Dify学习笔记-手册(三)
1、应用构建及提示词
在 Dify 中,一个“应用”是指基于 GPT 等大型语言模型构建的实际场景应用。通过创建应用,您可以将智能 AI 技术应用于特定的需求。它既包含了开发 AI 应用的工程范式,也包含了具体的交付物。
简而言之,一个应用为开发者交付了:
- 封装友好的 LLM API,可由后端或前端应用直接调用,通过 Token 鉴权
- 开箱即用、美观且托管的 Web App,你可以 WebApp 的模版进行二次开发
- 一套包含 Prompt Engineering、上下文管理、日志分析和标注的易用界面
你可以任选其中之一或全部,来支撑你的 AI 应用开发。
1.1、应用类型
Dify 中提供了两种应用类型:文本生成型与对话型,今后或许会出现更多应用范式(我们应该会及时跟进),Dify 的最终目标是能覆盖 80% 以上的常规 LLM 应用情景。
文本生成型与对话型应用的区别见下表:

2、创建应用
https://docs.dify.ai/v/zh-hans/guides/application-design/creating-an-application
2.1、创建应用的步骤
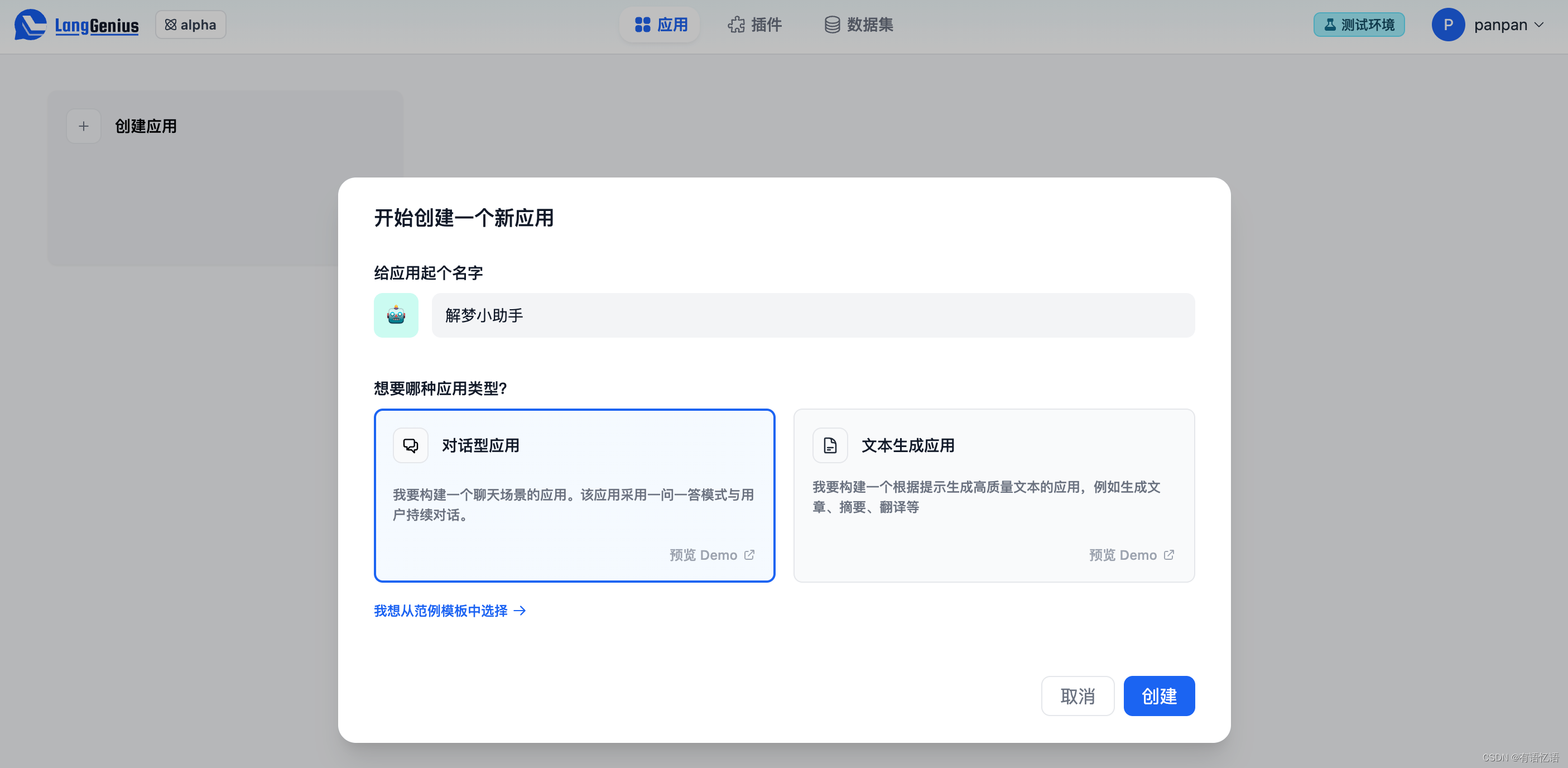
第 1 步,以管理员登录 Dify 后,前往主导航应用页
第 2 步,点击“创建新应用”
此外,我们在创建应用界面中提供了一些模版,你可以在创建应用的弹窗中点击从模版创建,这些模版将为你要开发的应用提供启发和参考。
第 3 步,选择对话型或文本生成型应用,并为它起个名字
应用名称今后可以随时修改。
2.2、从配置文件创建
如果你从社区或其它人那里获得了一个模版,你可以点击从应用配置文件创建,上传后可加载对方应用中的大部分设置项(但目前不包括数据集)。
2.3、你的应用
如果你是第一次使用,这里会提示你输入 OpenAI 的 API 密钥。一个可正常使用的 LLM 密钥是使用 Dify 的前提,如果你还没有请前往申请一个。
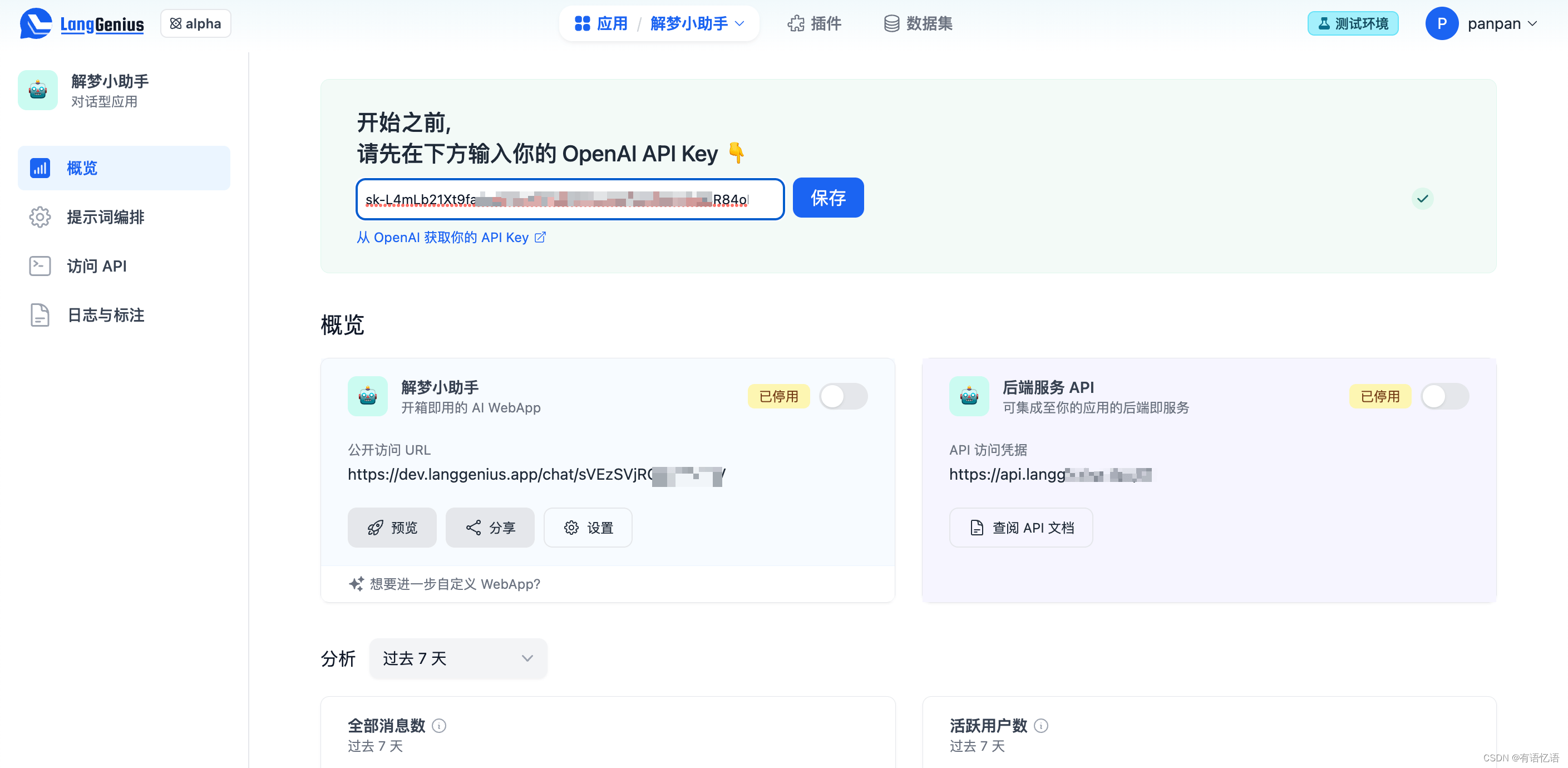
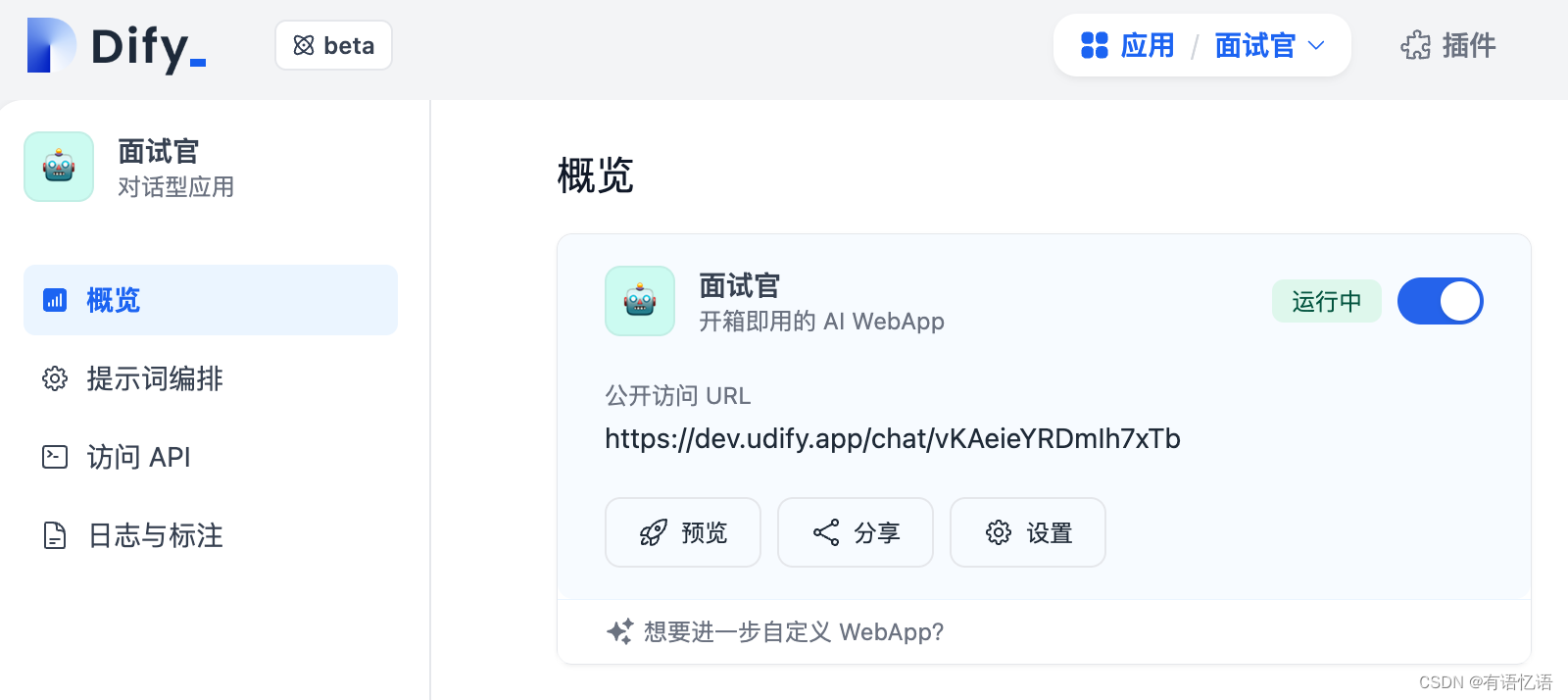
创建应用或选择一个已有应用后,会来到一个显示应用概况的应用概览页。你可以在这里直接访问你的 WebApp 或查看 API 状态,也可以开启或关闭它们。
统计显示了该应用一段时间内的用量、活跃用户数和 LLM 调用消耗—这使你可以持续改进应用运营的经济性,我们将逐步提供更多有用的可视化能力,请告诉我们你想要的。
- 全部消息数(Total Messages),反映 AI 每天的互动总次数,每回答用户一个问题算一条 Message。提示词编排和调试的会话不计入。
- 活跃用户数(Active Users),与 AI 有效互动,即有一问一答以上的唯一用户数。提示词编排和调试的会话不计入。
- 平均会话互动数(Average Session Interactions),反映每个会话用户的持续沟通次数,如果用户与 AI 问答了 10 轮,即为 10。该指标反映了用户粘性。仅在对话型应用提供。
用户满意度(User Satisfaction Rate),每 1000 条消息的点赞数。反应了用户对回答十分满意的比例。 - 平均响应时间(Average Response Time),衡量 AI 应用处理和回复用户请求所花费的平均时间,单位为毫秒,反映性能和用户体验。仅在文本型应用提供。
- 费用消耗(Token Usage),反映每日该应用请求语言模型的 Tokens 花费,用于成本控制。
2.4、接下来
试试你的 WebApp
逛一逛左侧的配置、开发和 Logs 页
试着参考案例配置一个应用
如果你具备开发前端应用的能力,请查阅 API 文档
3、提示词编排
掌握如何使用 Dify 编排应用和实践 Prompt Engineering,通过内置的两种应用类型,搭建出高价值的 AI 应用。
Dify 的核心理念是可声明式的定义 AI 应用,包括 Prompt、上下文和插件等等的一切都可以通过一个 YAML 文件描述(这也是为什么称之为 Dify )。最终呈现的是单一 API 或开箱即用的 WebApp。
与此同时,Dify 提供了一个易用的 Prompt 编排界面,开发者能以 Prompt 为基础所见即所得的编排出各种应用特性。听上去是不是很简单?
