Dubbo的几个序列化方式
欢迎订阅专栏,会分享Dubbo里面相关的技术实现
这篇文章就不详细的介绍每种序列化方式的实现细节,大家可以自行去问度娘,我也会找一些资料。需要注意的是,这个先后顺序不表示性能优越
ObjectInput、ObjectOutput
这两是Dubbo序列化的伯牙子期,庖丁和牛,一个喂到嘴边一个吃到胃里。
那么Dubbo既然是RPC框架,处理的是网络间的数据,那ObjectInput和ObjectOutput的中间层自然就是通过Netty的Channel和传递的Buffer
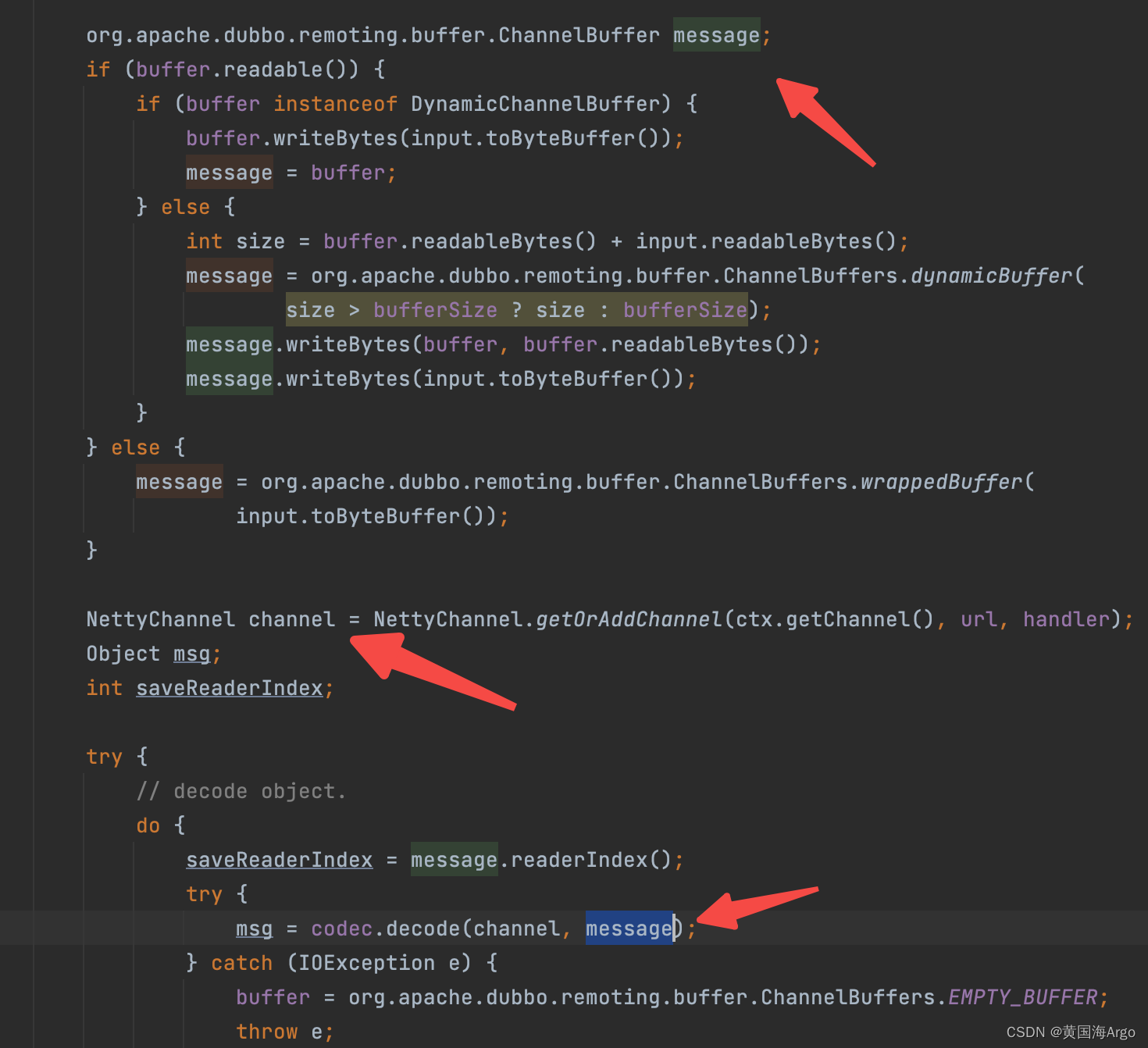
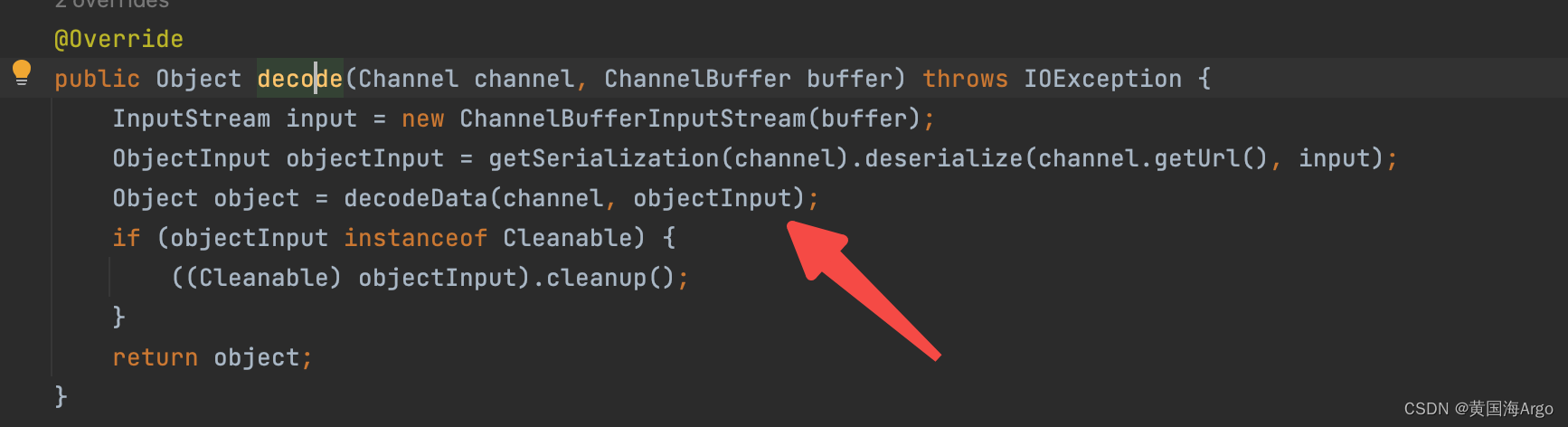
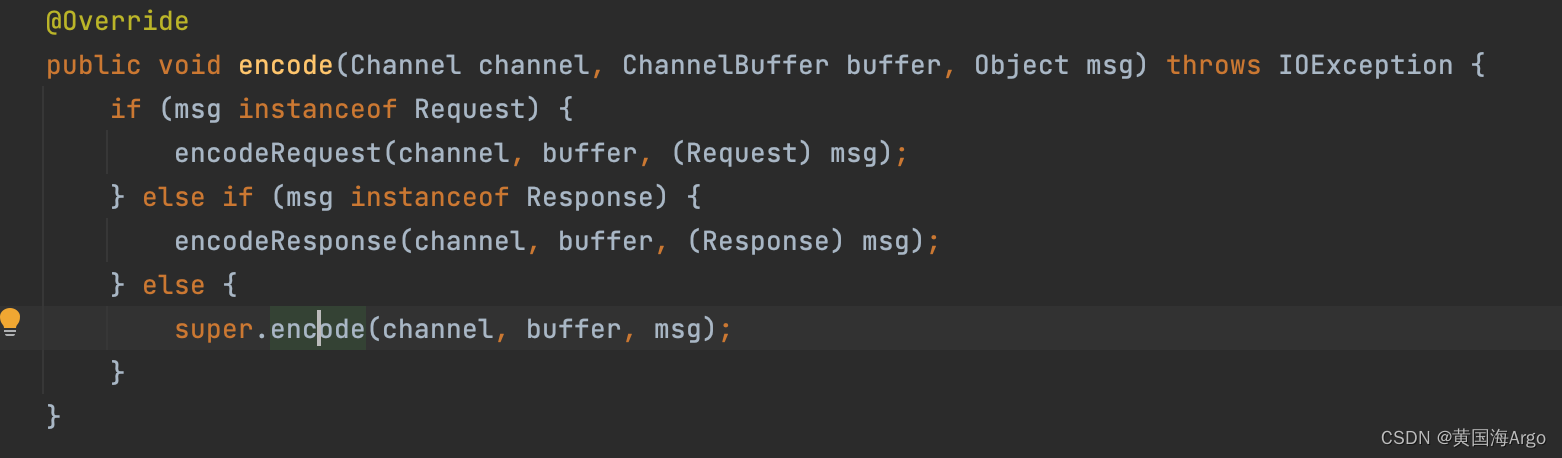
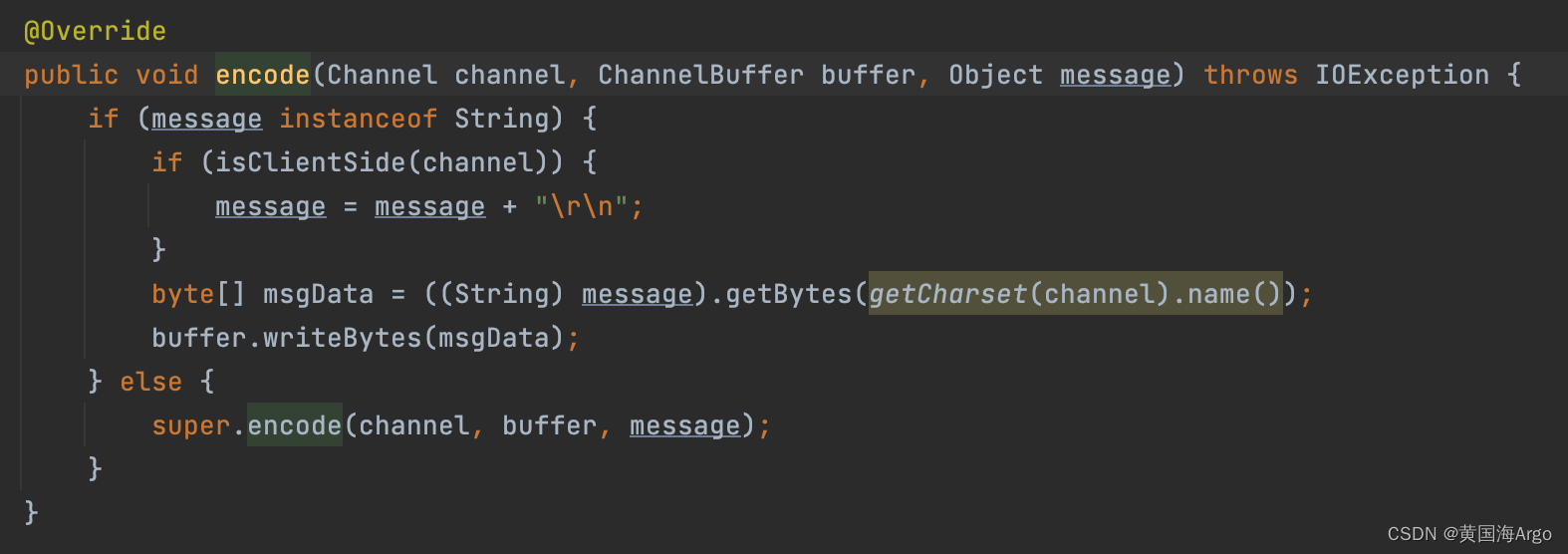


Avro
这几篇我觉得都挺不错的
什么是Avro?Hadoop首选串行化系统——Avro简介及详细使用_51CTO博客_avro hadoopAvro简介-CSDN博客
因为他特有的模式(schema)的设计,使得对于数据类型和属性信息可以尽量少的出现在序列化后的内容中。比如一个User类,其中有属性id,name,salary,age,address五个属性,总共有1000W条数据,那么无个属性的定义都只出现在schema中。如下
Objavro.schemaè{“type”:“record”,“name”:“User”,“namespace”:“com.czxy.hdfs.avro”,“fields”:[{“name”:“name”,“type”:“string”},{“name”:“id”,“type”:“int”},{“name”:“salary”,“type”:“int”},{“name”:“age”,“type”:“int”},{“name”:“address”,“type”:“string”}]} ?Gú?1r ?j=C?ò?6xzhangsan?(beijing wangwu?&guangzhoulisi *shenzhen?Gú?1r ?j=C?ò?6(后面还有1000W-2条的数据)
他特别适合那些数据密集的场景的另一个原因(摘自:大数据开放平台搭建,难点何在?_大数据_孙利兵_InfoQ精选文章)
Avro 开发中代码生成是可选的,这是一个跟其他系统,就是跟 Thrift 和 Protobuf 有很大区分的一个特性。另外 Avro 支持通用数据读取,不依赖于代码生成。有了这两个特性,Avro 就更能适应大数据变化的特性。
关于avro的视频推荐到B站找资源,有很多相关的视频可以学习使用?
Fastjson
dubbo里面fastjson的序列化实现方式就很明确,核心方法就是这几个,基本就是通过JSON做序列化和反序列化
//反序列化
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
String json = readLine();
return (T) JSON.parseObject(json, type);
}
private String readLine() throws IOException, EOFException {
String line = reader.readLine();
if (line == null || line.trim().length() == 0) {
throw new EOFException();
}
return line;
}
private <T> T read(Class<T> cls) throws IOException {
String json = readLine();
return JSON.parseObject(json, cls);
}
//序列化
@Override
public void writeBytes(byte[] b, int off, int len) throws IOException {
writer.println(new String(b, off, len));
}
@Override
public void writeObject(Object obj) throws IOException {
