深度神经网络中的混合精度训练
Mixed-Precision Training of Deep Neural Networks | NVIDIA Technical Blog
目录
深度神经网络 (DNN) 在许多领域取得了突破,包括图像处理和理解、语言建模、语言翻译、语音处理、游戏等。为了实现这些结果,DNN 的复杂性一直在增加,这反过来又增加了训练这些网络所需的计算资源。混合精度训练通过使用较低精度的计算(FP16)来降低所需的资源,这具有以下优点。
- 减少所需的内存量。半精度浮点格式 (FP16) 使用 16 位,而单精度 (FP32) 使用 32 位。降低所需的内存可以训练更大的模型或使用更大的小批量进行训练。
- 缩短训练或推理时间。执行时间可能对内存或算术带宽敏感。半精度将访问的字节数减半,从而减少了在内存受限层中花费的时间。与单精度相比,NVIDIA GPU 的半精度算术吞吐量提高了 8 倍,从而加快了数学受限层的速度。
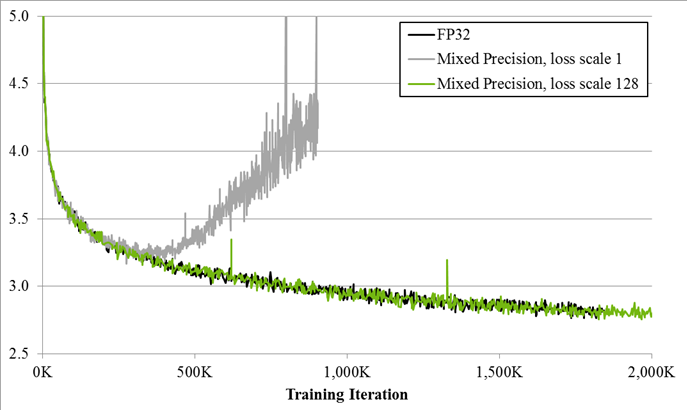
图 1.大型LSTM?英语语言模型的训练曲线显示了本文中描述的混合精度训练技术的好处。Y 轴是训练损失。不带损耗缩放的混合精度(灰色)在一段时间后会发散,而带损耗缩放的混合精度(绿色)与单精度模型(黑色)匹配。
由于 DNN 训练传统上依赖于 IEEE 单精度格式,因此本文的重点是半精度训练,同时保持单精度实现的网络精度(如图 1 所示)。这种技术称为混合精度训练,因为它同时使用单精度和半精度表示。
混合精度成功训练的技术
半精度浮点格式由 1 个符号位、5 个指数位和 10 个小数位组成。支持的指数值属于 [-24, 15] 范围,这意味着该格式支持 [2-24,65,504]范围。由于这比 [2-149, ~3.4×1038] 范围支持单精度格式,训练某些网络需要额外考虑。本节介绍了成功训练半精度 DNN 的三种技术:将 FP16 产品累积到 FP32 中;损失缩放;以及砝码的 FP32 主副本。借助这些技术, NVIDIA 和百度研究院能够匹配所有经过训练的网络的单精度结果准确性(混合精度训练)。请注意,并非所有网络都需要使用所有这些技术进行训练。
