Redis 给集合元素单独设置过期
其他系列文章导航
文章目录
前言
Redis 是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息代理。
在 Redis 中,集合(Set)是一种无序的数据类型,用于存储不重复的字符串元素。
虽然 Redis 的集合本身不支持为每个元素单独设置过期时间,但你可以通过一些技巧和策略来实现类似的功能。
一、场景
1.1?消费队列
最近,朋友在使用 Redis 时,脑中闪过一个创新的想法。他想用 Redis 的基础数据结构来构建一个简单版的延迟消费队列。
对于这个业务需求,我们需要设计一个状态图:
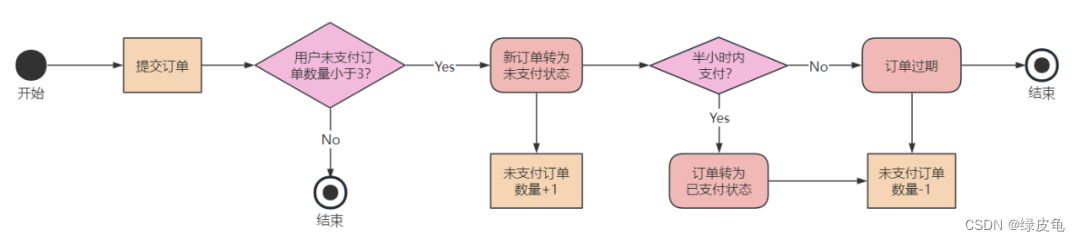
同时,我们需要确保队列的长度始终处于控制之中,例如,我们只允许用户拥有最多3个未支付的订单。
1.2 Redis实现
Redis,这款高性能的缓存和数据存储数据库,已经成为了后台开发者的得力助手。
假如我们要用 Redis 作为消费队列,我们可以考虑使用 List、Hash 和 Set 这三种数据结构。在这个业务场景中,由于我们主要关注的是 orderId(订单 ID),所以这三种数据结构都可以满足我们的需求。

例如,使用 hash 数据结构来存储数据时,我们可以设置 key 为 UnpaidOrder-{userId},然后每个 field 对应一个订单。
然而,现在我们面临一个挑战:每个订单的存活时间不同,有手动消费和定期删除两种逻辑。
- 订单1,如果手动支付,需要从列表中删除 orderId1;
- 订单2,如果在半小时内未支付,就会自动过期,用户还可以继续提交订单到未支付状态。
这就意味着在 List、Set 或者 Hash 这三种结构中,每个 field 都需要设置单独的过期时间。
这是一个常见而又棘手的问题,本文将从互联网业务中常见的解决方案入手,深入探讨一下 Redis 的底层实现。
二、常见的方案
在开发过程中,我们经常会遇到一种情况:需要计算某些特定字段的数量,而这些字段的生存时间又各不相同。
比如说,我们需要在业务中计算用户的未支付订单数,但是每个订单的过期时间都不相同。
在这种情况下,我们需要手动删除已经过期的字段,或者设置它们自动过期。
2.1 为单独的 field 设置过期
Redis 里面暂时没有接口给 List、Set 或者 Hash 的 field 单独设置过期时间,只能给整个列表、集合或者 Hash 设置过期时间。
这样,当 List/Set/Hash 过期时,里面的所有 field 元素就全部过期了。
但这样并不满足需求。
除非你同时把 field 和过期时间都存下来,然后在程序里面判断它是否过期。
2.2?设置整体过期时间
我们首先可以考虑给整个 List/Set/Hash 设置过期时间。
这很难满足每个字段单独设置过期时间的需要。
既然每个订单的过期时间都不同,我们是否可以根据时间来创建不同的集合,将同一时间过期的订单放在同一个集合中:

然后,我们可以分别为不同的集合设置 TTL。当订单过期未支付时,订单会随着集合的过期而在同一分钟内被删除。
然而,这种方法也存在一些问题。每次新增订单时,我们需要遍历过去30分钟的集合,检查是否有该用户的订单,并判断用户的未支付订单数是否超限。
此外,按分钟创建集合可能存在一个问题:用户的订单可能在01秒就过期了,但在59秒才被删除。
如果按秒创建集合,30分钟将需要创建1800个集合,这使得管理变得更加困难。因此,为集合设置整体过期时间并不是一个可行的解决方案。
2.3 zset 结合 score实现
除了常见的 List/Set/Hash 结构,Redis 还拥有一个专门用于排序的数据结构 zset(Sorted Set,排序集合)。
基于 Redis 的 Zset 结构,我们可以利用 Score 来表示过期时间,从而轻松实现每个字段的独立过期。

具体实现方法如下:
- 每次新增待支付订单时,我们将当前时间的 Unix timestamp 加上过期时间 30min 作为 score 设置为该元素。这样,sorted set 会根据这个过期时间戳对元素进行排序和存储。
- 当订单被支付后,根据 userId 和 orderId 删除 sorted set 中的待支付订单。
- 同时,在程序中添加一个定时任务,每隔一秒删除当前时间已过期的订单。
2.4 底层实现
用 Redis 的 zset 一方面可以很方便地实现了对每个字段的单独过期,不再受整个 Key 的过期时间限制,提高了灵活性。
另一方面,Redis 的 zset 操作是十分高效的,不会给系统带来显著的性能压力。
这得益于 zset 底层的数据结构,Zset 底层实现采用了 ZipList(压缩列表)和 SkipList(跳表)两种实现方式,当满足:
-
Zset 中保存的元素个数小于 128(可通过修改 zset-max-ziplist-entries 配置来修改)
-
Zset 中保存的所有元素长度小于 64byte(通过修改 zset-max-ziplist-values 配置来修改)
两个条件时,Zset 采用 ZipList 实现;否则,用 SkipList 实现。
2.4.1?ZipList 实现

