分布式【一致性Hash算法简介】
一致性Hash是一种特殊的Hash算法,由于其均衡性、持久性的映射特点,被广泛的应用于负载均衡领域,如nginx和memcached都采用了一致性Hash来作为集群负载均衡的方案。
一致性Hash算法简介
在了解一致性Hash算法之前,先来讨论一下Hash本身的特点。普通的Hash函数最大的作用是散列,或者说是将一系列在形式上具有相似性质的数据,打散成随机的、均匀分布的数据。负载均衡正是利用这一特性,对于大量随机的请求或调用,通过一定形式的Hash将他们均匀的散列,从而实现压力的平均化。
举个例子,如果我们给每个请求生成一个Key,只要使用一个非常简单的Hash算法Group = Key % N来实现请求的负载均衡,如下:
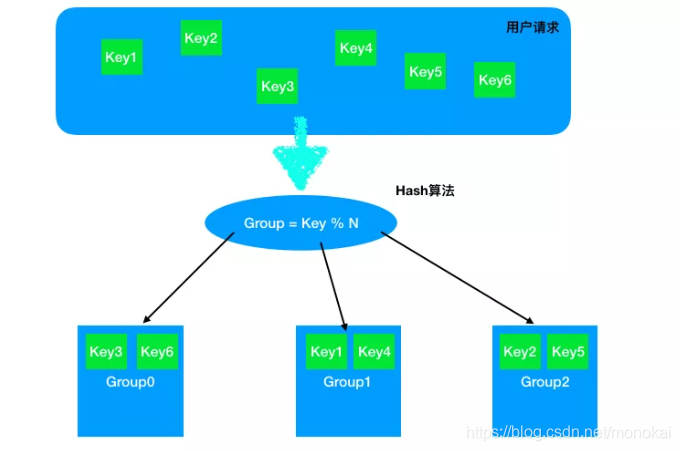
不难发现,这样的Hash只要集群的数量N发生变化,之前的所有Hash映射就会全部失效。如果集群中的每个机器提供的服务没有差别,倒不会产生什么影响,但对于分布式缓存这样的系统而言,映射全部失效就意味着之前的缓存全部失效,后果将会是灾难性的。
一致性Hash通过构建环状的Hash空间代替线性Hash空间的方法解决了这个问题,如下图:
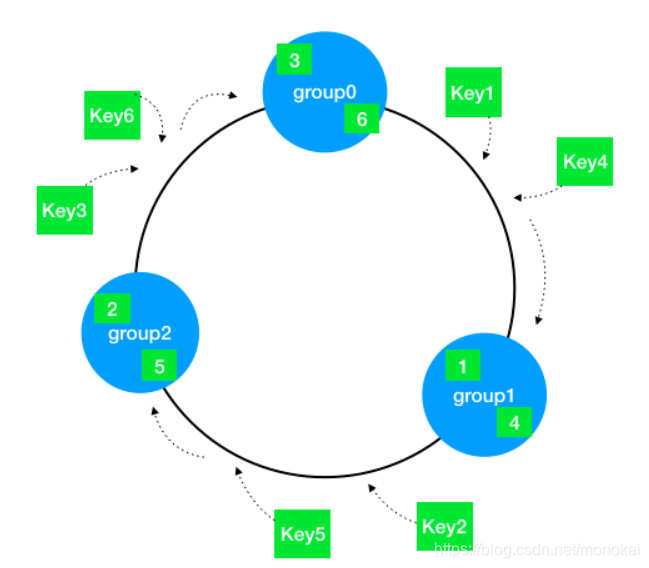
整个Hash空间被构建成一个首尾相接的环,使用一致性Hash时需要进行两次映射。
第一次,给每个节点(集群)计算Hash,然后记录它们的Hash值,这就是它们在环上的位置。
第二次,给每个Key计算Hash,然后沿着顺时针的方向找到环上的第一个节点,就是该Key储存对应的集群。
分析一下节点增加和删除时对负载均衡的影响,如下图:
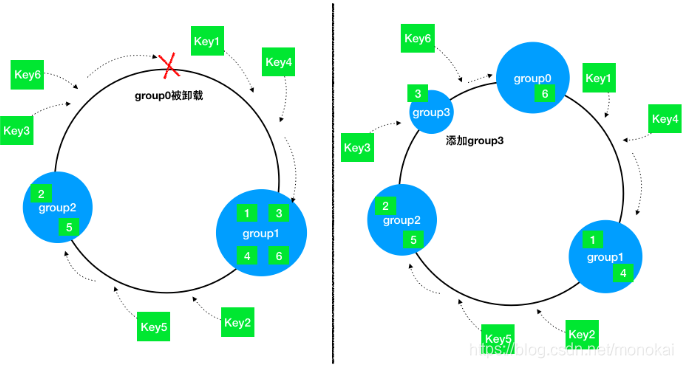
可以看到,当节点被删除时,其余节点在环上的映射不会发生改变,只是原来打在对应节点上的Key现在会转移到顺时针方向的下一个节点上去。增加一个节点也是同样的,最终都只有少部分的Key发生了失效。不过发生节点变动后,整体系统的压力已经不是均衡的了,下文中提到的方法将会解决这个问题。
问题与优化
最基本的一致性Hash算法直接应用于负载均衡系统,效果仍然是不理想的,存在诸多问题,下面就对这些问题进行逐个分析并寻求更好的解决方案。
数据倾斜
如果节点的数量很少,而hash环空间很大(一般是 0 ~ 2^32),直接进行一致性hash上去,大部分情况下节点在环上的位置会很不均匀,挤在某个很小的区域。最终对分布式缓存造成的影响就是,集群的每个实例上储存的缓存数据量不一致,会发生严重的数据倾斜。
缓存雪崩
如果每个节点在环上只有一个节点,那么可以想象,当某一集群从环中消失时,它原本所负责的任务将全部交由顺时针方向的下一个集群处理。例如,当group0退出时,它原本所负责的缓存将全部交给group1处理。这就意味着group1的访问压力会瞬间增大。设想一下,如果group1因为压力过大而崩溃,那么更大的压力又会向group2压过去,最终服务压力就像滚雪球一样越滚越大,最终导致雪崩。