有关如何在各种框架中应用这些技术的详细说明,包括可用的代码示例,请参阅混合精度训练用户指南。
FP32 累加
NVIDIA Volta GPU 架构引入了 Tensor Core 指令,该指令将半精度矩阵相乘,将结果累积为单精度或半精度输出。我们发现,累积到单个精度对于获得良好的训练结果至关重要。累积值在写入内存之前转换为半精度。cuDNN 和 CUBLAS 库提供了多种依赖于 Tensor Core 进行算术运算的函数。
损失缩放 loss scaling
训练 DNN 时会遇到四种类型的张量:激活、激活梯度、权重和权重梯度。根据我们的经验,激活、权重和权重梯度落在半精度表示的值大小范围内。然而,对于某些网络,小幅度激活梯度低于半精度范围。例如,考虑图 2 中训练 Multibox SSD 检测网络时遇到的激活梯度直方图,该直方图显示了 log2 刻度上值的百分比。小于 2-24 的值在半精度格式中变为零。
请注意,激活梯度不使用大多数半精度范围,激活梯度往往是幅度小于 1 的小值。因此,我们可以通过将激活梯度乘以比例因子?S?来将它们“移位”到 FP16 表示的范围内。在SSD网络的情况下,将梯度乘以8就足够了。这表明激活梯度值小于 2-27与该网络的训练无关,而保留 [2-27, 2-24) 范围。
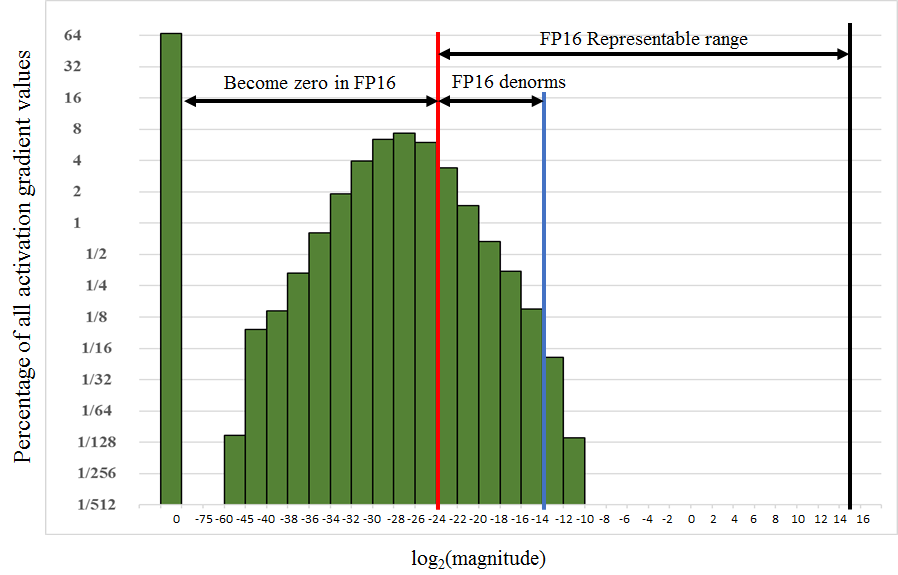
图2.以单精度训练 Multibox SSD 检测器网络时记录的激活梯度直方图。Y 轴是对数刻度上所有值的百分比。X 轴是绝对值的对数刻度,也是零的特殊条目。例如,在此培训课程中,66.8% 的值为零,而 4% 的值介于 2 之间-32和 2-30.
确保梯度落入半精度表示的范围内的一种非常有效的方法是将训练损失乘以比例因子。这仅增加了一次乘法,并且通过链式规则,它确保所有梯度都按比例放大(或向上移动),而无需额外费用。损失缩放可确保恢复丢失到零的相关梯度值。在权重更新之前,权重梯度需要按相同的因子?S?缩小。缩减操作可以与权重更新本身融合(导致没有额外的内存访问)或单独执行。有关详细信息,请参阅《混合精度训练用户指南》和《混合精度训练》白皮书。
FP32 Master?Copy of Weights
