Linux xxd命令分析视频文件Box教程(box分析box、视频box、分析atom分析)(xdd指令)
文章目录
Linux xxd命令分析视频文件Box教程
本文主要探讨如何使用Linux的xxd命令来分析和解读MP4视频文件中的box(也被称为“atom”)。
我们获取视频文件的16进制数据通常会用到以下命令:
xxd example.mp4 | less
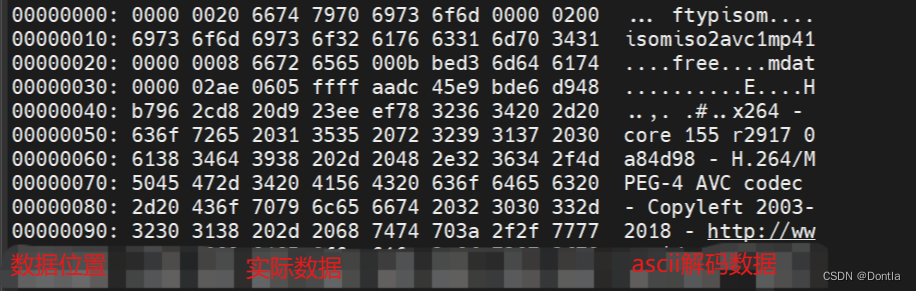
其中数据位置的单位为字节,一行默认显示16个字节数据。(对于16进制,2个数位为1个字节,可以看到上面实际数据中,一行共有8个xxxx,一个xxxx为2个字节,8个就是16个字节)
一、理解MP4格式
在深入了解xxd命令之前,我们首先需要理解MP4文件的基本构造。MP4文件由一系列“box”组成,每个box都有自己的类型和长度。Box可以嵌套其他box,形成一种层级结构。这些box包含了音频、视频和元数据等信息。
(示例:不同文件实际box排列嵌套方式可能有差别)
MP4文件
|
|--- ftyp box (文件类型)
|
|--- moov box (元数据)
| |
| |--- mvhd box (电影头)
| |
| |--- trak box (轨道)
| |
| |--- tkhd box (轨道头)
| |
| |--- mdia box (媒体)
| |
| |--- mdhd box (媒体头)
| |
| |--- minf box (媒体信息)
| |
| |--- stbl box (样本表)
|
|--- mdat box (媒体数据)
每个box的前8个字节构成了box的头部,其中包括4个字节的长度字段和4个字节的类型字段。长度字段表示整个box(包括头部和数据)的大小,而类型字段则是一个ASCII字符串,用于标识box的类型。
二、xxd命令简介
xxd命令是一个在Linux下将文件或输入转换为十六进制、二进制或ASCII表示的工具。这个命令对于分析二进制文件非常有用,尤其是当我们需要查看和理解文件内部结构的时候。
以下是一些基本的xxd命令:
-
将文件转换为十六进制表示:
xxd filename
-
将文件转换为二进制表示:
xxd -b filename
-
将十六进制表示转回到原始数据:
xxd -r -p
三、使用xxd命令分析MP4文件
让我们以一个具体的例子来演示如何使用xxd命令分析MP4文件。
假设我们有一个名为"example.mp4"的视频文件,我们可以使用以下命令查看其十六进制表示:
xxd example.mp4 | less
可能会看到如下的输出:
00000000: 0000 001c 6674 7970 6973 6f6d 0000 0200 ....ftypisom....
00000010: 6973 6f6d 6973 6f32 6176 6331 6d70 3431 isomiso2avc1mp41
00000020: 0000 0080 6d6f 6f76 0000 006c 6d76 6864 ....moov....mvhd
这里的每一行都表示了一个box。例如,第一行表示了一个ftyp box,它的大小为28字节("0000001c"转换为十进制),类型为’ftyp’("66747970"转换为ASCII)。接下来的12个字节是该box的数据。
四、解析MP4文件的疑难点
尽管xxd命令能够帮助我们查看MP4文件的内部结构,但理解这些数据并不总是直截了当的。以下是几个可能遇到的挑战:
1. Box的嵌套结构
像’moov’和’trak’这样的box可以包含其他的box。这就意味着我们需要跟踪当前的嵌套级别,并在读取新的box时更新当前的位置。
2. 长度和类型字段的字节序
MP4文件使用大端字节序,这就意味着我们需要将从文件中读取的字节反转过来。例如,如果我们读取了四个字节 “00 00 01 c”, 我们需要将其反转为 “1c 00 00 00”,然后再转换为十进制。
3. 非文本类型的数据
像’mdat’这样的box包含音频或视频数据,这些数据通常不是文本类型的,因此不能直接转换为ASCII字符。我们需要使用其他工具或者技术来解析这些数据。
五、python代码解析box嵌套结构的示例
以下是一个基于Python的简单示例,用于解析MP4文件中box的嵌套结构。这个脚本会打开一个MP4文件,并读取每个box的大小和类型。
import struct
def read_box(file):
data = file.read(8)
if data:
size, type = struct.unpack('>I4s', data)
return size, type.decode('utf-8')
else:
return None, None
def parse_boxes(file, level=0):
while True:
size, type = read_box(file)
if not size or not type:
break
print(f"{' ' * level} {type} {size}")
if type in ['moov', 'trak', 'mdia']:
# 这是一个可以包含其他box的容器,所以我们递归地解析它
start = file.tell()
parse_boxes(file, level + 1)
file.seek(start + size) # 跳到当前box之后的位置
else:
# 这不是一个容器,所以我们直接跳过它的内容
file.seek(size - 8, 1)
with open('example.mp4', 'rb') as f:
parse_boxes(f)
在这个脚本中,我们使用struct模块来读取二进制数据,并将其解析为具体的值。'>I4s'参数表示我们要读取一个大端字节序的无符号整数(即box的大小)和一个4字节长的字符串(即box的类型)。
注意,由于MP4文件的嵌套结构,我们需要使用递归来解析每个容器box。当我们遇到一个容器box时(如’moov’、‘trak’或’mdia’),我们会保存当前的位置,然后递归地解析该容器,最后再返回到原来的位置。
此外,由于box的大小包括了它自身的头部,所以在跳过box的内容时,我们需要减去8字节(即头部的大小)。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!