FPGA时序分析实例篇(上)------逻辑重组和DSP资源合理利用
声明:本文章转载自FPGA开源工坊,作者xiaotudou
在开始之前,有个预备知识:当时序不满足下列给出的图的要求时,STA分析(静态时序分析)会报错,在低频时可能忽略不计可以正常运行,但是频率上去之后很有可能会导致电路功能的错误。因此我们不能忽略,要对logic修改或者修改频率以满足STA要求。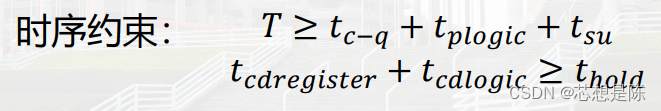
????????本篇介绍了一次时序调优的过程,也就是重新修改代码逻辑,解决时序瓶颈(本文是缩小Logic delay)。在设计初期就应该考虑到这个问题,比如DSP的流水线寄存器,BRAM的输出寄存器这些在设计初期就考虑使用到它们,来获取更好的时序。
? ? ? ? 因此,良好的编码习惯和风格有助于我们避免时序违例。
????????在FPGA上完成了Canny算法(一种图像处理算法)的实现时,遇到了时序不收敛的问题,记录一下。

可以看到时序的建立时间不满足。
我们在约束的主时钟频率是200MHz,也就是5ns,但是建立时间是-2.12ns,也就是说这个工程只能跑到7.12ns也就是140.45MHz,远远不能满足我们预先的设计。