SerializeWriter out = new SerializeWriter();
JSONSerializer serializer = new JSONSerializer(out);
serializer.config(SerializerFeature.WriteEnumUsingToString, true);
serializer.write(obj);
out.writeTo(writer);
out.close(); // for reuse SerializeWriter buf
writer.println();
writer.flush();
}代码没什么可看的,紧紧的略过
json格式的数据可以说是程序员的老相好了,甚至比跟自己老婆相处的时间还要久。它的组织形式是以key:value的形式组装的。实际上fastjson底层操作就是通过map来操作的。正是因为它的这种结构清晰的组织形式,使得它被广泛使用在交互Web输出,应用日志输出等各种应用场景中。
{
"ID": 1002,
"name": "张三",
"age": 21
}支持各种基础类型数据,还有复杂对象,和list,map等数据结构 。
Fastjson实现高性能的“手段”
1:通过ASM来动态生成字节码和对象访问器来访问和设置对象的属性值,避免了每次反射带来资源损耗(很多优秀的序列化方式都是使用ASM)
2:fastjson会缓存很多的数据,包括类元数据缓存、对象引用缓存和字符串缓存等。有了缓存,碰到相同类,对象,字符串时就可以重复利用,提高效率
3:优化字符串拼接:
1.通过StringBuilder来做长字符串的拼接,
2.碰到重复的字符串,会将其保存为一个字符串常量,之后有相同的字符串,做对象引用即可
4:有自己的json解析算法:
词法分析(Lexical Analysis):词法分析器将输入的JSON字符串划分为一个个的token,每个token代表一个JSON的语义单元。常见的JSON语义单元包括字符串、数字、布尔值、null、数组分隔符、对象分隔符等。在词法分析阶段,fastjson使用有限状态机(Finite State Machine)来解析输入的字符流,并将其转换为相应的token。
语法分析(Syntactic Analysis):语法分析器根据词法分析器生成的token流来构建JSON的语法树。fastjson采用递归下降的解析器设计,通过一系列的语法规则来解析不同类型的JSON结构。例如,字符串类型的JSON会根据语法规则解析出键值对,数组类型的JSON会解析出一组值等。解析过程中,fastjson会递归地调用解析器函数来处理嵌套的JSON结构。
值的解析与映射:在fastjson的解析算法中,解析器将JSON的值转换为相应的Java对象。基本类型的值(如字符串、数字、布尔值、null)会被转换为对应的Java基本类型。对象类型的值会被解析为Java的JSONObject对象,数组类型的值会被解析为Java的JSONArray对象。此外,fastjson还支持将JSON值直接映射到JavaBean对象,通过反射机制自动设置JavaBean的属性值。
5:有自己的压缩算法(QuickLZ)
LZ77压缩算法:LZ77是一种基于字典的压缩算法。它通过将重复出现的字符串替换为指向先前出现的相同字符串的指针来实现压缩。LZ77算法通常使用一个滑动窗口和一个查找缓冲区来进行压缩。滑动窗口存储了已经压缩的字符串,而查找缓冲区用于查找重复字符串的位置。
哈希表技术:QuickLZ使用哈希表来加速LZ77算法的查找过程。哈希表将先前出现的字符串的哈希值映射到滑动窗口中的位置。当需要查找重复字符串时,只需要计算当前字符串的哈希值,并在哈希表中查找匹配项,避免了对整个滑动窗口进行线性搜索。
压缩模式和解压模式:QuickLZ将压缩和解压功能分为两个模式,分别是LEVEL 1和LEVEL 3。LEVEL 1是快速压缩模式,适用于资源受限的环境,压缩速度较快;LEVEL 3是最佳压缩模式,适用于空间受限的环境,压缩率更高。根据需求可以选择不同的压缩模式。
快速压缩和解压:QuickLZ通过使用哈希表和预定位技术来加速压缩和解压过程。哈希表加速了查找重复字符串的过程,预定位通过确定指向先前位置的指针来加速匹配的查找。这些技术使得QuickLZ在压缩和解压速度方面表现出色。
6:并发优化:fastjson在处理多线程并发访问时,使用了线程局部变量和锁分离等技术来提高并发性能
