【C语言深度剖析——第四节(关键字4)】《C语言深度解剖》+蛋哥分析+个人理解
追求本质,不断进步
本文由@睡觉待开机原创,转载请注明出处。
本内容在csdn网站首发
欢迎各位点赞—评论—收藏
如果存在不足之处请评论留言,共同进步!
这里写目录标题
前言:
本节博客继续前篇内容进行续写,我们着重探求有符号与无符号数的问题,探求整形在内存中的存储这一课题
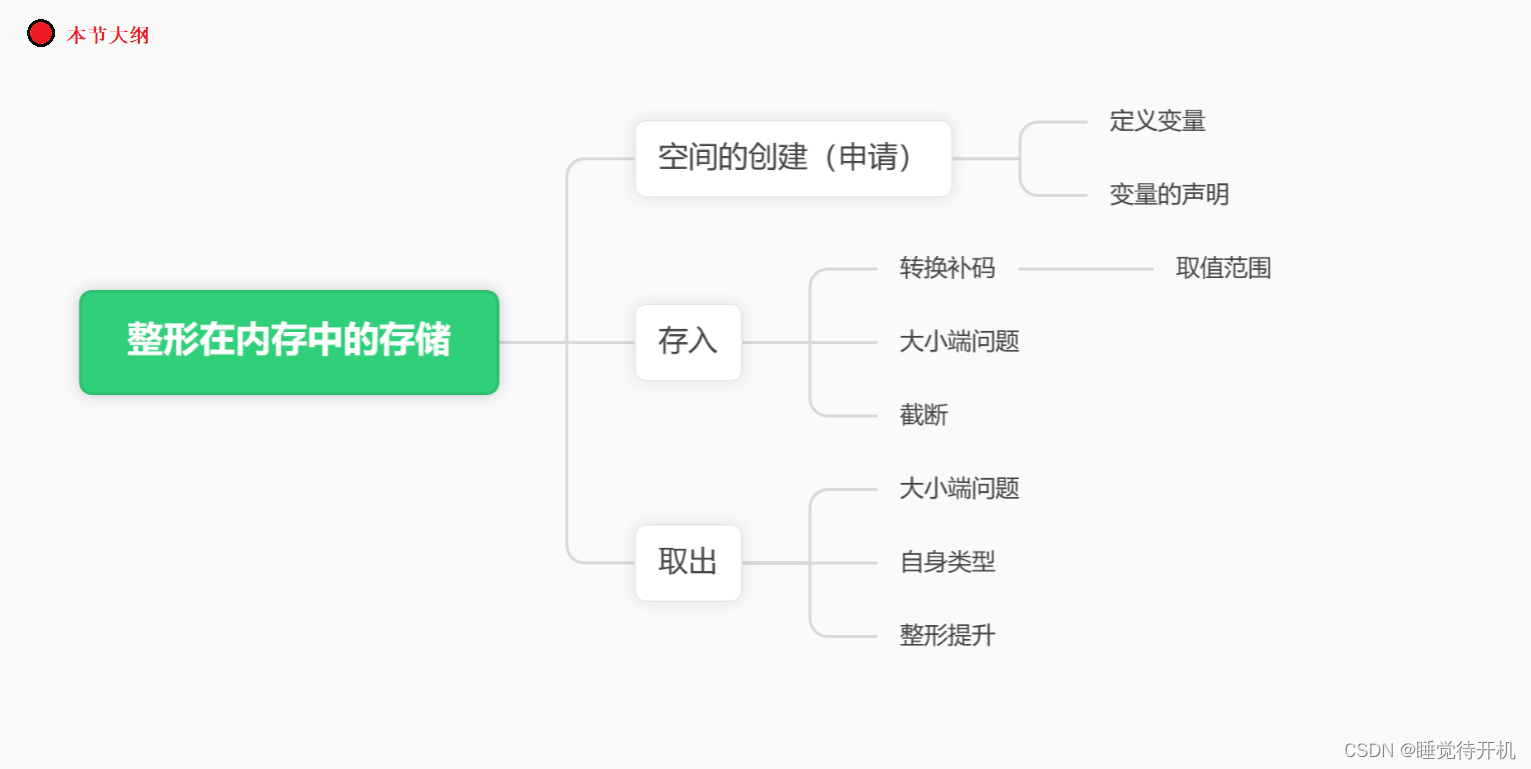
一、空间的申请
1.变量定义
1.1变量定义的概念:
所谓变量定义,本质上就是在内存中开辟特定大小的空间(不做解释,后文体会)。
概念区分:初始化与赋值
(1)概念:
初始化:指的是变量与生俱来的内容属性
赋值:值的是变量后来放到该变量空间的内容属性
(2)特点:
初始化只能进行一次,赋值可以进行多次
初始化具有先天性的含义,赋值有着后天的含义。
1.2变量定义的原因:
定义变量的原因在于开辟空间,暂时存储数据
