Mindspore 公开课 - prompt
发布时间:2024年01月16日
prompt 介绍
Fine-Tuning to Prompt Learning
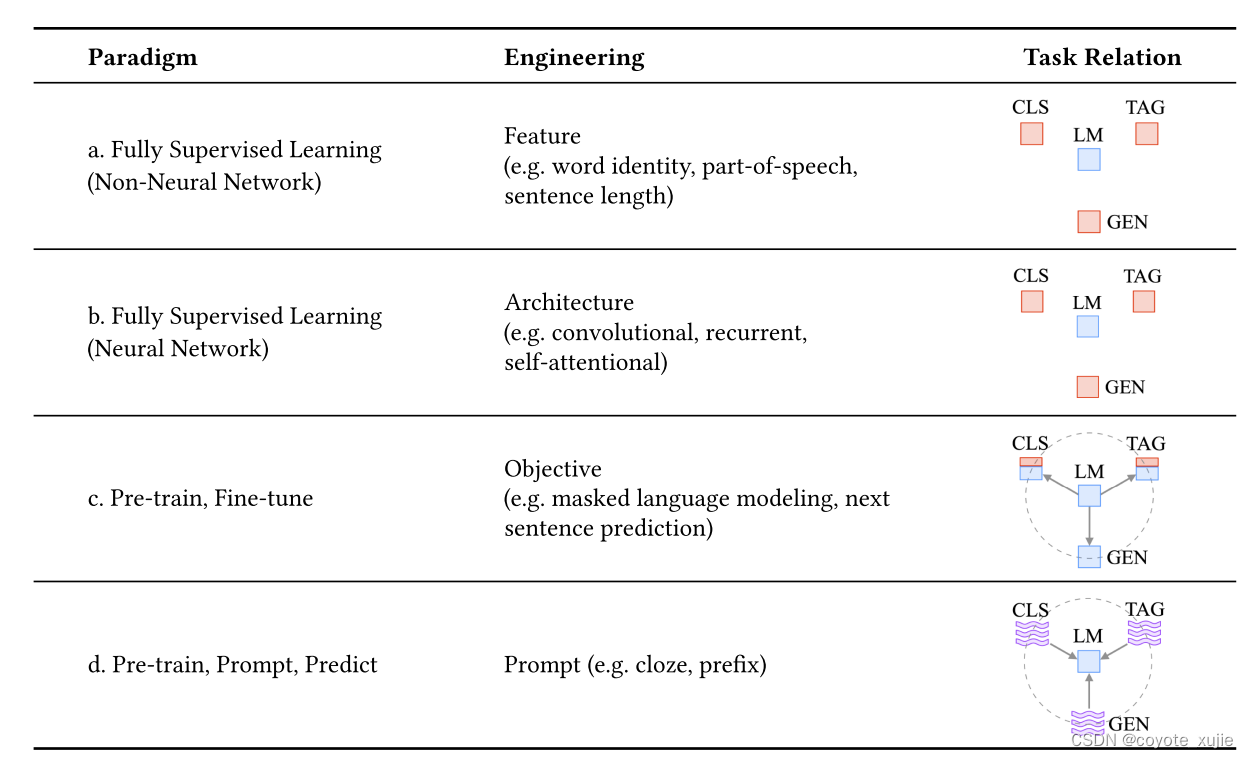
Pre-train, Fine-tune
- BERT
- bidirectional transformer,词语和句子级别的特征抽取,注重文本理解
- Pre-train: Maked Language Model + Next Sentence Prediction
- Fine-tune: 根据任务选取对应的representation(最后一层hidden state输出),放入线性层中
