【MySQL】数据库之高级SQL查询语句
发布时间:2023年12月28日
目录
1简单的select条件查询(where)
##全表查询
select * from 表名;
##针对某些字段查询
select 字段列表 from 表名;
##针对某一字段去重查询,只能指定一个字段
select distinct 指定一个字段 from 表名;
##使用where做条件查询
select 字段列表 from 表名 where 字段=值 and 字段=值;
##多个字段的查询,逻辑运算符:且and 或or
where 字段1=值 and|or 字段1=值;
##符号运算符有:
不等于!= <> 小于< 小于等于<= 大于> 大于等于>=
##不等于!= <>会做全表扫描查询
##字符运算符:
where 字段名称 not in(值1,值2...)
where 字段名称 in(值1,值2...)
where 字段名称 between 值1 and 值2 ##闭区间查询
where 字段名称 like '通配符表达式'
##当使用like模糊查询时,%开头,会全表扫描
##通配符有两个%和_ %表示任意,_表示单个字符;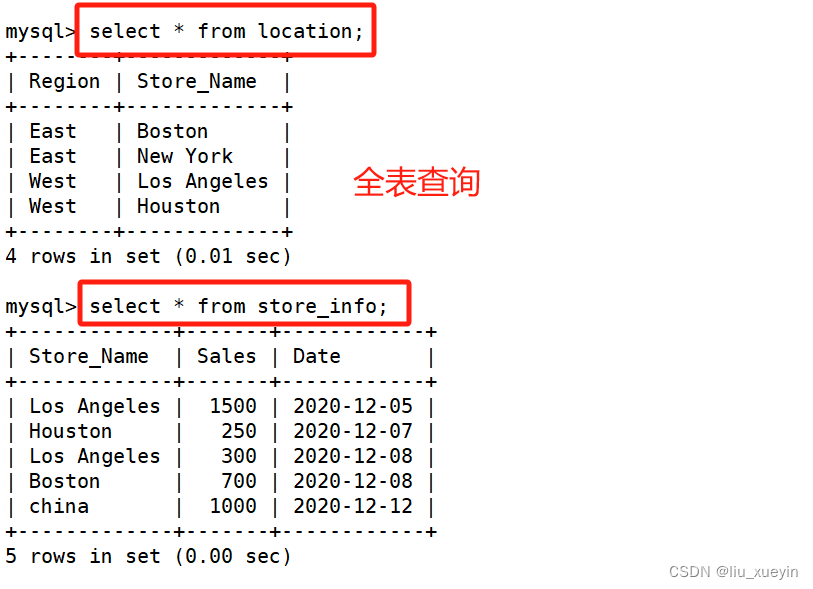

 ?
?



?like模糊查询
---- 通配符 ----通常通配符都是跟 LIKE 一起使用的
% :百分号表示零个、一个或多个字符
_ :下划线表示单个字符
'A_Z':所有以 'A' 起头,另一个任何值的字符,且以 'Z' 为结尾的字符串。例如,'ABZ' 和 'A2Z' 都符合这一个模式,而 'AKKZ' 并不符合 (因为在 A 和 Z 之间有两个字符,而不是一个字符)。
'ABC%': 所有以 'ABC' 起头的字符串。例如,'ABCD' 和 'ABCABC' 都符合这个模式。
'%XYZ': 所有以 'XYZ' 结尾的字符串。例如,'WXYZ' 和 'ZZXYZ' 都符合这个模式。
'%AN%': 所有含有 'AN'这个模式的字符串。例如,'LOS ANGELES' 和 'SAN FRANCISCO' 都符合这个模式。
'_AN%':所有第二个字母为 'A' 和第三个字母为 'N' 的字符串。例如,'SAN FRANCISCO' 符合这个模式,而 'LOS ANGELES' 则不符合这个模式。
---- LIKE ----匹配一个模式来找出我们要的数据记录
语法:SELECT "字段" FROM "表名" WHERE "字段" LIKE {模式};
SELECT * FROM Store_Info WHERE Store_Name like '%os%';2排序
select 字段列表 from 表名 order by 字段 asc或desc
asc 升序,默认为asc(Ascending)
desc 降序(Descending)