DNN 训练的每次迭代都会通过添加相应的权重梯度来更新网络权重。权重梯度幅度通常明显小于相应的权重,尤其是在与学习率相乘(或Adam或Adagrad等优化器的自适应计算因子)相乘之后。如果其中一个加法太小而无法产生半精度表示差异,则此幅度差异可能导致不会发生更新(例如,由于指数差大,较小的加法在移位以对齐二进制点后变为零)。
对于以这种方式丢失更新的网络,一个简单的补救措施是以单精度维护和更新权重的主副本。在每次迭代中,都会制作一个主权重的半精度副本,并将其用于正向和反向传播,从而获得性能优势。在权重更新期间,计算出的权重梯度将转换为单精度,并用于更新主副本,并在下一次迭代中重复该过程。因此,我们只在需要的地方将半精度存储与单精度存储混合使用。
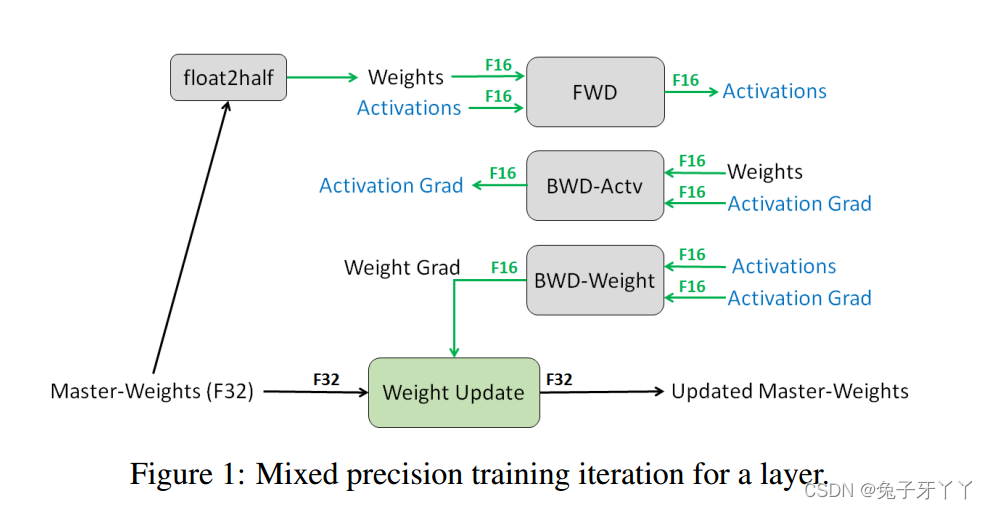
混合精度训练迭代过程
上面介绍的三种技术可以组合到每个训练迭代的以下步骤序列中。对传统迭代过程的补充以粗体显示。
- 制作权重的 FP16 副本
- 使用 FP16 权重和激活进行前向传播
- 将产生的损失乘以比例因子?S
- 使用 FP16 权重、激活及其梯度向后传播
- 将权重梯度乘以 1/S
- (可选)处理权重梯度(梯度裁剪、权重衰减等)
- 更新 FP32 中权重的主副本
AMP混合精度训练介绍
AMP(Automatic mixed precision):自动混合精度,该方法在训练网络时将单精度(FP32)与半精度(FP16)结合在一起,它使用FP16即半精度浮点数存储和计算,从而实现节省显存和加快训练速度的目的。
常用的两种实现amp的方式:
- NVIDIA Apex使用apex.amp?(O1模式开启自研kernel会出现Nan值,禁用自研kernel之后没有Nan值;O2没有Nan值)
- Pytorch 1.6版本后自带torch.cuda.amp (开启自研kernel 也会出现Nan值;禁用自研kernel之后没有Nan值)
FP16和FP32的区别
FP16和FP32在计算机的不同存储方法:
半精度浮点数 (FP16):?计算机使用 2 字节 (16 位) 存储,表示范围为?[5.9e-8,65504]
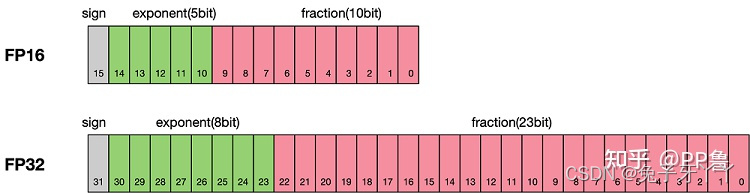