怎么根据时序约束和建立保持时间裕量来分析工程能跑到的最大频率可以参考下面:
首先来看一下PR之后是哪条路径不收敛,究竟是同一时钟域下的还是跨时钟域的路径,两者的处理方式不一样。
可以看到是Intra-clock paths爆红了,也就是同一时钟域下的路径时序不收敛。接下来看具体的时序路径:
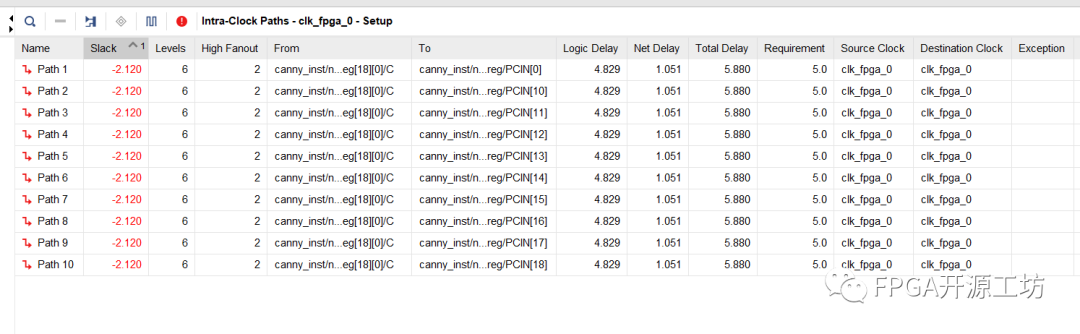
可以看到logic delay远远比net delay大,那么我们就需要去降低logic delay,也就是要把我们的组合逻辑搞简单一点。如果是net delay比较大就要考虑是不是布线拥塞的问题了,两者的处理方式不太一样。
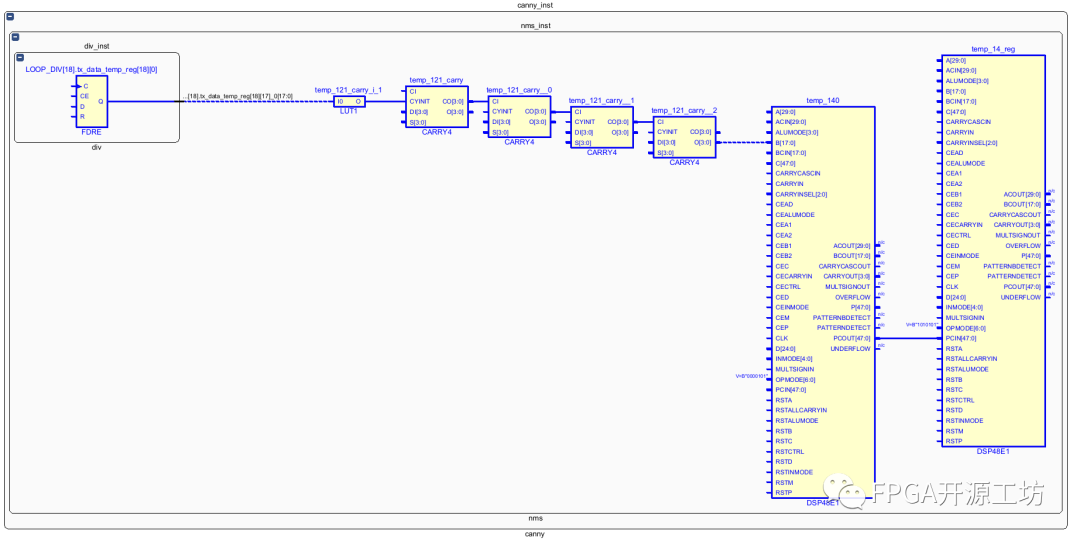
再来看一下它的电路图,可以看到在左边的寄存器输出之后经过LUT,Carry等组合逻辑之后,给到DSP的输入端。一般来说DSP的几级pipline最好的都用上,这样DSP可以跑到更高的频率。
再来看一下具体的路径报告:
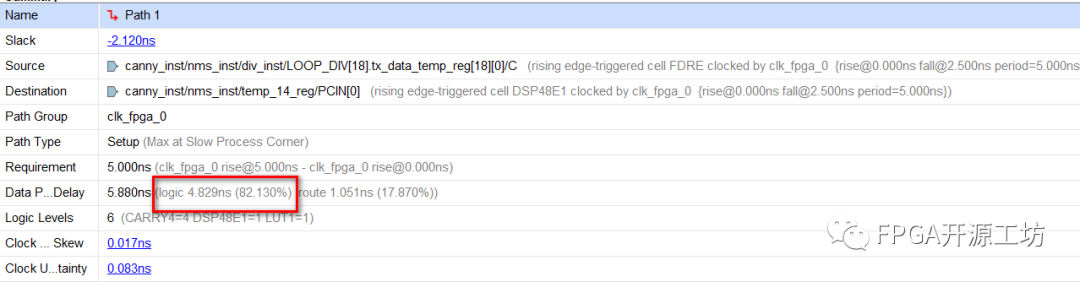
