爬虫实战案例 -- 爬取豆瓣读书网页内容
发布时间:2023年12月21日
-
进入网站检查信息 , 确定请求方式以及相关数据
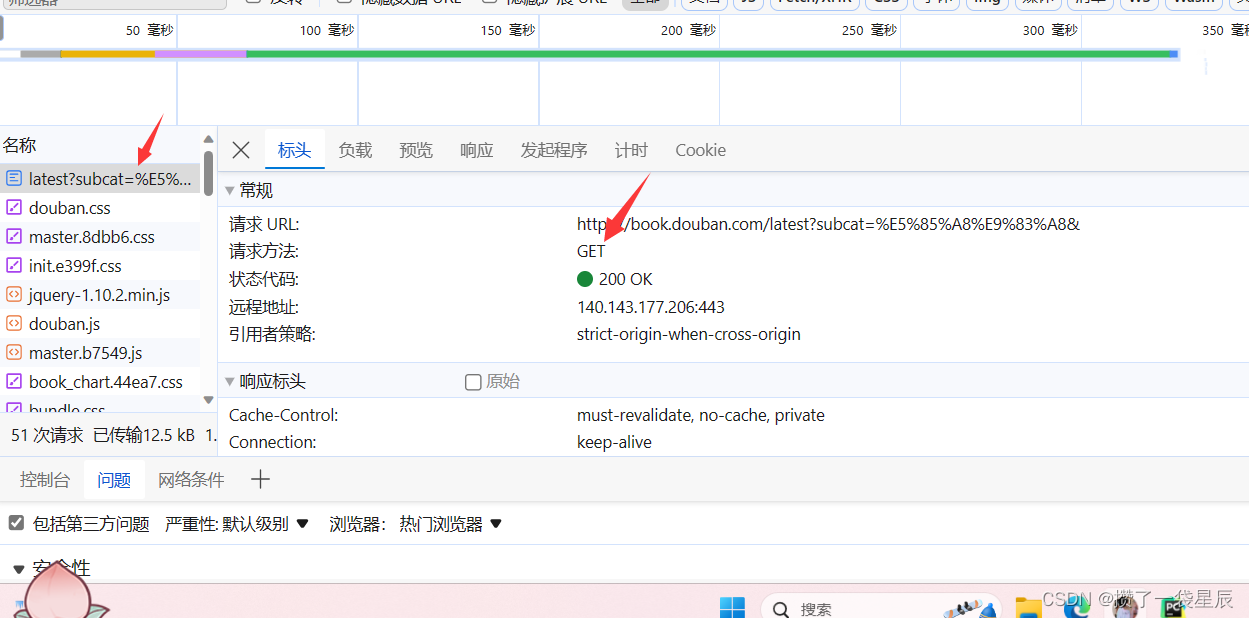
-
找到爬取目标位置
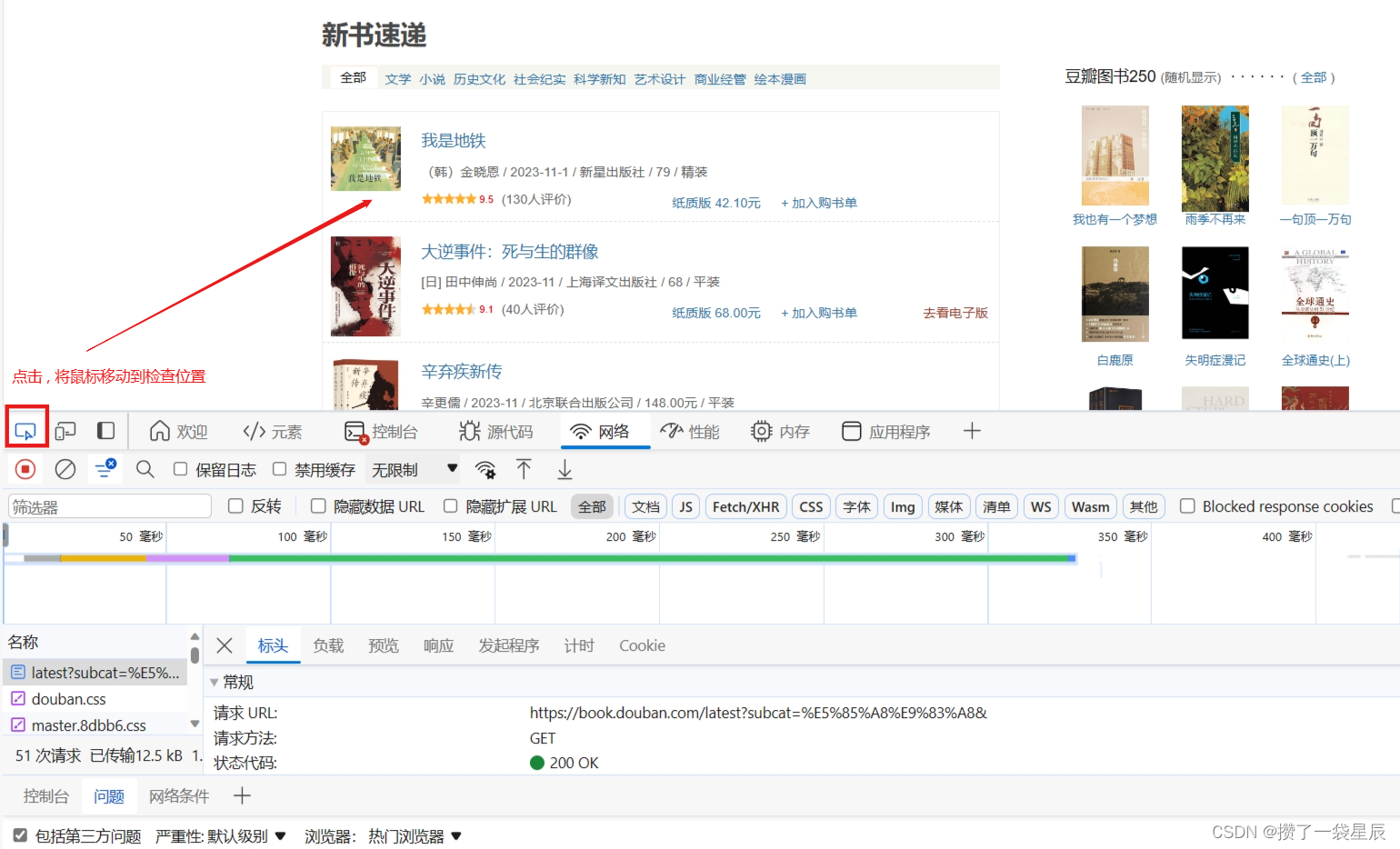
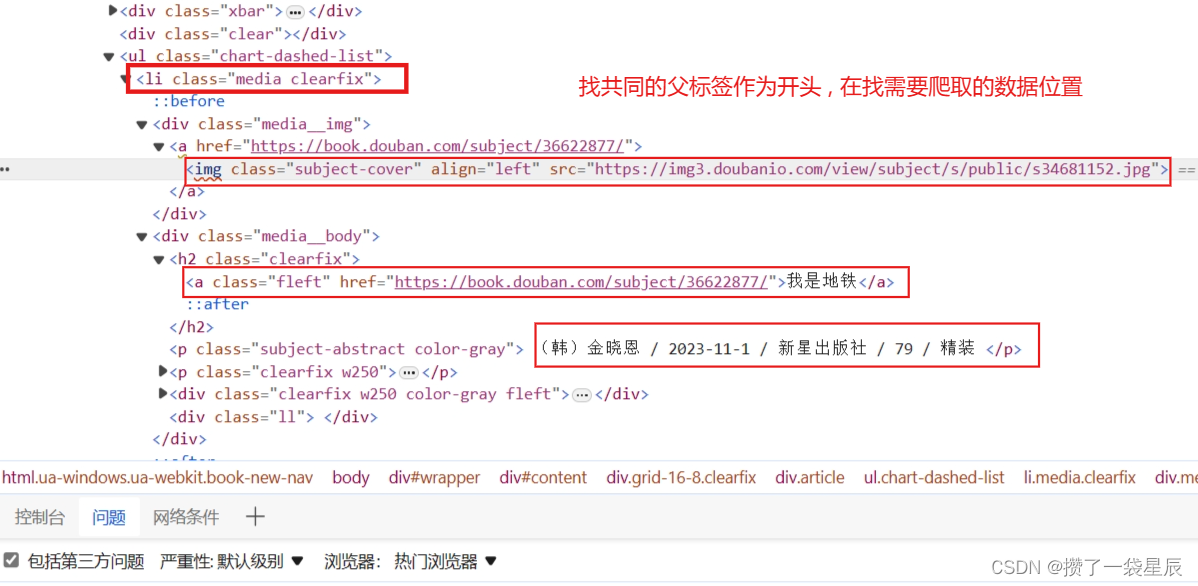
-
开始敲代码
# 链接网站
def url_link(url):
res = requests.get(url,headers = headers)
response = res.text
parse_data(response)
# 爬取信息
def parse_data(data):
msg = '<li\sclass="media\sclearfix">.*?'\
'<img\sclass="subject-cover".*?src="(.*?)"/></a>.*?'\
'class="fleft"\shref="(.*?)">(.*?)</a>.*?'\
