器。如GCC:
-fvisibility=hidden当心叉子陷阱
用于处理飞行状态的命令
假设该模块使用异步执行模型(请参阅上面的块部分)。当 Redis 执行 AOF rewrite 或 BGSAVE 时,如果 Redis 使用 fork 执行子进程时仍有一些命令处于 inflight 状态,则新生成的基础 AOF 或 RDB 可能不包含正在进行的数据。这似乎不是什么大问题,因为 inflight 的命令在最终完成时也会写入增量 AOF 中。但是,为了兼容 Redis 的原始行为(即分叉时必须没有处于飞行状态的命令,并且处于静态状态),模块最好在分叉之前确保所有处于飞行状态的命令都执行完毕。
在模块中,在分叉之前,我们可以利用 Redis 公开的 RedisModuleEvent_ForkChild 事件来执行我们传递的回调函数。
RedisModule_SubscribeToServerEvent(ctx, RedisModuleEvent_ForkChild, waitAllInflightTaskFinish);例如,等待队列在 waitAllInflightTaskFinish 中为空(即执行所有任务):
static void waitAllInflightTaskFinish() {
while (!thread_pool->idle())
;
}或者,可以通过直接使用glibc暴露的pthread_atfork来达到相同的效果。
int pthread_atfork(void (*prepare)(void), void (*parent)void(), void (*child)(void));避免死锁
需要注意的是,通过分叉创建的子进程与父进程几乎相同,但并不完全相同。子进程接收父进程的用户级虚拟地址空间的单独副本,包括文本、数据、bss 段、堆和用户堆栈。它还接收与父进程相同的任何打开文件描述符的副本,这意味着它可以读取和写入父进程中的任何打开的文件。父进程和子进程之间的主要区别在于它们具有不同的进程 ID (PID)。
但是,在 Linux 中,分叉时,只有当前线程被复制到子进程。fork(2) - Linux 手册页提供了以下相关说明:
子进程是使用单个线程创建的,该线程名为 fork()。父级的整个虚拟地址空间在子级中复制,包括互斥锁、条件变量和其他 pthreads 对象的状态;使用pthread_atfork(3)可能有助于处理由此可能导致的问题。
换句话说,除了调用 fork 的线程之外,所有其他线程都在子进程中“蒸发”。因此,如果某些异步线程对某些资源持有锁,则子进程中可能会发生死锁,因为这些线程会消失。
解决方案与在飞行中处理相同。确保在分叉之前释放所有锁。(实际上,只要执行了所有处于飞行状态的命令,就会释放通用锁。
确保复制到辅助数据库的 AOF 的幂等性
Redis 中主/辅助复制的主要目的是确保一致性。因此,辅助数据库的唯一任务是无条件地从主数据库接收复制的内容,并保持严格的一致性。但是,需要小心处理一些特殊命令。
在此示例中,Tair 公开的 Tair 字符串支持设置数据的版本号。例如,我们可以编写以下代码:
EXSET key value VER 10然后,在主数据库执行此命令后,最好在将命令复制到辅助数据库时按如下方式重写该命令:
EXSET key value ABS 11也就是说,绝对版本号用于强制辅助数据库与主数据库相同。类似的情况还有很多,例如与时间和浮点计算相关的场景。
支持平滑关机
该模块可能会启动一些异步线程或管理一些异步资源。当 Redis 关闭时,需要处理这些资源(例如停止、销毁和写入磁盘)。否则,当 Redis 退出时,可能会发生 coredump。
在 Redis 中,您可以注册 RedisModuleEvent_Shutdown 事件实现。当 Redis 关闭时,它将回调我们传递的 ShutdownCallback。
在较新的 Redis 版本中,该模块也可以通过公开 unload 函数来实现类似的功能。
RedisModule_SubscribeToServerEvent(ctx, RedisModuleEvent_Shutdown, ShutdownCallback);避免过大的 AOF
? 实现了AOF文件压缩功能。例如,哈希的所有写入操作都可以重写为一个或多个 hmset 命令。
? 确保单个重写的 AOF 的大小不超过 500 MB。如果超过 500 MB,我们必须将 AOF 重写为多个 CMD,并确保这些 CMD 是否需要以事务方式执行(即确保操作命令的执行是隔离的)。
? 对于结构复杂,无法用现有命令简单重写的模块,可以单独实现内部命令,如 xxxload/xxxdump,对模块的数据结构进行序列化和反序列化。该命令不会向客户端公开。
? 如果RedisModule_EmitAOF包含数组类型的参数(即使用“v”标志传递的参数),则数组的长度必须为 size_t 类型。否则,可能会遇到奇怪的错误。