可以看到logic的延时占到了82%,因此如果要解决这个时序为例,就必须要把logic delay给降低。
两者的比例可以参考,七系列的FPGA和UltraScale系列的FPGA不太一样:


来看一下这一个时序为例对应的代码:

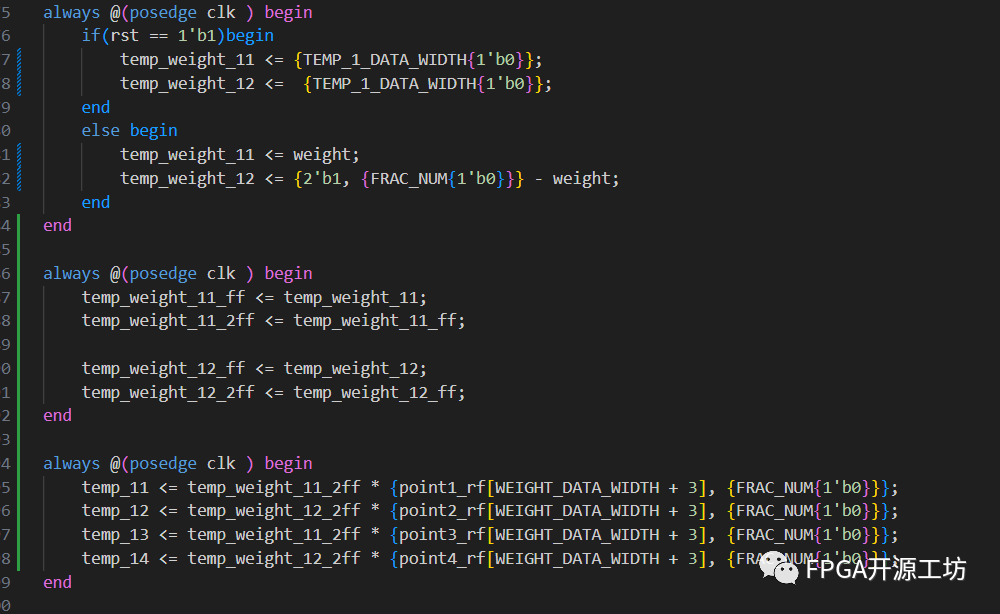
可以看到其实挺复杂的,有减法,有乘法。其中减法是被vivado用LUT+Carry搭了起来,乘法用的DSP。
要解决这个问题,就是把这一大段代码进行流水拆开嘛,把减法拆一级流水,乘法器拆为三级流水。
将代码修改为以下的样子,再来综合一下

可以看到时序就收敛了。
再来看一下生成电路结构:
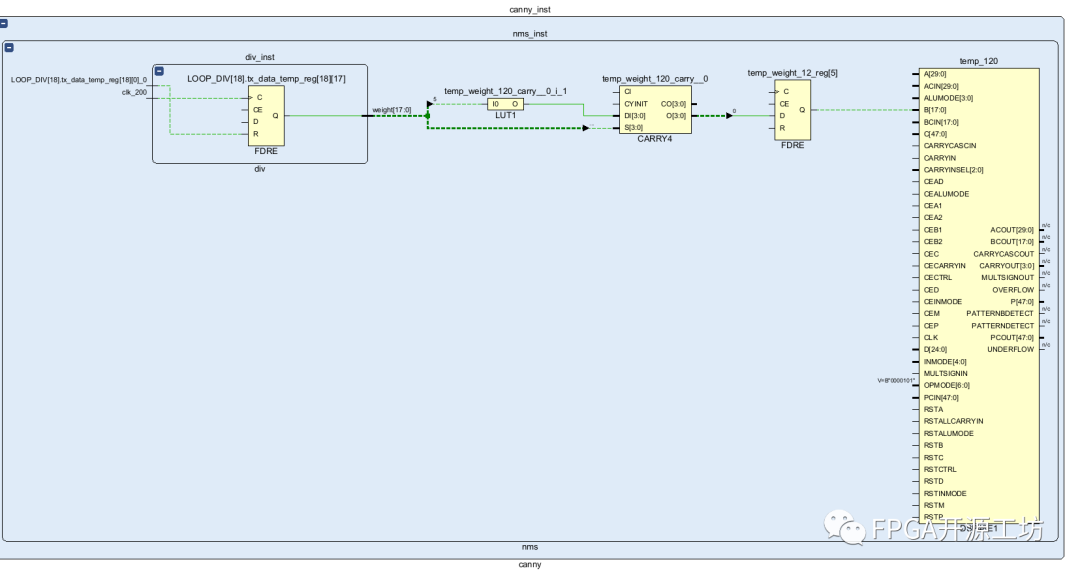
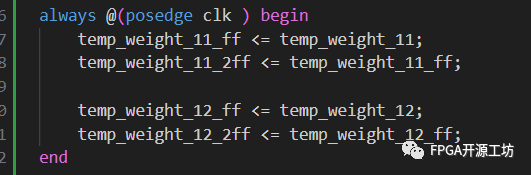
可以看到FDCE之后仍然是LUT+Carry的形式,用于做减法运算,然后再接入DSP的输入,在源码里面做完减法之后还有这两级寄存器,但是在电路图里面看不到他们了,这是因为这两级寄存器被DSP给吸收掉了,用于提高DSP的时钟频率,这两级寄存器会利用DSP单元内部的寄存器来实现,并不会增加我们的资源占用,DSP核里面的资源不用也是浪费。