总结一下
fastjson有以下几个优点
简单:使用起来简单,通过JSONObject,JSONArray,JSON三个重要类做对象,数组,对象和数组之间转的操作
好看:json格式化后的文本易读性非常高,如上所示
快:可以看这篇文章:分析FastJSON为何那么快与字节码增强技术揭秘_fastjson为什么快-CSDN博客
FST
fst是针对jdk序列化的优化的一种序列化方式。主要在两方面做了优化,一个是序列化效率上,一个是存储空间上
-
序列化效率:
- ? ? ? ? JDK:JDK的序列化通过反射机制对被目标对象做处理,而且是每次序列化都需要单独做反射来获取对象的结构。效率自然就慢了
- ? ? ? ? FST:FST在序列化和反序列化过程中使用了ASM字节码生成技术。在序列化期间,FST通过分析待序列化对象的结构,动态生成对应的字节码。生成了字节码了,自然就有一定程度的缓存。
-
存储空间:
- ? ? ? ? JDK:JDK的序列化方式的优点是将对象的所有信息都记在序列化的内容中,最大程度的保存对象的信息。所以他并没有使用一些压缩的算法或者策略来降低传输或者存储的成本。
- ? ? ? ? FST:FST则通过多种的算法来优化序列化后的内容在降低传输或者存储的成本。
????????????????Delta压缩策略:Delta压缩策略是FST使用的一种压缩算法,它通过计算相邻数据的差异来减少数据的存储空间。该策略可以在序列化时将数据转换为差异值的序列,然后在反序列化时重新构建原始数据。这种方法特别适用于存储和传输有序数据,因为有序数据的差异通常较小。
????????????????Snappy压缩算法: FST还使用了Snappy压缩算法,它是一种高速且可压缩性较好的数据压缩算法。Snappy算法通过使用一种快速的压缩和解压缩算法,有效地减小了数据的大小,同时保持了较低的处理延迟。这使得FST可以在序列化和反序列化过程中使用Snappy压缩算法,从而减少数据的传输和存储成本。
????????????????????????字段共享(Field Sharing):FST在序列化过程中会检测对象中的重复字段,并将它们转化为引用,避免重复序列化相同的数据。这样可以减少序列化后的数据大小。
????????????????????????增量编码(Delta Encoding):FST对一些场景中变化不大的数据(如时间戳、计数器等)进行增量编码。通过记录前后两次数据的差值,可以将变化较小的数据进行压缩,减少序列化后的数据量。
????????????????????????变长编码(Variable Length Encoding):FST使用变长编码来表示整数类型的数据,将数据按照不同的位数来编码。较小的数值使用较少的字节数来表示,减少序列化后的数据大小。
????????????????????????自适应压缩策略:FST根据待序列化数据的特征和大小选择不同的压缩策略,例如对于较小的数据采用直接存储的方式,对于较大的数据采用压缩算法来减小数据大小。
总结一下
????????FST同样也是使用ASM动态生成字节码来减少反射。
????????使用Delta压缩策略计算相邻数据的差异性并存储差异值序列,反序列化时再通过差异值序列恢复对象
假设有两个Java对象,一个是前一个对象A,一个是当前对象B,它们的属性如下:
对象A:{"name": "Tom", "age": 20, "city": "New York"} 对象B:{"name": "Tom", "age": 21, "city": "New York"}
在应用Delta压缩策略时,只有对象B相对于对象A有变化的属性值会被记录下来。在这个例子中,只有"age"属性的值发生了变化,因此生成的差异值序列为{"age": 21}。
????????FST和Fastjson都会对重复出现的字符串做整理,并转化为引用的方式,代替原来的字符串直接拼接
Gson
dubbo里面使用Gson做序列化代码不多,简单明了
@Override
public void writeBytes(byte[] b, int off, int len) throws IOException {
writer.println(new String(b, off, len));
}
@Override
public void writeObject(Object obj) throws IOException {