例:Natural Language Inference
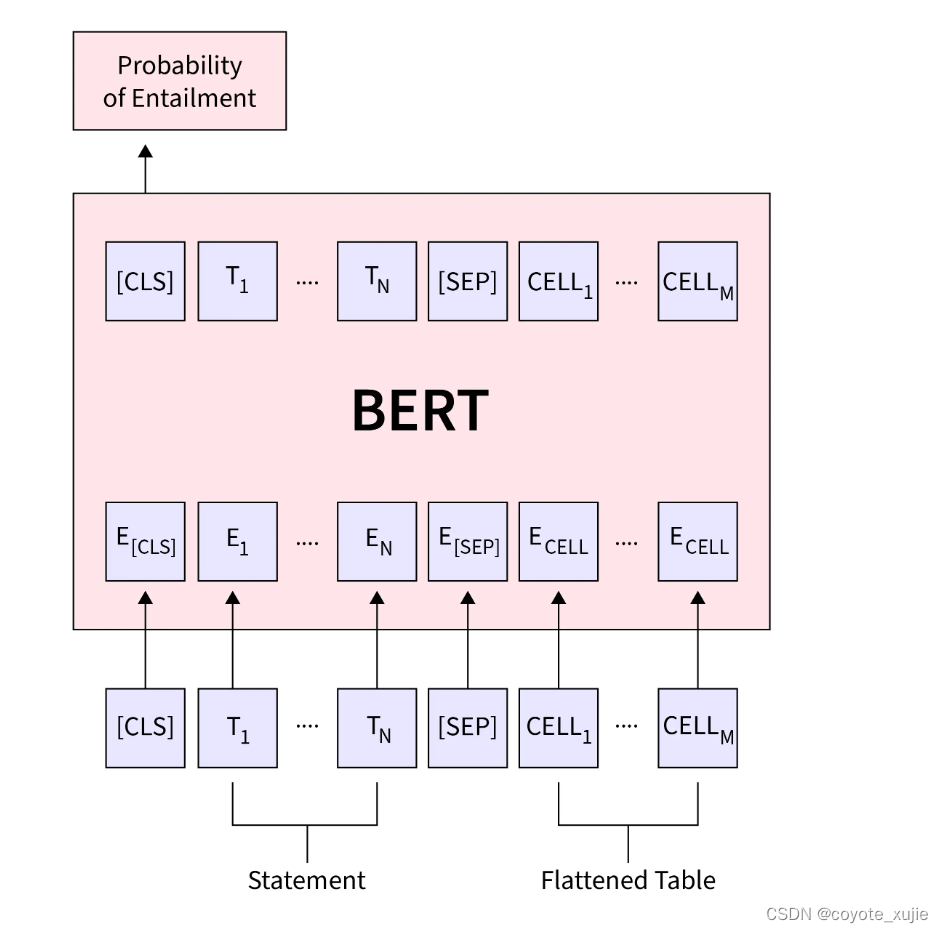
Pre-train, Fine-tune: models
- BERT
- bidirectional transformer,词语和句子级别的特征抽取,注重文本理解
- Pre-train: Maked Language Model + Next Sentence Prediction
- Fine-tune: 根据任务选取对应的representation(最后一层hidden state输出),放入线性层中
例:Named Entity Recognition
