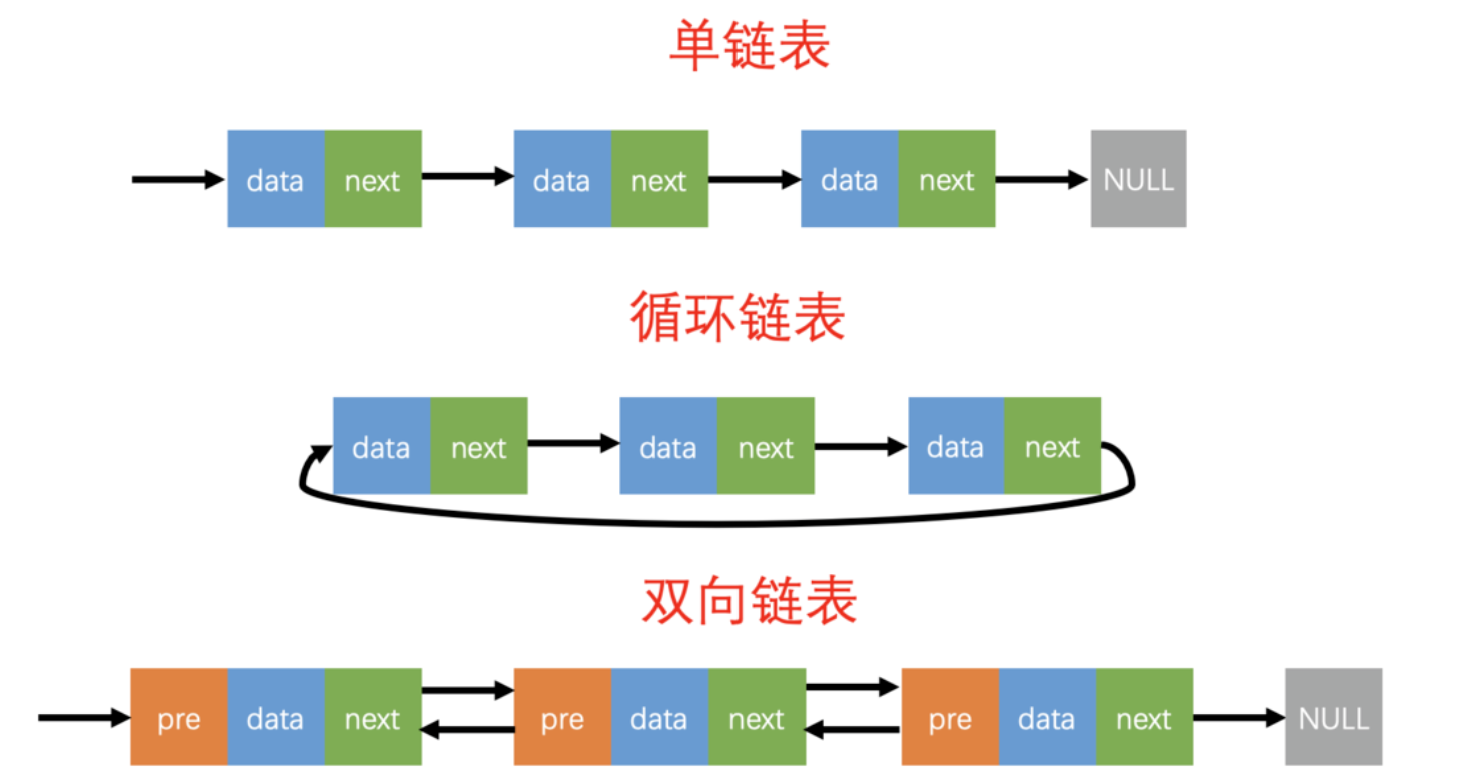
【数据结构】- 链表
链表
- SLTPrint(SLTNode* phead)打印链表
- BuySListNode(SLTDataType x)创建新的结点
- SLTPushBack(SLTNode** pphead, SLTDataType x)尾插
- SLTPushFront(SLTNode** pphead, SLTDataType x)头插
- SLTPopBack(SLTNode** pphead)尾删
- SLTPopFront(SLTNode** pphead)头删
- SLTFind(SLTNode* pphead,SLTDataType x)查找
- SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)插入数据
本篇为大家详细介绍链表:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
我们已经学过了顺序表,明白了顺序表的基本功能和格式,链表可以处理一些连续存储的数据,但是当我们遇到特殊情况时,顺序表就有了一些局限性,它也有自己的一系列缺点:

今天就来学习另一种存储数据的结构----链表(本篇先以简单的单链表为例)
同顺序表也一样,我们把函数放在头文件中声明,函数实现放在Slist.c文件,在test.c文件中测试实现链表的各个功能