char[] json = gson.toJson(obj).toCharArray();
writer.write(json, 0, json.length);
writer.println();
writer.flush();
json = null;
}
@Override
public void writeThrowable(Object obj) throws IOException {
String clazz = obj.getClass().getName();
ExceptionWrapper bo = new ExceptionWrapper(obj, clazz);
this.writeObject(bo);
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
Object value = readObject(cls);
return (T) PojoUtils.realize(value, cls, type);
}
private String readLine() throws IOException {
String line = reader.readLine();
if (line == null || line.trim().length() == 0) {
throw new EOFException();
}
return line;
}
private <T> T read(Class<T> cls) throws IOException {
String json = readLine();
return gson.fromJson(json, cls);
}代码没什么可看的,紧紧的略过
作为程序员,Gson一般也会用到,但使用频率没有那么高。其序列化后的字符串格式和fastjson差不多,都是key:value的组织形式
{
?? ?"ID": 1002,
?? ?"name": "张三",
?? ?"age": 21
}
gson也支持各种基础类型数据,还有复杂对象,和list,map等数据结构 。
Gson序列化和反序列化通过哪些能力实现的
Gson中有三个重要的组件,分别是Parser解析器,Serializers序列化器,Deserializer反序列化器。Deserializer反序列化器类似Parser解析器,不过它相比Parser解析器会有很多的局限性,比如
Deserializer反序列化器直接转换为特定对象,Parser解析器是将Json数据转为JsonElement对象。因为Parser解析器不用转成特定的对象,所以相比Deserializer反序列化器会有如下优点
- Deserializer反序列化器处理复杂的json结构会有局限性
- Deserializer反序列化器只可以处理标准的json数据,Parser解析器可以处理带有注释或者多行json 的情况
- Parser解析器在碰到Json中有的字段但是对象中没有的对象时会忽略,而Deserializer反序列化器会抛异常
- Parser解析器可以从Reader,InputStream中直接获取数据源来源做解析,而Deserializer反序列化器只能接受Json字符串作为来源
Gson使用反射机制获取Java对象的类信息,并通过映射器(Mapper)将JsonElement对象的值映射到Java对象的相应字段上
如何自定义一个反序列化器
public class Person {
private String name;
private int age;
// 省略构造方法和getter/setter
}
public class PersonDeserializer implements JsonDeserializer<Person> {
@Override
public Person deserialize(JsonElement json, Type typeOfT, JsonDeserializationContext context) throws JsonParseException {
JsonObject jsonObject = json.getAsJsonObject();
String name = jsonObject.get("name").getAsString();