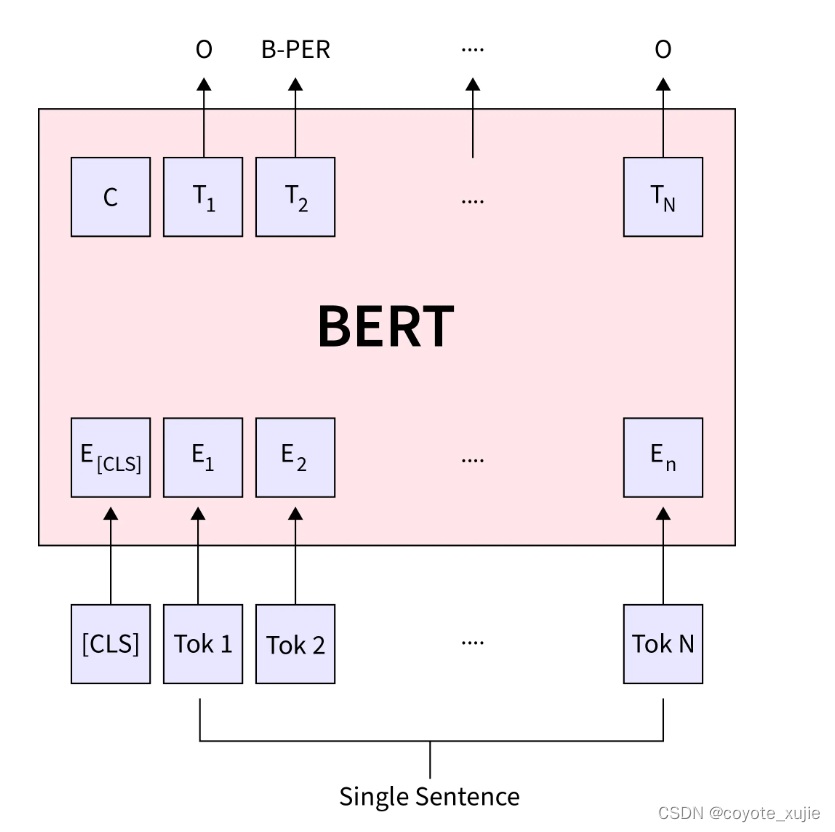
Pre-train, Fine-tune: models
- GPT
- auto-regressive model,通过前序文本预测下一词汇,注重文本生成
- Pre-train: L 1 ( U ) = ∑ i log ? P ( u i ∣ u i ? k , … , u i ? 1 ; Θ ) L_1(\mathcal{U})=\sum_i \log P\left(u_i \mid u_{i-k}, \ldots, u_{i-1} ; \Theta\right) L1?(U)=∑i?logP(ui?∣ui?k?,…,ui?1?;Θ)