首先,我们需要明确的是计算机是弥补人类计算能力低下问题诞生的(这里并没有贬低人类的意思,就是说人类跟计算机相比计算能力确实相对来说比较差)
之后,我们需要明白,我们人类计算时候是需要一步一步计算的,计算机也是需要进行先后计算了,并不是一下子就对所有数据进行处理,计算机也是对一个一个数据进行依次处理的,至于为什么算个数字那么快,因为计算机算的快而已,这并不是说计算机对所有数据进行同时处理。(注:当然计算机也是可以同时对数据进行处理的,不过同时处理数据的能力有限,了解即可)
然后,我们大概就明白了,为何需要变量?就是因为有些数据需要等待一些时间去让计算机处理,在处理之前,需要先存储起来防止数据丢失,这大概跟人类做运算时候要写在纸上差不多,省的忘了原来的数据,如果忘了那就惨了。
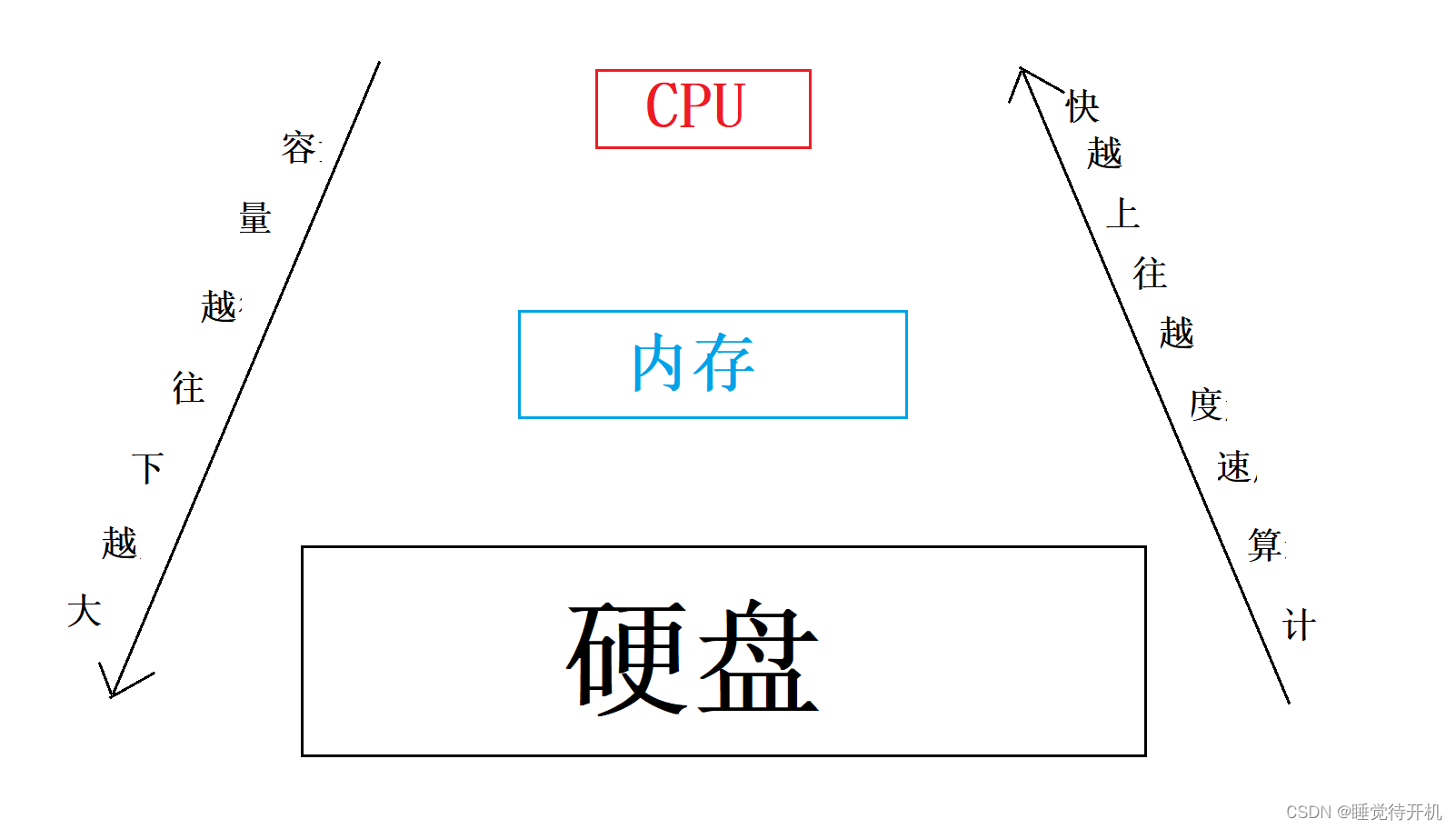
那为啥需要把数据放在一个个变量里进行处理啊?我数据直接放那一团不就行了嘛,这有点类似于我们吃饭,我们一般都是用碗吃饭,而不是直接用锅,原因在于效率高,计算机也是一样,在处理数据的时候,先用变量把在“一锅里的”数据分到一个个小碗里,然后就“吃”的快了。