int age = jsonObject.get("age").getAsInt();
return new Person(name, age);
}
}
Gson gson = new GsonBuilder()
.registerTypeAdapter(Person.class, new PersonDeserializer())
.create();
String json = "{\"name\": \"Alice\", \"age\": 25}";
Person person = gson.fromJson(json, Person.class);
总结一下
Gson也会使用反射的方式获取类信息,并通过映射器(Mapper)将JsonElement对象的值映射到Java对象的相应字段上,再做相应的序列化和反序列化。Gson还支持自定义序列化和反序列化器
Hessian2
Dubbo中Hessian2的序列化代码不多,就是引用Hessian2的能力做序列化和反序列化能力
@Override
public Object readObject() throws IOException {
return mH2i.readObject();
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls) throws IOException,
ClassNotFoundException {
return (T) mH2i.readObject(cls);
}
@Override
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
return readObject(cls);
}
@Override
public void writeBytes(byte[] b, int off, int len) throws IOException {
mH2o.writeBytes(b, off, len);
}
@Override
public void writeUTF(String v) throws IOException {
mH2o.writeString(v);
}
@Override
public void writeObject(Object obj) throws IOException {
mH2o.writeObject(obj);
}为什么Dubbo默认使用Hessian2来做序列化和反序列化
Dubbo是一个RPC框架,它的序列化协议如果可以直接使用二进制内容传输,与HTTP协议天然兼容,那么比基于文本类型的序列化协议传输势必更加有优势。
Hessian2是一种轻量级的序列化协议,相比其他复杂的序列化协议,它没有过多的元数据信息和复杂的数据结构定义,从而可以更快地进行序列化和反序列化操作。
Hessian2在Java中的实现使用了一些优化的技术和数据结构,如基于缓冲区的读写操作、快速的字节码生成等,这些优化可以提高整体的执行效率。
Hessian2的序列化和反序列化设计相关的算法、策略
基于标记的数据类型:Hessian2使用一个字节的标记来表示不同的数据类型,比如整数、字符串、列表等。通过这种方式,可以快速准确地识别和处理不同的数据类型,避免了冗余的元数据信息。
压缩算法:Hessian2使用了一些压缩算法来减小数据的大小。例如,对于重复出现的字符串和对象,它使用引用共享的方式来避免重复传输。此外,Hessian2还采用了一些简单的压缩算法,如变长整数编码(Variable Length Integer Encoding)和可变长度字符串编码(Variable Length String Encoding),以进一步减小数据的大小。
写入缓冲区:Hessian2在序列化过程中使用了写入缓冲区,将数据暂存在内存中,然后一次性写入输出流。这样可以减少对输出流的频繁写操作,提高效率。
读取缓冲区:Hessian2在反序列化过程中使用了读取缓冲区,将输入流中的数据暂存在内存中,然后从缓冲区中读取数据。这样可以减少对输入流的频繁读操作,提高效率。
字节码生成:Hessian2使用了字节码生成技术来优化底层的序列化和反序列化操作。通过生成动态字节码,可以减少反射操作和方法调用的开销,提高执行效率。
总结一下
Hessian2的一些优化算法和策略其实在别的序列化协议中也有类似的实现,甚至他们的实现可能更优,但为什么他能作为Dubbo的默认协议呢?