- Fine-tune: task-specific input transformations + fully-connected layer
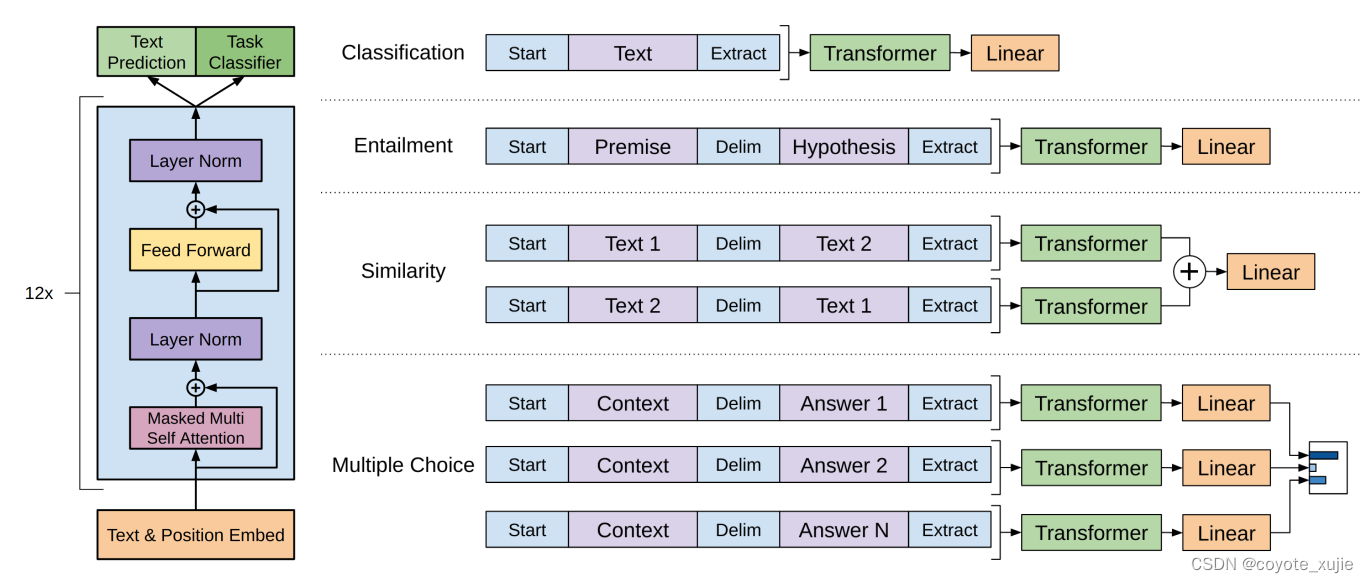
Pre-train, Fine-tune: challenges
- gap between pre-train and fine-tune
少样本学习能力差、容易过拟合
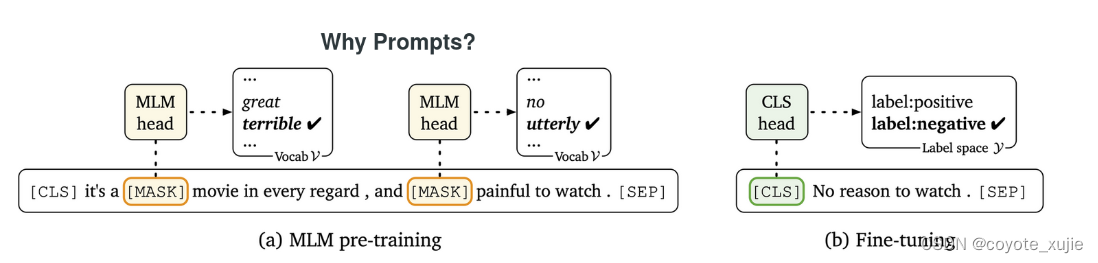
Pre-train, Fine-tune: challenges
- gap between pre-train and fine-tune
少样本学习能力差、容易过拟合