与顺序表一样,我们利用链表结构实现对数据的增删查改等一系列功能。
链表是链式存储结构,它按需申请释放,解决了顺序表扩容浪费的问题

在正式规划链表各个功能之前,我们需要做好基本的准备工作,这是指创建一个结构体里面分别存储我们的数据域和指针域,还有链表的初始化、最后的销毁数据、以及打印链表的函数。
首先我们建立一个结构体里面存放数据和指向下一个结点的指针
将int类型重命名,便于以后管理不同类型数据时进行修改。
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
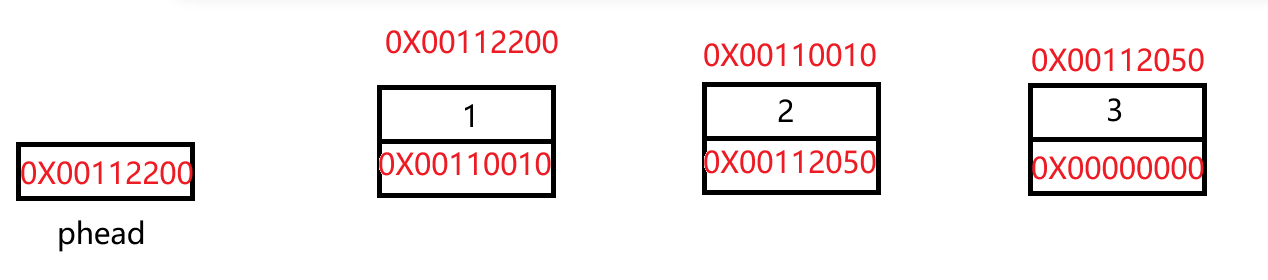
在定义链表之前,需要先定义一个头指针,通过头指针来帮助我们找到链表,这样我们可以借此将链表传入函数。
SLTPrint(SLTNode* phead)打印链表
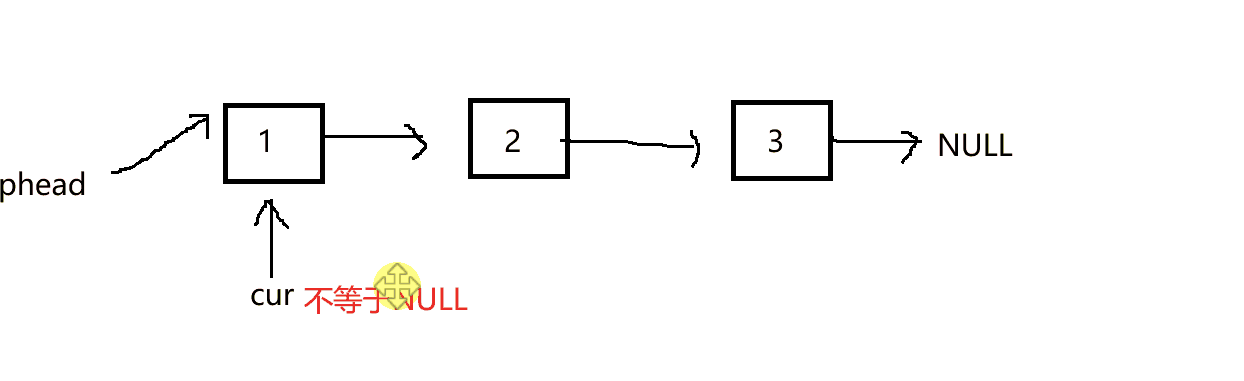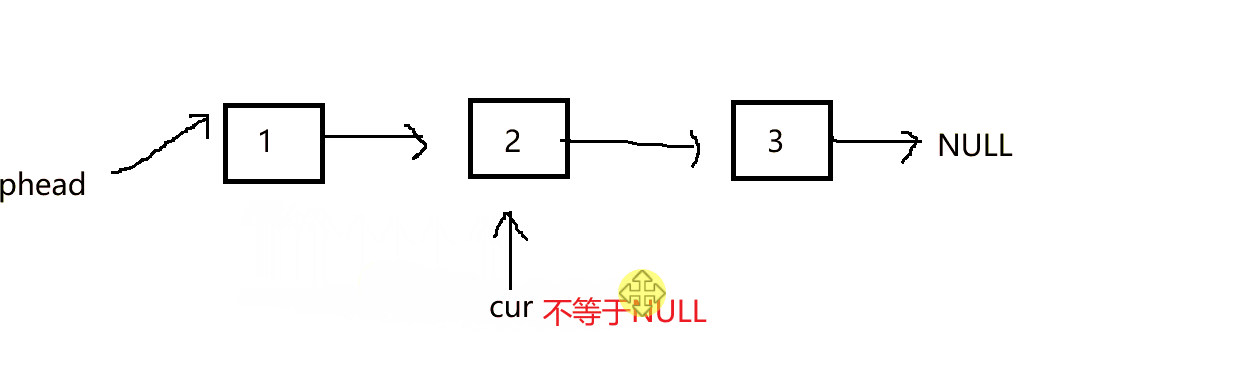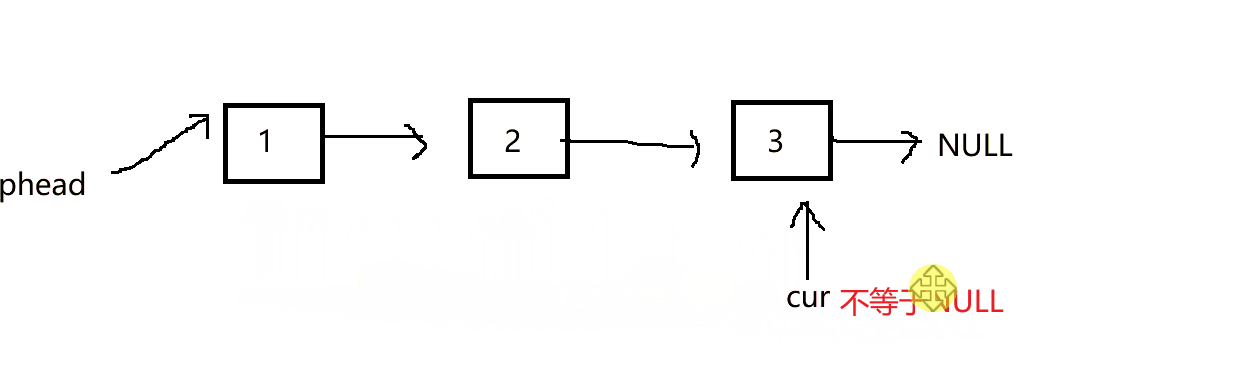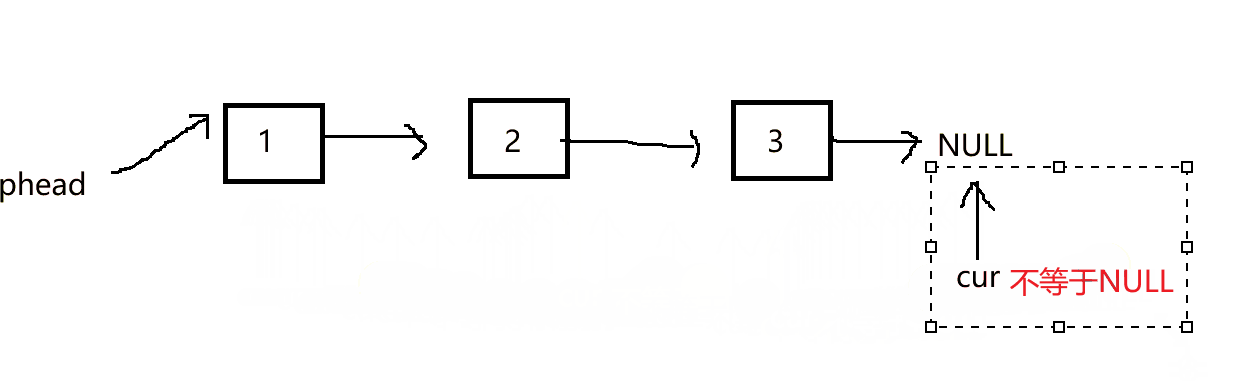
打印链表,我们只需依次打印出里面的数据,而每个结点中的指针则帮助我们找到下一个数据,并打印它,我们将这个过程封装进函数。传入链表的头结点
void SLTPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur)//当cur不等于NULL时进入循环进行打印数据
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
BuySListNode(SLTDataType x)创建新的结点
SLTNode* BuySListNode(SLTDataType x)//传参数x即我们要插入到新节点的值
{
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;//将指针域置空防止成为野指针
return newnode;
}
利用malloc函数为我们所新开辟的节点开辟一块SLTNode空间,将指针域置空
SLTPushBack(SLTNode** pphead, SLTDataType x)尾插
void SLTPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
SLTNode* cur = *pphead;
while (cur->next != NULL)
{
cur = cur->next;
}
cur->next = newnode;
}
}
在尾插数据时,我们仅仅传过去头结点,要想找1到链表的尾部,就要一个一个遍历,查找尾节点
在链表一系列准备工作做完之后,开始正式进行处理数据,在建立尾插函数时,第一个形参传递的是二级指针的形式。

众所周知,形参传一个指针是为了找到指向想要通过函数修改的变量的地址,可以在指针的基础上来修改变量,但是这里的形参是二级指针,也就是一个指针的地址,而不是普通的指针


想要改变结构体就要用结构体指针,想要改变结构体指针,要用结构体指针的指针所以,相应的,我们将形参设为二级指针时,再次传入指针想当于形参是指针的指针,那么当调用函数时,可以通过二级指针找到指针的地址,进行增加数据。
SLTPushFront(SLTNode** pphead, SLTDataType x)头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
想要在链表首部插入数据,首先需要改变头结点的指针,
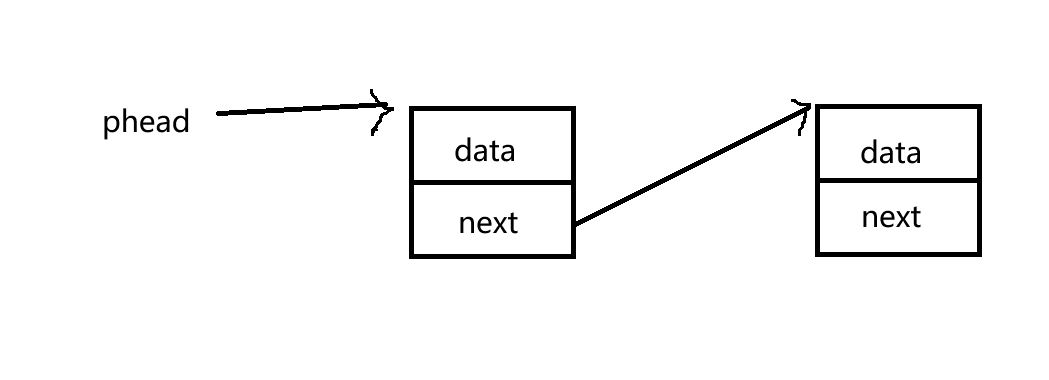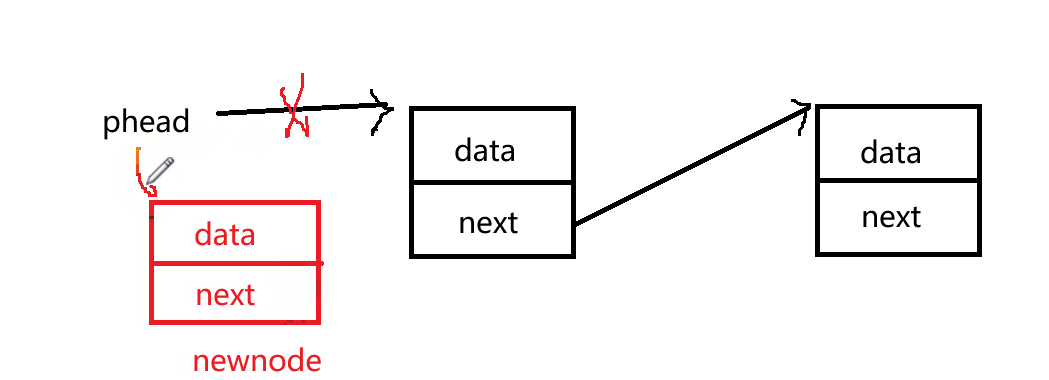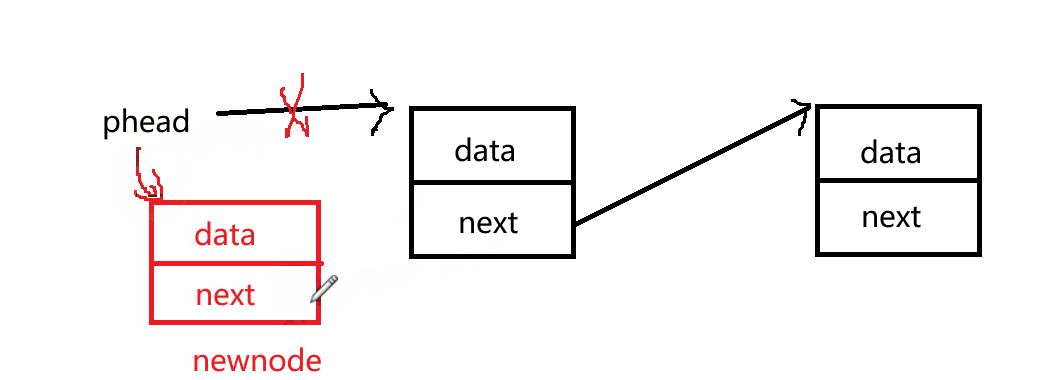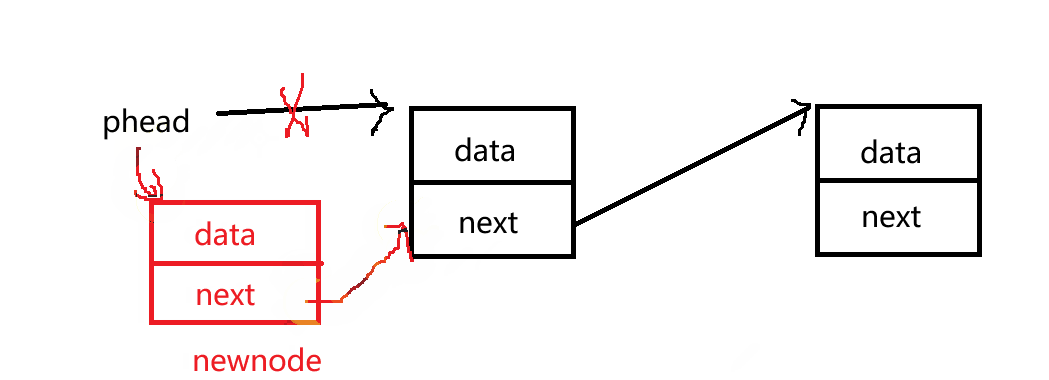
SLTPopBack(SLTNode** pphead)尾删
void SLTPopBack(SLTNode** pphead)
{
// 1、空
assert(*pphead);
// 2、一个节点