引入虚拟节点
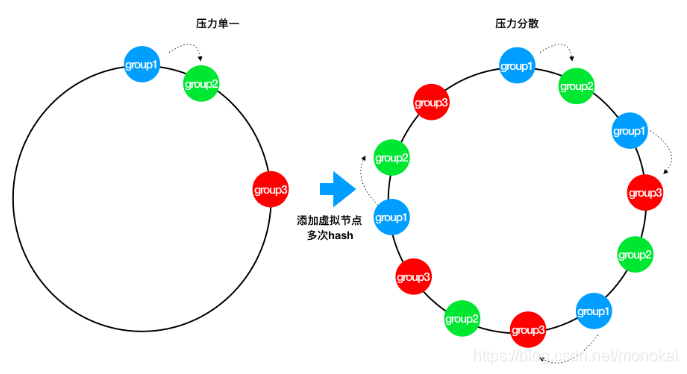
解决上述两个问题最好的办法就是扩展整个环上的节点数量,因此我们引入了虚拟节点的概念。一个实际节点将会映射多个虚拟节点,这样Hash环上的空间分割就会变得均匀。
同时,引入虚拟节点还会使得节点在Hash环上的顺序随机化,这意味着当一个真实节点失效退出后,它原来所承载的压力将会均匀地分散到其他节点上去。
优雅缩扩容
缓存服务器对于性能有着较高的要求,因此我们希望在扩容时新的集群能够较快的填充好数据并工作。但是从一个集群启动,到真正加入并可以提供服务之间还存在着不小的时间延迟,要实现更优雅的扩容,我们可以从两个方面出发:
高频Key预热
负载均衡器作为路由层,是可以收集并统计每个缓存Key的访问频率的,如果能够维护一份高频访问Key的列表,新的集群在启动时根据这个列表提前拉取对应Key的缓存值进行预热,便可以大大减少因为新增集群而导致的Key失效。
具体的设计可以通过缓存来实现,如下:
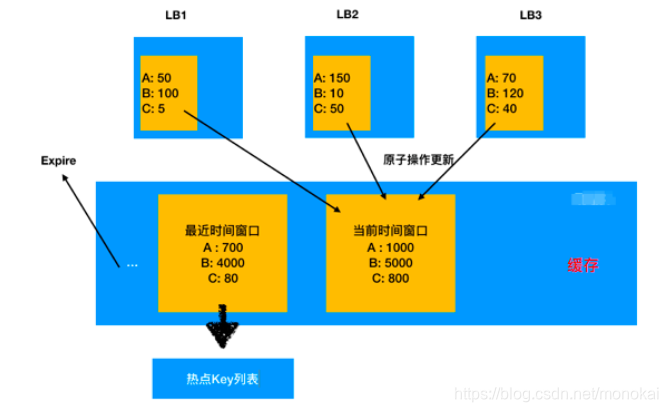
不过这个方案在实际使用时有一个很大的限制,那就是高频Key本身的缓存失效时间可能很短,预热时储存的Value在实际被访问到时可能已经被更新或者失效,处理不当会导致出现脏数据,因此实现难度还是有一些大的。
历史Hash环保留
回顾一致性Hash的扩容,不难发现新增节点后,它所对应的Key在原来的节点还会保留一段时间。因此在扩容的延迟时间段,如果对应的Key缓存在新节点上还没有被加载,可以去原有的节点上尝试读取。
举例,假设我们原有3个集群,现在要扩展到6个集群,这就意味着原有50%的Key都会失效(被转移到新节点上),如果我们维护扩容前和扩容后的两个Hash环,在扩容后的Hash环上找不到Key的储存时,先转向扩容前的Hash环寻找一波,如果能够找到就返回对应的值并将该缓存写入新的节点上,找不到时再透过缓存,如下图:
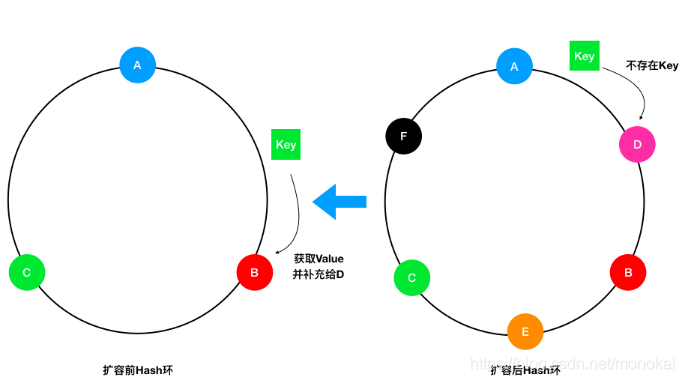
这样做的缺点是增加了缓存读取的时间,但相比于直接击穿缓存而言还是要好很多的。优点则是可以随意扩容多台机器,而不会产生大面积的缓存失效。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十一代思域雾灯改双光透镜解决方案
- PAT (Basic Level) Practice1010
- 美易平台与摩根大通财报分析金融科技的崛起
- 满帮面试一面
- 指针大礼包8
- 高通平台开发系列讲解(外设篇)高通平台EMMC适配说明
- Postman —— HTTP请求基础组成部分
- 华为机试:HJ90 合法IP
- 浅入浅出Spring架构设计
- 54 C++ 多线程 条件变量 condition_variable,wait(),notify_one()