无论简单或是复杂的 AI 应用,好的 Prompt 可以有效提高模型输出的质量,降低错误率,并满足特定场景的需求。Dify 已提供对话型和文本生成型两种常见的应用形态,这个章节会带你以可视化的方式完成 AI 应用的编排。
应用编排的步骤
确定应用场景和功能需求
设计并测试 Prompts 与模型参数
编排 Prompts 与用户输入
发布应用
观测并持续迭代
了解应用类型的区别
Dify 中的文本生成型应用与对话型应用在 Prompt 编排上略有差异,对话型应用需结合“对话生命周期”来满足更复杂的用户情景和上下文管理需求。
Prompt Engineering 已发展为一个潜力巨大,值得持续探索的学科。请继续往下阅读,学习两种类型应用的编排指南。
扩展阅读
3.1、文本生成型应用
文本生成类应用是一种能够根据用户提供的提示,自动生成高质量文本的应用。它可以生成各种类型的文本,例如文章摘要、翻译等。
适用场景
文本生成类应用适用于需要大量文本创作的场景,例如新闻媒体、广告、SEO、市场营销等。它可以为这些行业提供高效、快速的文本生成服务,降低人力成本并提高生产效率。
如何编排
文本生成应用的编排支持:前缀前提示词,变量,上下文和生成更多类似的内容。
这边以做一个翻译应用为例来介绍编排文本生成型应用。
第 1 步 创建应用
在首页点击 “创建应用” 按钮创建应用。填上应用名称,应用类型选择文本生成应用。
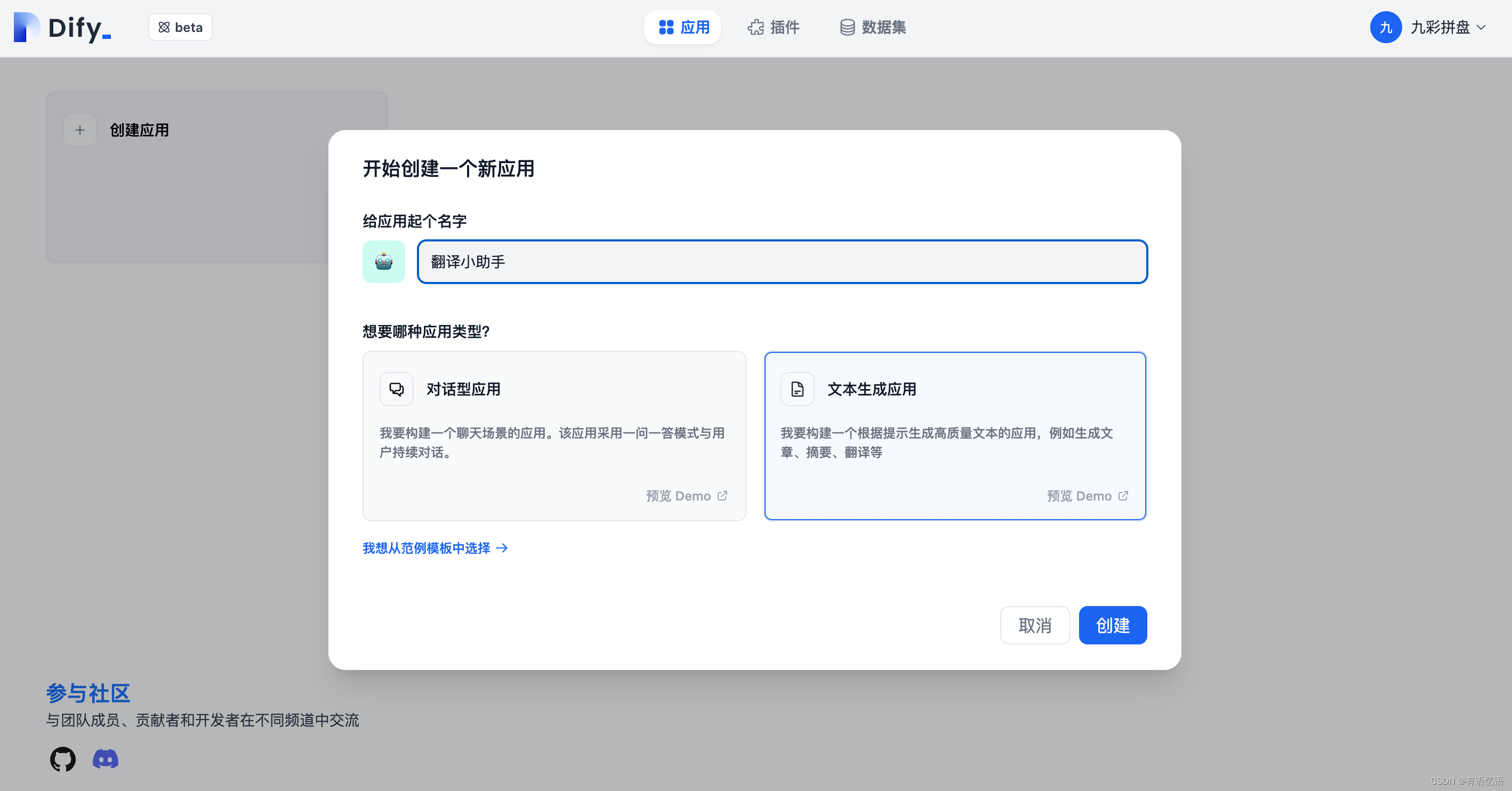
第 2 步 编排应用
应用成功后会自动跳转到应用概览页。点击左侧菜单:提示词编排 来编排应用。
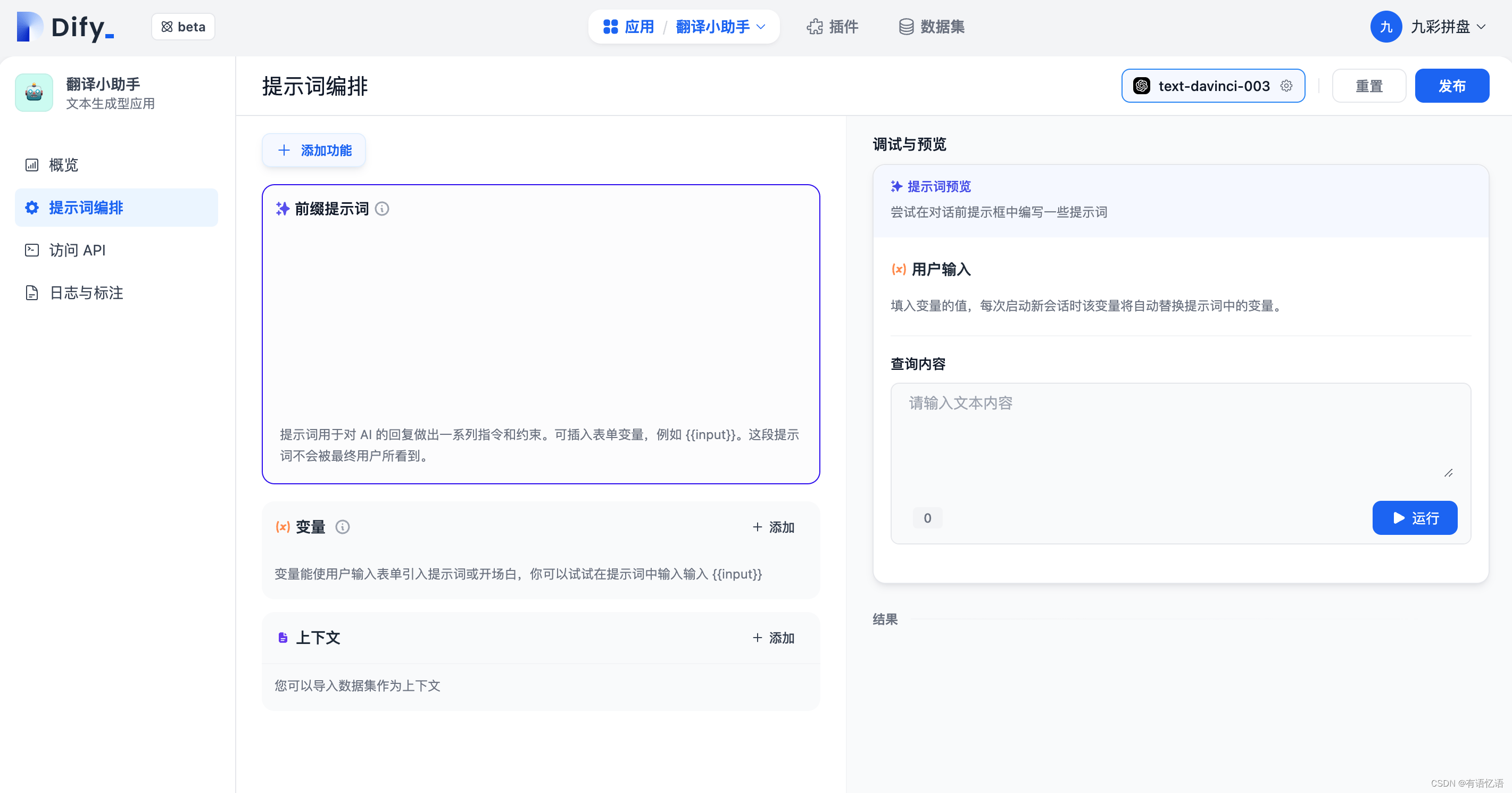
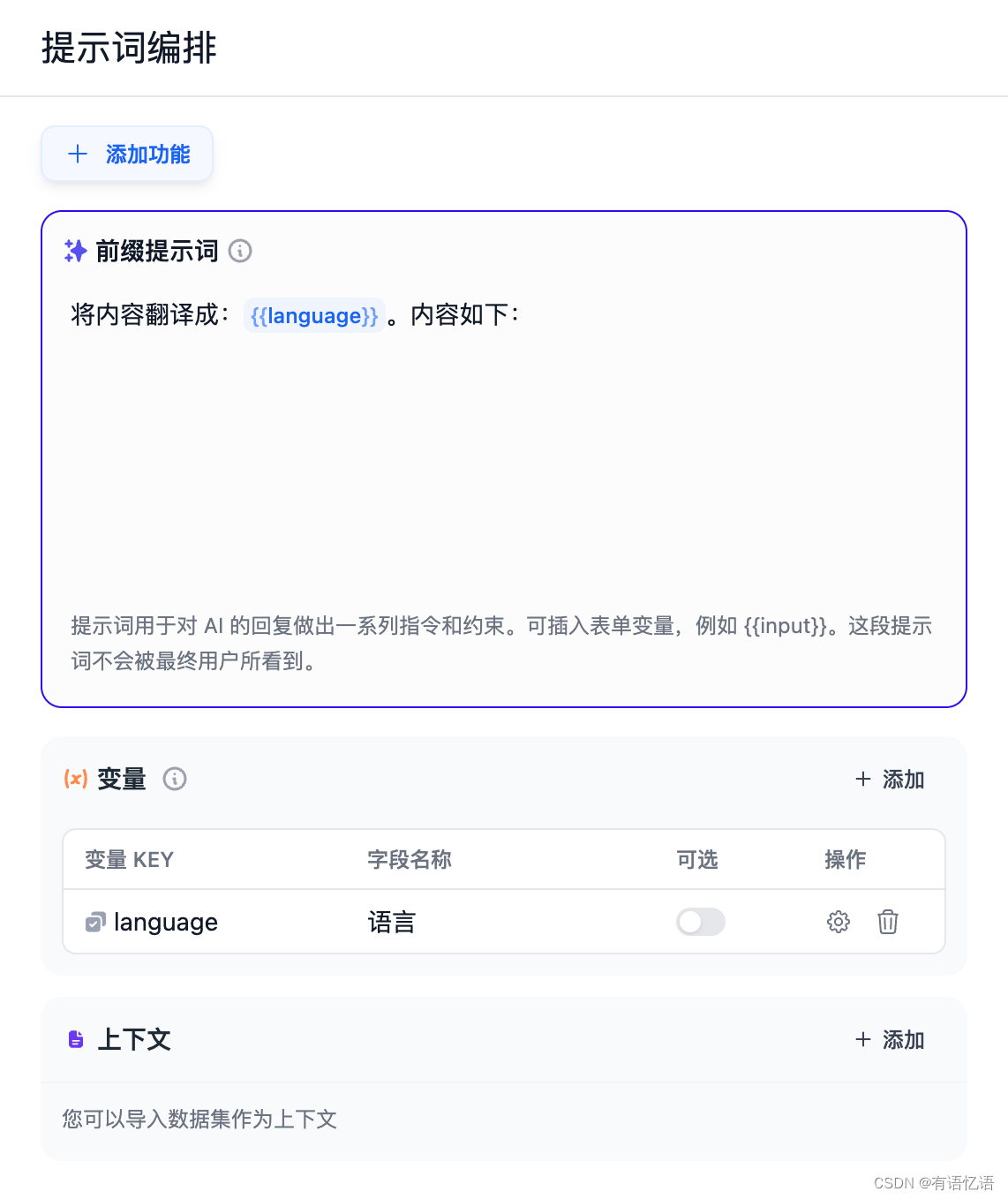
2.1 填写前缀提示词
提示词用于对 AI 的回复做出一系列指令和约束。可插入表单变量,例如 {{input}}。提示词中的变量的值会替换成用户填写的值。
我们在这里填写的提示词是:将内容翻译成:{{language}}。内容如下:
2.2 添加上下文
如果应用想基于私有的上下文对话来生成内容。可以用我们数据集功能。在上下文中点 “添加” 按钮来添加数据集。
2.3 添加功能:生成更多类似的
生成更多类似可以一次生成多条文本,可在此基础上编辑并继续生成。点击左上角的 “添加功能” 来打开该功能。
2.4 调试
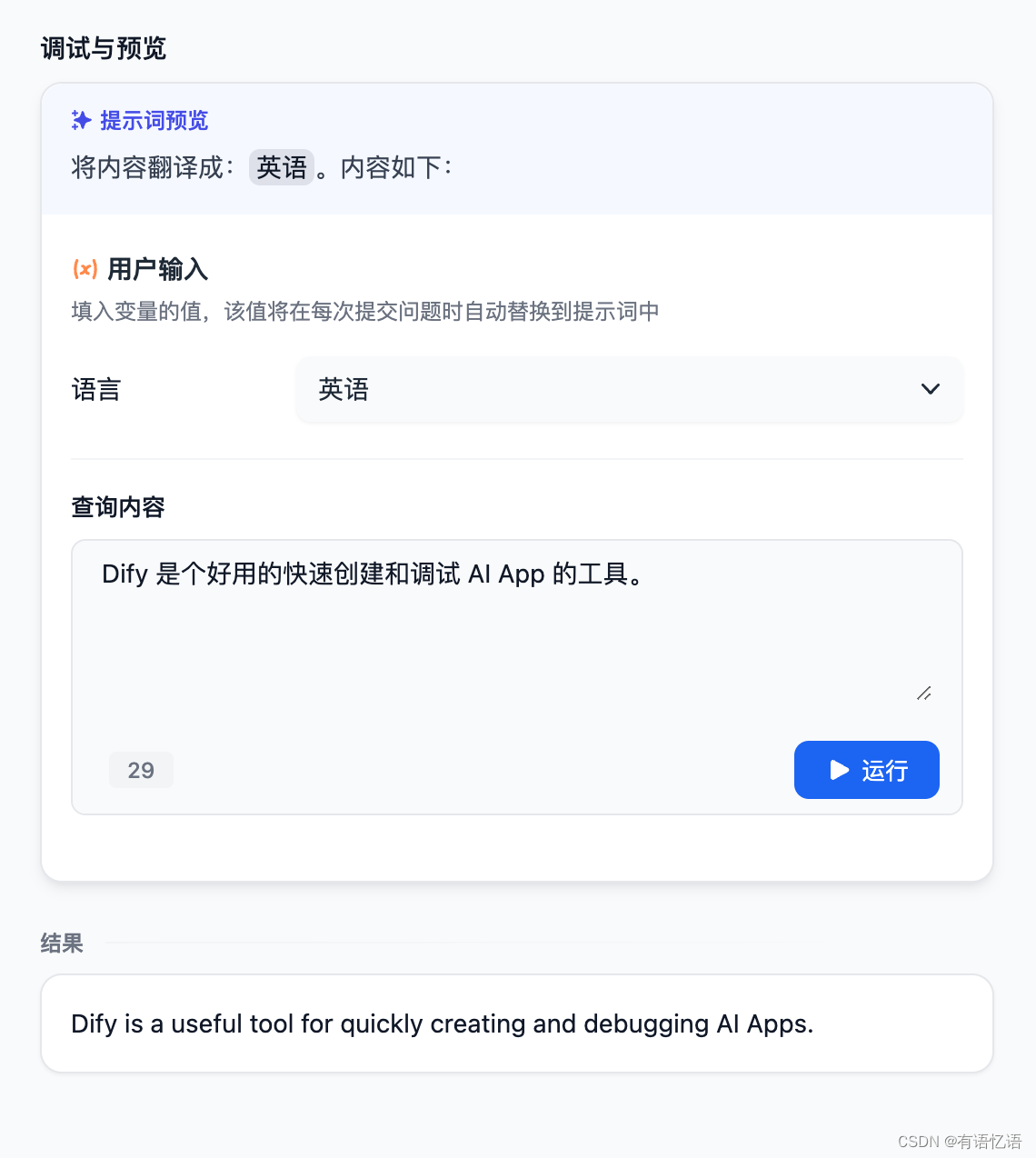
如果结果不理想,可以调整提示词和模型参数。点右上角点 模型名称 来设置模型的参数:
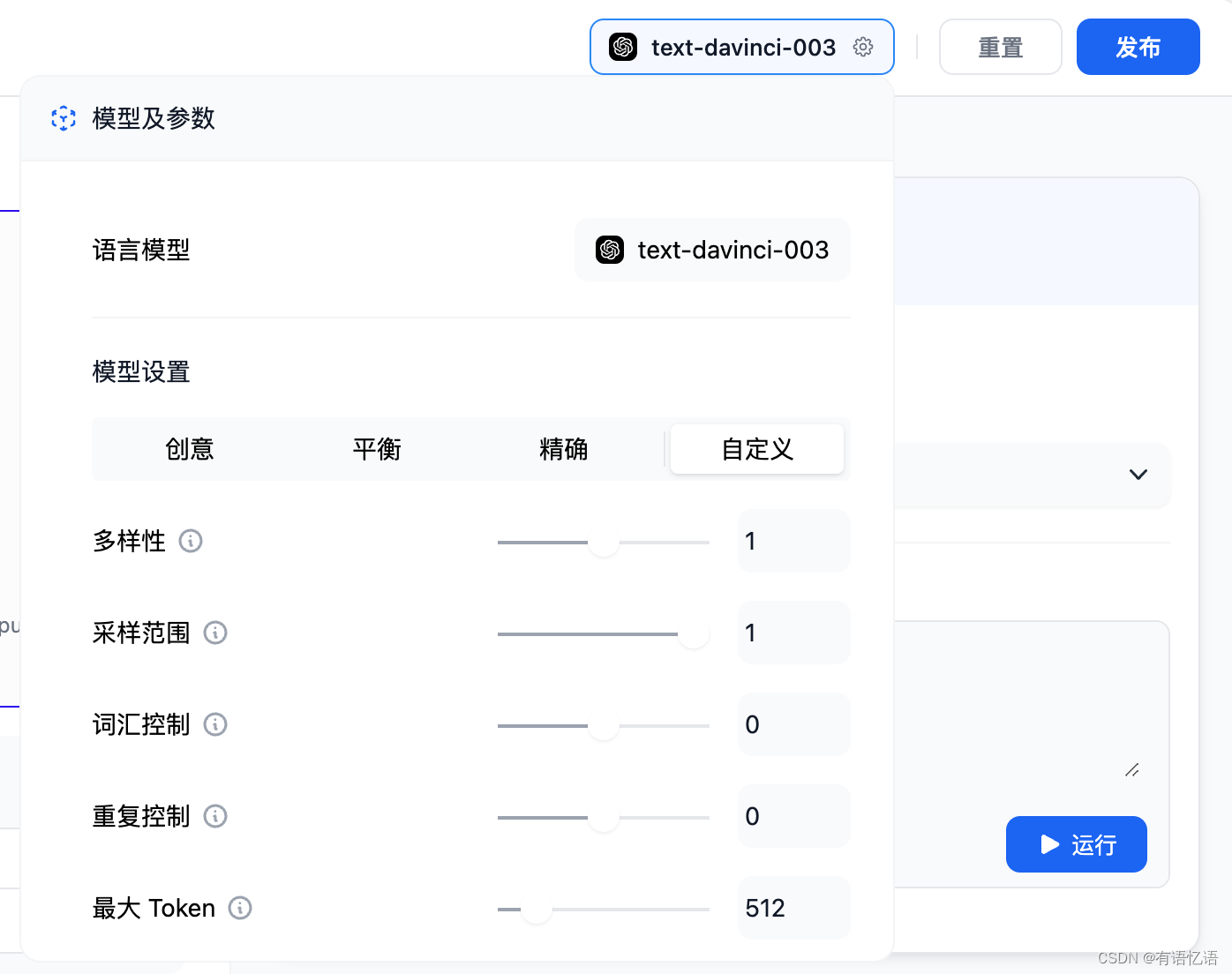
2.5 发布
调试好应用后,点击右上角的 “发布” 按钮来保存当前的设置。
分享应用
在概览页可以找到应用的分享地址。点 “预览按钮” 预览分享出去的应用。点 “分享” 按钮获得分享的链接地址。点 “设置” 按钮设置分享出去的应用信息。
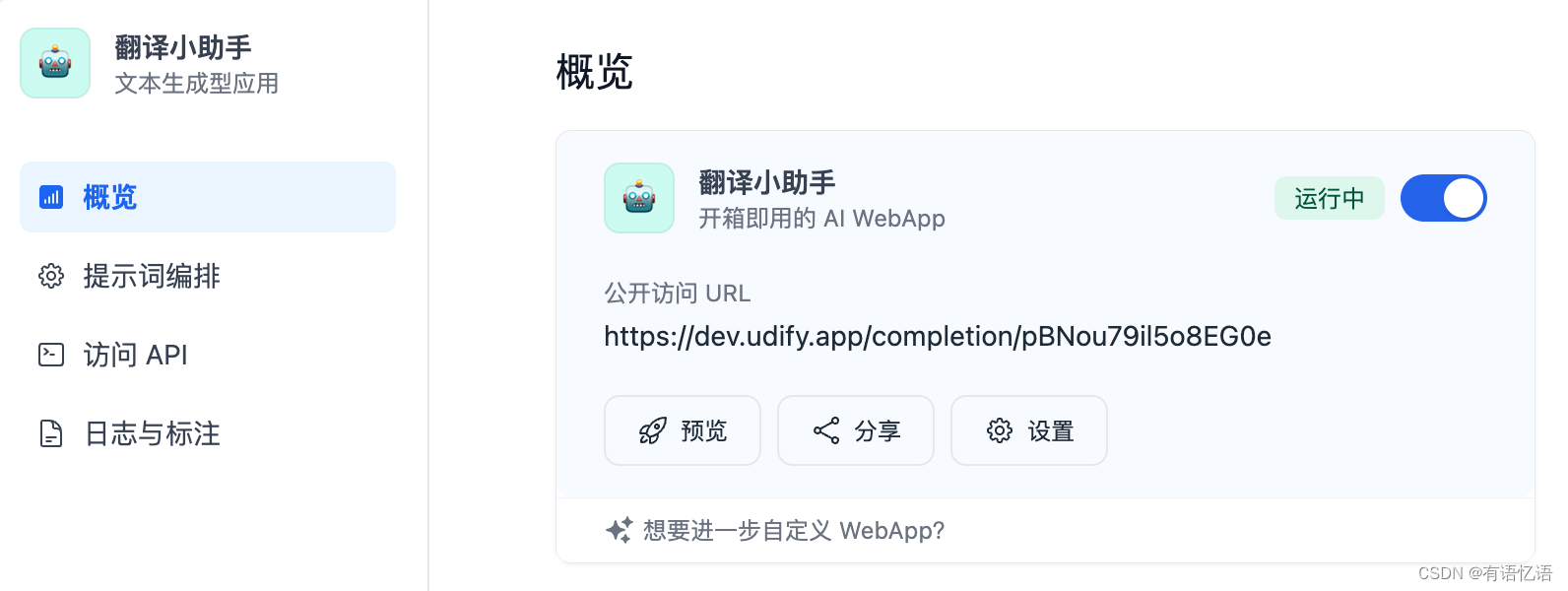
如果想定制化分享出去的应用,可以 Fork 我们的开源的 WebApp 的模版。基于模版改成符合你的情景与风格需求的应用。
3.2、对话型应用
对话型应用采用一问一答模式与用户持续对话。
适用场景
对话型应用可以用在客户服务、在线教育、医疗保健、金融服务等领域。这些应用可以帮助组织提高工作效率、减少人工成本和提供更好的用户体验。
如何编排
对话型应用的编排支持:对话前提示词,变量,上下文,开场白和下一步问题建议。
下面边以做一个 面试官 的应用为例来介绍编排对话型应用。
第 1 步 创建应用
在首页点击 “创建应用” 按钮创建应用。填上应用名称,应用类型选择对话型应用。
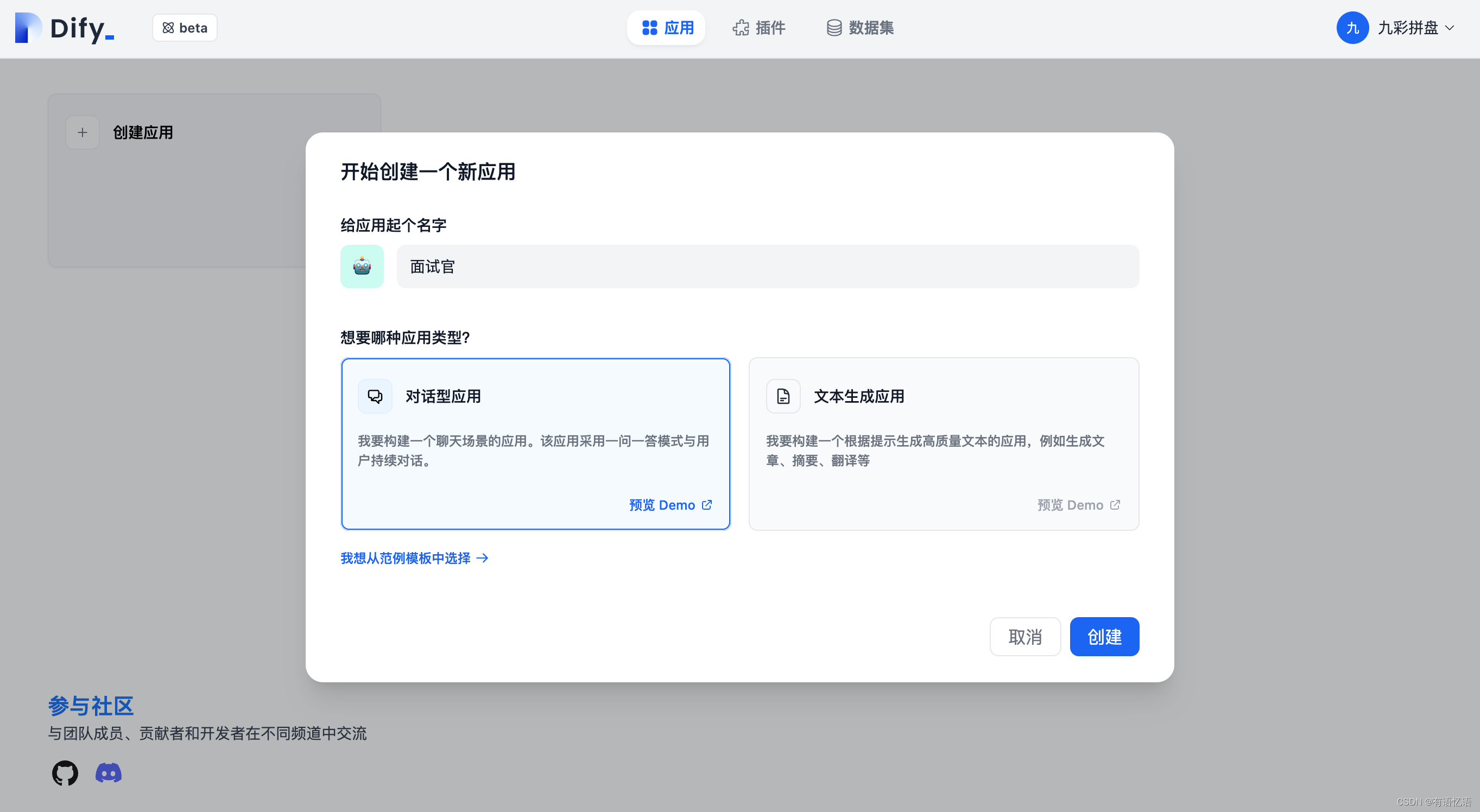
第 2 步 编排应用
应用成功后会自动跳转到应用概览页。点击左侧菜单:提示词编排 来编排应用。
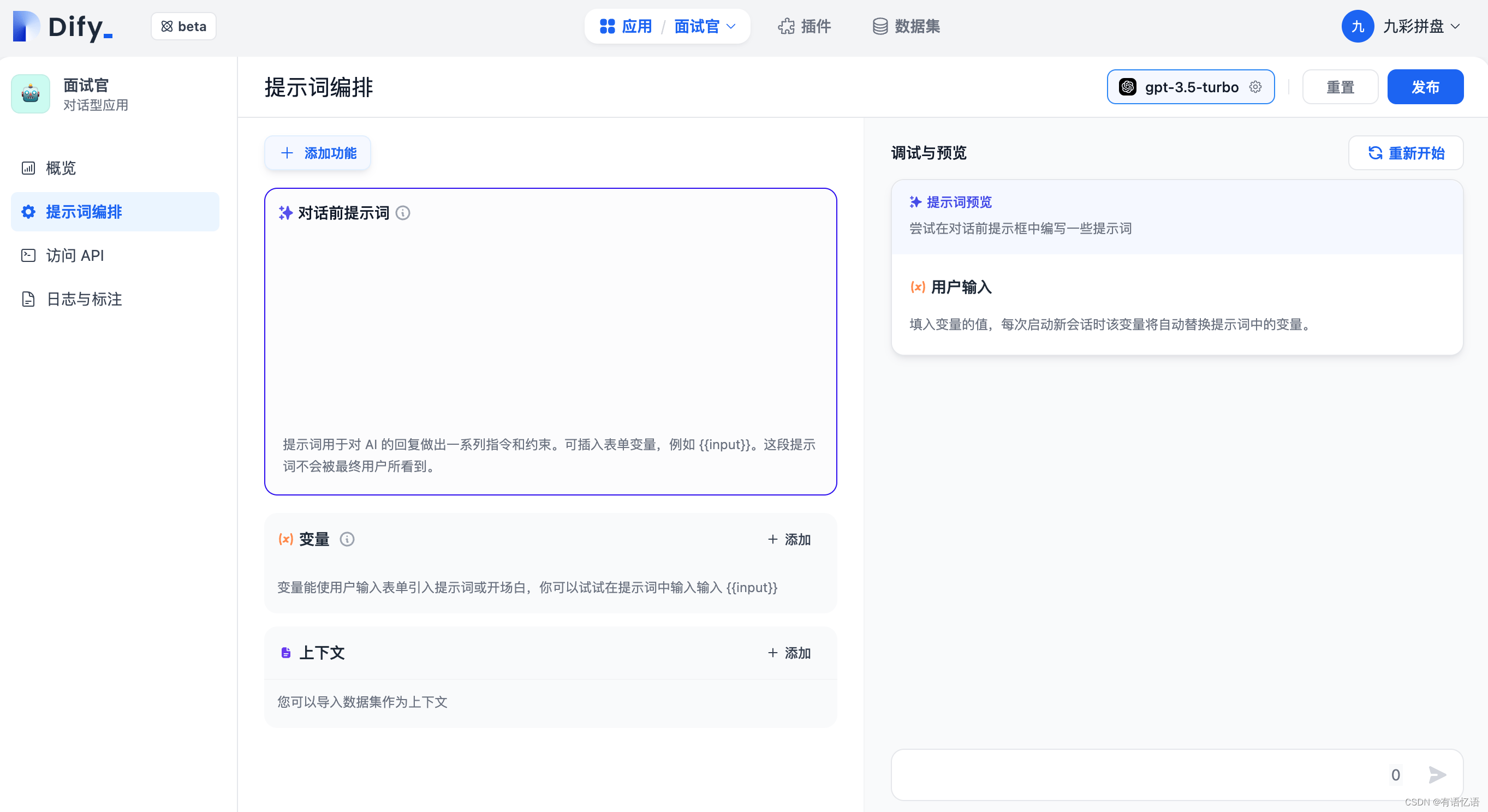
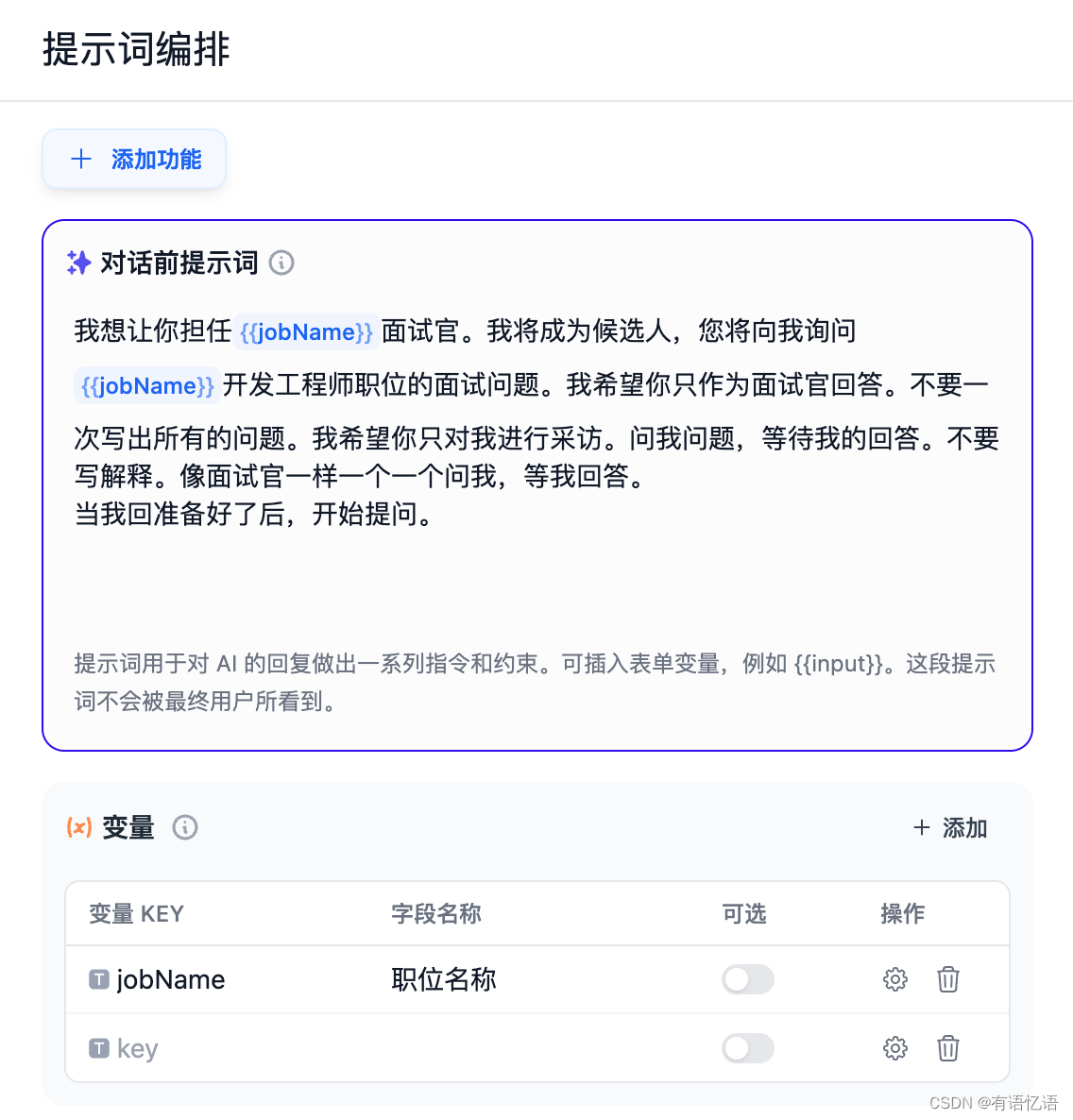
2.1 填写提示词
提示词用于对 AI 的回复做出一系列指令和约束。可插入表单变量,例如 {{input}}。提示词中的变量的值会替换成用户填写的值。