主要就是他使用的是二进制格式进行序列化,相比文本类型的协议,二进制格式的内容更快,更省空间。
Jdk
JDK序列化在Dubbo中的引用就几行比较简单的代码
@Override
public Object readObject() throws IOException, ClassNotFoundException {
byte b = getObjectInputStream().readByte();
if (b == 0) {
return null;
}
return getObjectInputStream().readObject();
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls) throws IOException,
ClassNotFoundException {
return (T) readObject();
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
return (T) readObject();
}
@Override
public void writeObject(Object obj) throws IOException {
if (obj == null) {
getObjectOutputStream().writeByte(0);
} else {
getObjectOutputStream().writeByte(1);
getObjectOutputStream().writeObject(obj);
}
}它的原理如下:
-
Java对象序列化:当一个Java对象需要进行序列化时,JDK会通过检测该对象是否实现了Serializable接口来确定是否可以进行序列化。如果实现了Serializable接口,JDK会将对象的状态以字节流的形式保存到内存中,然后可以将这个字节流存储到文件、数据库或通过网络传输给其他系统。
-
序列化过程:JDK将Java对象转换为字节流的过程主要参考以下步骤: a. 创建一个字节流输出流(ObjectOutputStream),用于存储序列化后的字节流。 b. 当调用writeObject()方法时,JDK会检查对象的类是否实现了Serializable接口。如果没有实现,将会抛出NotSerializableException异常。 c. JDK会对对象的类层级进行递归处理,将对象的所有成员(包括非静态和非瞬态的成员变量)序列化到字节流中。如果成员变量是引用类型,JDK会对引用对象进行相同的序列化操作。 d. 递归处理完成后,JDK会将字节流写入到字节流输出流中。
-
Java对象反序列化:当需要将字节流转换为Java对象时,JDK会根据字节流中的类描述信息以及字节流的数据信息,重新构建出与序列化前完全相同的Java对象。
-
反序列化过程:JDK将字节流转换为Java对象的过程主要参考以下步骤: a. 创建一个字节流输入流(ObjectInputStream),用于读取序列化后的字节流。 b. 当调用readObject()方法时,JDK会从字节流中读取字节数组,并根据字节流的类描述信息和数据信息,重新构建出Java对象。 c. JDK会对Java对象的类层级进行递归处理,将成员变量的值赋给对应的对象。 d. 递归处理完成后,JDK会返回反序列化后的Java对象。
JDK序列化协议的原理就是通过Java的反射机制和流式操作,将Java对象转换为字节流,或将字节流转换为Java对象。这种序列化协议的实现简单,但对于复杂的对象结构和大量数据的处理可能会存在效率和安全性的问题,需要在实际应用中慎重使用。
Kryo
Dubbo中Kryo的序列化代码不多,就是引用Kryo的能力做序列化和反序列化能力
@Override
public Object readEvent() throws IOException, ClassNotFoundException {
try {
return kryo.readObjectOrNull(input, String.class);
} catch (KryoException e) {
throw new IOException(e);
}
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> clazz) throws IOException, ClassNotFoundException {
try {
return kryo.readObjectOrNull(input, clazz);
} catch (KryoException e) {
throw new IOException(e);
}
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> clazz, Type type) throws IOException, ClassNotFoundException {
return readObject(clazz);
}
@Override
public void writeBytes(byte[] v, int off, int len) throws IOException {
if (v == null) {
output.writeInt(-1);
} else {
output.writeInt(len);
output.write(v, off, len);
}
}
@Override
public void writeUTF(String v) throws IOException {
output.writeString(v);
}
@Override
public void writeObject(Object v) throws IOException {
kryo.writeObjectOrNull(output, v, v.getClass());
}Kryo的使用场景
我之前是没听说过Kryo的,那么Kryo的性能如何呢?
- Kryo通常被认为是更高性能的序列化框架。它使用了类似于Java的反射机制,可以在运行时动态生成序列化和反序列化的代码,以提高序列化和反序列化的效率。
- Kryo生成的序列化字节流通常比Hessian2更紧凑,减少了网络传输的开销。
- 因为Kryo的高性能和紧凑的序列化字节流,使得它在存储或者传输方面也非常适合使用。比如redis,memcache,kafka,RocketMQ,Mysql等。
- 如果对性能要求非常高,而且数据传输量也比较大,传输的对象结构比较复杂的话,可以选择Kryo。它适用于分布式系统、缓存、消息队列、数据存储等场景
Kryo的高性能和适合处理复杂结构的对象依赖它使用的一下具体的技术
压缩策略:Kryo可以通过配置使用压缩算法(如LZ4、Snappy等)对序列化后的数据进行压缩,从而减小数据的传输大小(这两种策略并不是压缩比最好的,但是其压缩速率是非常突出的,压缩比和压缩速度很难两者兼得)。(Lz4压缩算法学习-CSDN博客,压缩算法选型(gzip/snappy/lz4)及性能对比-腾讯云开发者社区-腾讯云)
缓存策略:Kryo使用缓存来存储已序列化的对象和类信息,避免重复序列化相同的对象和类信息,提高序列化和反序列化的性能。Kryo提供了注册机制,可以将频繁使用的类提前注册到缓存中。
无需预定义类:Kryo支持动态注册和序列化未提前定义的类,即可以在序列化时动态地发现和记录未知的类,而不需要手动指定。
数据紧凑表示:Kryo采用紧凑的二进制表示形式,将对象的字段和属性以字节流的形式进行存储,减少了序列化后的数据大小。
序列化方式:Kryo直接将对象的字段和属性按照二进制形式序列化成字节流,而不需要将对象转换为中间形式(如XML、JSON)进行序列化。这种直接的序列化方式可以减少序列化和反序列化的开销