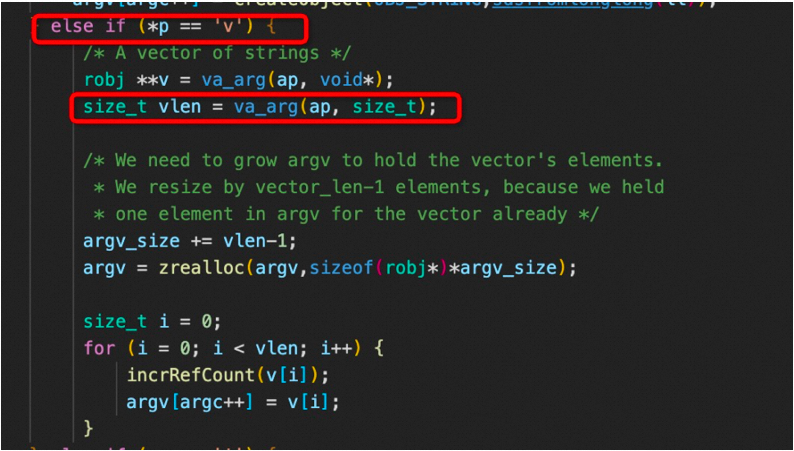
RDB 编码具有向后兼容性
RDB 是以二进制格式序列化和反序列化的,因此相对简单。但需要注意的是,如果将来数据结构的序列化方式可能会发生变化,最好添加编解码版本,这样在升级过程中可以保证兼容性。代码如下:
void *xxx_RdbLoad(RedisModuleIO *rdb, int encver) {
if (encver == version1 ) {
/* version1 format */
} else if (encver == version2 ){
/* version2 format */
}
}命令实现建议
? 参数校验:在执行命令前验证参数的有效性(如参数的正确数量和类型),在命令执行不成功时尽量避免提前修改密钥空间(如提前使用RedisModule_ModuleTypeSetValue修改主库)。
??错误消息:返回的错误消息应简单明了,说明错误类型。
? 一致的响应类型:命令的返回类型在不同情况下应该是一致的,例如当密钥不存在时、密钥类型错误、执行成功、某些参数错误等。通常,除错误类型(例如简单字符串或数组)外,所有情况都应返回相同的类型,例如简单字符串或数组(即使它是空数组)。这使客户端更容易分析命令返回值。
? 检查读写类型:命令必须严格区分读写类型,因为它决定了命令是否可以在副本上执行,以及命令是否需要同步写入 AOF。
? 复制幂等性和 AOF:对于写入命令,请使用 RedisModule_ReplicateVerbatim 或 RedisModule_Replicate 执行主/辅助复制并写入?AOF(必要时重写原始命令)。Multi/exec 会在 RedisModule_Replicate 生成的 AOF 之前和之后自动添加(以确保模块中生成的命令是隔离的)。因此,建议优先使用 RedisModule_ReplicateVerbatim 进行复制和写入 AOF。但是,如果命令中有版本号等参数,请使用 RedisModule_Replicate 将版本号重写为绝对版本号,将过期时间重写为绝对过期时间。此外,如果需要使用 RedisModule_Replicate 重写命令,请确保不会再次重写重写的命令。
??复用?argv 参数:传递给命令的 argv 中的参数类型为 RedisModuleString **,命令返回后会自动释放这些 RedisModuleString 指针。因此,不应在命令中直接引用这些 RedisModuleString 指针。如果需要这样做(例如避免内存复制),可以使用 RedisModule_RetainString/RedisModule_HoldString 来增加 RedisModuleString 的引用计数,但请记住稍后手动释放它们。
??开钥匙的方式:用RedisModule_OpenKey开钥匙时,要严格区分REDISMODULE_READ和REDISMODULE_WRITE两种开门方式。不区分会影响内部stat_keyspace_misses和stat_keyspace_hits信息的更新,以及过期的重写。同时,无法删除使用 REDISMODULE_READ 方法打开的密钥,否则会报错。
? 不同键类型的处理方式:目前只有字符串的set命令可以强制覆盖其他类型的键。当键存在但类型不匹配时,其他命令应返回错误“WRONGTYPE Operation against a key of having the wrong kind value”。
? 集群支持多键命令:对于多键命令,firstkey、lastkey 和 keystep 的值必须正确处理,因为只有当这些值正确时,Redis 才能检查这些键在集群模式下是否存在 CROSS SLOTS 问题。
? 全局索引和结构:如果模块有自己的全局索引,请检查索引中是否包含 dbid、key 等信息。Redis 的 move、rename、swapdb 等命令可以暗中更改密钥名称并交换两个 dbid。因此,如果此时未同步更新索引,则可能会出现意外错误。
??根据角色确定操作:Redis 模块可以是主数据库,也可以是辅助数据库。该模块可以使用RedisModule_GetContextFlags来确定当前的 Redis 角色,并根据角色采取不同的操作(例如是否主动过期)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【JavaSE】Java入门七(抽象类和接口详解)
- 安徽省人民政府关于印发《打造通用人工智能产业创新和应用高地若干政策》通知
- 1-学成在线项目开发环境配置
- 神经辐射场(NeRFs)的研究进展
- day 18二叉树(五)
- 约瑟夫环(报数游戏)C++
- 工具系列:PyCaret介绍_Fugue 集成_Spark、Dask分布式训练
- OkHttpClient常见方法和使用
- 【C】void指针(通用指针)
- 对象合并(相同的相加,不同的创建)