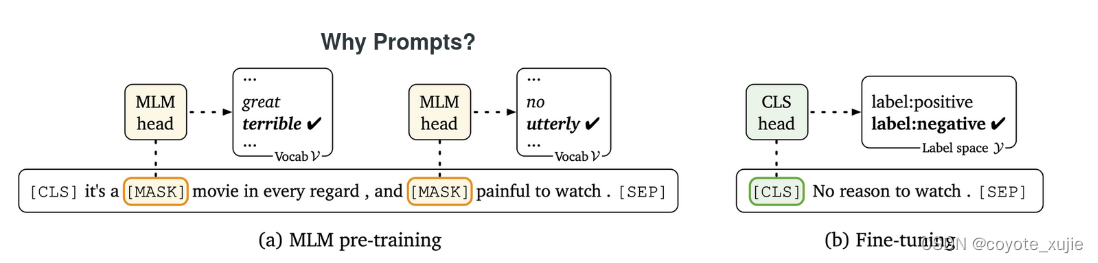
Pre-train, Fine-tune: challenges
- cost of fine-tune
现在的预训练模型参数量越来越大,为了一个特定的任务去 finetuning 一个模型,然后部署于线上业务,也会造成部署资源的极大浪费
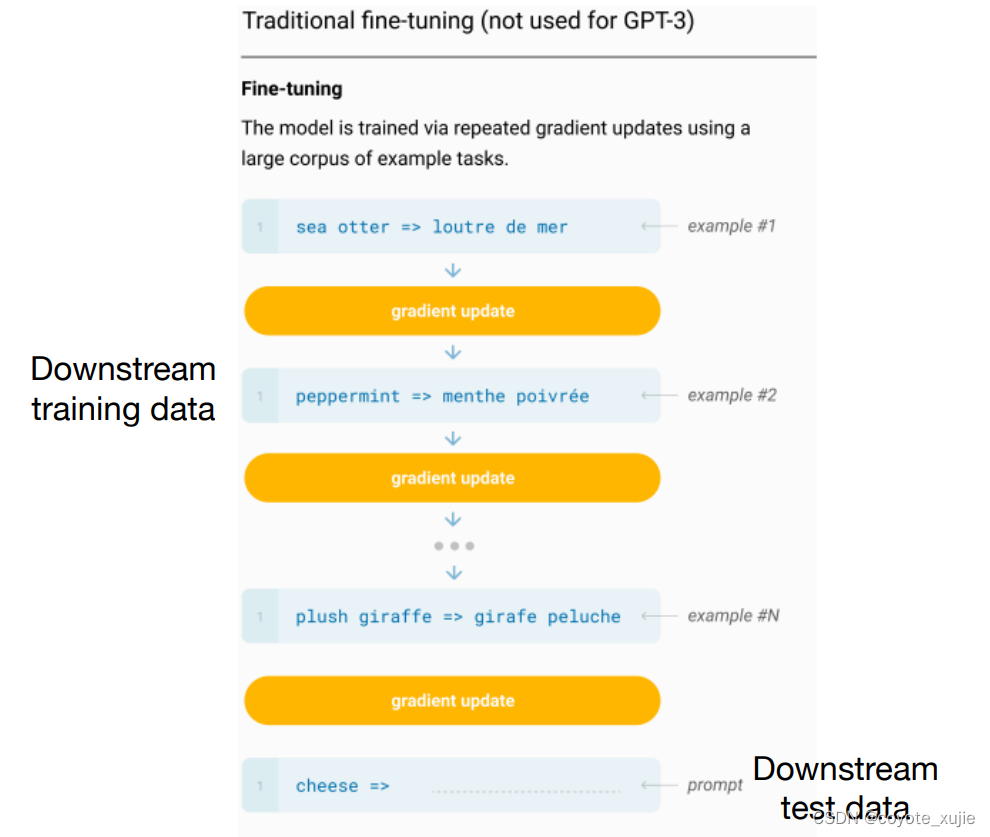
Pre-train, Prompt, Predict: what is prompting
- fine-tuning: 通过改变模型结构,使模型适配下游任务
- prompt learning: 模型结构不变,通过重构任务描述,使下游任务适配模型