单精度浮点数 (FP32)?:计算机使用 4 字节 (32 位) 存储,表示范围为?[1.4e-45,3.4e38],FP32 能够表示的范围要比 FP16 大的多得多。

FP16的优势
默认情况下,大多数深度学习框架都采用FP32进行训练。相比与FP32,FP16具有一下优势:
- 1.减少显存占用,这使得我们可以用更大的 batch size
- 2.加快训练和推断的计算
- 3.NVIDIA Tensor Core支持
FP16的问题
如果我们简单地把模型权重和输入从 FP32 转化成 FP16,虽然可以加快速度,但是模型的精度会被严重影响,原因如下:
- 1. 溢出错误:由于FP16的动态范围比FP32位的狭窄很多,因此,在计算过程中很容易出现上溢出和下溢出,溢出之后就会出现"NaN"的问题。
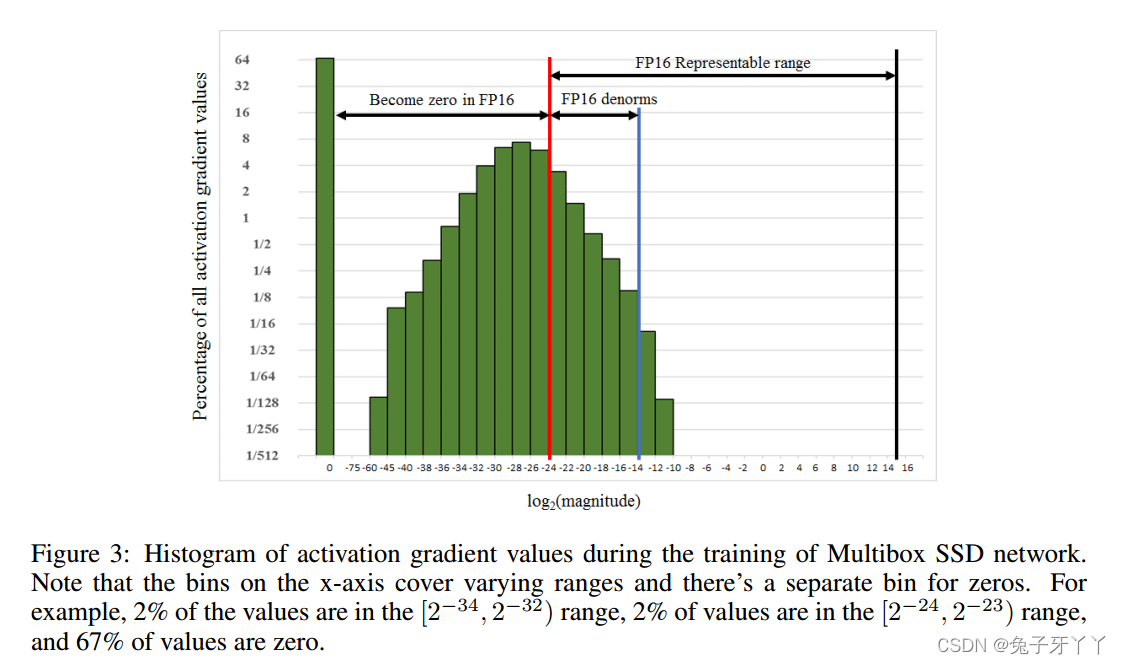
Multibox SSD网络训练过程中激活梯度值的直方图。2%的值在[2?34,2?32)范围内,2%的数值在[2–24,2?23)范围内,以及67%的数值为零。
-
- 2. 舍入误差:当梯度过小时,小于当前区间内的最小间隔时,该次梯度更新可能会失败

解决P16的精度问题策略
论文里提到下面三个策略:Micikevicius, Paulius, Sharan Narang, et al. “Mixed Precision Training.” ArXiv:1710.03740 [Cs, Stat], February 15, 2018.?https://arxiv.org/abs/1710.03740
1、混合精度计算
在内存中用FP16做储存和乘法从而加速计算,而用FP32做累加避免舍入误差。混合精度训练的策略有效地缓解了舍入误差的问题。
2、损失缩放(Loss scaling)
为了解决下溢出的问题,对计算出来的 loss 值进行缩放 (scale),由于链式法则的存在,对 loss 的缩放会作用在每个梯度上,这些梯度会平移到 FP16 的有效范围内。这样就可以用 FP16 存储梯度而又不会溢出了。此外,在进行更新之前,需要先将缩放后的梯度转化为 FP32,再将梯度反缩放(unscale)回去。?
