网络爬虫 动态数据采集
动态数据采集
规则
??????? 有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样,在浏览器中可以看到正常显示的页面教据,但是使用 requests 得到的结果并没有,这是因为requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文档中的,也可能是经过 avaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获取数据,然后数据才被处理从而呈现到网页上,这其实就是发送了一个 Ajax 请求。
????????照 Web 发展的趋势来看,这种形式的页面越来越多。网页的原始 HTML 文档不会包含任何数据,数据都是过 Ajax 统一加载后再呈现出来的,这样在 We 开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。
????????所以如果遇到这样的页面,直接利用 requests 等库来抓取原始页面,是无法获取到有效数据的,这时需要分析网页后台向接口发送的Ajax 请求,如果可以用 requests 来模拟 Aiax 请求,那么就可以成功抓取了所以,本章我们的主要目的是了解什么是 Ajax 以及如何去分析和抓取 Ajax 请求。
什么是Ajax
????????Ajax,全称为 Asynchronous JavaScript and XML,即异步的avaScript 和 XML,它不是-门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
??????? 对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用JavaScript 改变网页,这样网页内容就会更新了。
手写Ajax接口
环境搭建
pip install flask一个简单请求过程
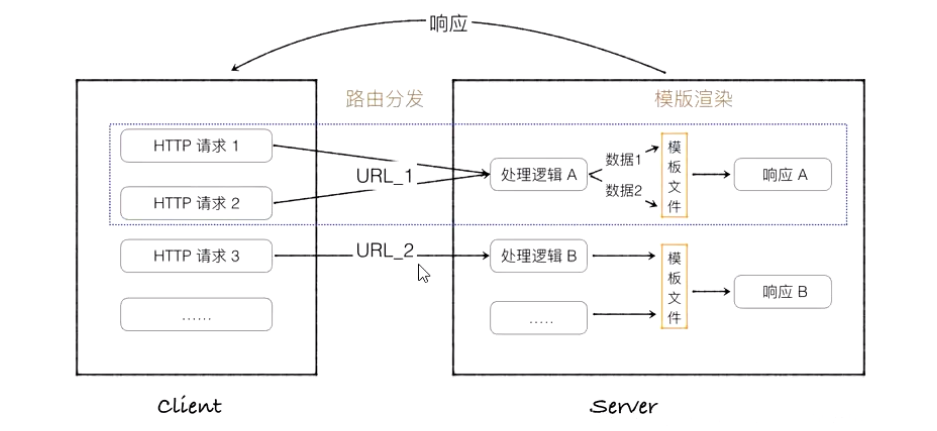
通俗地说,路由(Routing)就像是一种地图,告诉服务器当用户访问一个特定的 URL 地址时该如何响应。在 Web 开发中,路由是将浏览器中的 URL 映射到后端应用程序中的一种功能或代码块的机制。
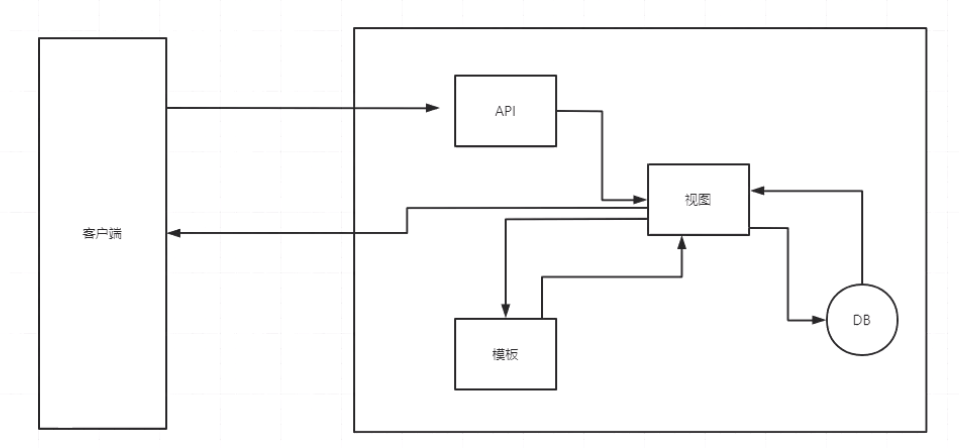
API 是“应用编程接口”(Application Programming Interface)的缩写。它是一套预定义的规则和协议,用于构建和集成软件应用程序。简单来说,API 是一种使得不同软件组件之间可以相互沟通的方式。
Web API:通常指的是通过HTTP协议为Web服务器和客户端或者两个在线服务之间提供数据交换的接口。例如,天气服务的API可以允许开发者获取天气预报数据。
在Web开发中,视图通常指的是用户请求特定URL时服务器返回的页面。例如,在一个Web应用中,服务器可能会根据用户请求的不同路径(比如/home或/products)来提供不同的HTML内容。在Web框架中,视图还可以是模板,模板中的数据会由服务器动态填充,然后渲染成最终的HTML发送给客户端。
在Web开发领域,模板特指的是用于动态生成HTML页面的预设文件。这些模板文件包含了静态的HTML标记,以及用于插入动态内容的特殊模板标签或占位符。当服务器接收到一个请求时,它会结合模板和相关的数据来生成最终的HTML页面,然后发送给客户端。
例如,在Python的Flask框架中,模板可能会使用Jinja2模板引擎编写:
<!DOCTYPE html>
<html>
<head>
<title>{{ title }}</title>
</head>
<body>
<h1>Hello, {{ name }}!</h1>
</body>
</html>
在上面的例子中,{{ title }} 和 {{ name }} 是模板变量,它们在渲染过程中会被实际的值所替换。
编写网络爬虫爬取蛋卷基金信息并存储
import requests
import pymysql
# 创建数据库连接
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306)