'class="subject-abstract\scolor-gray">(.*?)</p>'
result = re.findall(msg,data,re.S)
for i in result:
img_url = i[0]
bookData = i[1]
bookName = i[2]
bookauthor = i[3].strip()
print('图片信息:', img_url)
print('详情链接:', bookData)
print('书籍名字:', bookName)
print('作者信息:', bookauthor)
print('======================')
keep_data(bookName,img_url,bookData,bookauthor)
# 保存数据
def keep_data(img, data, name, author):
# 创建文件夹
if not os.path.exists('doubanData'):
os.mkdir('doubanData')
# 保存书籍信息
with open("doubanData\db.json", "a", encoding="utf-8") as f:
f.write("书籍名称:" + name + "\n")
f.write("图片信息:" + img + "\n")
f.write("书籍详情页:" + data + "\n")
f.write('书籍作者:' + author + "\n\n")
# 保存图片信息
urlDta = requests.get(data).content
with open('doubanData/{}.jpg'.format(img),'wb') as f:
f.write(urlDta)
if __name__ == '__main__':
# 设置爬取页数
for i in range(1,6):
url = f'https://book.douban.com/latest?subcat=%E5%85%A8%E9%83%A8&p={i}'
print(f"正在爬取第{i}页")
print("====================================================================")