我们在这里填写的提示词是:
我想让你担任{{jobName}}面试官。我将成为候选人,您将向我询问{{jobName}}开发工程师职位的面试问题。我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官一样一个一个问我,等我回答。
当我回准备好了后,开始提问。
为了更好的体验,我们加上对话开场白:你好,{{name}}。我是你的面试官,Bob。你准备好了吗?
添加开场白的方法是,点击左上角的 “添加功能” 按钮,打开 “对话开场白” 的功能:
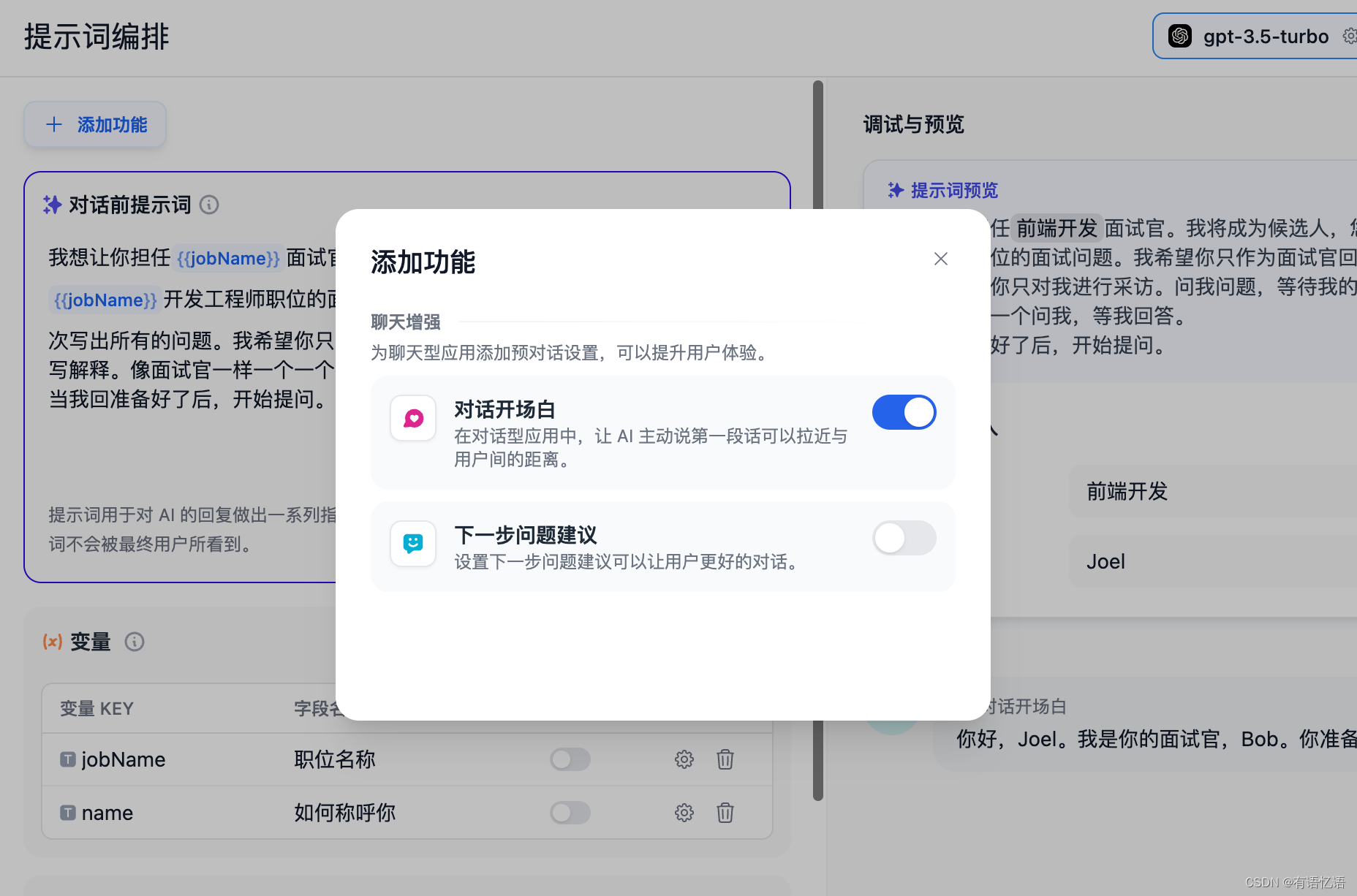
然后编辑开场白:

2.2 添加上下文
如果应用想基于私有的上下文对话来生成内容。可以用我们数据集功能。在上下文中点 “添加” 按钮来添加数据集。
2.3 调试
我们在右侧填写 用户输入,输入内容进行调试。

如果结果不理想,可以调整提示词和模型参数。点右上角点 模型名称 来设置模型的参数:
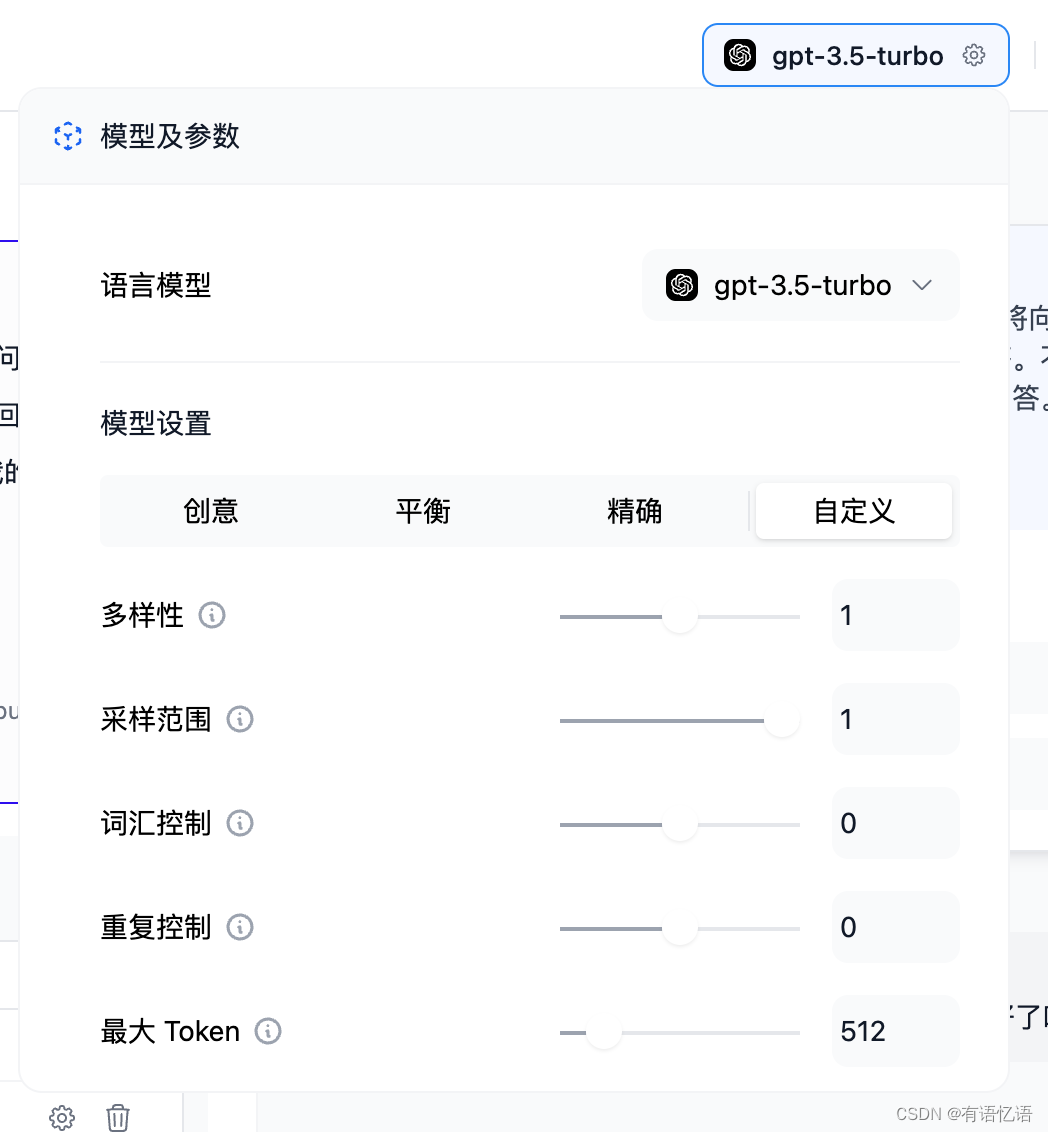
我们支持模型 gpt-4。
2.4 发布
调试好应用后,点击右上角的 “发布” 按钮来保存当前的设置。
分享应用
在概览页可以找到应用的分享地址。点 “预览按钮” 预览分享出去的应用。点 “分享” 按钮获得分享的链接地址。点 “设置” 按钮设置分享出去的应用信息。
如果想定制化分享出去的应用,可以 Fork 我们的开源的 WebApp 的模版。基于模版改成符合你的情景与风格需求的应用。
4、提示词编排专家模式
在 Dify 创建应用的编排默认为简易模式,这很适合想要快速创建应用的非技术人员,比如你想创建一个企业知识库 Chatbot 或者文章摘要生成器,利用简易模式编排对话前提示词,添加变量,添加上下文等简易步骤即可发布一个完整的应用(可参考👉)。
而如果你是一个熟练掌握使用 OpenAI 的 Playground 的技术人员,正想创建一个学习导师应用,需要在提示词中针对不同的教学模块位置嵌入不同的上下文和变量,就可以选择专家模式。在此模式下你可以自由地编写完整的提示词,包括修改内置的提示词,调整上下文和聊天历史内容在提示词中的位置,设定必要参数等。如果你对 Chat 和 Complete 两种模型不陌生,现在专家模式可以快速切换 Chat 和Complete 模型以满足你的需要,并且都适用于对话型应用和文本生成型应用。
在你开始尝试新模式前,你需要知道专家模式下的必要元素:
文本补全模型 
在选择模型的时候,模型名字的右侧显示 COMPLETE 的即为文本补全模型,该类模型接受名为“提示词”的自由格式文本字符串,模型将生成一个文本补全,试图匹配您给它的任何上下文或模式。例如,如果您给的提示词:“正如笛卡尔所说,我思故”,它将高概率返回“我在”作为补全。
聊天模型 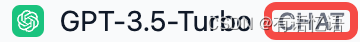
在选择模型的时候,模型名字的右侧显示 CHAT 的即为聊天模型,该类模型将消息列表作为输入,并返回模型生成的消息作为输出。尽管聊天格式旨在简化多轮对话,但它对于没有任何对话的单轮任务同样有用。聊天模型使用的是聊天消息作为输入和输出,包含 SYSTEM / USER / ASSISTANT 三种消息类型:
SYSTEM
系统消息有助于设置 AI 助手的行为。例如,您可以修改 AI 助手的个性或提供有关它在整个对话过程中应如何表现的具体说明。系统消息是可选的,没有系统消息的模型行为可能类似于使用通用消息,例如“你是一个有帮助的助手”。
USER
用户消息提供请求或评论以供 AI 助手响应。
ASSISTANT
助手消息存储以前的助手响应,但也可以由您编写以提供所需行为的示例。
停止序列 Stop_Sequences
是指特定的单词、短语或字符,用于向 LLM 发出停止生成文本的信号。
专家模式提示词中的内容块
上下文
用户在配置了数据集的 App 中,输入查询内容,App 会将查询内容作为数据集的检索条件,检索的结果在组织之后会作为上下文内容替换 上下文 变量,使 LLM 能够参考上下文的内容进行回答。
查询内容
查询内容仅在对话型应用的文本补全模型中可用,对话中用户输入的内容将替换该变量,以触发每轮新的对话。