Msgpack
Dubbo中Msgpack的序列化代码不多,就是引用Msgpack的能力做序列化和反序列化能力
@Override
public Object readObject() throws IOException, ClassNotFoundException {
return om.readValue(this.in, Object.class);
}
@Override
public <T> T readObject(Class<T> cls) throws IOException, ClassNotFoundException {
return read(cls);
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls, Type type) throws IOException, ClassNotFoundException {
Object value = readObject(cls);
return (T) PojoUtils.realize(value, cls, type);
}
private <T> T read(Class<T> cls) throws IOException {
return om.readValue(this.in, cls);
}MsgPack是一种高效的二进制序列化协议,可以将数据以二进制形式进行序列化和反序列化。它在数据传输和存储中拥有广泛的应用场景。
实现原理
MsgPack的实现原理是将数据按照一定的规则转换成二进制数据。它使用了一种基于标记的格式,可以根据数据类型的不同选择不同的编码方式。具体的实现原理包括以下几个方面:
数据类型标记:MsgPack中有表示不同数据类型的标记,如整数、字符串、数组等。在序列化过程中,通过标记来表示数据的类型,以便在反序列化时能够正确解析数据。
数据编码:根据数据类型的不同,MsgPack采用不同的编码方式将数据编码成二进制形式。例如,整数类型可以通过变长的方式编码,字符串类型可以通过长度前缀的方式编码。
压缩算法:MsgPack还支持使用不同的压缩算法对数据进行压缩,以减少数据传输的大小。常用的压缩算法包括Gzip和Snappy等。
应用场景
MsgPack在许多场景中都有广泛的应用,特别是在需要高效的数据传输和存储的领域。以下是一些常见的应用场景:
数据传输:MsgPack可以用于网络传输中的数据序列化和反序列化。由于MsgPack的二进制格式比文本格式更紧凑,可以减少传输的数据量,提高传输效率。
分布式系统:在分布式系统中,节点之间需要传输大量的数据。MsgPack可以将数据序列化成二进制格式,以便在网络中传输,提高系统的性能。
高性能存储:MsgPack可以用于将数据序列化后存储在磁盘或内存中。由于MsgPack的编码方式高效紧凑,可以节省存储空间,并提高数据的读写速度。
数据交换与共享:MsgPack可以用于不同系统之间的数据交换和共享。由于MsgPack支持多种编程语言,可以方便地在不同平台上进行数据交换和共享。
总结一下
MsgPack作为一种高效的二进制序列化协议,在大数据传输和高性能存储等领域有着广泛的应用。它可以提高数据传输和存储的效率,减少资源消耗,并提供跨平台的数据交换和共享能力。
MsgPack和Kryo相比
虽然MsgPack不如Kryo那么紧凑,但是它支持多语言,而Kryo是针对Java平台做的优化。
- 如果你需要在Java中处理复杂的对象图,并且关注内存效率和性能表现,Kryo可能更适合。
- 如果你需要在多个编程语言之间进行数据交互,并且关注跨平台的兼容性,MsgPack可能更适合。
Native-hessian
Dubbo中Native-hessian的序列化代码不多,就是引用Native-hessian的能力做序列化和反序列化能力
@Override
public String readUTF() throws IOException {
return input.readString();
}
@Override
public Object readObject() throws IOException {
return input.readObject();
}
@Override
@SuppressWarnings("unchecked")
public <T> T readObject(Class<T> cls) throws IOException {
return (T) input.readObject(cls);
}
@Override
public <T> T readObject(Class<T> cls, Type type) throws IOException {
return readObject(cls);
}
@Override
public void writeBytes(byte[] b, int off, int len) throws IOException {
output.writeBytes(b, off, len);
}
@Override
public void writeUTF(String v) throws IOException {
output.writeString(v);
}
@Override
public void writeObject(Object obj) throws IOException {
output.writeObject(obj);
}
可以更多的关注上面的Hessian2
Dubbo针对Hessian2的一些缺陷做了专门的优化,其底层的实现原理是一样的,都是用hessian协议做序列化和反序列化
优化了序列化和反序列化的性能:Dubbo的Hessian2在编码和解码过程中进行了性能优化,减少了不必要的操作和内存开销。这些优化能够提升序列化和反序列化的效率,减少网络传输和存储的开销。
支持更广泛的数据类型:Dubbo的Hessian2支持更多类型的数据序列化和反序列化,包括Java基本类型、集合类、自定义对象等。它能够更灵活地处理各种数据类型,并保持序列化和反序列化的一致性。
支持版本兼容性:Dubbo的Hessian2提供了版本兼容性支持,可以根据协议定义的版本信息进行兼容处理。这使得在升级或者不同版本之间的通信中能够更好地处理数据兼容性问题。
Protobuf
Dubbo中Protobuf的序列化代码不多,就是引用Protobuf的能力做序列化和反序列化能力
private <T> T read(Class<T> cls) throws IOException {
if (!ProtobufUtils.isSupported(cls)) {
throw new IllegalArgumentException("This serialization only support google protobuf messages, but the actual input type is :" + cls.getName());
}
return ProtobufUtils.deserialize(is, cls);
}
@Override
public void writeObject(Object obj) throws IOException {
/**
* Protobuf does not allow writing of non-protobuf generated messages, including null value.
* Writing of null value from developers should be denied immediately by throwing exception.