而且之前讲过,我们做饭的地方跟我们吃饭的地方离得距离是比较远的,类似于硬盘中的程序跟cpu处理是比较远的,要想提高效率,就是借助变量变成“小碗”送到内存当中,这样就跟cpu离得近了。其实我感觉变量就是起到了一个方便读取数据的作用。
变量定义的本质在于,开辟一块内存空间,暂时存储数据
2.变量声明
变量声明的本质就是:告知编译器。**
两者的区别在于,
声明你可以声明多次,定义只能定义一次哈。
本质区别在于定义开辟内存空间,变量声明没有开辟内存空间。
这个区别有一个比较有意思的比喻,大概是这样的,变量的定义类似于你跟你女朋友表白,只能表白一次吧?哈哈。然后变量的声明的话就是你告诉你周围的人,那个女孩是我女朋友哈,你们不要有非分之想了哈。这里想说声明可以声明无数次。(这里只是做一个比喻说明一下哈,无任何不良诱导)
二、数据存入
首先同学们,我想问int a = -10;计算机会直接把-10存入内存中吗?答案是不是
原因在于计算机只认识二进制。
因而就需要进制转换,需要把-10这一个十进制数字转换成为二进制的形式,这就牵扯到了原码、反码以及补码的概念和转换问题。
1.转换补码
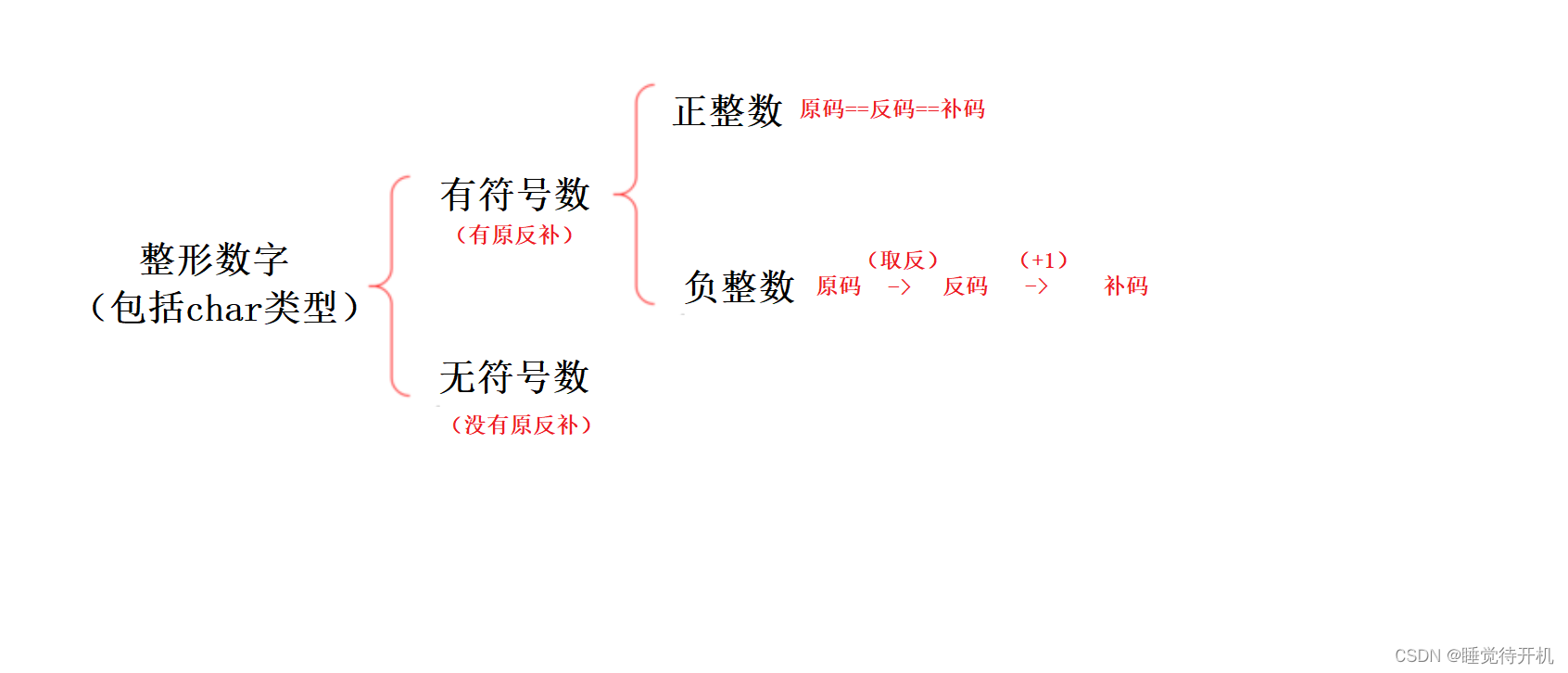
有符号数:
首先,对于有符号数,一定要能表示该数据是正数还是负数,所以我们一般用最高比特位来充当符号位。
原码反码补码都有符号位和数值位。符号位0表示正数,1表示负数,而三种表示方法各不相同。
无符号数:
不需要转换,原码反码补码相同不存在符号位。
如果一个数据是负整数,那么要遵守下面的规则进行转换:
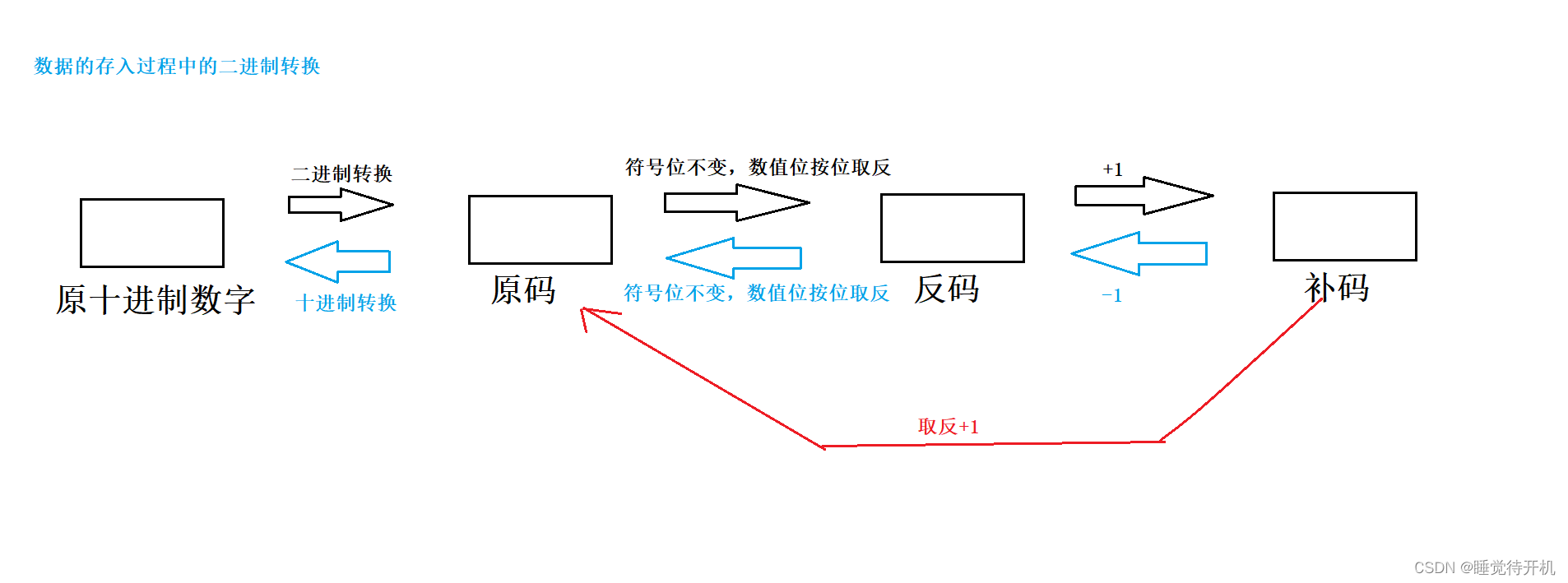
原码:直接将数字按照正负数的形式翻译成二进制即可
反码:符号位不变,数值位按位取反
补码:反码+1
无符号数:不需要转换(原码反码补码相同),没有符号位的概念
整形:数据存放内存中的其实是补码
为啥需要补码来存储整形类型?
原因在于:
1.使用补码,可以将符号位和数值位进行统一处理,并且加法和减法也可以统一进行处理