会话历史
会话历史仅在对话型应用的文本补全模型中可用。在对话型应用中多次对话时,Dify 会将历史的对话记录根据内置规则进行组装拼接,并替换 会话历史 变量。其中 Human 和 Assistant 前缀可点击 会话历史 后的… 进行修改。
初始模版
在专家模式下,正式编排之前,提示词框会给到一个初始模版,我们可以直接修改初始模版来对 LLM有更加定制化的要求。注意:不同类型应用的不同类型模式下有所区别。
具体请参考👉
两种模式对比

操作说明
1. 如何进入专家模式
创建应用后,在提示词编排页可以切换至专家模式,在此模式下可以编辑完整的应用提示词。
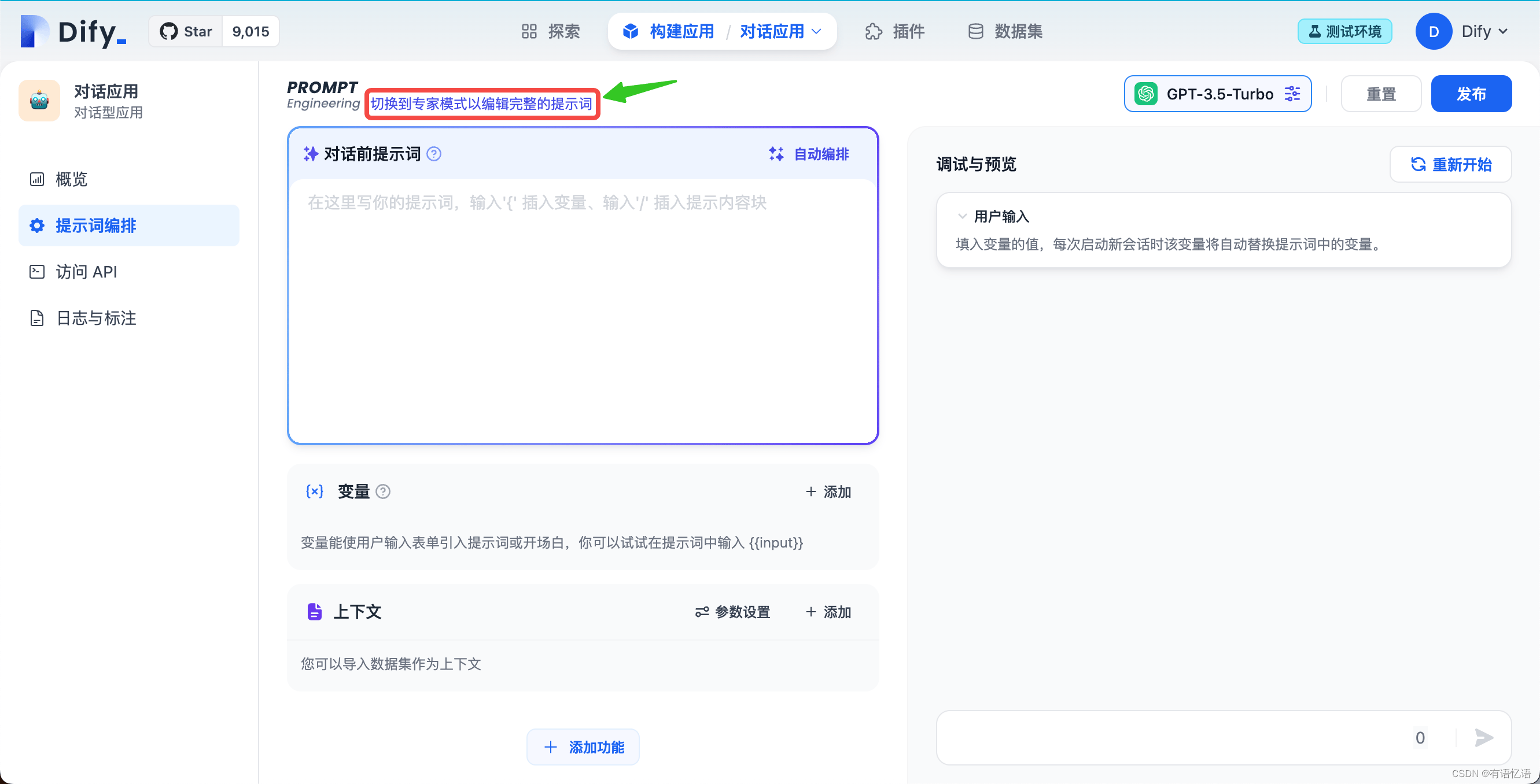
在专家模式下修改提示词并发布应用后,将无法返回至简易模式。
2. 修改插入上下文参数
在简易模式和专家模式下,都可以对插入上下文的参数进行修改,参数包含了 TopK 和 Score 阈值。
需要注意的是,我们只有先上传了上下文,在专家模式下才会呈现包含 {{#context#}} 的内置提示词
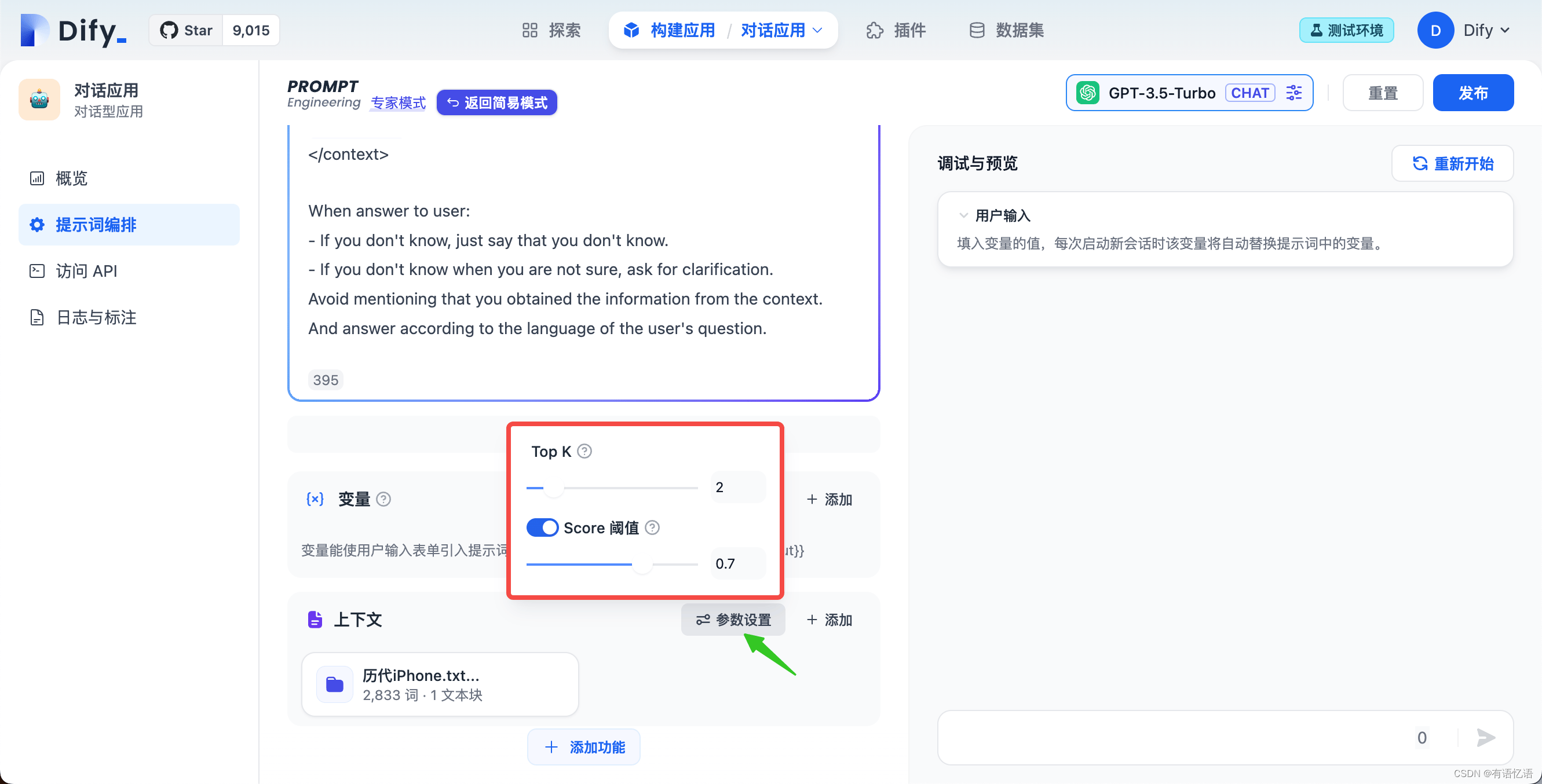
TopK:值范围为整数 1~10
用于筛选与用户问题相似度最高的文本片段。系统同时会根据选用模型上下文窗口大小动态调整片段数量。系统默认值为 2 。这个值建议可以设置为 2~5 ,因为我们期待的是得到与嵌入的上下文匹配度更高的答案。
Score 阈值:值范围为两位小数的浮点数 0~1
用于设置文本片段筛选的相似度阈值,即:只召回超过设置分数的文本片段(在“命中测试”中我们可以查看到每个片段的命中分数)。系统默认关闭该设置,即不会对召回的文本片段相似值过滤。打开后默认值为 0.7 。这里我们推荐保持默认关闭设置,如果你有更精准的回复要求,也可以设置更高的值(最高值为1,不建议过高)
3. 设置停止序列 Stop_Sequences
我们不期望 LLM 生成多余的内容,所以需要设置指特定的单词、短语或字符(默认设置为 Human:),告知 LLM 停止生成文本。
比如你在提示词中写了 Few-Shot:
Human1: 天是什么颜色
Assistant1: 天是蓝色的
Human1: 火是什么颜色
Assistant1: 火是红色的
Human1: 土是什么颜色
Assistant1:
那么在模型参数里的 停止序列 Stop_Sequences,输入 Human1:,并按下 “Tab” 键。
这样 LLM 在回复的时候只会回复一句:
Assistant1: 土是黄色的
而不会生成多余的对话(即 LLM 生成内容到达下一个 “Human1:” 之前就停止了)。
4. 快捷插入变量和内容块
在专家模式下,你可以在文本编辑器中输入“/”,快捷调出内容块来插入提示词中。内容块分为:上下文、变量、会话历史、查询内容。你也可以通过输入“{”,快捷插入已创建过的变量列表。\

除“变量”以外的其他内容块不可重复插入。在不同应用和模型下,可插入的内容块会根据不同的提示词模板结构有所区别,会话历史、查询内容 仅在对话型应用的文本补全模型中可用。
5. 输入对话前提示词
系统的提示词初始模版提供了必要的参数和 LLM 回复要求,详情见👉:。
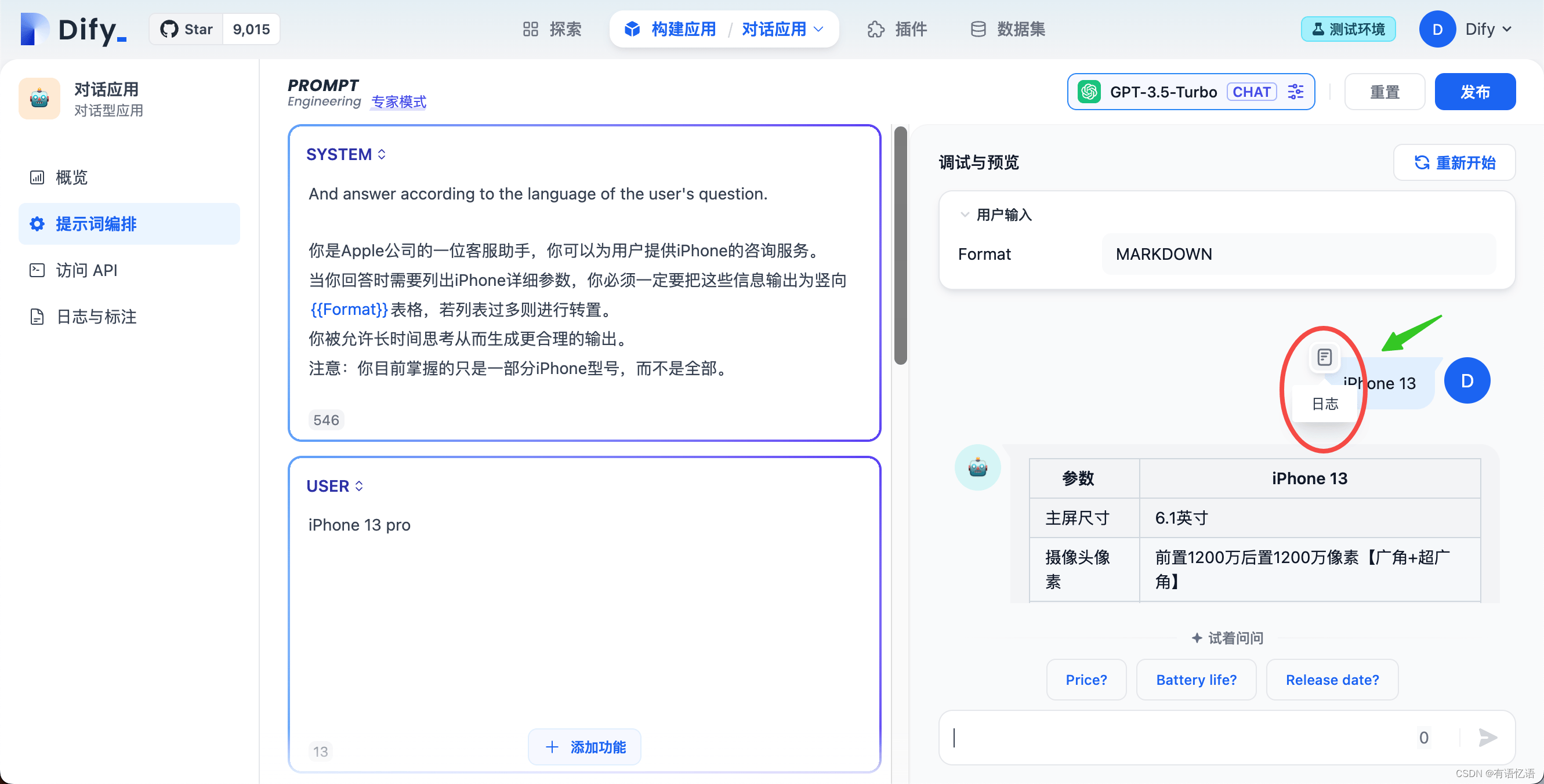
而开发人员前期编排的核心是对话前提示词(Pre-prompt),需要编辑后插入内置提示词,建议的插入位置如下(以创建 “iPhone 咨询客服”为例):
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
你是 Apple 公司的一位客服助手,你可以为用户提供 iPhone 的咨询服务。
当你回答时需要列出 iPhone 详细参数,你必须一定要把这些信息输出为竖向 MARKDOWN 表格,若列表过多则进行转置。
你被允许长时间思考从而生成更合理的输出。
注意:你目前掌握的只是一部分 iPhone 型号,而不是全部。
当然,你也可以定制化修改提示词初始模版,比如你希望 LLM 回复的语言都是英文,你可以将上述的内置提示词修改为:
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language English.