// 3、一个以上节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}
在尾删时,通常的情况是遍历链表—>找到尾结点—>删除尾结点—>将倒数第二个节点的指针置为NULL
这里需要考虑三种情况
1,当链表为空时,即我们不需要删除节点,那这个时候调用尾删函数就是没有意义的,所以需要
assert(*pphead),判断链表不为空。
2,当链表中只有一个节点时,我们只需要删除这一个节点,不需要对其他节点进行操作
3,当链表中有>=两个节点时,就可以按照一般情况正常删除尾结点
SLTPopFront(SLTNode** pphead)头删
void SLTPopFront(SLTNode** pphead)
{
// 空
assert(*pphead);
// 非空
SLTNode* newhead = (*pphead)->next;
free(*pphead);
*pphead = newhead;
}
删除头结点,如果链表为空,那么只需释放头结点指针即可,如果链表非空,那么将新结点的指针指向头结点的下一个位置SLTNode* newhead = (*pphead)->next,然后释放头结点指针,载将新结点newhead赋给头结点,这样就完成了头结点的删除
SLTFind(SLTNode* pphead,SLTDataType x)查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
查找函数一定是查找某一个值,如果找到,然后函数返回其结点,所以函数参数传链表指针和要查找的值
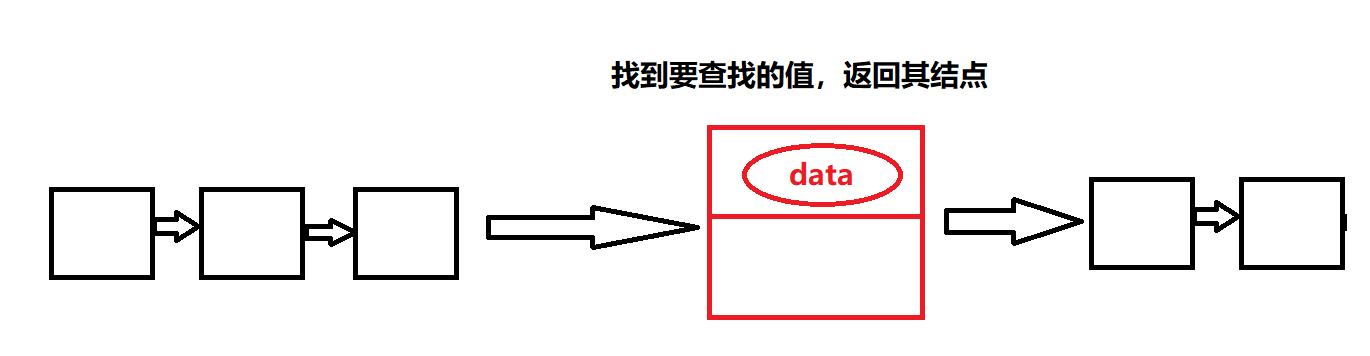
遍历每个结点的data数据,如果符合我们要查找的值,则返回节点指针
SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)插入数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SLTNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VisualVM监控远程服务SpringBoot
- 如何装好Home Assistant,四种方式安装HA OS测试
- IPFoxy运营干货|谷歌广告Google Ads如何选择最佳关键词?
- 力扣(leetcode)第392题判断子序列(Python)
- 2024新趋势下的“电力行业数字化转型建设方案”
- codeforces D. Array Collapse
- 计算机mfc140.dll丢失问题的5个解决方法,快速解决dll问题的方法
- Git学习基础-day01
- LSF 状态异常主机告警
- JVM篇——ParNew和CMS垃圾回收器,针对这一组垃圾回收器的详细介绍以及著名的三色标记算法分析,黄金文档,一篇文章拿下CMS!