C++——结构体
发布时间:2024年01月22日
1,结构体基本概念
结构体属于用户自定义的数据类型,允许用户存储不同的数据类型。像int(整型),浮点型,bool型,字符串型等都是属于系统内置的数据类型。而今天要学习的结构体则是属于我们自定义的一种数据类型
2,结构体定义和使用
语法:struct 结构体名 { 结构体成员列表 };
通过结构体创建变量的方式有三种,struct关键字不可省略:
- struct 结构体名 变量名
- struct 结构体名 变量名 = {成员1值,成员2值...}
- 定义结构体时顺便创建变量
#include<bits/stdc++.h>
using namespace std;
//1,创建学生数据类型 :学生包括(姓名,年龄,分数)
//自定义数据类型,一些类型集合组成的一个类型
//语法 struct 类型名称{ 成员列表 }
struct Student{
//成员列表
//姓名
string name;
//年龄
int age;
//成绩
int score;
}s3;//顺便创建结构体变量s3.
//2,通过学生类型创建具体学生
int main(){
//2.1 struct Student s1
Student s1;
s1.name="张三";
s1.age=18;
s1.score=100;
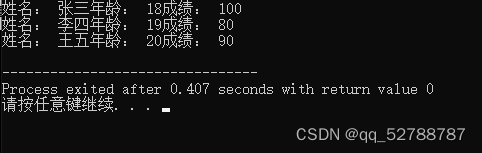
cout<<"姓名: "<<s1.name<<"年龄: "<<s1.age<<"成绩: "<<s1.score<<endl;
//2.2 struct Student s2={...}
Student s2={"李四",19,80};
cout<<"姓名: "<<s2.name<<"年龄: "<<s2.age<<"成绩: "<<s2.score<<endl;
//2.3 在定义结构体时顺便创建结构体变量
s3.name="王五";
s3.age=20;
s3.score=90;
cout<<"姓名: "<<s3.name<<"年龄: "<<s3.age<<"成绩: "<<s3.score<<endl;
} 
结构体在具象化的时候,可以通过三种方式创建具体的类型:
- ?struct Student s1
- ?struct Student s2={...}
- ?在定义结构体时顺便创建结构体变量?
3,结构体数组
作用:将自定义的结构体放入到数组中方便维护,也就是数组中的每一个元素都是我们自定义的同一种数据结构类型,也就是结构体。
语法:struct? 结构体名 数组名[元素个数]={ {},{},{},...,{} }
示例:
#include<bits/stdc++.h>
using namespace std;
//结构体数组
struct student{
string name;
int age;
int score;
};
int main(){
struct student stuarry[3]={
{"july",18,100},
{"miss.li",20,90},
{"zhang",21,130}
};
stuarry[1].name="san";
stuarry[1].age=21;
stuarry[1].score=100;
for(int i=0;i<3;i++){
cout<<"姓名:"<<stuarry[i].name<<endl;
cout<<"年龄:"<<stuarry[i].age<<endl;
cout<<"成绩:"<<stuarry[i].score<<endl;
}
}4,结构体指针
作用:利用指针访问结构体中的成员
- 利用操作符->可以通过结构体指针访问结构体属性
struct student{
string name;
int age;
int score;
};
int main(){
//创建学生结构体变量
student s={"zhang",18,100};
//通过指针指向结构体变量
student *p=&s;
//通过指针访问结构体变量中的数据
p->age=20;
cout<<"name= "<<p->name<<"age= "<<p->age<<"score= "<<p->score<<endl;
} 通过上述例子我们可以总结出来:
-
指针在定义时,指针等号左右的数据结构要对应,int对int,float对float,struct对struct。
-
指针通过->操作符可以访问成员
5,结构体嵌套结构体? ? ?