2.原码与补码的相互转换,其运算过程是相同的(都是取反+1),不需要格外的硬件电路
我需要强调一点的是,右边数字的二进制转换与左边的类型没有半毛钱关系,编译器判断有无符号整形,只看你赋值的数字有没有+号或者-号而已
那同学觉得计算机就这样把补码扔到内存了吗?
显然不只如此!还需要考虑大小端存储问题。
2.大小端存储
大小端存储取决于硬件单元,这个大小端存储是啥意思呢?
大小端存储的概念:
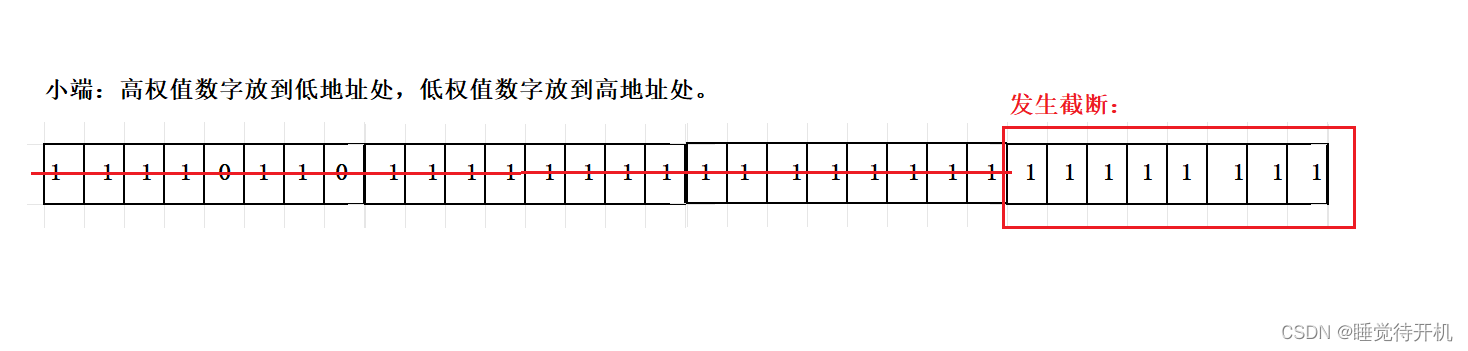
大端:低权值数字放到高地址处,高权重数字放到低地址处。
小端:高权值数字放到低地址处,低权值数字放到高地址处。

3.截断
考虑到怎么存储之后,我们还得需要考虑一个问题,就是会不会发生截断?比如你把一个数字放到一个char类型里面,char类型只有8个比特位,存不下一个数字的32个比特位,必然要发生截断。
当然对于截断问题,只是顺便一提,有兴趣可以单独去研究一下。
4.取值范围的问题
一个类型有取值范围,那你知道取值范围是怎么进行确定的吗?