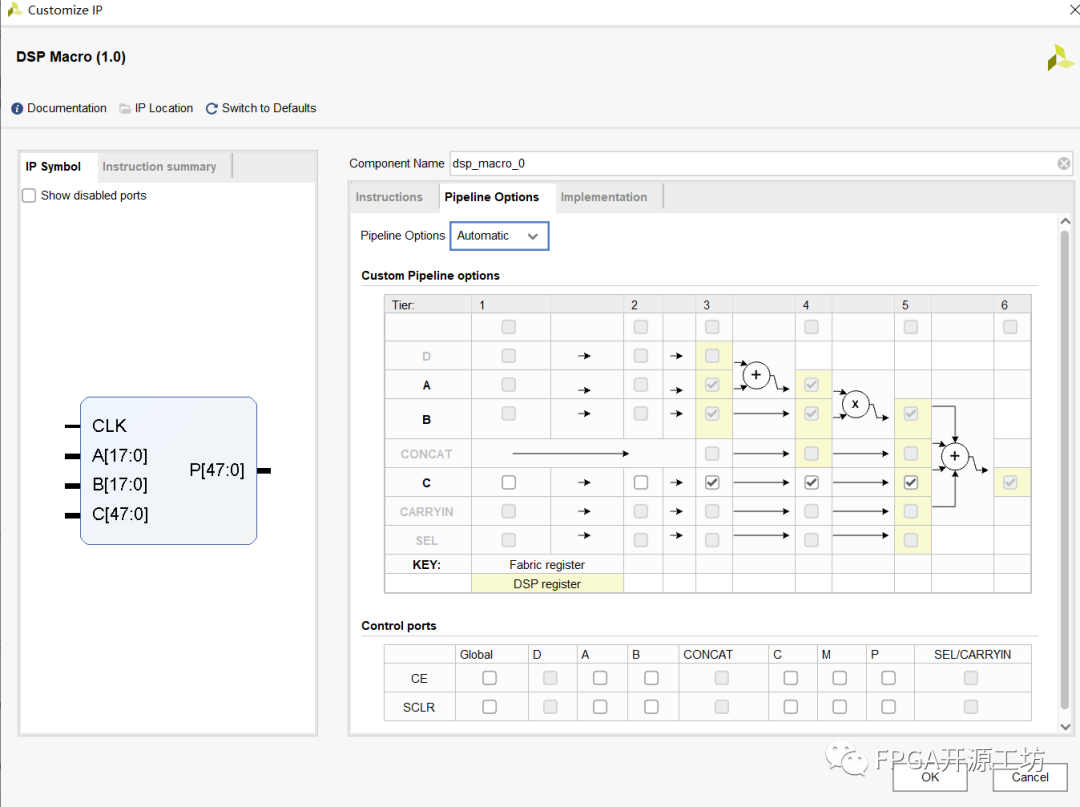
上图为DSP单元里面的寄存器排布,可以看到有六级。
细心的朋友可能看到,上图的电路结构不仅有DSP和LUT模块,还有FDCE+CARRY4进位链,这些对时序影响同样不可忽视,我们将在下一篇中讨论。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- FastReport动态绑定数据源
- IDEA项目代码飘红,但可以正常编译运行,且清除缓存也不管用,解决办法!!
- 什么是远程桌面协议 (RDP)?远程桌面协议 (RDP) 替代方案
- 算法分析与设计课后练习29
- 基本shell功能实现(exec系列程序替换函数练习)
- go语言(八)---- map
- Go、Python、Java、JavaScript等语言的求余(取模)计算
- 阿里云轻量应用服务器和e/u1/c7/g7/r7/c8y/g8y/r8y实例如何选择?
- 【2024-01-22】某极验3流程分析-滑块验证码
- ASCII、GBK与UTF-8的前世今生