【K8S 云原生】Pod资源限制、Pod容器健康检查
目录
一、docker的重启方式和K8S重启方式
1、deployment的重启方式:
Always:无论正常退出还是非正常退出都重启
????????deployment的yaml文件只能是Always
????????pod的yaml三种模式都可以
OnFailure:只有状态码非0才会重启。正常退出是不重启的
Never:正常退出和非正常退出都不重启
容器退出了,pod才会重启
pod可以有多个容器
pod可以有多个容器,只要有一个容器退出,整个pod都是重启,pod内的所有都会重启
2、docker的重启策略:
Never:docker的默认策略,正常退出和非正常退出都不重启
on-Failure:非正常退出时才会重启容器
Always:只要容器退出都是重启
unless-stoped:只要容器退出就会重启,docker守护进程启动时已经停止的容器,不再重启
意思是docker运行时,退出会重启,docker关闭,一并关闭的容器不会重启
单机部署:docker足够了
集群化部署:K8S
二、yaml文件快速生成:
#快速生成pod创建yaml
kubectl create deployment nginx --image=nginx1.22 --replicas=3 --dry-run=client -o yaml > /opt/demo1.yaml
#快速生成service的yaml
kubectl expose deployment nginx --port=80 --target-port=80 --type=NodePort --dry-run=client -o yaml > /opt/demo2.yaml
--dry-run=client:只调用api命令,不创建三、pod的状态:
pending挂起状态:pod已被创建,但是尚未分配到运行他的node节点(1、节点上资源不够? 2、节点上资源不够)
Running运行中:pod已经被分配到了node节点,pod内部的所用容器都已经启动,运行状态正常
competed/successded:容器内部的进程运行完毕正常退出,没有发生错误
failed:pod中的容器非正常退出。发生了错误,需要通过查看详情或者日志定位问题
UNkown:由于某些原因,K8S集群无法获取pod的状态。apiserver出了问题
terminating:终止中,pod正在被删除,里面的容器正在终止。终止过程中,涉及资源回收、垃圾清理、终止过程中需要执行的命令
crashloopbackoff:pod当中的容器退出,kubelet正在重启
imagepullbackoff:正在重试拉取镜像
errimagepull:拉取镜像出错了(1、网速太慢 2、镜像名写错了 3、镜像仓库挂了)
Evicte:pod被驱赶了(node节点的资源不够部署pod,或者是资源不足,kubelet自动选择一个pod驱逐)
InvalidImageName:无法解析镜像名称
ImageInspectError:无法校验镜像
ErrImageNeverPull:策略禁止拉取镜像
RegistryUnavailable: 连接不到镜像中心
CreateContainerConfigError:不能创建kubelet使用的容器配置
CreateContainerError: 创建容器失败
m.internalLifecycle.PreStartContainer 执行hook报错
RunContainerError:启动容器失败
PostStartHookError:执行hook报错
ContainersNotInitialized: 容器没有初始化完毕
ContainersNotReady:容器没有准备完毕
ContainerCreating:容器创建中
PodInitializing:pod初始化中
DockerDaemonNotReady:docker还没有完全启动
NetworkPluginNotReady: 网络插件还没有完全启动
Evicte: pod被驱赶四、Pod的资源限制
1、限制的方式和种类
对pod内的容器使用节点资源的限制:
1、request:pod内容器需要的资源
2、limit:最高能占用系统多少资源
一般在工作中,只做一个limit,需要多少,最多也只能占这么多
两个限制:CPU和内存限制
2、CPU的限制的格式:
①、数字加小数点:1、2、0.5、0.3、0.2、0.1
要么是整数数,要么小数点后只能跟一位