url_link(url)
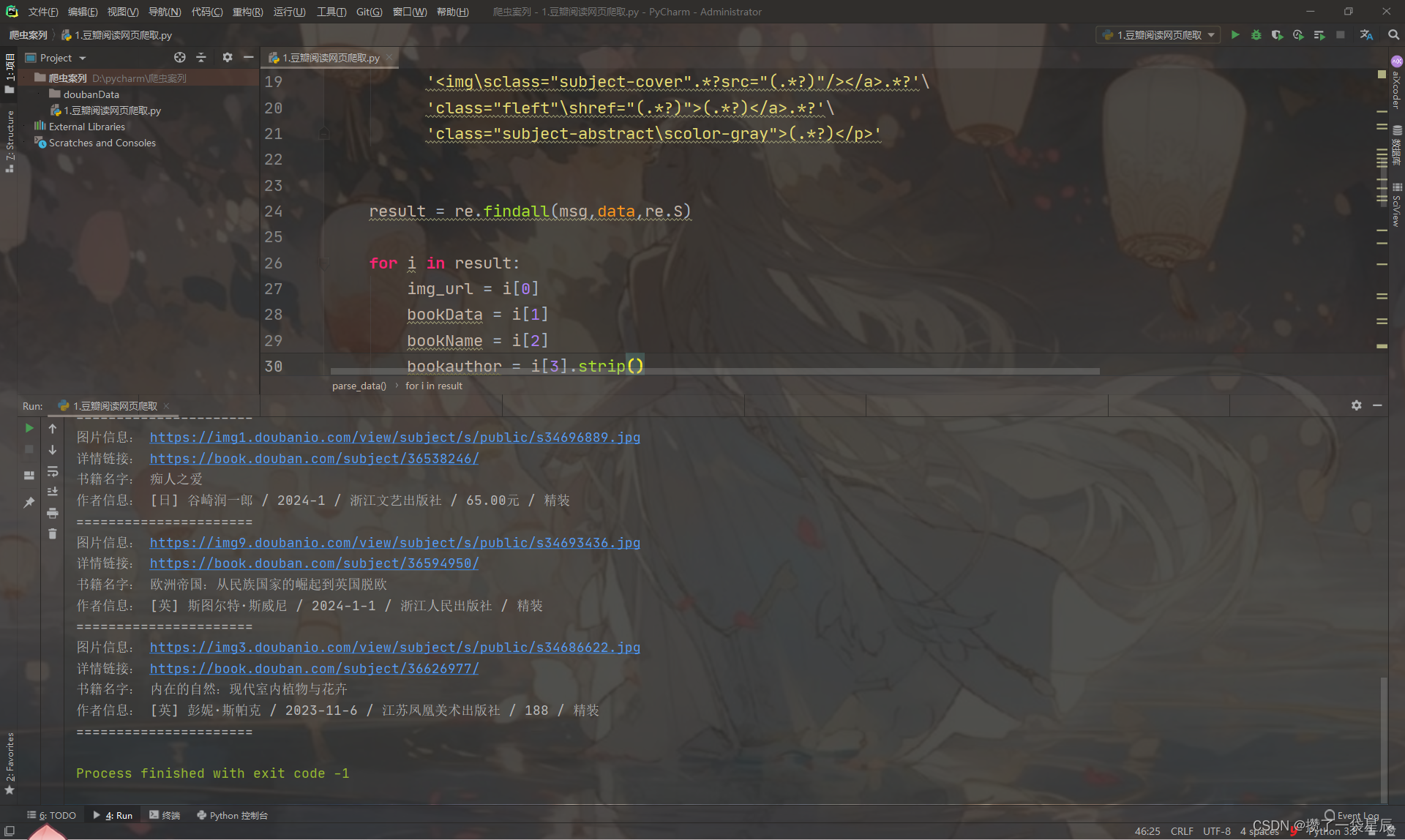
最终效果
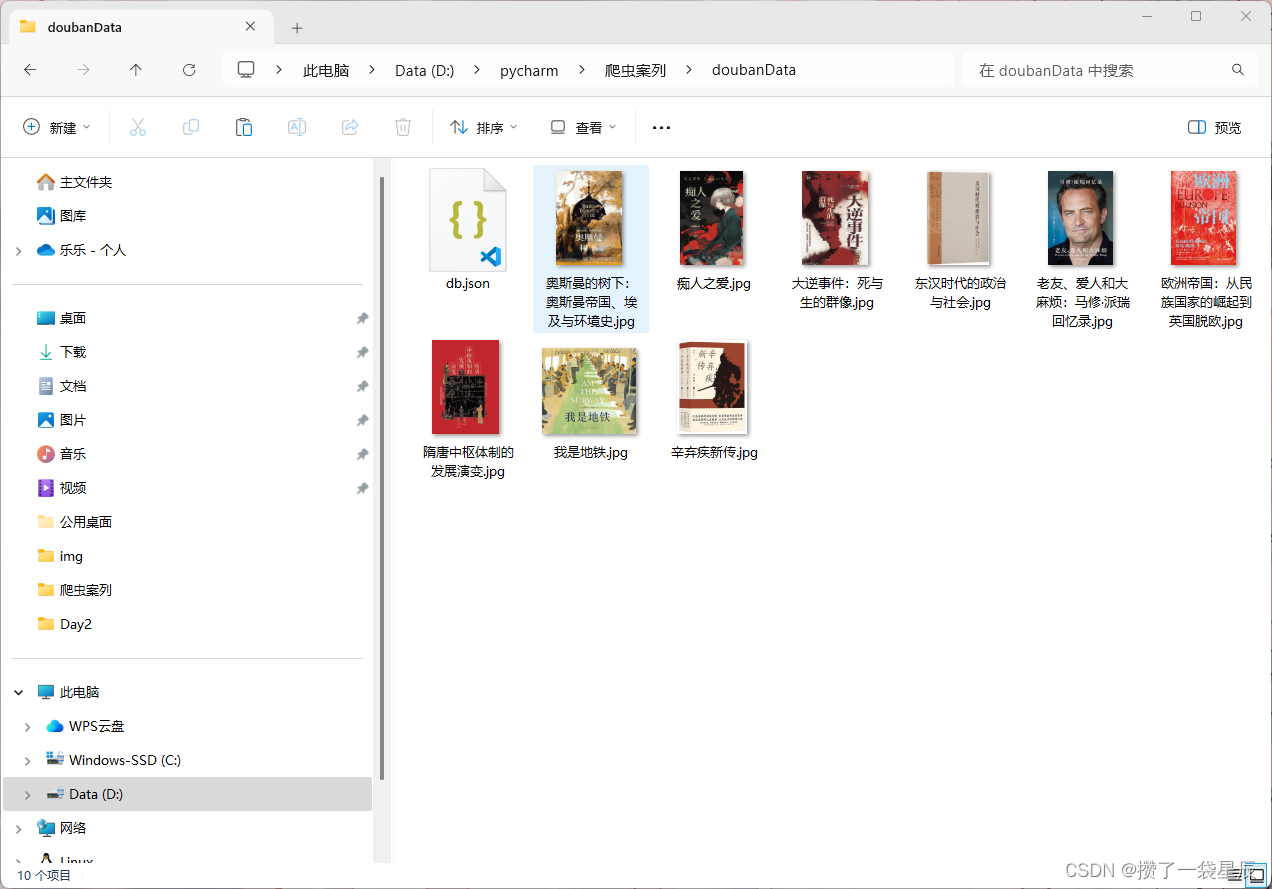
文章来源:https://blog.csdn.net/xiugtt6141121/article/details/135119167
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 优先级队列与仿函数
- dubbox框架!!!
- Everything——搜索神器的安装使用教程
- Cocos Creator:坐标系
- 《PySpark大数据分析实战》-12.Spark on YARN配置Spark运行在YARN上
- 【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
- Freemarker基本语法与案例讲解
- 【改进YOLOv8】电动车电梯入户检测系统:融合HGNetv2改进改进YOLOv8
- 数据结构【线性表篇】(四)
- 九、C++结构体(1)