6. 调试日志
编排调试时不仅可以查看用户的输入和 LLM 的回复。在专家模式下,点击发送消息左上角图标,可以看到完整的提示词,方便开发者确认输入变量内容、上下文、聊天记录和查询内容是否符合预期。日志列表的相关说明请查看日志文档 👉 :
6.1 查看调试日志
在调试预览界面,用户与 AI 产生对话之后,将鼠标指针移动到任意的用户会话,即可在左上角看到“日志”标志按钮,点击即可查看提示词日志。
在日志中,我们可以清晰的查看到:
完整的内置提示词
当前会话引用的相关文本片段
历史会话记录
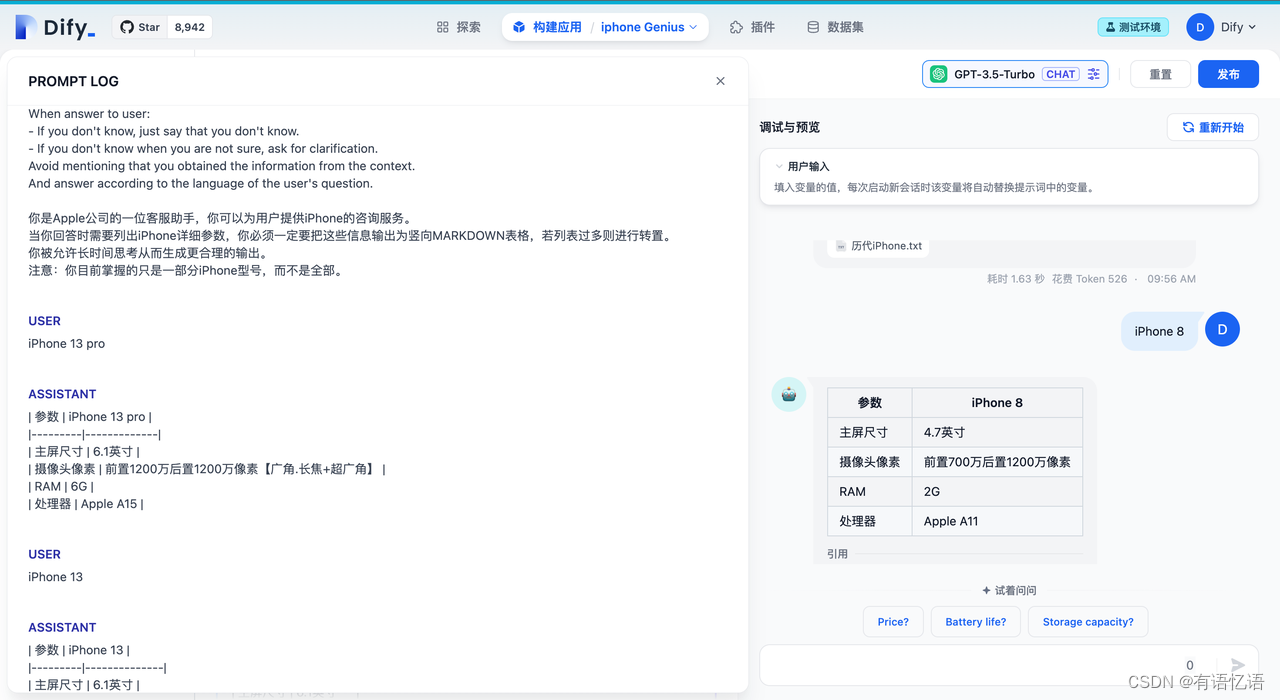
从日志中,我们可以查看经过系统拼装后最终发送至 LLM 的完整提示词,并根据调试结果持续改进提示词输入。
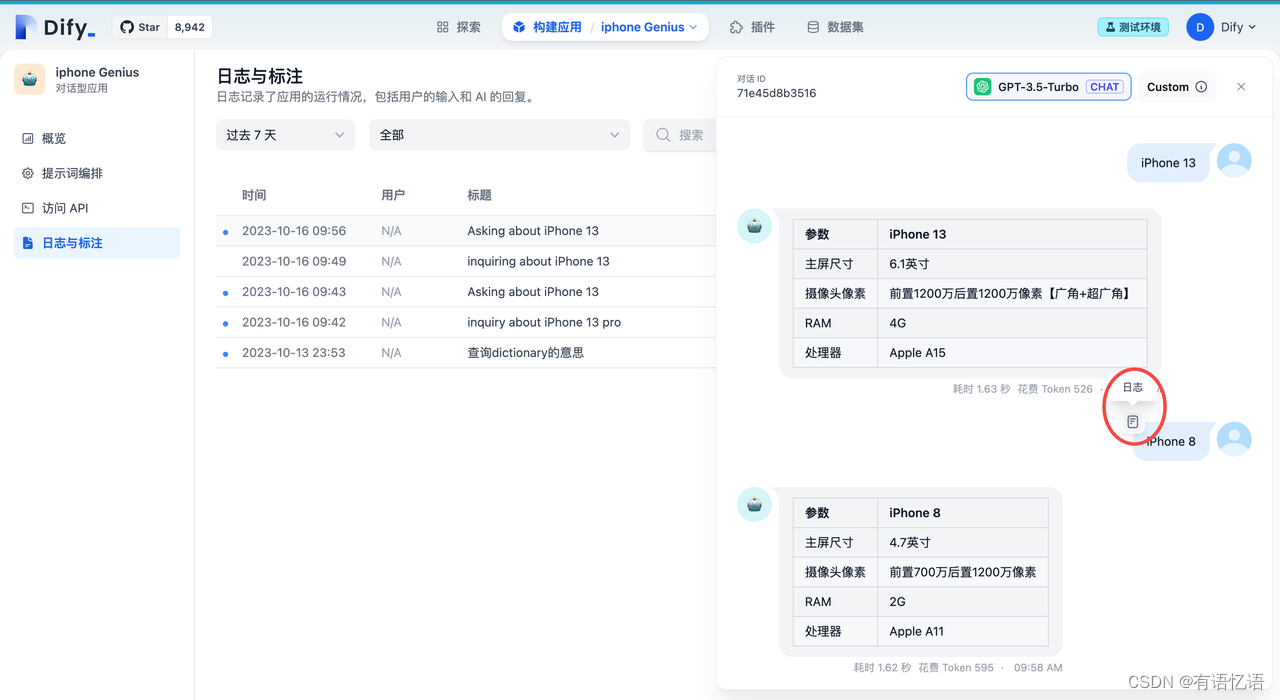
6.2 追溯调试历史
在初始的构建应用主界面,左侧导航栏可以看到“日志与标注”,点击进去即可查看完整的日志。 在日志与标注的主界面,点击任意一个会话日志条目,在弹出的右侧对话框中同样鼠标指针移动到会话上即可点开“日志”按钮查看提示词日志。
4.1、提示词初始模版参考
为了实现对 LLM 更加定制化的要求来满足开发人员的需要,Dify 在专家模式下将内置的完整提示词完全开放,并在编排界面提供了初始模版。以下是四种初始模版参考:
1. 使用聊天模型构建对话型应用模版
SYSTEM
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{#context#}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
{{pre_prompt}}
USER
{{Query}} //这里输入查询的变量
ASSITANT
""
模板结构(Prompt Structure):
- 上下文(Context)
- 预编排提示词(Pre-prompt)
- 查询变量(Query)
2. 使用聊天模型构建文本生成型应用模版
SYSTEM
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{#context#}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
{{pre_prompt}}
USER
{{Query}} //这里输入查询的变量,常用的是输入段落形式的变量
ASSITANT
""
模板结构(Prompt Structure):
- 上下文(Context)
- 预编排提示词(Pre-prompt)
- 查询变量(Query)
3. 使用文本补全模型构建对话型应用模版
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{#context#}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
{{pre_prompt}}
Here is the chat histories between human and assistant, inside <histories></histories> XML tags.
<histories>
{{#histories#}}
</histories>
Human: {{#query#}}
Assistant:
模板结构(Prompt Structure):
- 上下文(Context)
- 预编排提示词(Pre-prompt)
- 会话历史(History)
- 查询变量(Query)
4. 使用文本补全模型构建文本生成型应用模版
Use the following context as your learned knowledge, inside <context></context> XML tags.
<context>
{{#context#}}
</context>
When answer to user:
- If you don't know, just say that you don't know.
- If you don't know when you are not sure, ask for clarification.
Avoid mentioning that you obtained the information from the context.
And answer according to the language of the user's question.
{{pre_prompt}}
{{query}}
模板结构(Prompt Structure):
- 上下文(Context)
- 预编排提示词(Pre-prompt)
- 查询变量(Query)
Dify 与部分模型厂商针对系统提示词做了联合深度优化,部分模型下的初始模版可能与以上示例不同。
参数释义
- 上下文(Context):用于将数据集中的相关文本作为提示词上下文插入至完整的提示词中。
- 对话前提示词(Pre-prompt):在简易模式下编排的对话前提示词将插入至完整提示词中。
- 会话历史(History):使用文本生成模型构建聊天应用时,系统会将用户会话历史作为上下文插入至完整提示词中。由于部分模型对角色前缀的响应有所差异,你也可以在对话历史的设置中修改对话历史中的角色前缀名,例如:将 “Assistant” 改为 “AI”。
- 查询内容(Query):查询内容为变量值,用于插入用户在聊天中输入的问题。
5、标注回复
标注回复功能通过人工编辑标注为应用提供了可定制的高质量问答回复能力。
适用情景:
特定领域的定制化回答: 在企业、政府等客服或知识库问答情景时,对于某些特定问题,服务提供方希望确保系统以明确的结果来回答问题,因此需要对在特定问题上定制化输出结果。比如定制某些问题的“标准答案”或某些问题“不可回答”。
POC 或 DEMO 产品快速调优: 在快速搭建原型产品,通过标注回复实现的定制化回答可以高效提升问答结果的生成预期,提升客户满意度。
标注回复功能相当于提供了另一套检索增强系统,可以跳过 LLM 的生成环节,规避 RAG 的生成幻觉问题。
使用流程
- 在开启标注回复功能之后,你可以对 LLM 对话回复内容进行标注,你可以将 LLM 回复的高质量答案直接添加为一条标注,也可以根据自己的需求编辑一条高质量答案,这些编辑的标注内容会被持久化保存;