---- ORDER BY ----按关键字排序
语法:SELECT "字段" FROM "表名" [WHERE "条件"] ORDER BY "字段" [ASC, DESC];
#ASC 是按照升序进行排序的,是默认的排序方式。
#DESC 是按降序方式进行排序。对数据进行排序并输出排名
select A.Store_Name,A.Sales,count(B.Sales) rank from store_info A,store_info B where A.sales<B.sales or (A.sales=B.sales and A.Store_Name=B.Store_Name) groupp by A.store_name,A.sales order by rank desc;
select A.Store_Name,A.Sales,(select count(B.sales)+1 from store_info B where A.sales<B.sales) rank from store_info A order by A.Sales desc;
##自己调用自己
3.函数
3.1数学函数
| abs(x) | 返回 x 的绝对值 |
| rand() | 返回 0 到 1 的随机数 |
| mod(x,y) | 返回 x 除以 y 以后的余数 |
| power(x,y) | 返回 x 的 y 次方 |
| round(x) | 返回离 x 最近的整数 |
| round(x,y) | 保留 x 的 y 位小数四舍五入后的值 |
| sqrt(x) | 返回 x 的平方根 |
| truncate(x,y) | 返回数字 x 截断为 y 位小数的值 |
| ceil(x) | 返回大于或等于 x 的最小整数 |
| floor(x) | 返回小于或等于 x 的最大整数 |
| greatest(x1,x2...) | 返回集合中最大的值,也可以返回多个字段的最大的值,也可以指定字段名 |
| least(x1,x2...) | 返回集合中最小的值,也可以返回多个字段的最小的值 |
SELECT ABS(-2),RAND(),MOD(2,3),POWER(2,3),ROUND(1.88),ROUND(1.238,2),SQRT(4),TRUNCATE(1.238,2),CEIL(1.3),FLOOR(1.3);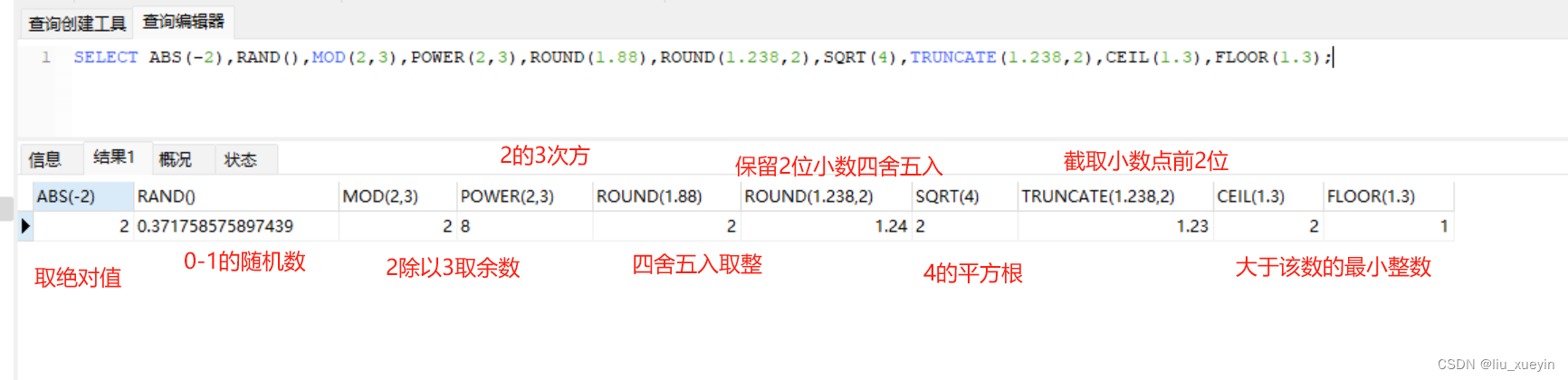
SELECT GREATEST(1.88,2.1,3,5,6),LEAST(1.88,2.1,3,5,6);
3.2聚合函数
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(x) | 返回指定列的所有值之和 |
SELECT sum(Sales),COUNT(Sales),avg(Sales) FROM store_info;
SELECT sum(Sales)/COUNT(Sales),avg(Sales) FROM store_info;