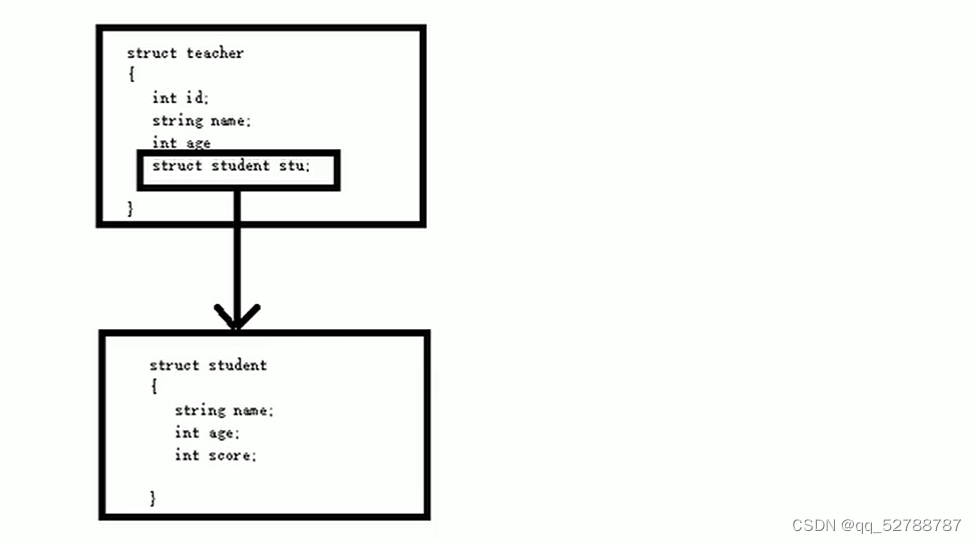
作用:结构体中的成员可以是另一个结构体
例如:每个老师辅导一个学员,一个老师的结构体中,记录一个学生的结构体
嵌套示意图:
#include<bits/stdc++.h>
using namespace std;
struct student{
string name;
int age;
int score;
};//定义学生结构体
struct teacher{
int id;
string name;
int age;
student stu;//代表这个老师所带的学生
};
int main(){
teacher t;
t.id=1000;
t.age=50;
t.name="Mr.li";
t.stu.age=10;
t.stu.name="xiaowang";
t.stu.score=60;
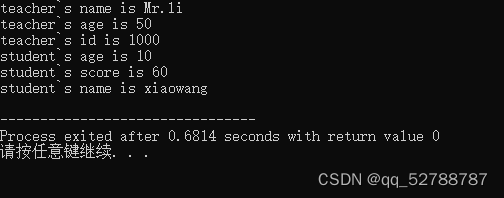
cout<<"teacher`s name is "<<t.name<<endl;
cout<<"teacher`s age is " <<t.age<<endl;
cout<<"teacher`s id is "<<t.id<<endl;
cout<<"student`s age is "<<t.stu.age<<endl;
cout<<"student`s score is "<<t.stu.score<<endl;
cout<<"student`s name is "<<t.stu.name<<endl;
} 
? ? ? ? ? ? ? ? ? ? ? ? ? ??
6,结构体做函数参数
作用:将结构体作为参数向函数中传递
传递方式有两种:
- 值传递(形参修饰不会改变实参)
- 地址传递(如果函数形参发生改变,实参也会跟着改变)
示例:
#include<bits/stdc++.h>
using namespace std;
struct student{
string name;
int age;
int score;
};//定义学生结构体
void printstudent1(struct student s){
s.age=100;
cout<<"子函数1中,姓名:"<<s.name<<"年龄为 "<<s.age<<"成绩为 "<<s.score<<endl;
}
void printstudent2(struct student *p){
p->age=100;
cout<<"子函数2中,姓名:"<<p->name<<"年龄为:"<<p->age<<"成绩为:"<<p->score<<endl;
}
int main(){
student s;
s.name="Bob";//实参
s.age=20;
s.score=85;
printstudent1(s);// 值传递,形参修饰实参,不会改变实参的值
printstudent2(&s);//地址传递
cout<<"main函数中"<<"姓名:"<<s.name<<"年龄为 "<<s.age<<"成绩为 "<<s.score<<endl;
}?主函数里的赋值为实参,函数中的赋值为形参,大家可以相应修改两种参数传递方式的参数值看看主函数里的实参会怎么变化,得出的结论亦是上面两种结论。值传递修改形参不会改变实参的值,地址传递则会修改实参的值,具体原理参照C++——函数-CSDN博客。