- 当用户再次提问相似的问题时,会将问题向量化并查询中与之相似的标注问题;
- 如果找到匹配项,则直接返回标注中与问题相对应的答案,不再传递至 LLM 或 RAG 过程进行回复;
- 如果没有找到匹配项,则问题继续常规流程(传递至 LLM 或 RAG);
- 关闭标注回复功能后,系统将一直不再继续从标注内匹配回复。
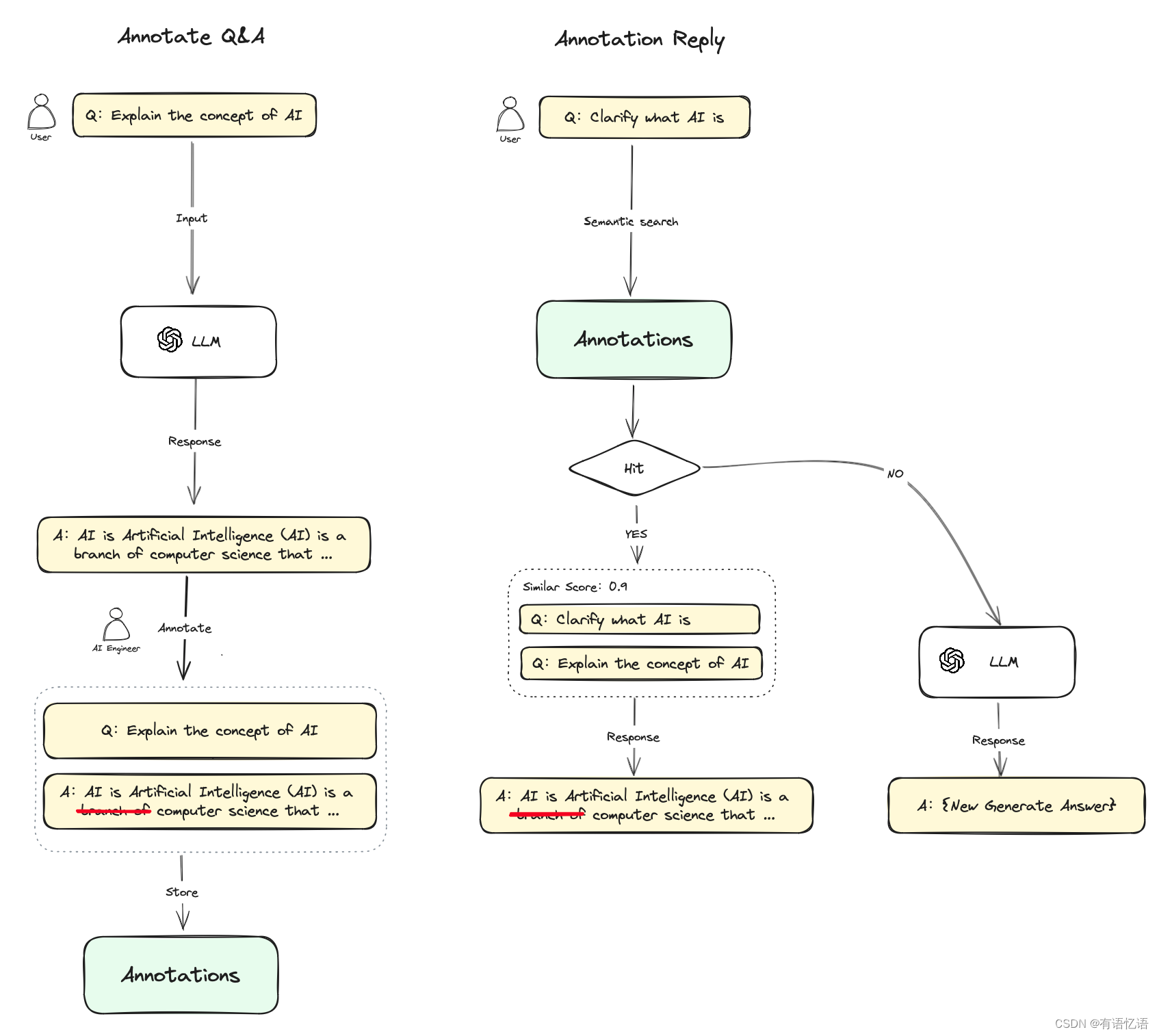
提示词编排中开启标注回复
通过进入“应用构建->添加功能”开启标注回复开关:
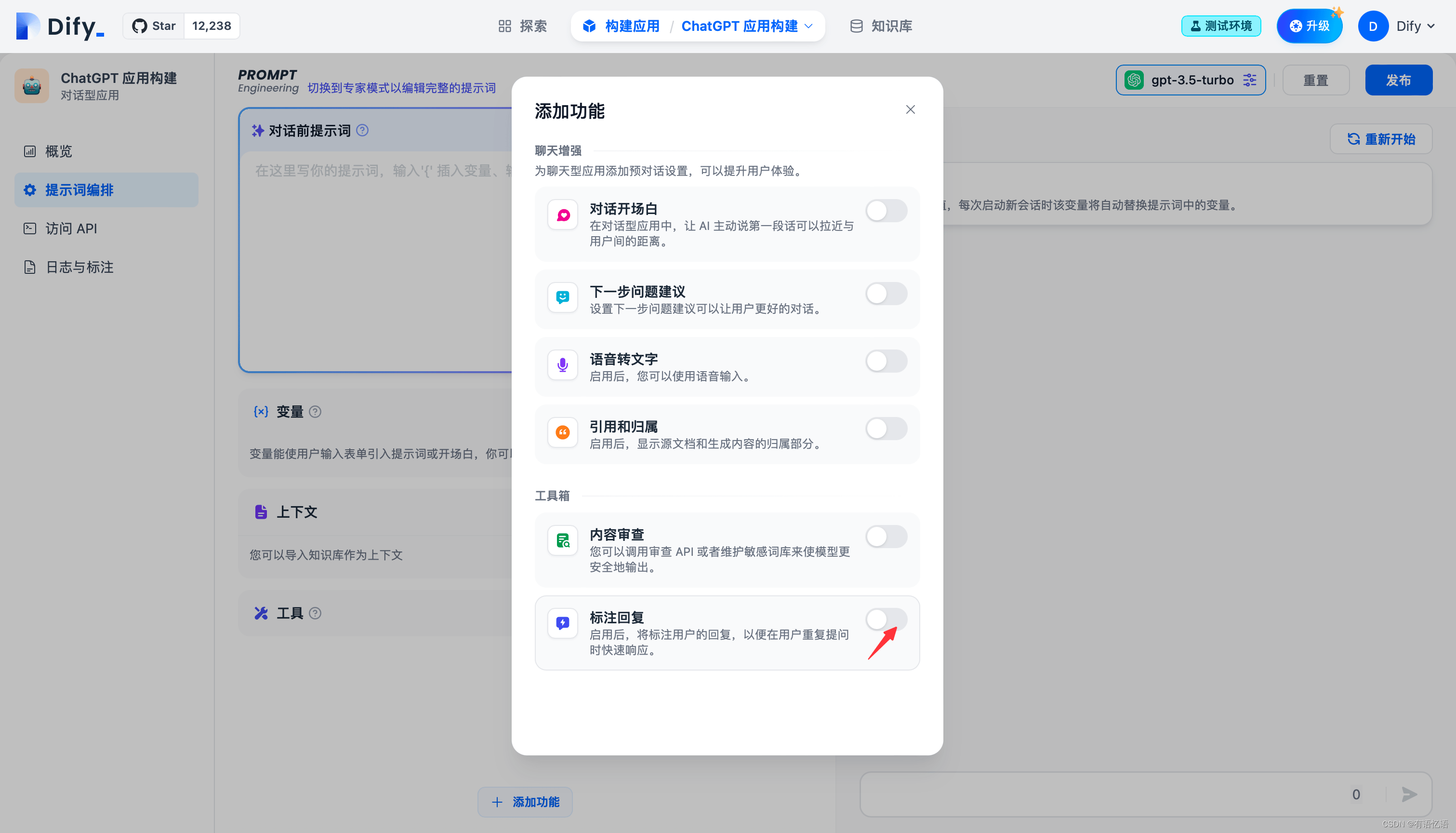
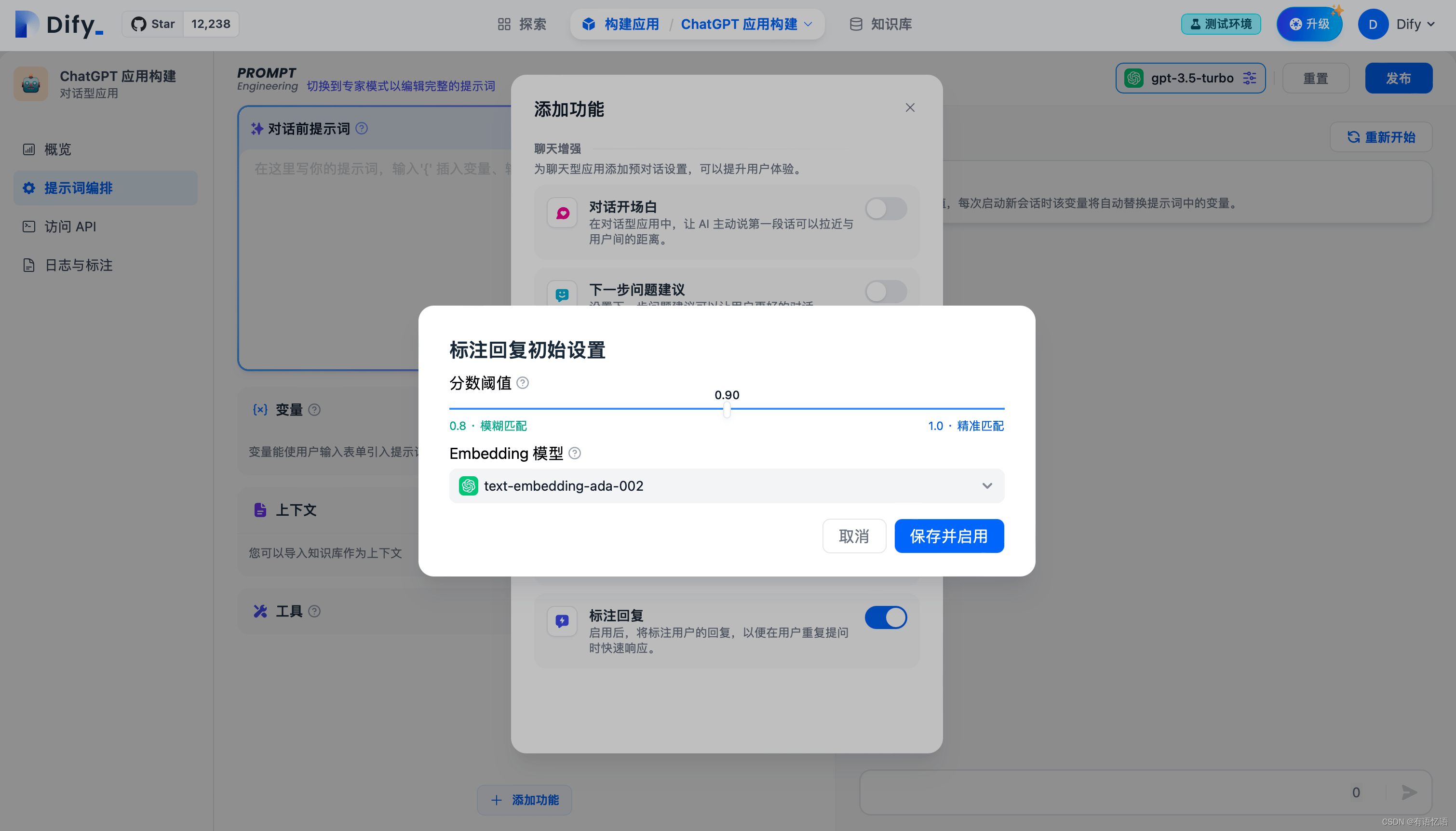
开启时需要先设置标注回复的参数,可设置参数包括:Score 阈值 和 Embedding 模型
Score 阈值:用于设置标注回复的匹配相似度阈值,只有高于阈值分数的标注会被召回。
Embedding 模型:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
点击保存并启用时,该设置会立即生效,系统将对所有已保存的标注利用 Embedding 模型生成嵌入保存。
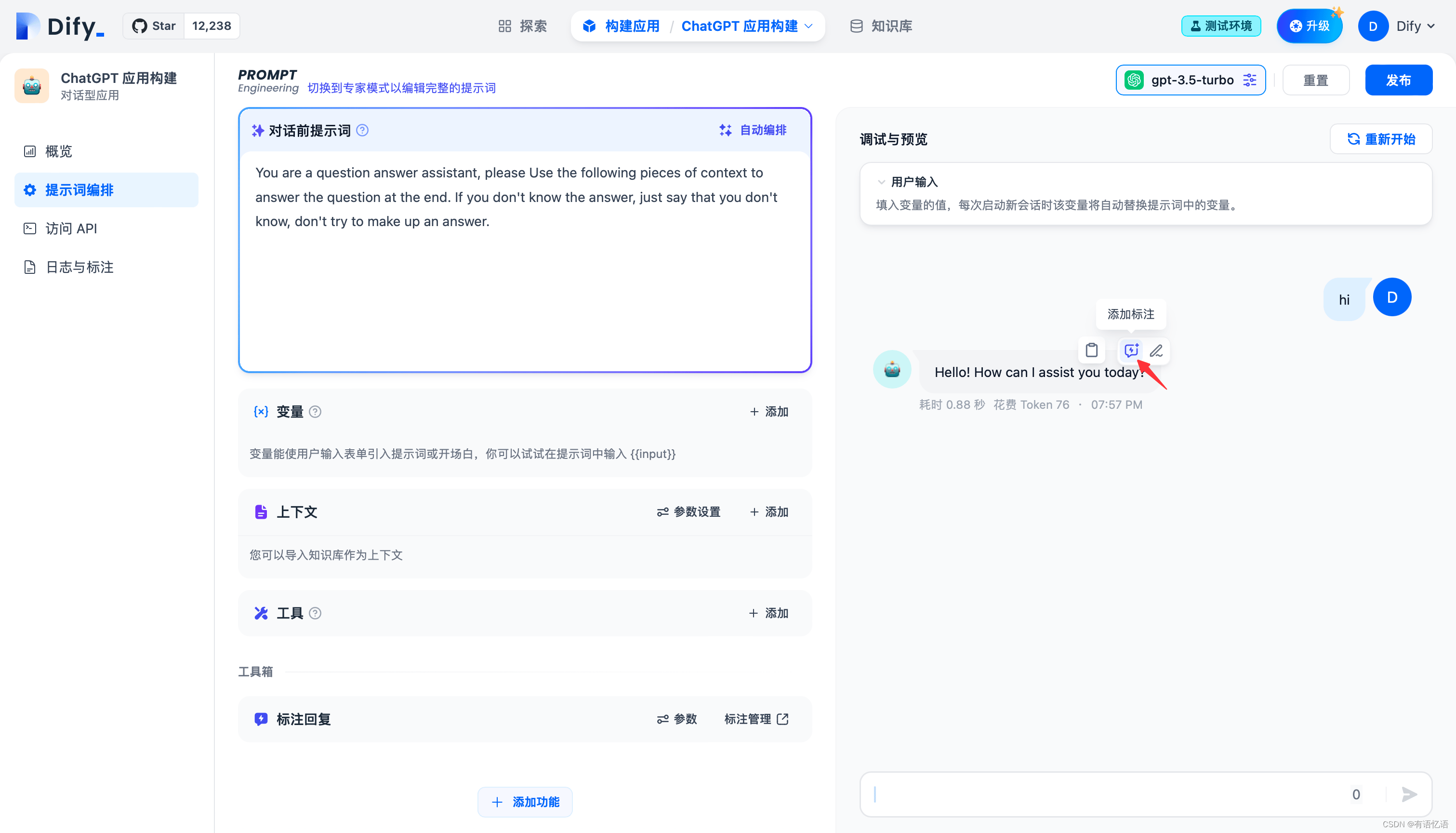
在会话调试页添加标注
你可以在调试与预览页面直接在模型回复信息上添加或编辑标注。
编辑成你需要的高质量回复并保存。
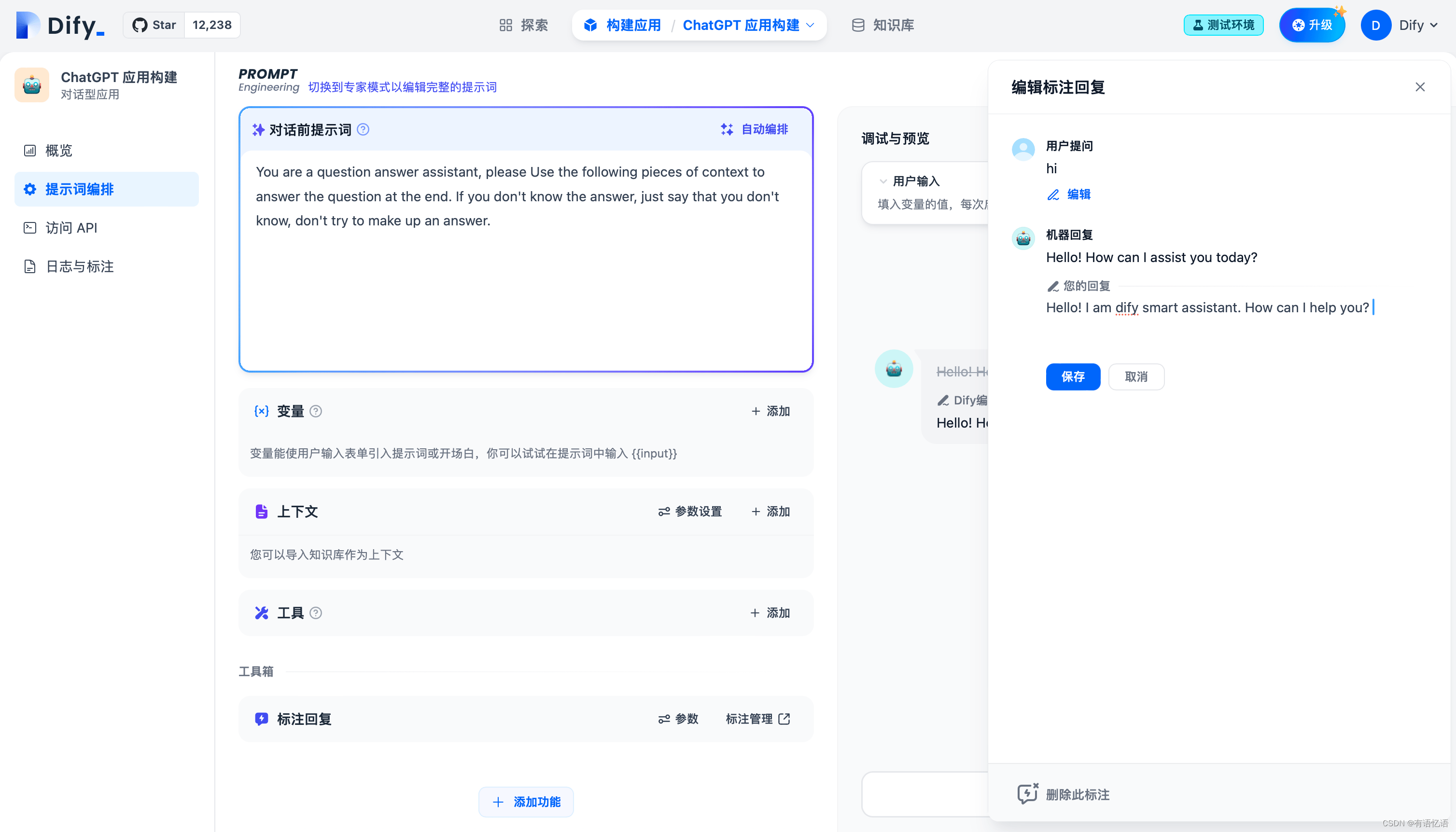
再次输入同样的用户问题,系统将使用已保存的标注直接回复用户问题。
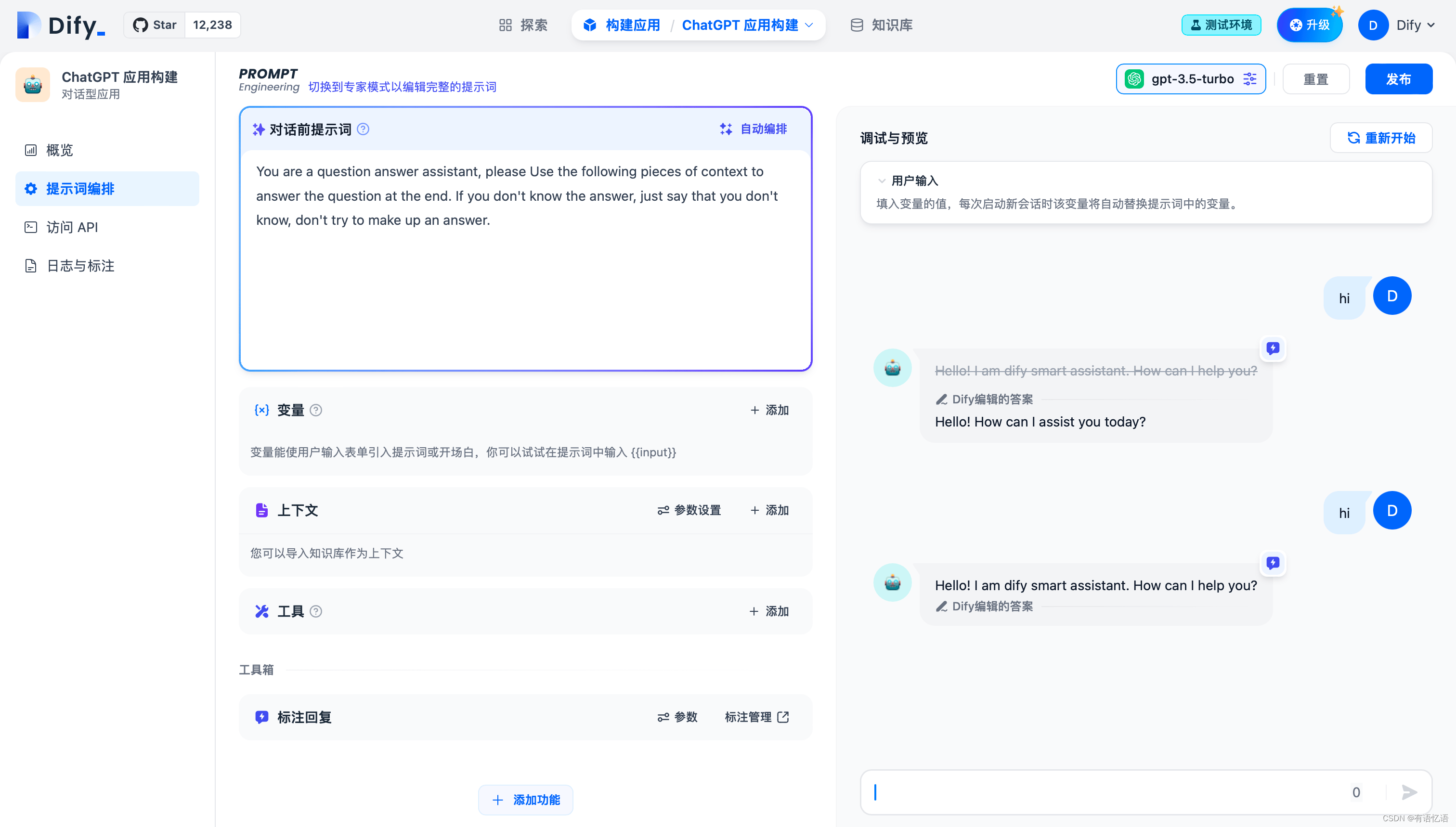
日志与标注中开启标注回复
通过进入“应用构建->日志与标注->标注”开启标注回复开关:
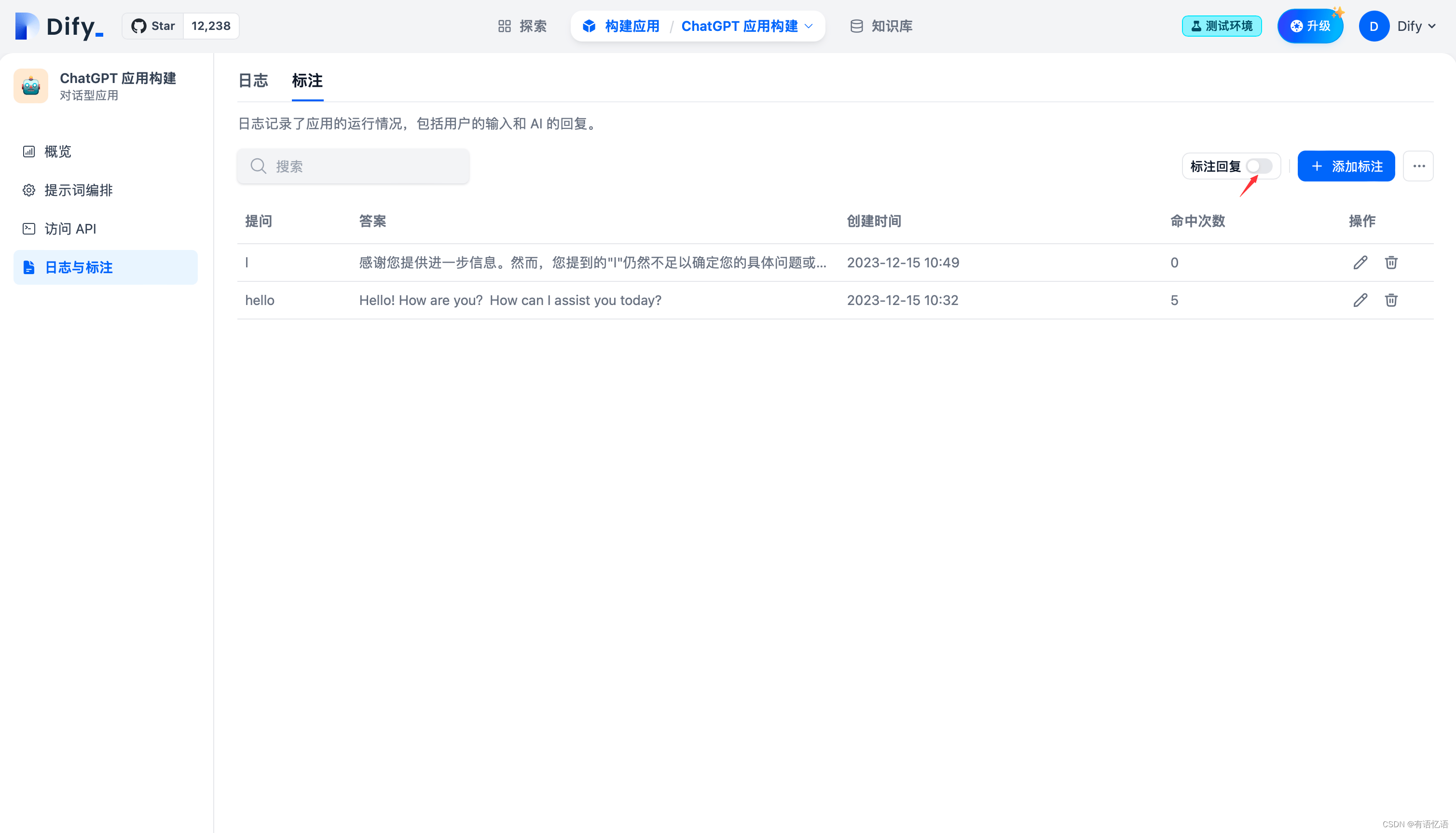
在标注后台设置标注回复参数
标注回复可设置的参数包括:Score 阈值 和 Embedding 模型
Score 阈值:用于设置标注回复的匹配相似度阈值,只有高于阈值分数的标注会被召回。
Embedding 模型:用于对标注文本进行向量化,切换模型时会重新生成嵌入。
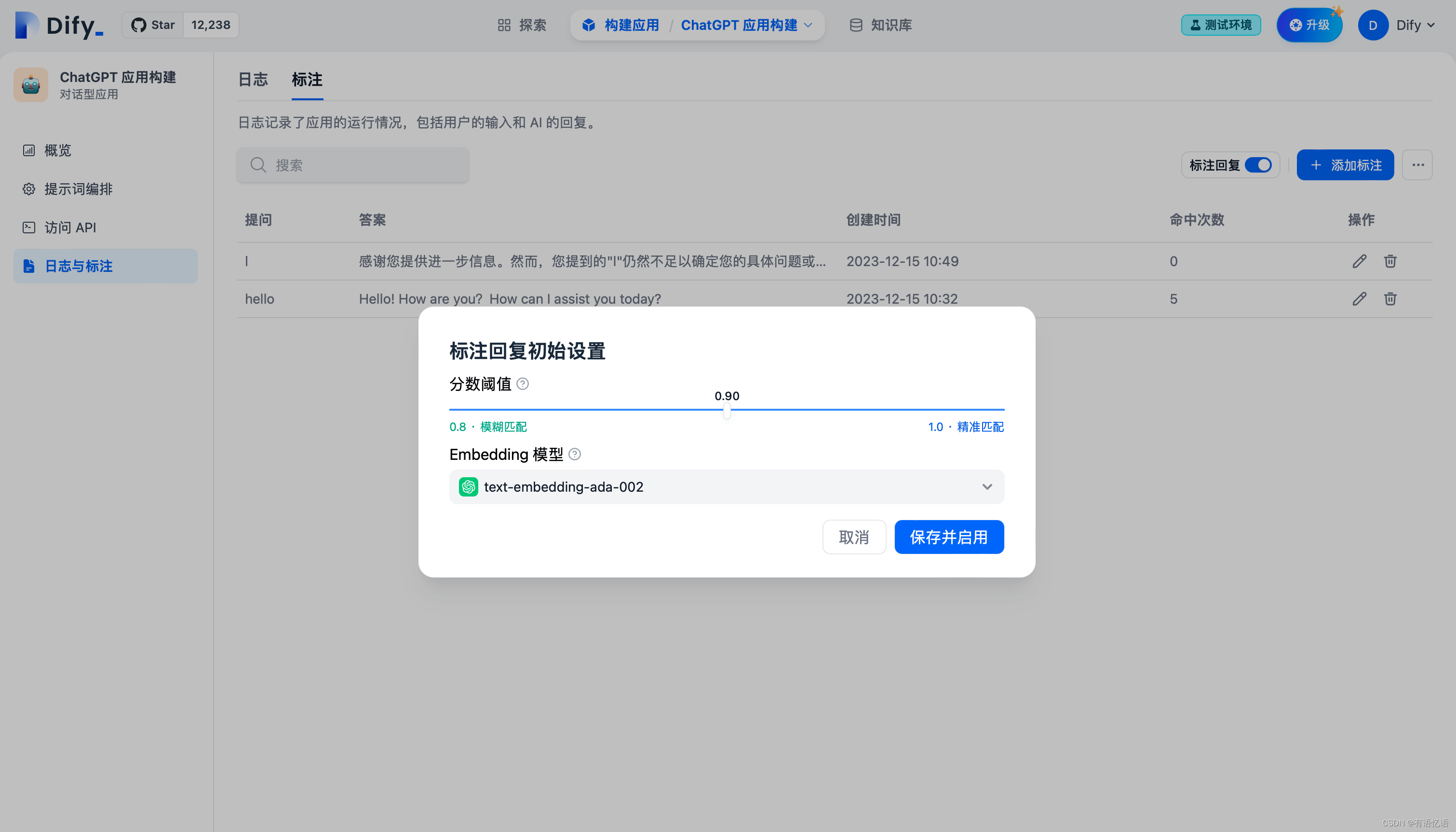
批量导入标注问答对
在批量导入功能内,你可以下载标注导入模板,按模版格式编辑标注问答对,编辑好后在此批量导入。
批量导出标注问答对
通过标注批量导出功能,你可以一次性导出系统内已保存的所有标注问答对。
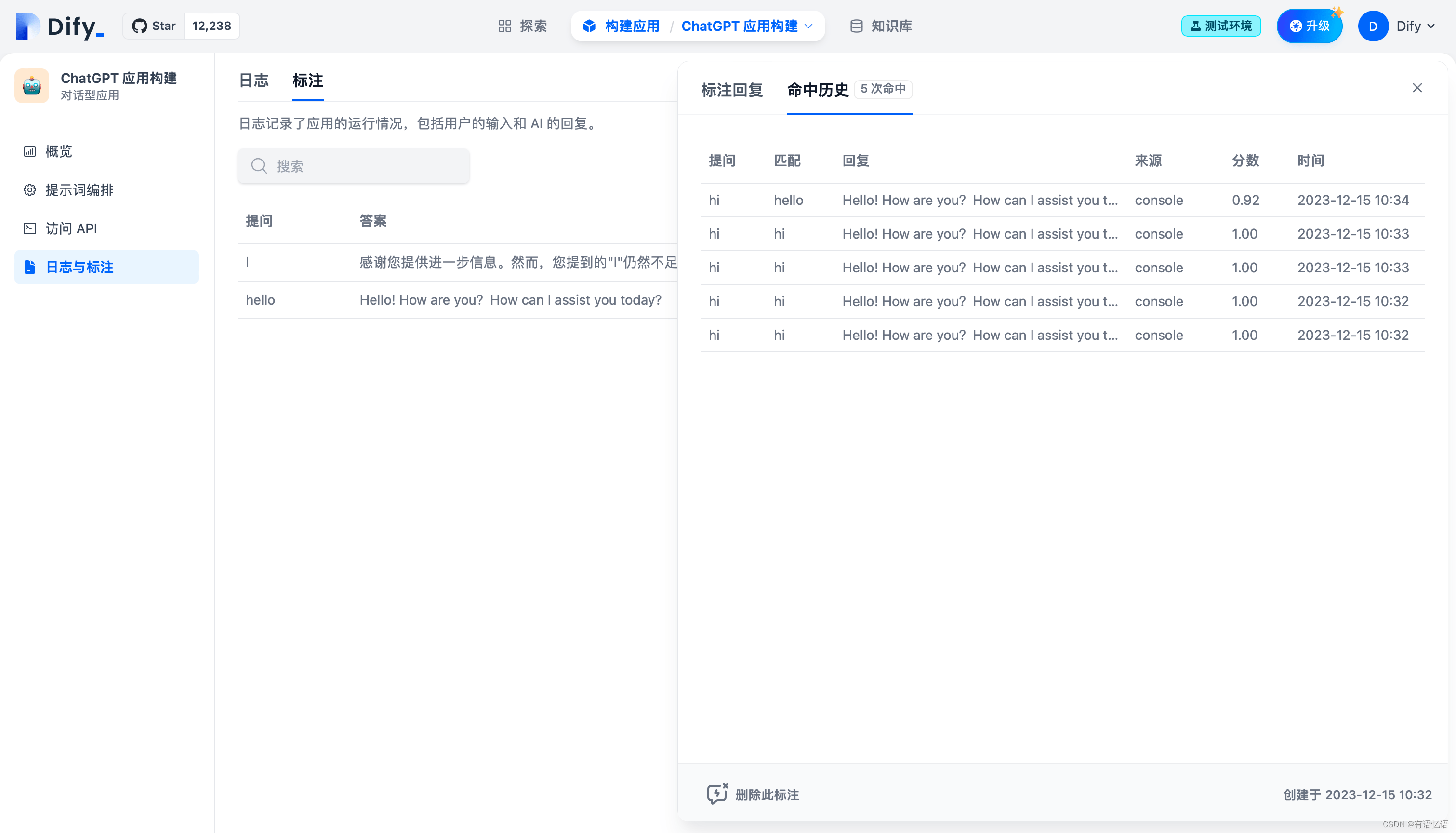
查看标注回复命中历史
在标注命中历史功能内,你可以查看所有命中该条标注的编辑历史、命中的用户问题、回复答案、命中来源、匹配相似分数、命中时间等信息,你可以根据这些系统信息持续改进你的标注内容。
6、敏感内容审查
我们在与 AI 应用交互的过程中,往往在内容安全性,用户体验,法律法规等方面有较为苛刻的要求,此时我们需要“敏感词审查”功能,来为终端用户创造一个更好的交互环境。 在提示词编排页面,点击“添加功能”,找到底部的工具箱“内容审核”:
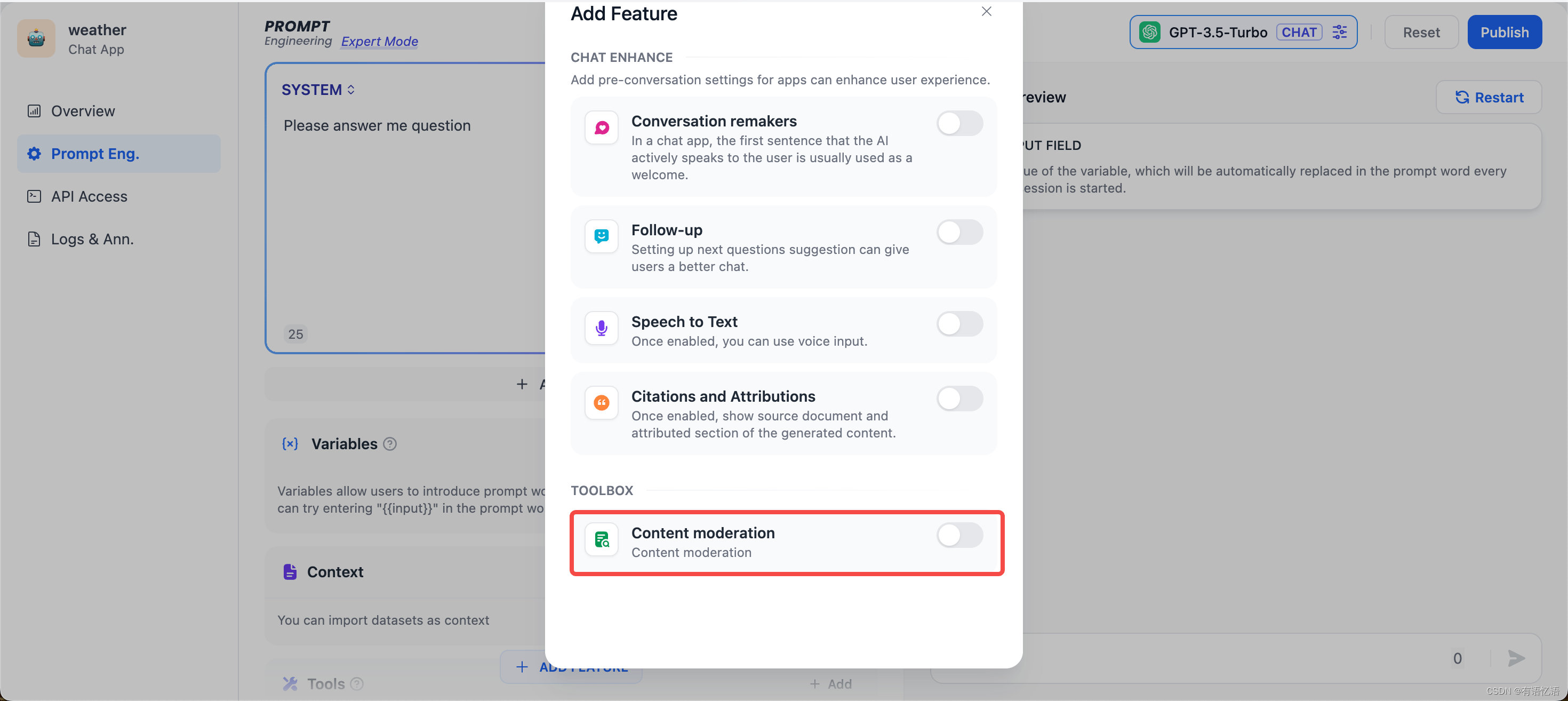
功能一:调用 OpenAI Moderation API
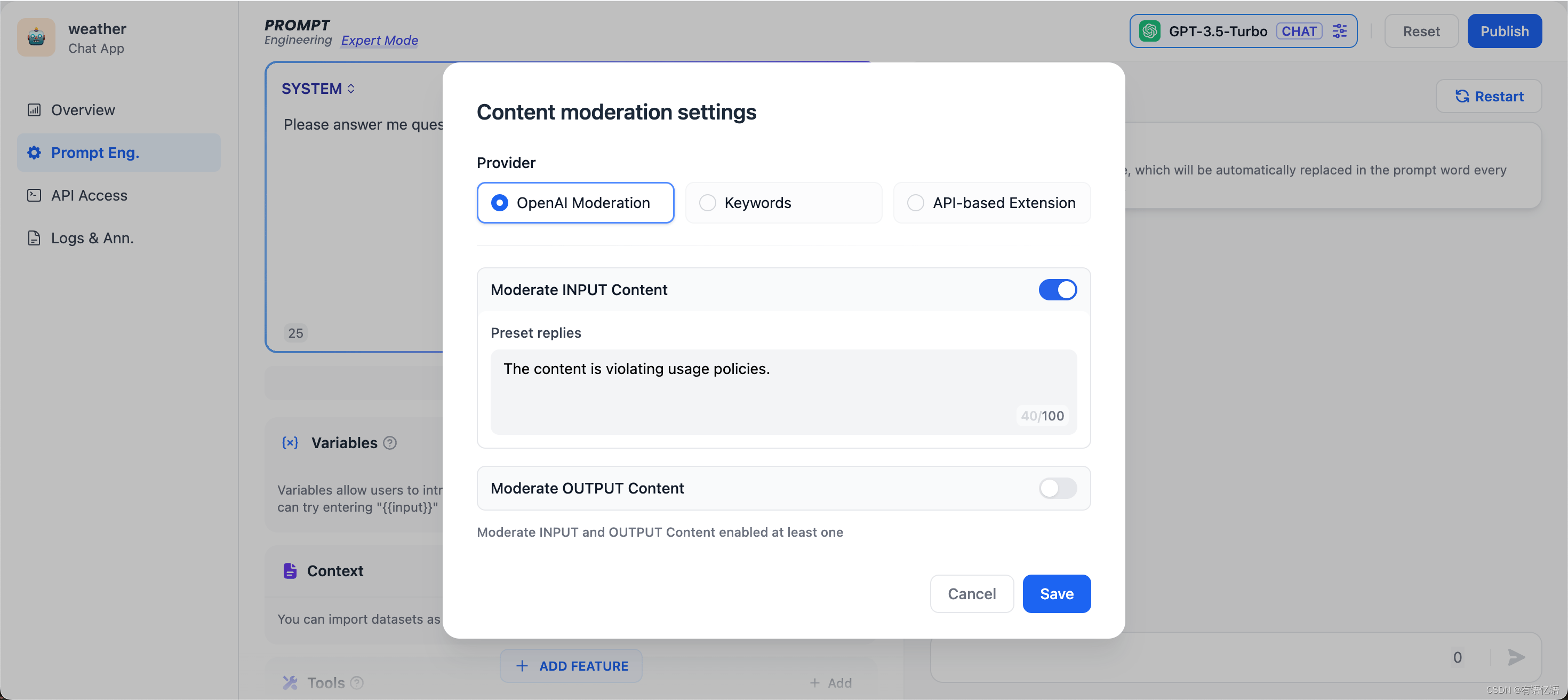
OpenAI 和大多数 LLM 公司提供的模型,都带有内容审查功能,确保不会输出包含有争议的内容,比如暴力,性和非法行为,并且 OpenAI 还开放了这种内容审查能力,具体可以参考 platform.openai.com 。现在你也可以直接在 Dify 上调用 OpenAI Moderation API,你可以审核输入内容或输出内容,只要输入对应的“预设回复”即可。
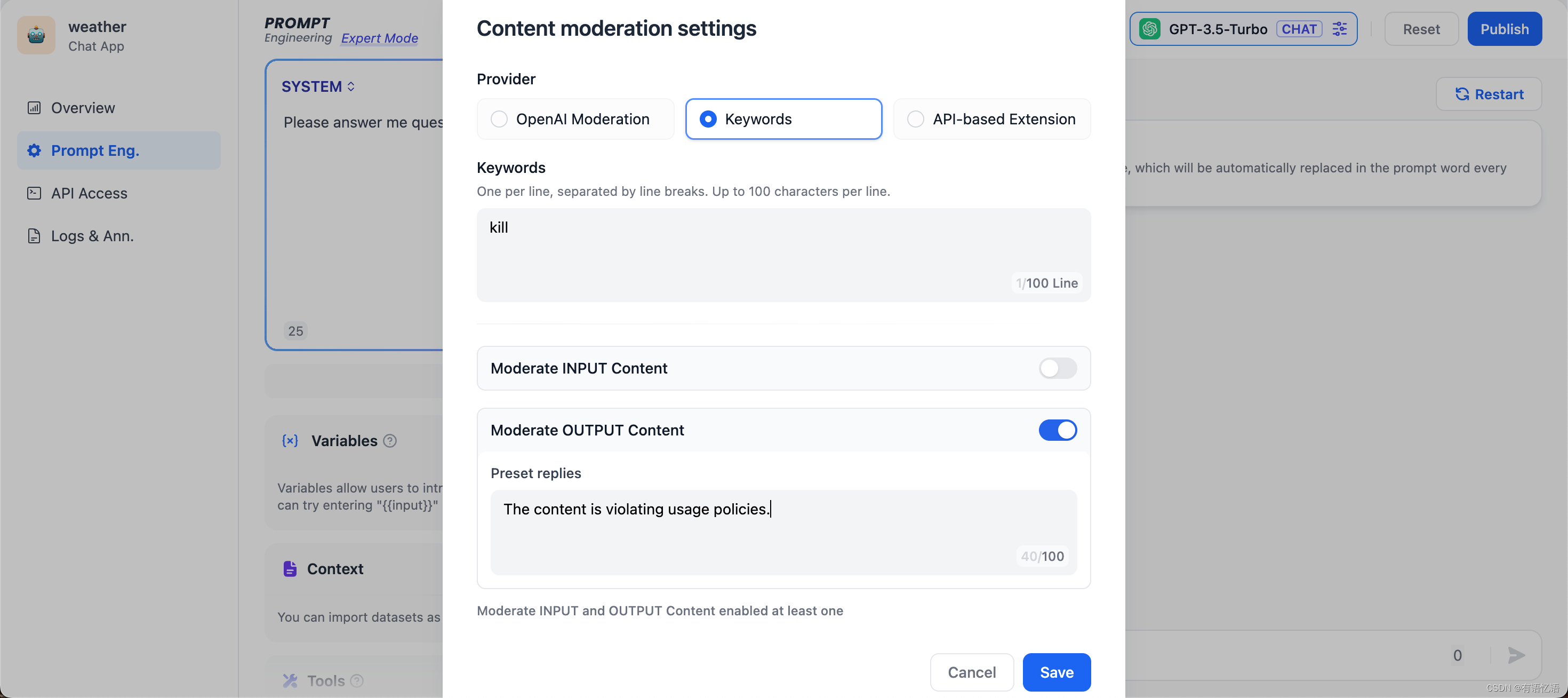
功能二:自定义关键词
开发者可以自定义需要审查的敏感词,比如把“kill”作为关键词,在用户输入的时候作审核动作,要求预设回复内容为“The content is violating usage policies.”可以预见的结果是当用户在终端输入包含“kill”的语料片段,就会触发敏感词审查工具,返回预设回复内容。
功能三: 敏感词审查 Moderation 扩展
不同的企业内部往往有着不同的敏感词审查机制,企业在开发自己的 AI 应用如企业内部知识库 ChatBot,需要对员工输入的查询内容作敏感词审查。为此,开发者可以根据自己企业内部的敏感词审查机制写一个 API 扩展,具体可参考 ,从而在 Dify 上调用,实现敏感词审查的高度自定义和隐私保护。
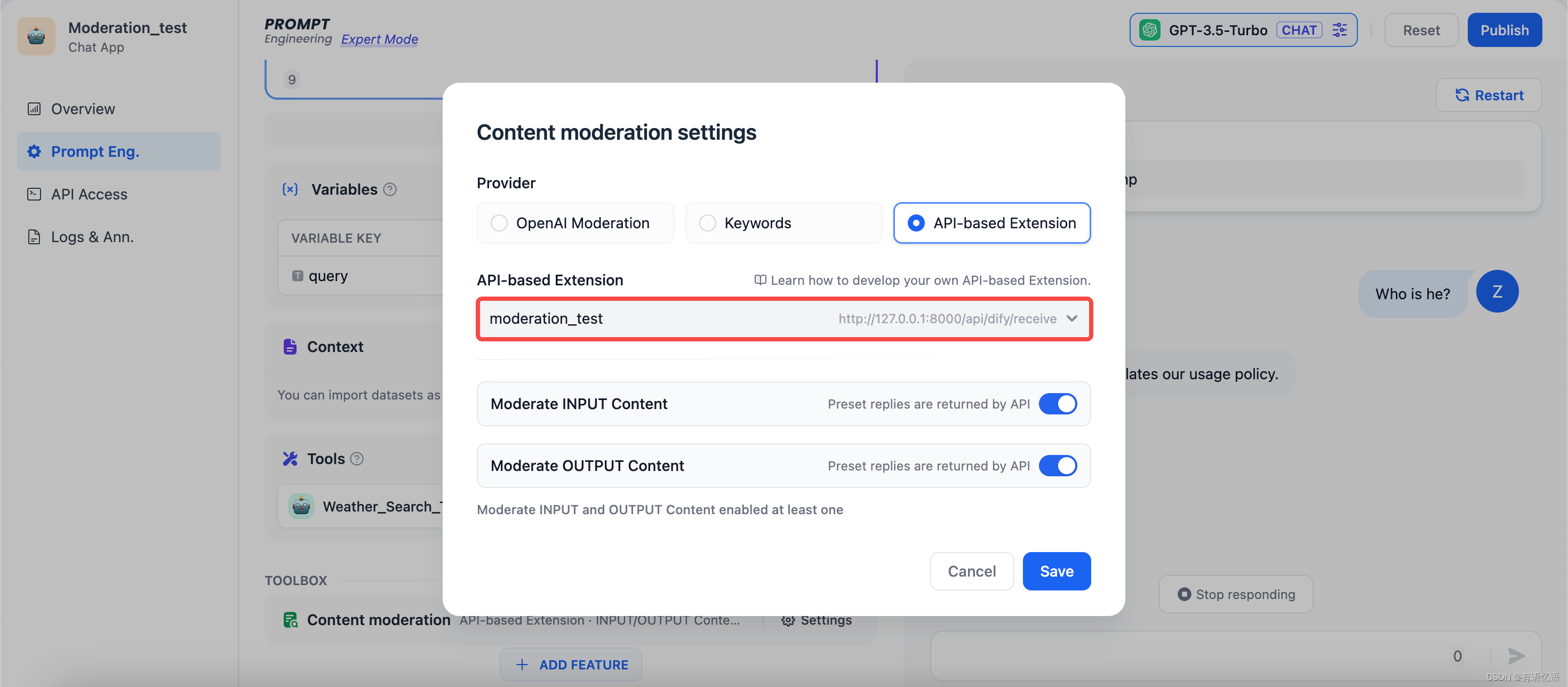
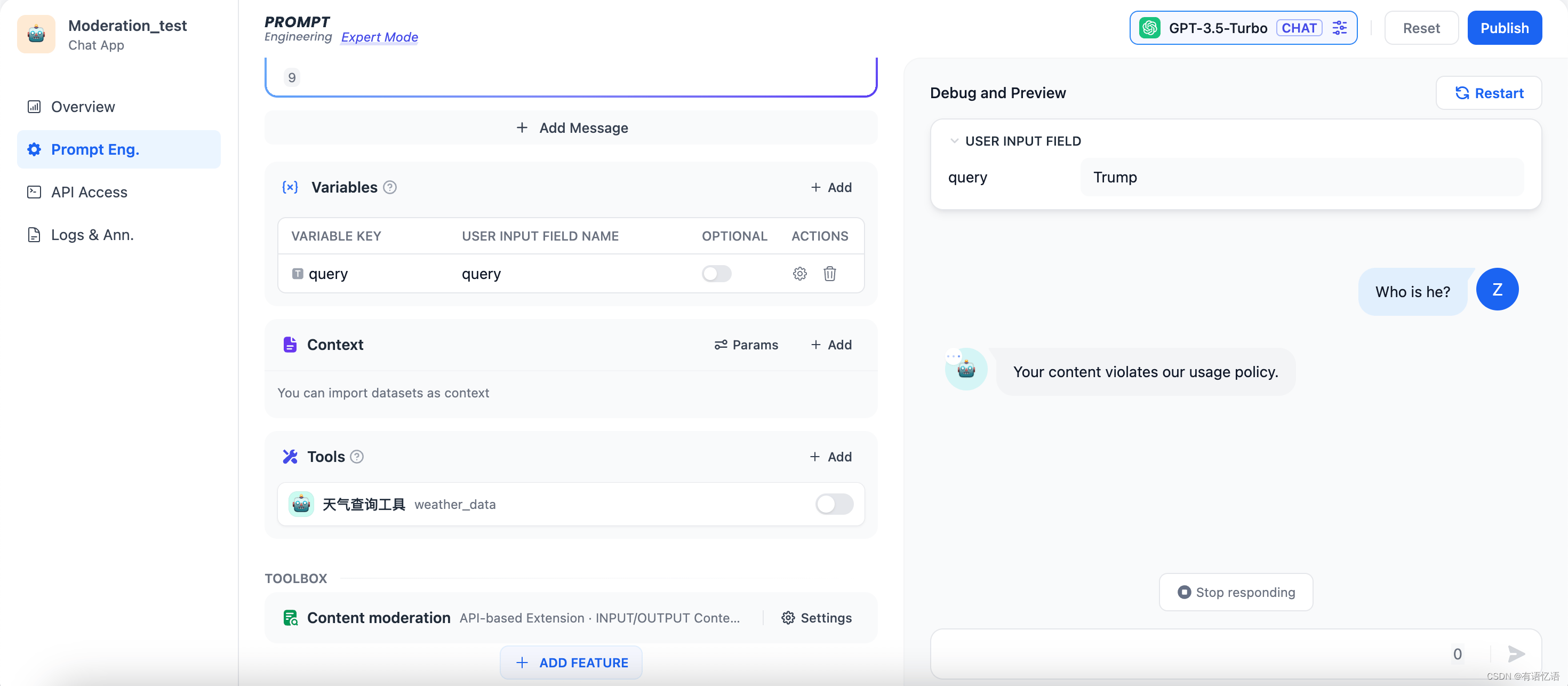
比如我们在自己的本地服务中自定义敏感词审查规则:不能查询有关美国总统的名字的问题。当用户在query变量输入"Trump",则在对话时会返回 “Your content violates our usage policy.” 测试效果如下:
7、扩展外部能力
在创造 AI 应用的过程中,开发者面临着不断变化的业务需求和复杂的技术挑战。有效地利用扩展能力不仅可以提高应用的灵活性和功能性,还可以确保企业数据的安全性和合规性。Dify 提供了以下两种扩展方式:
API扩展
https://github.com/langgenius/dify-docs/blob/main/zh_CN/guides/application-design/extension/code/based_extension/README.md
7.1、API 扩展
开发者可通过 API 扩展模块能力,当前支持以下模块扩展:
moderation 敏感内容审计
external_data_tool 外部数据工具
在扩展模块能力之前,您需要准备一个 API 和用于鉴权的 API Key(也可由 Dify 自动生成,可选)。
除了需要开发对应的模块能力,还需要遵照以下规范,以便 Dify 正确调用 API。
API 规范
Dify 将会以以下规范调用您的接口:
POST {Your-API-Endpoint}