SELECT COUNT(DISTINCT store_name) FROM store_info;
使用count函数进行条件计数,做排序操作的
SELECT count(b.sales)+1 FROM store_info b WHERE 250<b.sales;
SELECT count(b.sales)+1 FROM store_info b WHERE 300<b.sales;
SELECT count(b.sales)+1 FROM store_info b WHERE 700<b.sales;
SELECT count(b.sales)+1 FROM store_info b WHERE 1000<b.sales;
SELECT count(b.sales)+1 FROM store_info b WHERE 250<b.sales;
SELECT a.Store_Name,a.Sales,(SELECT count(b.sales)+1 FROM store_info b WHERE a.sales<b.sales) FROM store_info a;
count函数的用法之 用于分组计数
SELECT store_name,COUNT(store_name) FROM store_info GROUP BY store_name;


拓展:count(*)和?count(字段)的区别
#count(*) 包括了所有的列的行数,在统计结果的时候,不会忽略列值为 NULL
#count(列名) 只包括列名那一列的行数,在统计结果的时候,会忽略列值为 NULL 的行




3.3字符串函数
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substring_index(x,y,z) | 针对x字符,按照y字符为分隔符,z为-1取最右边,z为1为取最左边,2表示第2个分隔符 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
3.3.1针对concat函数
SELECT CONCAT(store_name,'-',Sales) FROM store_info;


3.3.2针对subtr函数
select SUBSTRING_INDEX(Date,'-',-2) from store_info;
##指定分隔符取值
substring_index(x,y,z) ##针对x字符,按照y字符为分隔符,z为-1取最右边,z为1为取最左边
select SUBSTR(Date,6) from store_info;
##截取
substr(x,y,z) ##针对字符串x的第y个字符开始(包含第y个字符,与linux的字符串截取有区别),获取z个字符串,x可以是字段

select SUBSTR(Date,6,2) from store_info;
select SUBSTRING_INDEX(SUBSTRING_INDEX(Date,'-',-2),'-',1) from store_info;
3.3.3针对length函数
SELECT store_name,LENGTH(store_name) FROM store_info;
3.3.4针对replace函数
SELECT REPLACE('hello','lo','lo world');
3.3.5针对trim函数
##返回指定字符串 可以是字符串,也可以是字段
trim() ##可以使用子查询获取查询结果为字符串
TRIM([{BOTH | LEADING | TRAILING} [要移除的字符串] FROM] str|字段)
##both 表示开头和结尾的 对应字符串截取后 剩下的
##leading 表示开头的 对应字符串截取后 剩下的
##trailing 表示结尾的 对应字符串截取后 剩下的
4.group by分组
---- GROUP BY ----
对GROUP BY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
GROUP BY 有一个原则,凡是在GROUP BY后面出现的字段,必须在 SELECT 后面出现;
凡是在 SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在 GROUP BY 后面
语法:SELECT "字段1", SUM("字段2") FROM "表名" GROUP BY "字段1";
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name ORDER BY sales desc;

SELECT store_name,SUM(Sales) FROM store_info GROUP BY store_name;
SELECT store_name,count(Sales) FROM store_info GROUP BY store_name;
SELECT store_name,max(Sales) FROM store_info GROUP BY store_name;
SELECT store_name,min(Sales) FROM store_info GROUP BY store_name;5.子查询字段和as别名
---- 子查询 ----
连接表格,在WHERE 子句或 HAVING 子句中插入另一个 SQL 语句
语法:SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询
(SELECT "字段1" FROM "表格2" WHERE "条件"); #内查询
#可以是符号的运算符,例如 =、>、<、>=、<= ;也可以是文字的运算符,例如 LIKE、IN、BETWEEN
SELECT SUM(Sales) FROM Store_Info WHERE Store_Name IN
(SELECT Store_Name FROM location WHERE Region = 'West');
SELECT SUM(A.Sales) FROM Store_Info A WHERE A.Store_Name IN
(SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);SELECT SUM(sales) FROM store_info WHERE Store_Name in (SELECT Store_Name FROM location WHERE Region = 'west');
SELECT SUM(sales) FROM store_info WHERE Store_Name in (SELECT Store_Name FROM location);
SELECT SUM(A.Sales) FROM store_info A WHERE A.Store_Name IN (SELECT Store_Name FROM location B WHERE B.Store_Name = A.Store_Name);
6.select查询的顺序