*/
if (obj == null) {
throw new IllegalStateException("This serialization only supports google protobuf objects, " +
"please use com.google.protobuf.Empty instead if you want to transmit null values.");
// obj = ProtobufUtils.convertNullToEmpty();
}
if (!ProtobufUtils.isSupported(obj.getClass())) {
throw new IllegalArgumentException("This serialization only supports google protobuf objects, current object class is: " + obj.getClass().getName());
}
ProtobufUtils.serialize(obj, os);
os.flush();
}Dubbo里面的Protobuf是对Google的原生的protobuf做了一些定制和扩展,使得更加适合Dubbo这个框架,具体做了哪些的扩展其实并不重要,感兴趣的可以自己去了解。
更多的我觉得应该了解原生的protobuf为什么具备那么高的性能
Protobuf之所以具有高性能,主要有以下几个方面的原因:
紧凑的二进制格式:Protobuf使用了一种高效的二进制编码格式,将数据序列化为紧凑的二进制数据流。相比于其他文本格式如JSON或XML,二进制编码的数据量更小,减少了网络传输的数据量和延迟。
快速的编解码算法:Protobuf使用了基于二进制编码的Varint和Zigzag编码等算法,可以高效地进行编码和解码操作。Varint可以根据字段的值大小动态选择不同长度的编码方式,而Zigzag编码可以将有符号数字转换为无符号整数,进一步减少了数据的大小。
自动生成的高效代码:通过Protobuf编译器,可以根据定义的消息结构自动生成高效的序列化和反序列化代码。这些代码经过优化,使用了高效的数据结构和算法,提高了编解码的性能。
跨平台支持:Protobuf支持多种编程语言和平台,可以在不同的系统上进行数据的序列化和反序列化。这种跨平台的支持使得Protobuf在分布式系统中的各个组件之间可以方便地进行数据交换,提高了系统的灵活性和可扩展性。
综上所述,Protobuf之所以具有高性能,是因为它使用紧凑的二进制格式,快速的编解码算法,自动生成的高效代码以及跨平台的支持。这些特性使得Protobuf在数据交换和存储方面具有较高的效率和性能优势。
Protobuf目前的使用场景?
Protobuf在许多实际生产框架中得到了广泛应用。以下是一些使用Protobuf的实际生产框架的例子:
Google的内部通信协议:Google在内部使用Protobuf作为其内部通信协议的默认选择。它在Google的许多服务和框架中被广泛使用,包括Google搜索、Gmail和Google Maps等。
gRPC:gRPC是一个开源的高性能、通用性的远程过程调用(RPC)框架,它使用Protobuf作为默认的序列化协议。gRPC可以在多种编程语言和平台上进行跨语言的通信,并且提供了强大的性能和扩展性。
Apache Kafka:Kafka是一个分布式流处理平台,用于高吞吐量、低延迟的数据流处理。Kafka使用Protobuf作为消息的序列化格式,以提高性能和节省存储空间。
Apache Hadoop:Hadoop是一个用于处理大规模数据集的开源框架,它使用Protobuf作为MapReduce任务中输入和输出的序列化格式,以提高性能和可靠性。
Etcd:Etcd是一个高可用的键值存储系统,用于分布式协调和配置共享。Etcd使用Protobuf作为其内部通信协议,以实现高效的数据传输和跨语言的互操作性。
Protostuff
Dubbo中Protostuff的序列化代码不多,就是引用Protostuff的能力做序列化和反序列化能力
@Override
public byte[] readBytes() throws IOException {
int length = dis.readInt();
byte[] bytes = new byte[length];
dis.read(bytes, 0, length);
return bytes;
}
@Override
public void writeBytes(byte[] v, int off, int len) throws IOException {
dos.writeInt(len);
byte[] bytes = new byte[len];
System.arraycopy(v, off, bytes, 0, len);
dos.write(bytes);
}同protobuf,我们只关注原生protostuff为什么会具备高性能
Protostuff之所以具有高性能,主要有以下几个方面的原因:
优化的序列化和反序列化算法:Protostuff采用了一种高效的序列化和反序列化算法,使用了类似于Protobuf的Varint和Zigzag编码等技术,以及多级缓存和预分配的方式,减少了内存分配和数据拷贝的开销,提高了序列化和反序列化的速度。
零拷贝:Protostuff利用NIO的特性,可以直接操作内存,将数据从输入流直接写入到内存中,或从内存中读取到输出流,避免了数据拷贝的过程,减少了IO操作的开销。
低依赖:Protostuff的核心代码非常精简,没有大量的依赖库,避免了额外的开销和复杂性。同时,Protostuff也支持自定义的数据格式和序列化方式,可以根据实际需求进行扩展和定制,提高了灵活性和适应性。
简单的使用方式:Protostuff提供了简单易用的API,开发者可以方便地进行对象的序列化和反序列化操作,而无需关注底层的实现细节。这种简单的使用方式使得Protostuff在实际开发中更加方便快捷。
综上所述,Protostuff之所以具有高性能,是因为它采用了优化的序列化和反序列化算法,利用零拷贝和低依赖的特性,简化了使用方式。这些特性使得Protostuff在对象的序列化和反序列化过程中具有较高的效率和性能优势。
几种重要的序列化协议的比较与选择
Kryo在处理复杂对象图上的性能表现较好,Fastjson在处理JSON数据方面表现出色,而Protobuf在处理大量数据和节省字节数方面具有优势
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis:原理速成+项目实战——Redis企业级项目实战终结篇(HyperLogLog实现UV统计)
- 第三章 垃圾收集器与内存分配策略(二)
- xtu oj 1375 Fabonacci
- 【Java 设计模式】行为型之观察者模式
- HTML+CSS+JAVASCRIPT实战项目——新年快乐特效
- PyQt6 基类QObject类介绍以及应用
- 找不到x3daudio1_7.dll怎么解决?教你如何解决x3daudio1_7.dll文件丢失问题
- 消息队列有哪些应用场景?
- CF1446C Xor Tree
- TLS 1.2详解