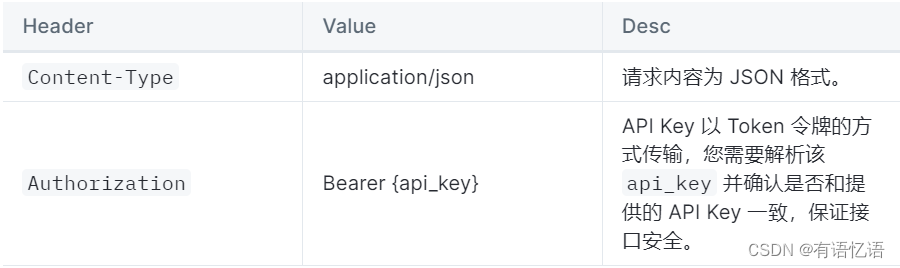
Header
Request Body
{
"point": string, // 扩展点,不同模块可能包含多个扩展点
"params": {
... // 各模块扩展点传入参数
}
}
API 返回
{
... // API 返回的内容,不同扩展点返回见不同模块的规范设计
}
校验
在 Dify 配置 API-based Extension 时,Dify 将会发送一个请求至 API Endpoint,以检验 API 的可用性。
当 API Endpoint 接收到 point=ping 时,接口应返回 result=pong,具体如下:
Header
Content-Type: application/json
Authorization: Bearer {api_key}
Request Body
{
"point": "ping"
}
API 期望返回
{
"result": "pong"
}
范例
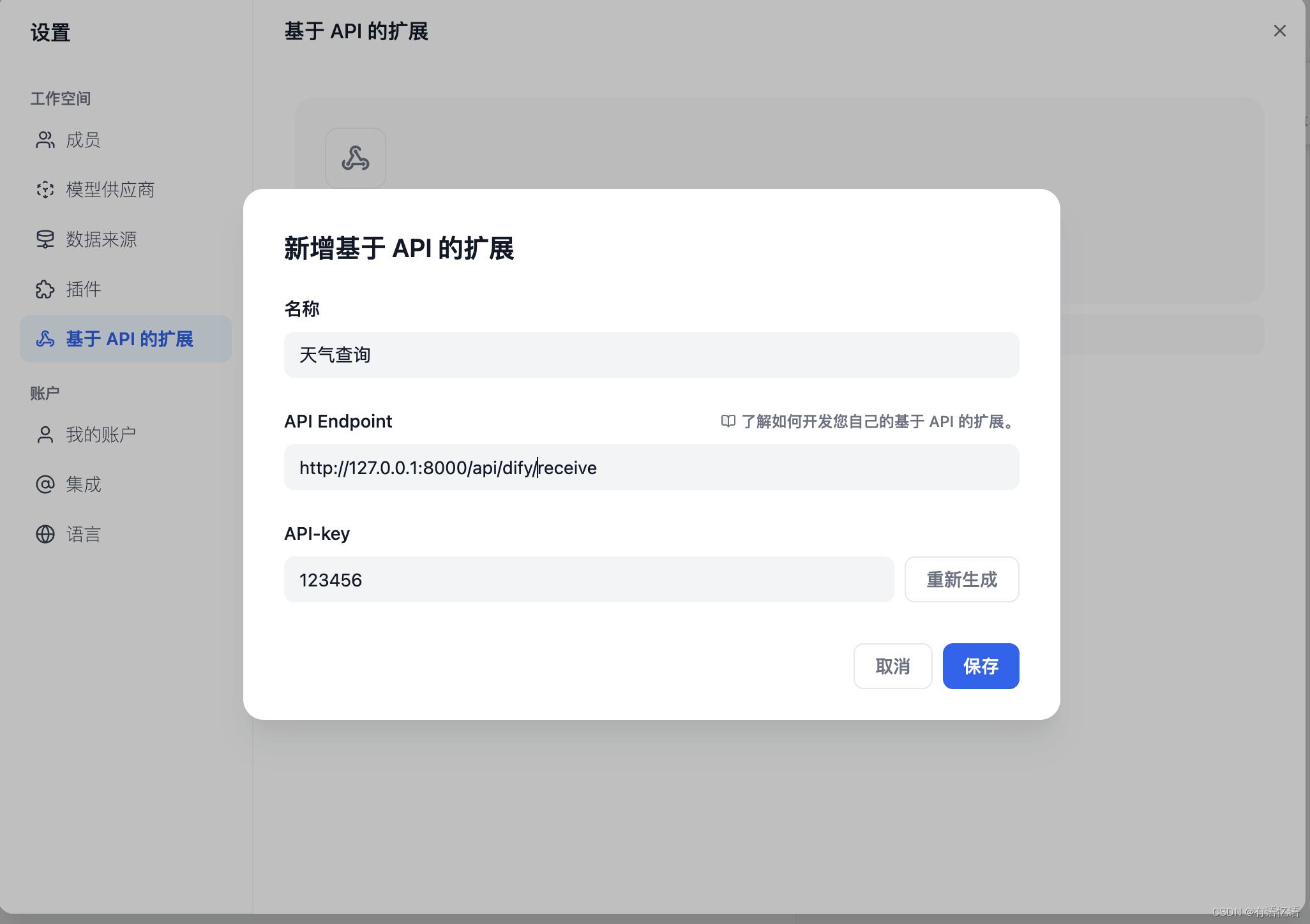
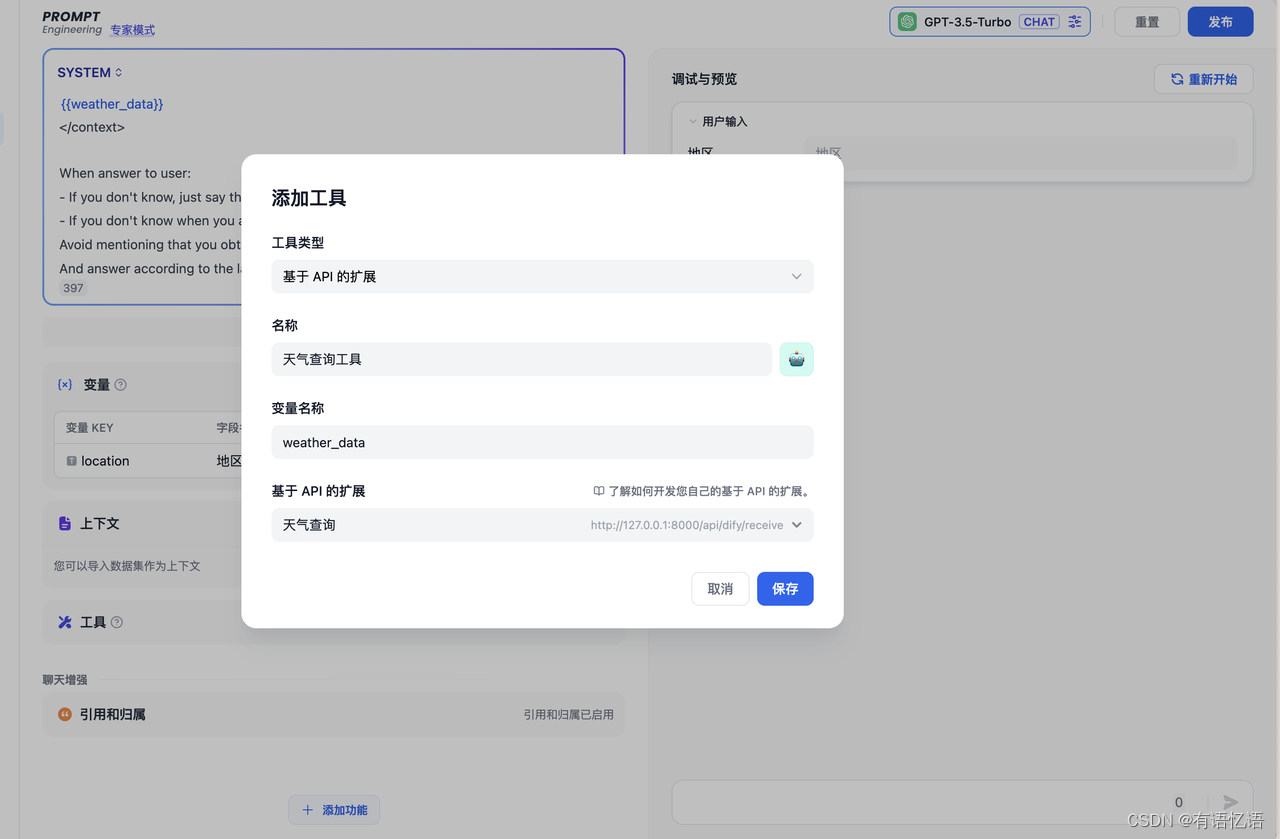
此处以外部数据工具为例,场景为根据地区获取外部天气信息作为上下文。
API 范例
POST https://fake-domain.com/api/dify/receive
Header
Content-Type: application/json
Authorization: Bearer 123456
Request Body
{
"point": "app.external_data_tool.query",
"params": {
"app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
"tool_variable": "weather_retrieve",
"inputs": {
"location": "London"
},
"query": "How's the weather today?"
}
}
API 返回
{
"result": "City: London\nTemperature: 10°C\nRealFeel?: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
}
代码范例
代码基于 Python FastAPI 框架。
- 安装依赖
pip install fastapi[all] uvicorn - 按照接口规范编写代码
from fastapi import FastAPI, Body, HTTPException, Header
from pydantic import BaseModel
app = FastAPI()
class InputData(BaseModel):
point: str
params: dict = {}
@app.post("/api/dify/receive")
async def dify_receive(data: InputData = Body(...), authorization: str = Header(None)):
"""
Receive API query data from Dify.
"""
expected_api_key = "123456" # TODO Your API key of this API
auth_scheme, _, api_key = authorization.partition(' ')
if auth_scheme.lower() != "bearer" or api_key != expected_api_key:
raise HTTPException(status_code=401, detail="Unauthorized")
point = data.point
# for debug
print(f"point: {point}")
if point == "ping":
return {
"result": "pong"
}
if point == "app.external_data_tool.query":
return handle_app_external_data_tool_query(params=data.params)
# elif point == "{point name}":
# TODO other point implementation here
raise HTTPException(status_code=400, detail="Not implemented")
def handle_app_external_data_tool_query(params: dict):
app_id = params.get("app_id")
tool_variable = params.get("tool_variable")
inputs = params.get("inputs")
query = params.get("query")
# for debug
print(f"app_id: {app_id}")
print(f"tool_variable: {tool_variable}")
print(f"inputs: {inputs}")
print(f"query: {query}")
# TODO your external data tool query implementation here,
# return must be a dict with key "result", and the value is the query result
if inputs.get("location") == "London":
return {
"result": "City: London\nTemperature: 10°C\nRealFeel?: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind "
"Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
}
else:
return {"result": "Unknown city"}