cursor = db.cursor()
cursor.execute('use spiders')
def get_data():
url = 'https://danjuanfunds.com/djapi/fund/growth/011102?day=1m'
headers = {
'User-Agent':'111222333444'
}
resp = requests.get(url, headers=headers).json()
data = resp.get('data')['fund_nav_growth']
for item in data:
date = item.get('date') # 如果没有就返回 None
value = item.get('value')
than_value = item.get('than_value')
print('日期:', date, '\n', '本产品:', value, '沪深:', than_value)
# 保存数据到数据库
save_data(date, value, than_value)
def save_data(date, value, than_value):
sql = 'INSERT INTO funds(date, value, than_value) VALUES(%s, %s, %s)'
cursor.execute(sql, (date, value, than_value))
db.commit() # 提交事务
# 获取并保存数据
get_data()
# 关闭光标和数据库连接
cursor.close()
db.close()编写网络爬虫爬取虎牙信息并存储
import requests,pymysql
def conn_mysql():
db = pymysql.connect(host='localhost',user='root',password='123456',database='spiders')
cursor = db.cursor()
return cursor,db
def get_date(url):
resp = requests.get(url).json()
dates = []
try:
date = resp.get('vList')
for item in date:
indurce = item.get('sIntroduction')
author = item.get('sNick')
home_numb = item.get('sGameHostName')
# print('主播名:',author,'简介:',indurce,'房间号:',home_numb)
dates.append([author,indurce,home_numb])
save_date(dates)
except Exception as e:
print(e)
def save_date(data):
cursor, db = conn_mysql()
cursor.execute('use spiders')
sql = 'insert into huya(author,indurce,home_numb) values(%s,%s,%s)'
for d in data:
print(d)
try:
cursor.execute(sql,(d[0],d[1],d[2]))
db.commit()
except Exception as e:
print(e)
db.rollback()
urls = []
for i in range(1,127):
url = 'https://live.huya.com/liveHttpUI/getLiveList?iGid=0&iPageNo={}&iPageSize=120'.format(i)
if url not in urls:
urls.append(url)
for url in urls:
print(i)
get_date(url)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!