where-->group by --> having --> select --> distinct -->order by --> limit
7.having的作用是什么?
针对group by过后的表进行条件过滤,
having的作用是对group by分组后的表做进一步条件过滤,和where的语法类似的,不用where是因为where是对表字段做过滤,执行的顺序是在group by 前面;
---- HAVING ----
用来过滤由 GROUP BY 语句返回的记录集,通常与 GROUP BY 语句联合使用
HAVING 语句的存在弥补了 WHERE 关键字不能与聚合函数联合使用的不足。
语法:SELECT "字段1", SUM("字段2") FROM "表格名" GROUP BY "字段1" HAVING (函数条件);
SELECT Store_Name, SUM(Sales) FROM Store_Info GROUP BY Store_Name HAVING SUM(Sales) > 1500;

SELECT store_name,count(store_name) FROM store_info GROUP BY store_name HAVING count(store_name)>1;
SELECT store_name FROM store_info GROUP BY store_name HAVING count(store_name)>1;
SELECT store_name,sales FROM store_info WHERE Store_Name in (SELECT store_name FROM store_info GROUP BY store_name HAVING count(store_name)>1);
SELECT store_name,sum(sales) FROM store_info
WHERE Store_Name in (SELECT store_name FROM store_info GROUP BY store_name HAVING count(store_name)>1) GROUP BY store_name;
8.exists的作用?
---- EXISTS ----
用来测试内查询有没有产生任何结果,类似布尔值是否为真
#如果有的话,系统就会执行外查询中的SQL语句。若是没有的话,那整个 SQL 语句就不会产生任何结果。
语法:SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");
SELECT SUM(Sales) FROM Store_Info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');9.表连接
9.1内连接、左连接、右连接与联集、多表查询
?join的语法:select 字段列表 from 左表 A [inner|left|right] join 右表 B on A.key=B.key
内连接inner join:只返回两个表字段相等的行记录,交集
左连接left join :返回左表所有的行记录,以及右表字段相等的行记录,不相等的在右表中返回null
右连接right join :返回右表所有的行记录,以及左表字段相等的行记录,不相等的在左表中返回null
##(select语句1) union [all] (select语句2)
联集union ? ? ? ? 联集,将两个select查询语句的结果合并,并去重
联集union all ? ? 联集,将两个select查询语句的结果合并,不去重? ?
?
9.2多表连接
select A.字段 from 左表 A,右表 B,.... where A.key=B.key;
##这里不能用using函数
10.几种多表查询方法