- 启动 API 服务,默认端口为 8000,API 完整地址为:http://127.0.0.1:8000/api/dify/receive,配置的 API Key 为 123456。
uvicorn main:app --reload --host 0.0.0.0 - 在 Dify 配置该 API。
5. 在 App 中选择该 API 扩展。
App 调试时,Dify 将请求配置的 API,并发送以下内容(范例):
{
"point": "app.external_data_tool.query",
"params": {
"app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
"tool_variable": "weather_retrieve",
"inputs": {
"location": "London"
},
"query": "How's the weather today?"
}
}
API 返回为:
{
"result": "City: London\nTemperature: 10°C\nRealFeel?: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
}
本地调试
由于 Dify 云端版无法访问内网 API 服务,为了方便本地调试 API 服务,可以使用 Ngrok 将 API 服务的端点暴露到公网,实现云端调试本地代码。操作步骤:
-
进入 https://ngrok.com 官网,注册并下载 Ngrok 文件。
-
下载完成后,进入下载目录,根据下方说明解压压缩包,并执行说明中的初始化脚本。
$ unzip /path/to/ngrok.zip
$ ./ngrok config add-authtoken 你的Token -
查看本地 API 服务的端口:
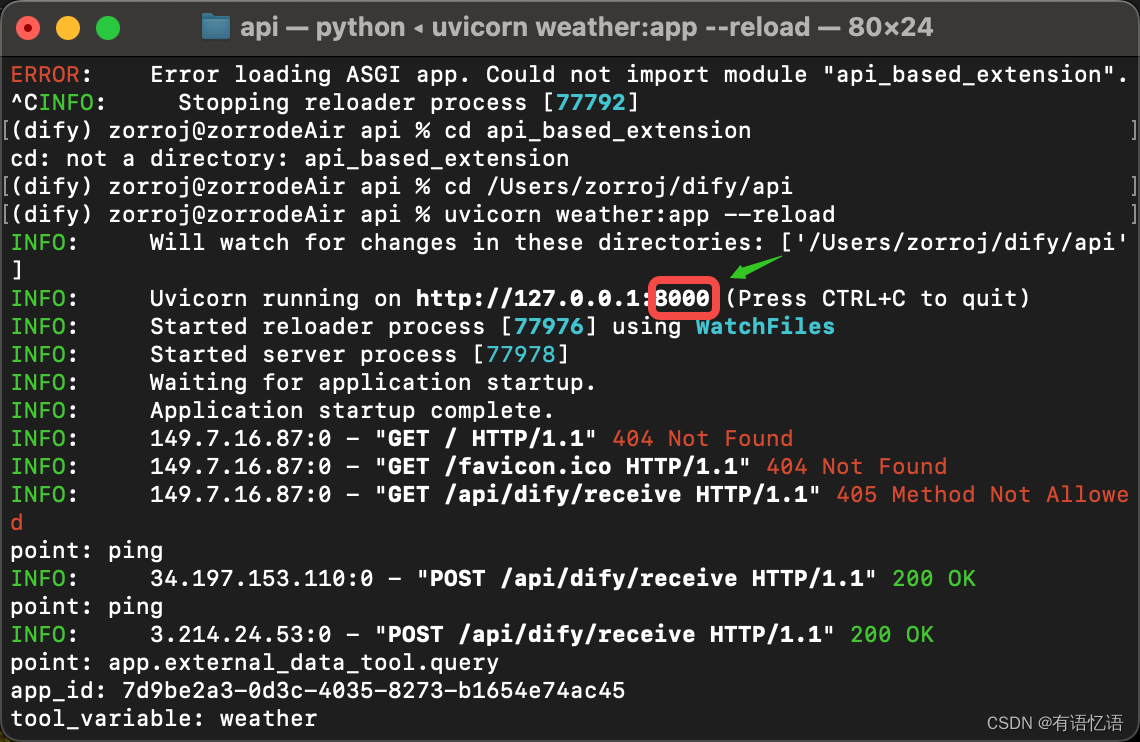
并运行以下命令启动:
$ ./ngrok http 端口号
启动成功的样例如下:
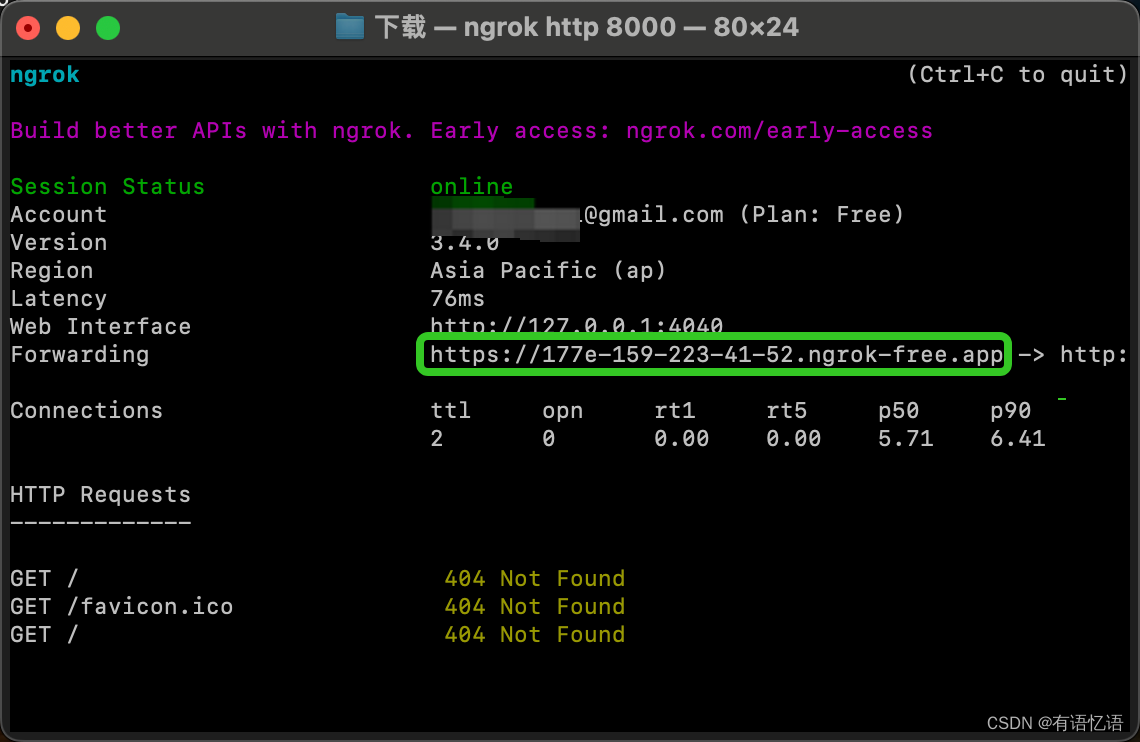
4. 我们找到 Forwarding 中,如上图:https://177e-159-223-41-52.ngrok-free.app(此为示例域名,请替换为自己的)即为公网域名。
- 按照上述的范例,我们把本地已经启动的服务端点暴露出去,将代码范例接口:http://127.0.0.1:8000/api/dify/receive 替换为 https://177e-159-223-41-52.ngrok-free.app/api/dify/receive
此 API 端点即可公网访问。至此,我们即可在 Dify 配置该 API 端点进行本地调试代码,配置步骤请参考 外部数据工具 。
使用 Cloudflare Workers 部署 API 扩展
我们推荐你使用 Cloudflare Workers 来部署你的 API 扩展,因为 Cloudflare Workers 可以方便的提供一个公网地址,而且可以免费使用。
使用 Cloudflare Workers 部署 API 扩展。
7.1.1、外部数据工具
在创建 AI 应用时,开发者可以通过 API 扩展的方式实现使用外部工具获取额外数据组装至 Prompt 中作为 LLM 额外信息。具体的实操过程可以参考 外部数据工具
。
前置条件
请先阅读
完成 API 服务基础能力的开发和接入。
扩展点
app.external_data_tool.query 应用外部数据工具查询扩展点。
该扩展点将终端用户传入的应用变量内容和对话输入内容(对话型应用固定参数)作为参数,传给 API。
开发者需要实现对应工具的查询逻辑,并返回字符串类型的查询结果。
Request Body
{
"point": "app.external_data_tool.query", // 扩展点类型,此处固定为 app.external_data_tool.query
"params": {
"app_id": string, // 应用 ID
"tool_variable": string, // 外部数据工具变量名称,表示对应变量工具调用来源
"inputs": { // 终端用户传入变量值,key 为变量名,value 为变量值
"var_1": "value_1",
"var_2": "value_2",
...
},
"query": string | null // 终端用户当前对话输入内容,对话型应用固定参数。
}
}
Example
{
"point": "app.external_data_tool.query",
"params": {
"app_id": "61248ab4-1125-45be-ae32-0ce91334d021",
"tool_variable": "weather_retrieve",
"inputs": {
"location": "London"
},
"query": "How's the weather today?"
}
}
API 返回
{
"result": string
}
Example
{
"result": "City: London\nTemperature: 10°C\nRealFeel?: 8°C\nAir Quality: Poor\nWind Direction: ENE\nWind Speed: 8 km/h\nWind Gusts: 14 km/h\nPrecipitation: Light rain"
}
\
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 无监督学习(上)
- 在Windows上使用 Python
- 【Mars3d】实现cesium叠加dwg或者其他矢量图的解决方案
- Vue中的keep-alive缓存组件的理解
- java/php/net/python企业物资管理系统【2024年毕设】
- Liunx Top命令
- C语言级联内存池之轻松零拷贝IPC
- 从C/C++ Extension到Clangd:Linux开发实战
- linux系统nginx工具的日志配置
- Python的数组切片突然联想到三体中的维度打击,原来真的可以这样理解