1:占用一个cpu
2:占两个cpu
0.5:半个cpu
0.2:只能使用一个cpu的1/5
0.1:最小的单位,只占用1/10②、m来表示cpu:millicores。1000m、2000m、100m
cpu时间分片原理:通过周期性的轮流分配cpu时间给各个进程。多个进程可以在cpu上交替执行。在K8S中就表示占用cpu的比率
2000m:2个cpu
1000m:1个cpu
500m:半个cpu
100m:最小单位1/10个cpu2、内存的限制:
单位:大写的开头+小写的i
Ki、Mi、Gi、Ti
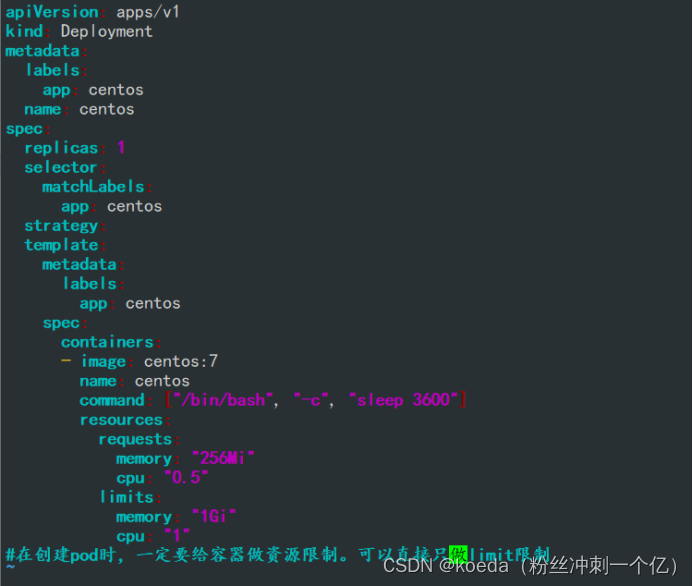
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: centos
name: centos
spec:
replicas: 1
selector:
matchLabels:
app: centos
strategy:
template:
metadata:
labels:
app: centos
spec:
containers:
- image: centos:7
name: centos
command: ["/bin/bash", "-c", "sleep 3600"]
resources:
requests:
memory: "256Mi"
cpu: "0.5"
limits:
memory: "1Gi"
cpu: "1"
#在创建pod时,一定要给容器做资源限制。可以直接只做limit限制
stress压力测试工具
超过资源限制,进程会被立即杀死
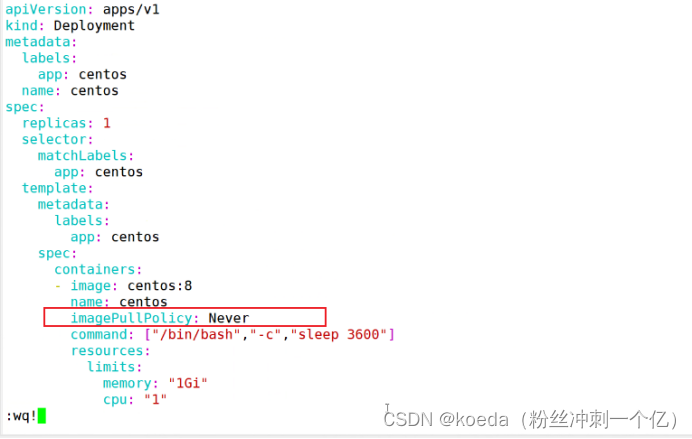
五、K8S拉取镜像的策略:
ifNotPresent:默认策略,如果本地镜像有,就不在拉取,本地没有就去镜像仓库拉取
Always:无论镜像是否存在,创建时(包括重启时)都会重新拉取镜像
Never:仅仅使用本地镜像
如果没有特殊需求,默认即可,不用配置
都还是本地部署,用Never即可
如果涉及到外部部署,默认策略即可(事前要把docker的镜像导入到目标主机)
Always:一般不用
六、pod内的容器的健康检查—探针:
1、探针:probe
是K8S对容器执行的定期检查诊断
探针都是对容器进行操作
所有的探针策略伴随整个pod的生命周期。除了启动探针。
2、探针种类:
1.1、存活探针:livenessProbe
探测容器是否正常运行,如果发现探测失败,会杀掉容器,容器会根据重启策略来决定是否重启。不是杀掉pod,只是对容器操作。特点就是杀死容器,重启
1.2、就绪探针
探测容器是否进入ready状态,并且做好接收请求的准备。
探测失败 进入READY 0/1状态,无法接受请求,没有进入ready状态。service会把这个资源对象的端点endpoints从当中剔除,service也不会把请求转发到这个pod
1.3、启动探针
只是在容器的启动后开始检测,容器内的应用是否启动成功。在启动探测成功之前,所有的其他探针都会处于禁用状态,一旦启动探针结束,后续的操作不再受启动探针的影响
在一个容器中可以有多个探针,也可以只有一个探针
3、probe的检查方法:
以上三种探针都能用下面的检查方式
3.1、exec:
在容器内部执行命令,如果命令的返回码是0,表示成功
适用于需要在容器内自定义命令来检查容器的健康状态的情况
3.2、httpGet:
对指定ip+端口的容器发送一个httpget的请求。响应状态码在200-400
内都是成功 200<= X <400 之间都算成功
适用于检查容器能否响应http的请求,web容器(nginx、Tomcat等)
3.3、tcpSocket:
检查端口,对指定端口上的容器的IP地址进行tcp检查(三次握手),端口打开,认为探测成功。否则都是失败
用于检查特定容器的端口监听状态
类似于telnet 192.168.233.30 80 检查80端口是否正常
诊断结果:
1、成功:容器通过了,正常运行
2、失败:失败了只有存活探针会重启
3、未知:诊断失败
七、livenessProbe存活探针健康监测实例:
1、存活探针的exec检查方式:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: centos
name: centos
spec:
replicas: 1
selector:
matchLabels:
app: centos
strategy:
template:
metadata:
labels:
app: centos
spec:
containers:
- image: centos:7
name: centos
command: ["/bin/bash", "-c", "touch /opt/123.txt ; sleep 3600"]
livenessProbe:
exec:
command: ["/usr/bin/test" , "-e", "/opt/123.txt"]
#检测/opt/123.txt文件是否存在,存在则检测成功
initialDelaySeconds: 3
#表示容器启动之后多少秒来进行探测,时间不要设置的太短,否则容器没启动就开始探测,无效探测
periodSeconds: 2
#表示探针探测的间隔时间。每隔多少秒进行一次检查。范围是看应用的延迟敏感度。非常重要的核心组件,间>
隔设置小一点
failureThreshold: 2
#如果探测失败,失败几次之后,把容器标记为不健康。
successThreshold: 1
#只要成功一次就标记为就绪、健康、ready。这里的值只能是1,所以这项可以不加
timeoutSeconds: 1
#表示每次探测的超时时间,这个时间要比间隔时间小,意思是在1秒内要完成探测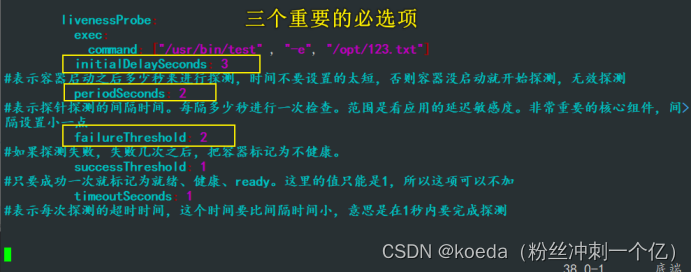

删除文件,模拟探针检测失效
kubectl exec -it centos-797bc57596-dcvzh -- rm -rf /opt/123.txt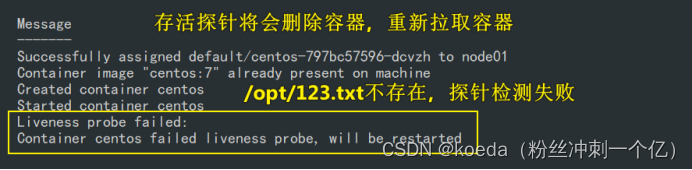
这里重新拉取容器之后,因为command,/opt/123.txt会自动生成,所以拉取一次,容器又Running了
2、存活探针的httpGet检查方式:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx:1.22
name: nginx
livenessProbe:
httpGet:
scheme: HTTP
port: 80
initialDelaySeconds: 4
periodSeconds: 2

用Tomcat测试:
apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- image: tomcat:8.0.52
name: tomcat
livenessProbe:
httpGet:
scheme: HTTP
port: 8080
path: /index.html
initialDelaySeconds: 4
periodSeconds: 2
#相当于访问http://ip/index.html
将path改成 index.jsp
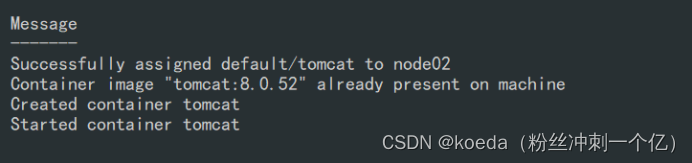

3、存活探针的tcpSocket检查方式:
kind: Pod
metadata:
name: tcp-tomcat
spec:
containers:
- image: tomcat:8.0.52
name: tcp-tomcat
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 4
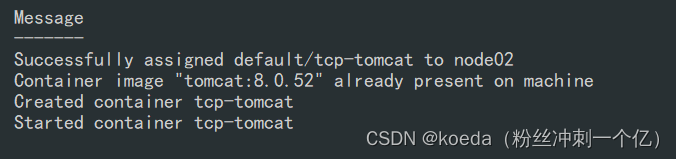
periodSeconds: 2检测端口8080,端口打开表示检测成功:
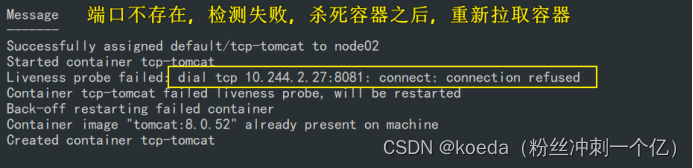
将端口改成8081:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 当 ChatGPT 有了身体会怎样?《Nature》预测 2024 科技大事丨 RTE 开发者日报 Vol.112
- GBASE南大通用-Command 属性
- android APP修改为鸿蒙APP
- C++知识补充(一)
- Android安卓打包app应用程序编译shrinkResources true报错解决方案
- 如何在 Ubuntu 20.04 上安装 Apache Kafka
- 管理篇 - 9到13
- 参照oracle按名称排序,用js在前端对附件封装排序方法
- node.js和浏览器之间的区别
- Redis:原理速成+项目实战——Redis实战8(基于Redis的分布式锁及优化)