ZipList是一个数组的形式,存储数据时分为列表头部分和数据部分,列表头部分有 3 个元素:
zlbytes:表示当前 list 的存储元素的总长度
zllen:表示当前 list 存储的元素的个数
zltail:表示当前 list 的头结点的地址,通过 zltail 就是可以实现 list 的遍历
数据部分以键值对的方式依次排列,键存储的是实际
member,值存储的是 member 对应的分值(score)。
2.4.2?SkipList 实现?
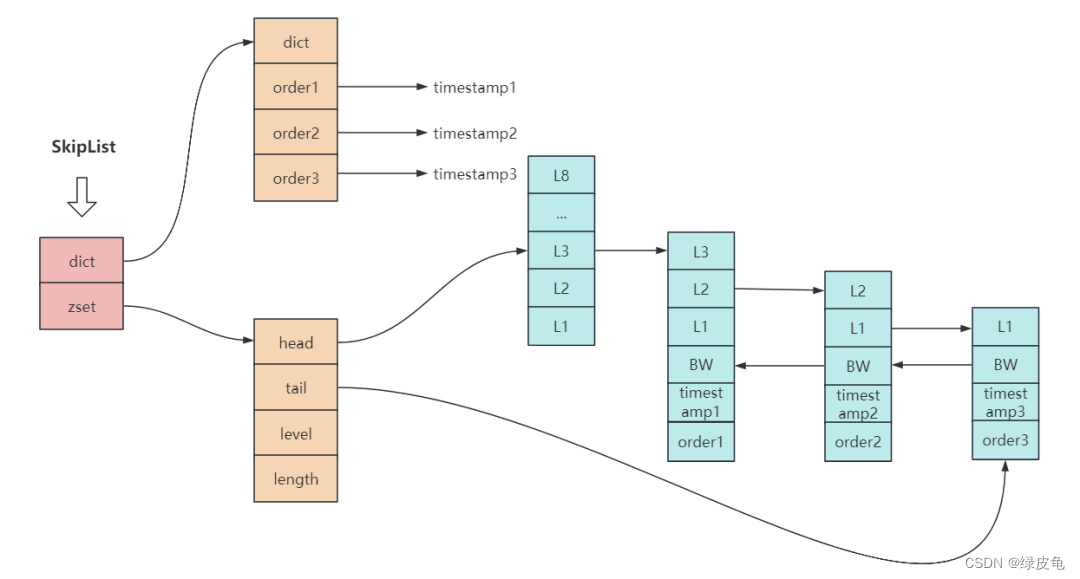
SkipList 分为两部分:
-
dict 部分是由字典实现(其实就是 HashMap,里面放了成员到 score 的映射);
-
zset 部分使用跳跃表实现(存放了所有的成员,解决了 HashMap 中 key 无序的问题)。
从图中可以看出,dict 和 zset 都存储数据。
但实际上 dict 和 zset 最终使用的指针都指向了同一份成员数据,即数据是被两部分共享的,为了方便表达将同一份数据展示在两个地方。
2.5 代码实现
当我们插入一个过期时间到 zset 时,Redis 会自动帮我们排好序,我们只需要在程序中新增一个定时任务,比如:每秒执行一次删除任务,删除时间戳从 0 到当前时间戳的 score 值即可。
伪代码如下:
# 1. 创建新的待支付订单时,查询zset个数
count = zcard UnpaidOrder-{userId}
# 2. 判断未支付订单个数
if count >= 3:
return
# 3. 新增订单
zadd UnpaidOrder-{userId} redis.Z{Score: {timestamp1}, Member: {order1}}
# 4.1 订单支付后,从 set 中删除未支付订单
zrem UnpaidOrder-{userId} order1
# 4.2 过期时间到了,从 set 中删除未支付订单
zremrange UnpaidOrder-{userId} 0 {current_timestamp}三、总结
通过合理的数据结构选择和巧妙的应用,我们成功地解决了为 List、Set 和 Hash 结构中的字段设置单独过期时间的问题。
这个方案在实际项目中得到了验证,并取得了显著的效果。
对比其它的延时队列,或者 etcd 的 field 过期方案,Redis 的实现相对而言更为便捷,理解起来也更为简单。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【蓝桥杯选拔赛真题31】C++数位求和 第十三届蓝桥杯青少年创意编程大赛C++编程选拔赛真题解析
- Drools 规则属性讲解(结合代码实例讲解)
- 【Python可视化系列】一文教你绘制不同类型的散点图(理论+源码)
- 【Docker光速搞定深度学习环境配置!】
- 并发代码中的错误处理挑战
- Android Telephony概览
- vscode格式化python代码
- FreeRTOS学习——信号量
- mysql原理--undo日志2
- 小米行车记录仪mp4文件修复案例