反向传播前:将loss手动增大缩放因子 (loss_scale)倍
反向传播后:将权重梯度缩小缩放因子 (loss_scale)倍,恢复正常值
3、权重备份
将模型权重、激活值、梯度等数据用?FP16?来存储,同时维护一份?FP32?的模型权重副本(master-weight)用于更新。前向使用FP16,在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。
尽管与单精度训练相比,保持额外的权重副本会使权重的内存需求增加50%,但对整体内存使用的影响要小得多。对于训练来说,由于更大的batch size和每层的输出值被保存以在反向传播过程中重复使用,因此内存消耗主要由这些输出值决定。由于输出值也以半精度格式存储,因此训练深度神经网络的总内存消耗大致减半。
Apex
代码格式
APEX中,用户不需要手动将模型或数据类型转换为.half(),只需要从现有的默认 (FP32) 脚本开始,添加与 Amp API 对应的三行,然后就可以使用混合精度进行训练。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
不同的训练模式说明
NVIDIA的APEX混合精度库为例,里面提供了多种策略,可以根据不同的场景进行使用:
-
opt_level:O0(纯FP32),O1和O2是混合精度的不同实现,O3(纯FP16),还有O4,O5使用BFLOAT16
-
cast_model_type:将模型的参数转换为所需的类型。
-
patch_torch_functions:patch所有 Torch 函数和 Tensor 方法以执行 Tensor Core 友好的操作,例如 FP16 中的 GEMM 和卷积,以及任何受益于 FP32 中的 FP32 精度的操作。
-
keep_batchnorm_fp32:将 batchnorm 权重保持在 FP32 ,模型的其余部分是 FP16。
-
master_weights:保持 FP32 权重。
-
loss_scale:float值 or "dynamic"(自适应调整损失比例)。动态损失放大(dynamic loss scaling),为了充分利用FP16的范围,缓解舍入误差,将loss*loss_scale。如果产生上溢出,则跳出参数更新,缩小放大倍数使其不溢出。在2000步后再尝试使用大的scale来充分利用FP16的范围。
蓝色为默认值
| opt_level | O0 | O1 | O2 | O3 |
|---|---|---|---|---|
| cast_model_type | torch.float32 | None | torch.float16 | torch.float16 |
| patch_torch_functions | False | True | False | False |
| patch_torch_functions_type | None | torch.float16 | None | None |
| keep_batchnorm_fp32 | None | None(自动设为TRUE) | True | False |
| master_weights | False | None | True | False |
| loss_scale | 1.0 | "dynamic" | "dynamic" | 1.0 |
O0?纯FP32
纯FP32训练,可作为accuracy的baseline
O1?混合精度
- 权重为FP32
- 前向:对Pytorch func和Tensor method进行自动转换,根据黑白名单自动决定使用FP16(GEMM,卷积),还是FP32(softmax)进行计算。
- 白名单函数强制 FP16(将conv的input,weight,bias转换为FP16类型),黑名单函数使用FP32。
- 其余函数则根据参数类型自动判断,如果参数都是 FP16,则以 FP16 运行,如果有一个参数为 FP32,则以 FP32 运行。?对于那些在 FP16 环境中运行不稳定的模块,我们会将其添加到黑名单中,强制它在 FP32 的精度下运行。
- 动态损失缩放(dynamic loss scaling)
O1步骤:
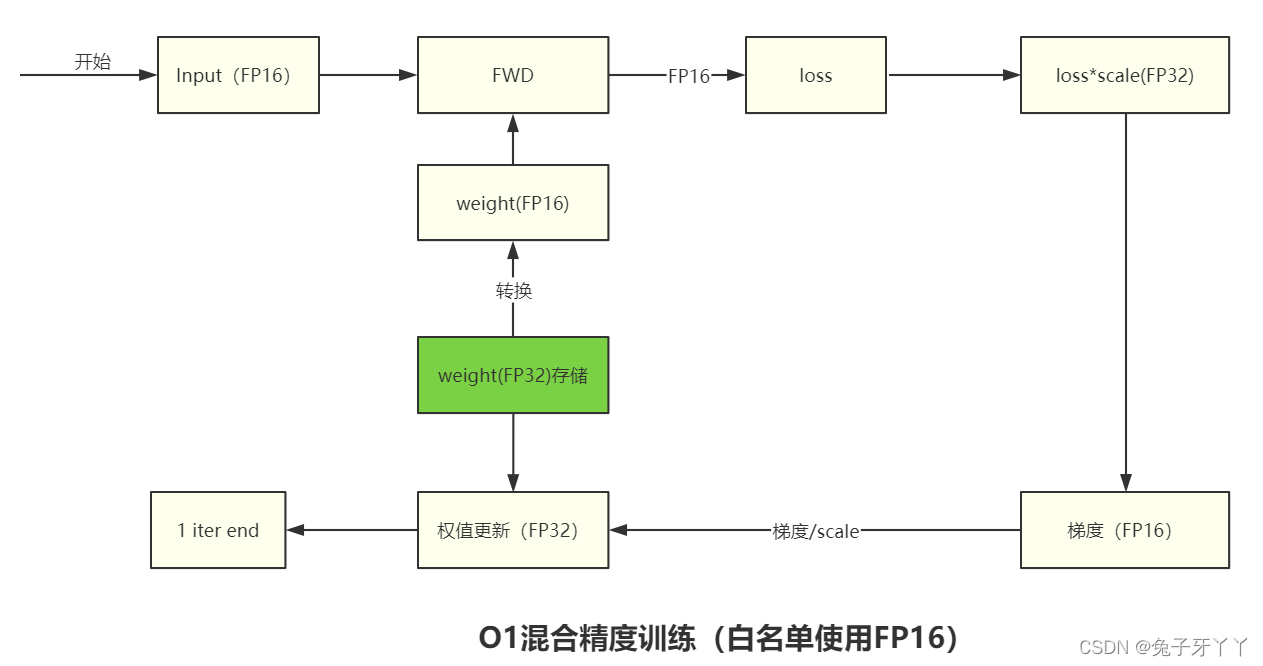
- 根据黑白名单对 PyTorch 内置的函数和一些tensor进行包装?