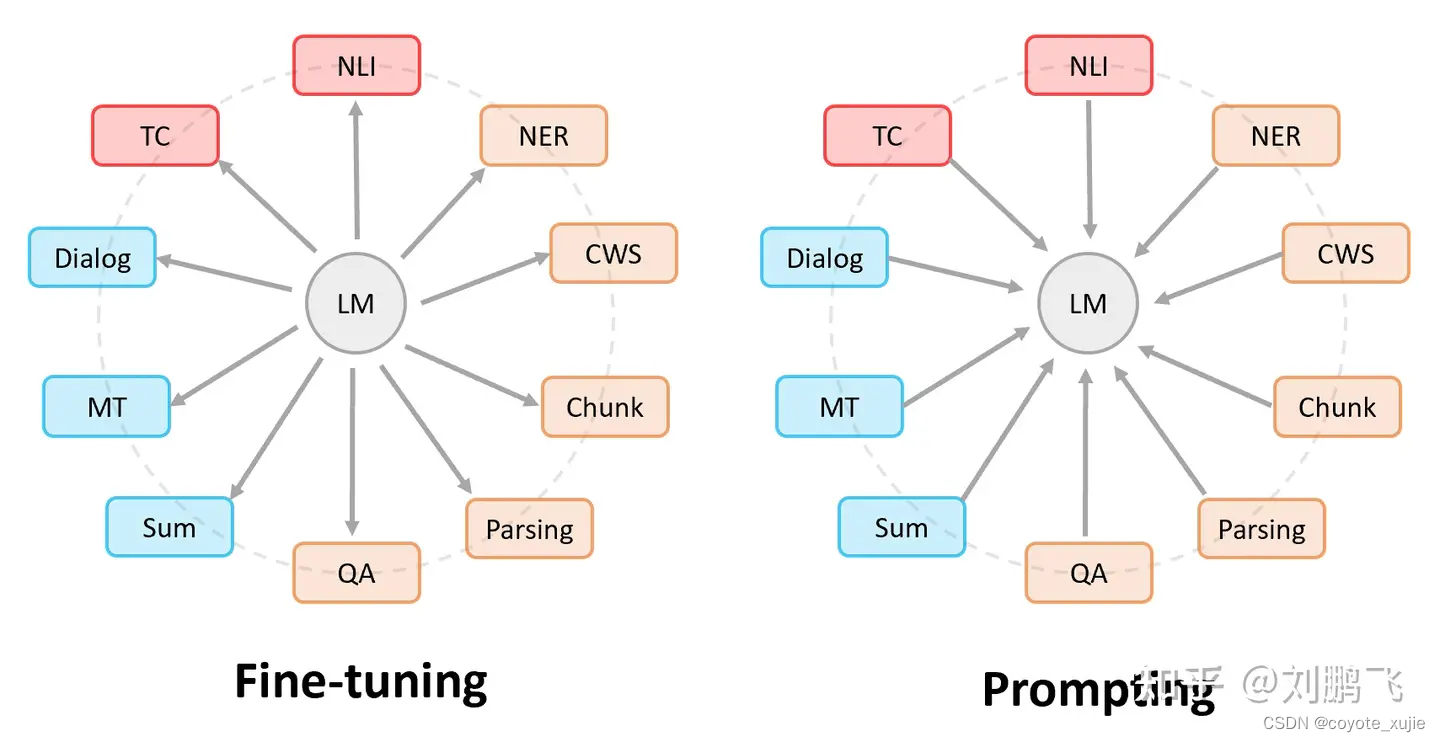
Pre-train, Prompt, Predict: workflow of prompting
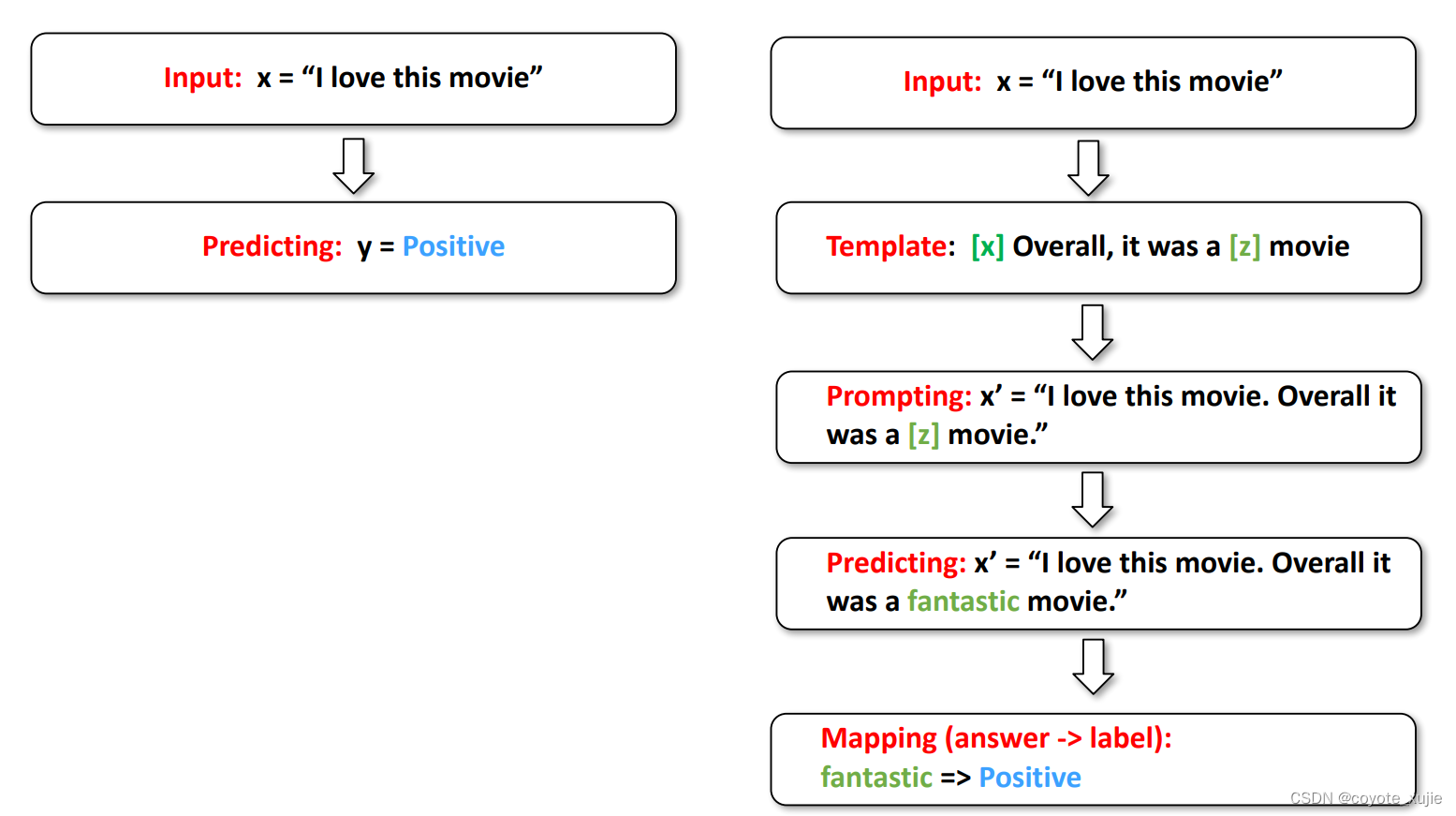
Pre-train, Prompt, Predict: workflow of prompting
- Template: 根据任务设计prompt模板,其中包含 input slot[X] 和 answer slot [Z],后根据模板在 input slot 中填入输入
- Mapping (Verbalizer): 将输出的预测结果映射回label