求交集 的方法


select A.字段 from from 左表 as A inner join 右表 as B on A.key=B.key
select A.字段 from from 左表 as A inner join 右表 as B using(同名字段)
select A.字段 from from 左表 as A left join 右表 as B on A.key=B.key where B.key is not null
select A.字段 from from 左表 as A right join 右表 as B on A.key=B.key where A.key is null
select A.字段 from 左表 A,右表 B where A.key=B.key; ##这里不能用using函数
select 字段 from 左表 where 关键字段1 in (select 关键字段2 from 右表);
select A.字段,count(字段) from (select distinct 关键字段 from 左表 union all select distinct 关键字段 from 右表 ) as A group by A.字段 having count(字段) >1求左表有交集
select A.字段 from from 左表 as A left join 右表 as B on A.key=B.key
求左表无交集
select A.字段 from from 左表 as A left join 右表 as B on A.key=B.key where B.key is null
select 字段 from 左表 where 关键字段1 not in (select 关键字段2 from 右表);
求右表有交集
select A.字段 from from 左表 as A right join 右表 as B on A.key=B.key
求右表无交集
select A.字段 from from 左表 as A right join 右表 as B on A.key=B.key where A.key is null
select 字段 from 右表 where 关键字段1 not in (select 关键字段2 from 左表);
求两个表无交集
select A.字段 from from 左表 as A left join 右表 as B on A.key=B.key where B.key is null
union
select A.字段 from from 左表 as A right join 右表 as B on A.key=B.key where A.key is null
##使用派生表求两个表无交集
select A.字段,count(字段) from (select distinct 关键字段 from 左表 union all select distinct 关键字段 from 右表 ) as A group by A.字段 having count(字段) =1
求两个表所有的合集
联集union 联集,将两个select查询语句的结果合并,并去重
联集union all 联集,将两个select查询语句的结果合并,不去重
select A.字段 from from 左表 as A left join 右表 as B on A.key=B.key
union
select A.字段 from from 左表 as A right join 右表 as B on A.key=B.key11图表
11.1创建视图表
视图表的作用是记录select语句
create view 视图表名称 as select语句;11.2查看视图表
##查询视图表
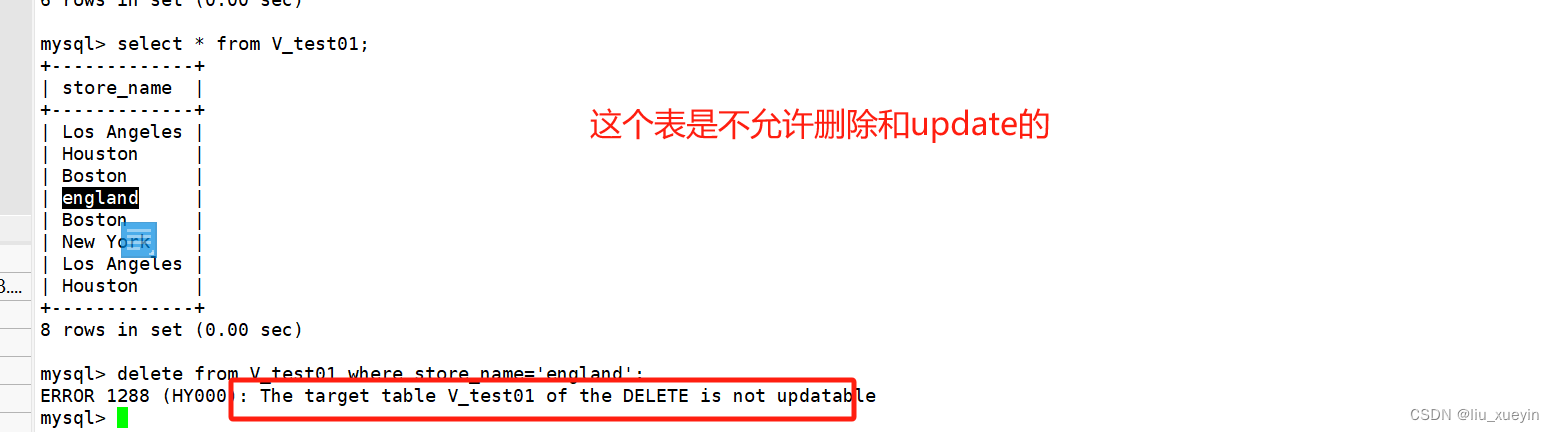
select * from 视图表名称;11.3视图表中的数据是否能修改?(重点)
能不能改看情况!!!
首先视图表的作用是保存select语句的,
通常来讲,select不涉及表数据的处理,那么视图表可以修改,且修改视图表会同时修改原表;
但是如果说select语句中包含有聚合函数,group by等等情况,视图表的数据不能修改,非要修改的话,那就去修改原表吧。。。。
具体哪些不能改,下面是chatgpt的回答

实操演示
 ?模拟修改原表
?模拟修改原表

文章来源:https://blog.csdn.net/liu_xueyin/article/details/135252732
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 源码编译安装Apache
- Aging:这种来源于肉豆蔻的化合物可延缓衰老并显著延长寿命
- 【数据库分库分表思路】
- OpenGauss源码分析-SQL引擎
- Express/mongoose对数据库中密码加密处理
- 华为数通方向HCIP-DataCom H12-831题库(判断题:61-80)
- OWASP漏洞原理<最基础的数据库 第二课>
- 【一】通信协议概述
- 什么是云安全?如何保护云资源
- XXE利用的工作原理,利用方法及防御的案例讲解