一个类型的取值范围的大小取决于这个类型有多少个比特位
假如我只给你一个比特位,请问你可以表示几个数字(不考虑符号位)?
就俩数字(2^1)嘛,一个0一个1嘛
我如果给你两个比特位呢?
4(2^2)个数字,00,01,10,11
我如果给你三个比特位呢?
8(2^3)个数字,000,001,010,011,100,101,110,111
……
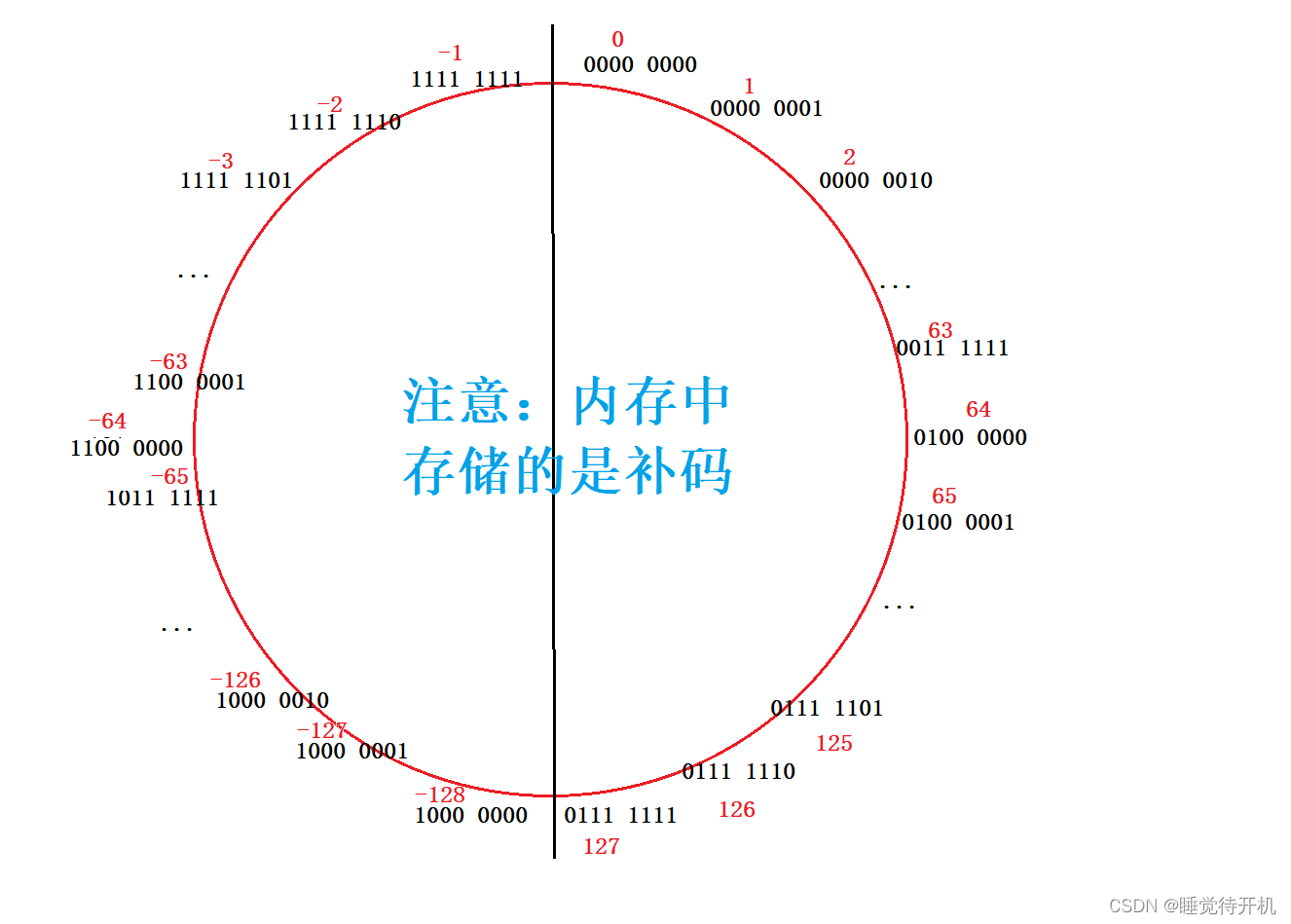
所以,,,一个8个比特位的char类型,可以表示几个数字?2^8==256!