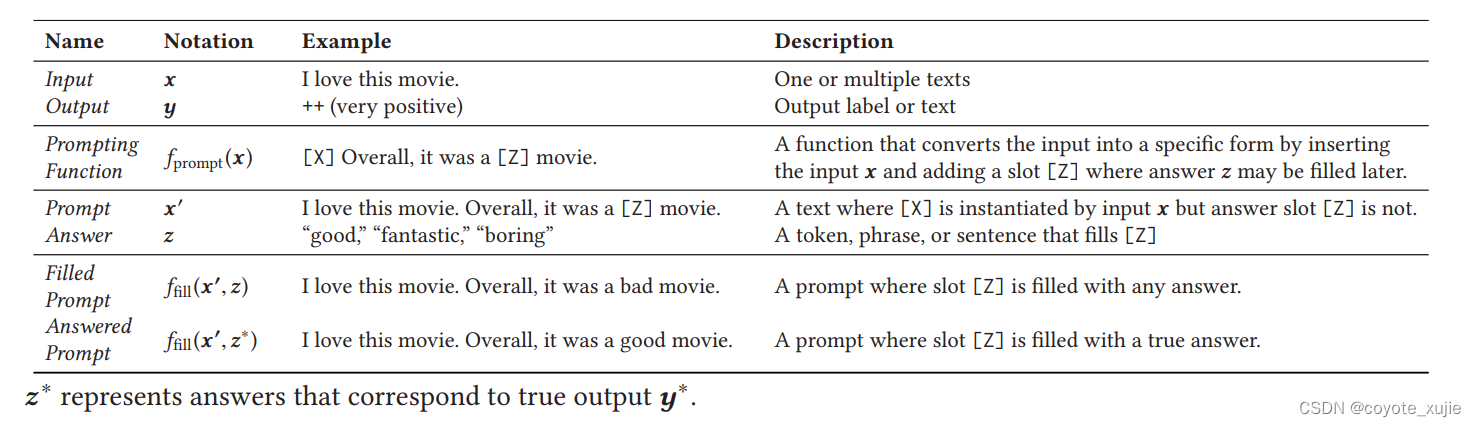
Pre-train, Prompt, Predict: prompt design
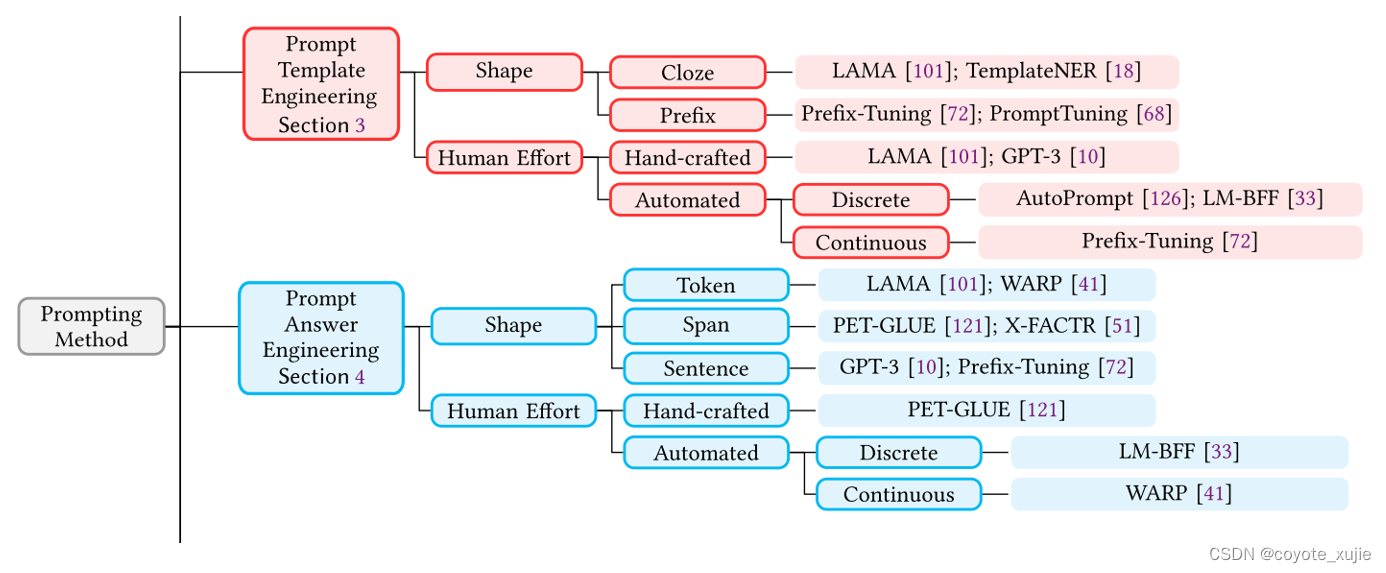
Prompting 中最主要的两个部分为 template 与 verbalizer 的设计。
他们可以分别基于任务类型和预训练模型选择(shape)或生成方式(huamn effort)进行分类。
文章来源:https://blog.csdn.net/Wolf_xujie/article/details/135612018
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用Go语言实现RESTful API
- R语言【base】——sample():随机取样和排列
- C#设计模式之观察者模式
- 一文读懂$mash 通证的 “Fair Launch” 规则,将公平发挥极致
- Kafka-消费者-KafkaConsumer分析-Heartbeat
- Java 数据类型(无废话版)
- LeetCode 2660. 保龄球游戏的获胜者
- 用DevExpress WPF Windows 10 UI组件,轻松构建触摸优先的业务型应用UX(上)
- 十六:爬虫-验证码与字体反爬
- nginx中的正则表达式及location和rewrite