最根本的原理在于:值传递参数时是独立开辟了一些内存空间,而地址传递则是用指针直接指向实参地址
7,结构体中const使用场景
8,结构体案例
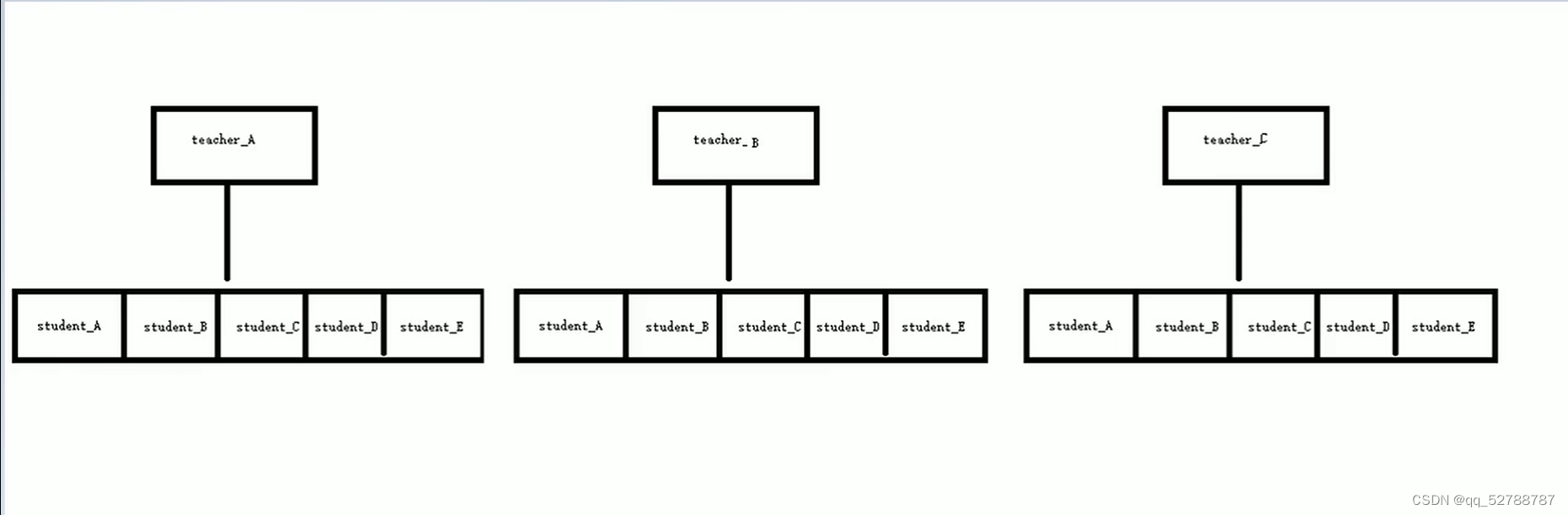
案例描述:学校正在做毕设项目,每名老师带领五个学生,总共有三名老师
#include<bits/stdc++.h>
using namespace std;
struct student{
string name;
int score;
};//定义学生结构体
struct teacher{
string name;
student arrstudent[5];
};
//给老师和学生赋值的函数
void teacher(struct teacher array[],int len){
string nameseed="ABCDE";
for(int i=0;i<len;i++){
array[i].name="teacher_";
array[i].name+=nameseed[i];
for(int j=0;j<5;j++){
array[i].arrstudent[j].name="student_";
array[i].arrstudent[j].name+=nameseed[j];
int random=rand()%60+40;
array[i].arrstudent[j].score=random;
}
}
}
void print(struct teacher array[],int len){
for(int i=0;i<len;i++){
cout<<" teacher`s name is "<<array[i].name<<endl;
for(int j=0;j<5;j++){
cout<<"student`s name is "<<array[i].arrstudent[j].name<<"score is "<<array[i].arrstudent[j].score<<endl;
}
}
}
int main(){
struct teacher array[3];
int len=sizeof(array)/sizeof(array[0]);
teacher(array,len);
print(array,len);
}
文章来源:https://blog.csdn.net/qq_52788787/article/details/135751279
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《最新出炉》系列初窥篇-Python+Playwright自动化测试-6-元素定位大法-下篇
- 性能篇:LinkedList循环为什么使用Iterator而不是for?
- 独立站的移动端优化:确保网站在手机和平板设备上具有良好的用户体验和交互效果
- 前端常用的Vscode插件
- 软件测试开发工程师常用的测试工具详解
- pg数据库计算两个时间戳相差的天数
- RT-Thread学习
- 第十三章 需求工程之对数据关系进行建模
- UG模型的显示与隐藏
- CIM:插补时空数据框架2021篇