Python进阶知识:整理6 -> 正则表达式
发布时间:2024年01月18日
1 基础匹配用法
# 演示Python中正则表达式re模块的3个基础匹配方法
import re
# 1. match()方法 从头匹配
string = "hello world"
result = re.match("hello", string) # 如果头部没有匹配成功就直接失败了,后面就不会继续匹配了
print(result)
print(result.group())
print(result.span())
print("--------------------")
# 2. search()方法 搜索匹配
s1 = "python11888999python"
result = re.search("python", s1) # 搜索整个字符串,找到第一个匹配的,并返回结果
print(result)
print(result.group())
print(result.span())
print("----------------------")
# 3. findall()方法 搜索匹配所有,返回一个列表
s2 = "python11888999python"
result = re.findall("python", s2)
print(result)
print("--------------------")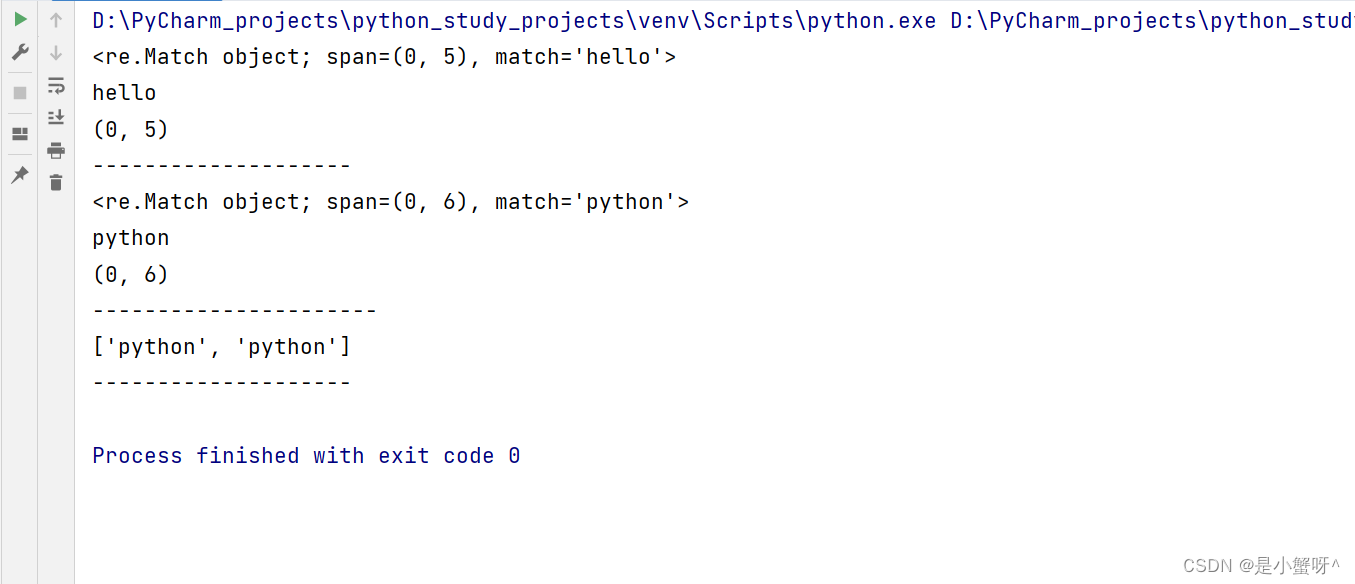
2 元字符匹配
"""
字符 功能
. 匹配任意1个字符(除了\n), \. 匹配点本身
[...] 匹配[]中列举的字符, 字符集合, [0-9a-zA-Z_], [a-z], [0-9], [...]
\d 匹配数字, [0-9]的简写
\D 匹配非数字, [^0-9]的简写
\w 匹配字母或数字或下划线, [a-zA-Z0-9_]的简写
\W 匹配非(字母或数字或下划线), [^a-zA-Z0-9_]的简写
\s 匹配空白, [ \t\n\x0b\r]的简写, 即空格, tab键
\S 匹配非空白, [^ \t\n\x0b\r]的简写
[^...] 匹配除了[]中列举的字符之外的字符, 反向字符集合, [^0-9], [^a-zA-Z_]
"""
import re
s = "itheima @@ Python2 !!999 # It"
result = re.findall(r"\d", s) # 加上 r 可以表示字符串中的转义字符无效
print(result)
print("---------------------")
result2 = re.findall(r"\W", s) # 非单词字符
print(result2)
print("---------------------")
# 匹配所有的英文字母
result3 = re.findall(r"[a-zA-Z]", s)
print(result3)
"""
数量匹配:
* 匹配*号 前的字符 0次或无数次
+ 匹配+号 前的字符 1次或无数次
? 匹配?号 前的字符 0次或1次
{m} 匹配{m} 前的字符 出现m次
{m,} 匹配{m} 前的字符 出现最少m次
{m,n} 匹配{m,n} 前的字符 出现 m到n次
"""
"""
边界匹配:
^ 匹配一行字符串的开头
$ 匹配一行字符串的结束
\b 匹配一个单词的边界
\B 匹配非单词边界
"""
"""
分组匹配:
| 匹配左右任意一个表达式
(...) 分组, 将 ()中的内容作为一组, (abc.efs), (a|b|c)
"""
# 案例: (注意: 正则表达式中千万不要随意价格空格)
# 1. 匹配账号: 只能由字母数字组成,长度限制6-10位
r = '^[a-zA-Z0-9]{6,10}$'
s = '1232dfgf'
result = re.findall(r, s)
print(result)
print('---------------------')
# 2. 匹配QQ号, 要求纯数字, 长度5-11,第一位不为0
r = '^[1-9][0-9]{4,10}$' # {4,10} 开头已经占了一位了
s_qq = '329809378'
result_qq = re.findall(r, s_qq)
print(result_qq)
print('---------------------')
# 3. 匹配邮箱地址,只允许请qq 、163、gmail这三种邮箱地址
# abc.ghs.edu@qq.com
# abc.ghs.edu@qq.jsx.ss.com
# abc.@163.com
r = '^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$'
s = 'abc.ghs.edu@qq.com'
result = re.findall(r, s) # findall 会返回正则中的分组 () -> [('.edu', 'qq', '.com')]
# 所以需要整体再放入一个组中
r = '(^[\w-]+(\.[\w-]+)*@(qq|163|gmail)(\.[\w-]+)+$)'
result_all = re.findall(r, s)
result_match = re.match(r, s)
print(result_match)
print(result_all)
print("----------------------")
文章来源:https://blog.csdn.net/m0_61495539/article/details/135653612
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 不懂随身WiFi别怕,一篇文章带你了解!2024随身wifi怎么选?随身WiFi哪个品牌最靠谱?
- Arduino下载、安装及配置(含中文配置步骤)
- 基于STM32的考试指纹管理系统的设计与实现
- 经典目标检测YOLO系列(三)YOLOv3算法详解
- 【ASP.NET Core 基础知识】--中间件--内置中间件的使用
- Fiddler抓包 -- 使用教程
- Mybatis配置
- 05-《人月神话》汤姆克鲁斯-中译本纠错及联想
- 网络指令(ipconfig | netstat | tasklist)
- 《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(7)