- ?将 loss_scale 初始化为一个很大的值?
- ?对于每次迭代?
- (a). 前向传播:按照黑白名单自动选择数据类型进行计算。 白名单:拷贝FP32模型并且转换成 FP16 进行计算
- (b). 将 loss 乘以 loss_scale
- (c). 反向传播: 计算出梯度FP16
- (d). 将梯度 unscale ,即除以 loss_scale?
- (e).?每次更新前检查溢出问题(检查梯度中有没有
inf和nan),如果检测到 inf 或 nan
? ? ? ? ? ? ? ? ? ? ? i. loss_scale /= 2
? ? ? ? ? ? ? ? ? ? ? ii. 跳过此次更新
- (f). optimizer.step(),利用 FP16 的梯度更新 FP32 的模型参数
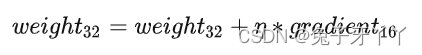
- (g). 如果连续2000次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
以?nn.Linear?为例, 这个模块有两个权重参数?weight?和?bias,输入为?input,前向传播就是调用了?torch.nn.functional.linear(input, weight, bias),对于白名单来说,就是把权重参数?weight?和?bias和input转换为 FP16再进行计算。
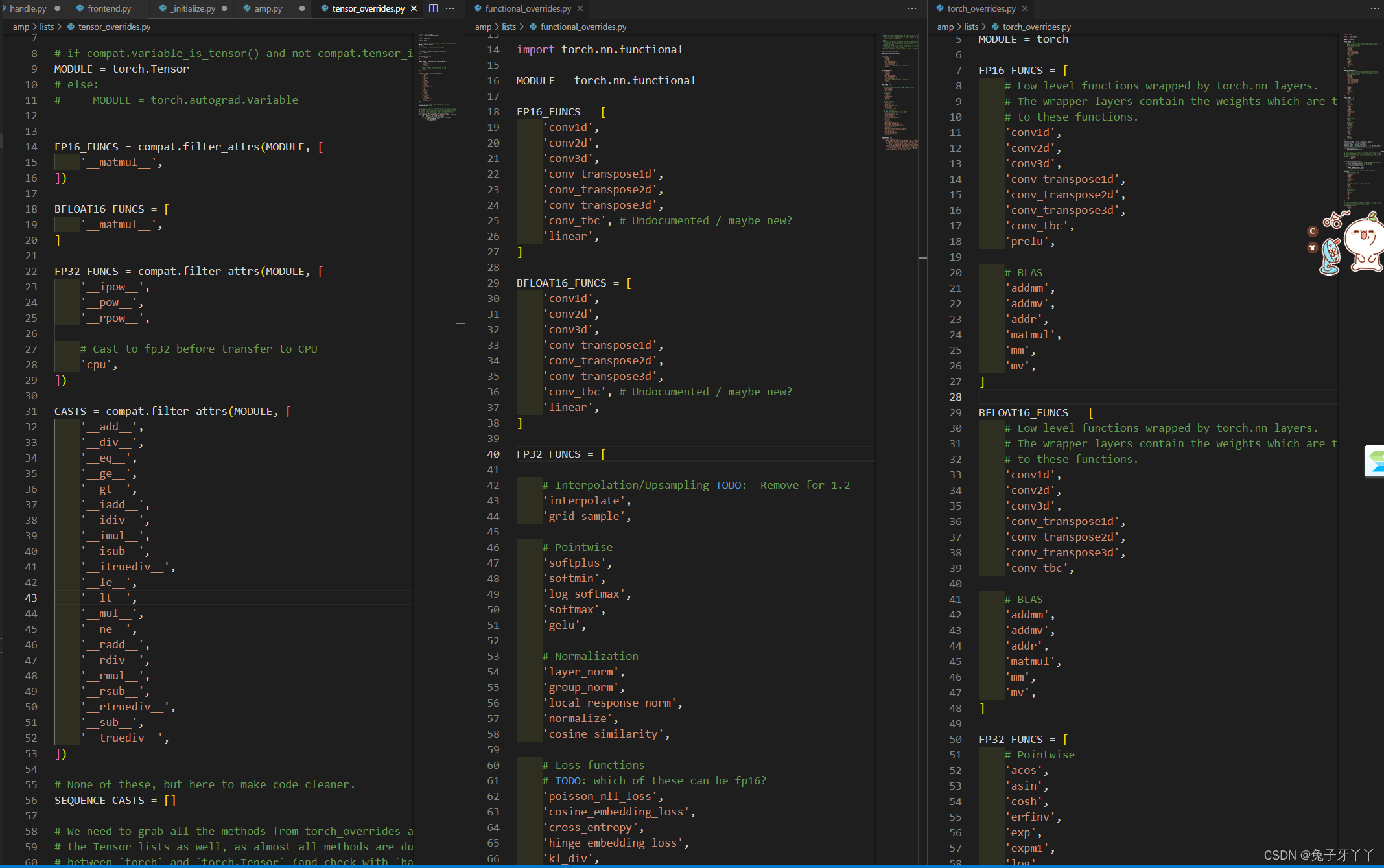
黑白名单
lists里有三个文件:functional_overrides.py,tensor_overrides.py,torch_overrides.py分别定义了黑白名单(FP16/FP32的适用情况)
O2混合精度
- 除了 BN 层以外的模型权重为 FP16
- 创建一个FP32的权重副本
O2步骤:
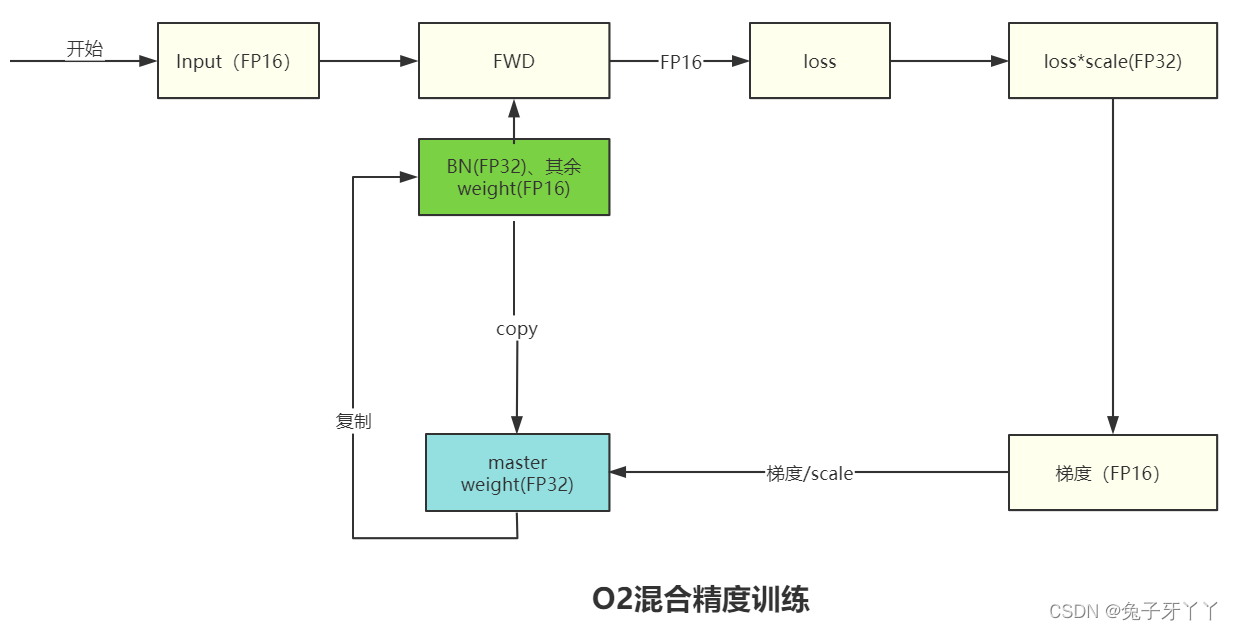
- 将除了 BN 层以外的模型权重和梯度转化为 FP16,输入类型也转化为 FP16,模型输出类型不设置为FP32;
- 维护一个 FP32 的模型权重副本用于更新
- 将 loss_scale 初始化为一个很大的值;
- 对于每次迭代
- (a). 前向传播: 除了 BN 层权重是 FP32,模型其它部分都是 FP16,得到FP32的loss
- (b). 将 loss 乘以 loss_scale转换为FP16
- (c). loss反向传播,计算得到 FP16 的梯度?