这也就解释char(有符号)类型的取值范围是-128—127了。
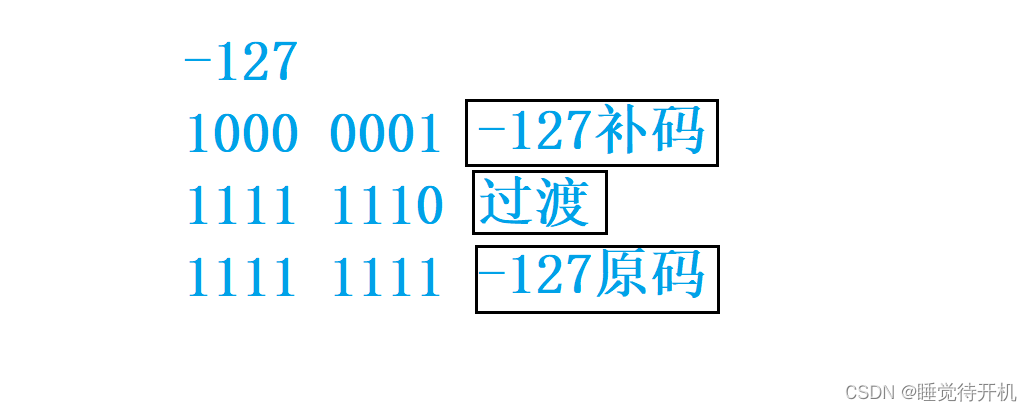
但是我有个小疑惑,-128靠8个比特位是怎么表示出来的?明明需要9个比特位啊。

只是人为规定!!!
之后呢,还要给大家看一个取值循环图,大家就能明白类型的取值范围是怎么回事了:
三、数据取出
1.大小端
还是要先看大小端问题,小端存储就小端取出,大端存储就大端取出即可。
2.自身类型
到了这个时候,说实在的左边的类型才有作用,什么意思呢?左边的类型决定了怎么看待这串二进制数字。
比如说左边如果是无符号整形类型,那么就不会把二进制最高位看成符号位,同理,如果是有符号类型,就会把最高位的二进制位看成符号位,这两种情况是截然不同的数值!

3.整型提升
如果我在内存里面是一个8个比特位的字符呢?你放入的类型却是一个int类型怎么办?整型提升。有符号int补符号位,无符号int前面补0,给你补到32个比特位再说。当然,这个地方也就不细说了,有兴趣可以自行研究一下。
练习题
最后送大家一道练习题哈,如果看完本文章大体理解我说的啥的话,应该可以做对,当然不对的话也不要担心哈,再弄懂就好啦,知识不是一下就会弄懂的。
int main()
{
char a[1000];
int i;
for (i = 0; i < 1000; i++)
{
a[i] = -1 - i;
}
printf("%d", strlen(a));
return 0;
}
答案:255,请试分析本题。
解析:略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 嵌入式软件开发对硬件知识的掌握要求要多高?
- 【博士每天一篇论文-实验分析】Toroidal topology of population activity in grid cells
- 次梯度算法
- TypeScript到ArkTS的适配规则
- C语言中指针变量如何使用
- JDK下载、安装和环境配置
- 地震预测系统项目实现
- PostgreSQL 可观测性最佳实践
- Selenium在vue框架下求生存
- 数据结构初阶之插入排序与希尔排序详解