- (d). 将 FP16 梯度转化为 FP32,并unscale
- (e). 如果检测到梯度 inf 或 nan
? ? ? ? ? ? ? ? ? i. loss_scale /= 2
? ? ? ? ? ? ? ? ? ii. 跳过此次更新
- (f). optimizer.step(),利用 FP16 的梯度更新 FP32 的模型参数
- sgd中params[i].add_(grads[i],?alpha=-lr)FP32+FP16=FP32
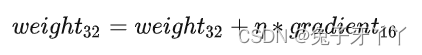
- (g). 如果连续2000次迭代都没有出现 inf 或 nan,则 loss_scale *= 2
O3纯FP16
纯FP16来当速度的baseline
torch.cuda.amp
PyTorch 从 1.6 以后开始支持amp,即torch.cuda.amp module,类似于apex的O1模式:
torch.cuda.amp?给用户提供了较为方便的混合精度训练机制,“方便”体现在两个方面:
1.amp 会自动为算子选择合适的数值精度(FP32、FP16)
该名单在 torch\testing\_internal\autocast_test_lists.py里定义
- CUDA Ops that can autocast to?float16
__matmul__,?addbmm,?addmm,?addmv,?addr,?baddbmm,?bmm,?chain_matmul,?multi_dot,?conv1d,?conv2d,?conv3d,?conv_transpose1d,?conv_transpose2d,?conv_transpose3d,?GRUCell,?linear,?LSTMCell,?matmul,?mm,?mv,?prelu,?RNNCell - CUDA Ops that can autocast to?float32
__pow__,?__rdiv__,?__rpow__,?__rtruediv__,?acos,?asin,?binary_cross_entropy_with_logits,?cosh,?cosine_embedding_loss,?cdist,?cosine_similarity,?cross_entropy,?cumprod,?cumsum,?dist,?erfinv,?exp,?expm1,?group_norm,?hinge_embedding_loss,?kl_div,?l1_loss,?layer_norm,?log,?log_softmax,?log10,?log1p,?log2,?margin_ranking_loss,?mse_loss,?multilabel_margin_loss,?multi_margin_loss,?nll_loss,?norm,?normalize,?pdist,?poisson_nll_loss,?pow,?prod,?reciprocal,?rsqrt,?sinh,?smooth_l1_loss,?soft_margin_loss,?softmax,?softmin,?softplus,?sum,?renorm,?tan,?triplet_margin_loss - CUDA Ops that promote to the widest input type
这些操作不需要特定的 dtype 来保持稳定性,但需要多个输入并要求输入的 dtype 匹配。如果所有输入都是?float16,则运算在 中运行float16。如果任何输入是float32,autocast 将所有输入转换为float32并运行 op in?float32。
addcdiv addcmul_?atan2_?bilinear_?cross_?dot_?grid_sample_?index_put_?scatter_add_?tensordot
2.amp 提供了loss_scaling 操作 ,为了防止下溢,将loss乘以一个比例因子,并对缩放后的loss反向传播,然后将梯度除以相同的比例因子

代码格式:
|
|
参考连接
nvidia apex官方文档:?Apex (A PyTorch Extension) — Apex 0.1.0 documentation
Micikevicius, Paulius, Sharan Narang, et al. “Mixed Precision Training.” ArXiv:1710.03740 [Cs, Stat], February 15, 2018.?https://arxiv.org/abs/1710.03740
torch.amp文档? https://pytorch.org/docs/stable/amp.html#
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!