C++ UTF-8与GBK字符的转换 —基于Linux 虚拟机 (iconv_open iconv)
发布时间:2024年01月07日
?1、UTF-8 和 GBK 的区别
GBK:通常简称 GB? (“国标”汉语拼音首字母),GBK 包含全部中文字符。
UTF-8 :是一种国际化的编码方式,包含了世界上大部分的语种文字(简体中文字、繁体中文字、英文、日文、韩文等语言),也兼容 ASCII 码。UTF-8 则包含全世界所有国家需要用到的字符。
2、UTF-8 和 GBK 的作用:
这两种编码方式的的作用就是,在不同的应用环境中使用特定的编码方式
如果输入字符编码是UTF-8,如果想要将信息转换为汉字呈现在显示器上,就必须进行GBK转码操作,才能在显示屏上看到信息;
如果输入字符编码是GBK,如果想要在系统操作中让嵌入式设备或者编程环境认知它,就需要进行UTF-8转码操作。
3、UTF-8 和 GBK 之间如何转换:
在字符转换的过程中,二者不可以直接进行转换,必须借助于unicode
3.1、UTF-8转GBK
UTF-8——unicode——GBK
3.2、GBK转UTF-8
GBK——unicode——UTF-8
4、UTF-8 转GBK ——C++代码:
4.1、引入Win32
因为linux是32位的,所以首先需要引入Winsows.h库,附带引入iconv.h库
#include<iostream>
#include<string>
#include<string.h>
#ifdef _WIN32
#include<Windows.h>
#else
#include<iconv.h>
#endif // _WIN32
using namespace std;
#ifndef _WIN324.2、定义函数
static size_t Convert(char* from_cha, char* to_char, char* in, size_t inlen, char* out, size_t outlen)
{
//转换上下文
iconv_t cd;
cd = iconv_open(to_char, from_cha);
if (cd == 0)
{
return -1;
}
memset(out, 0, outlen);
char** pin = ∈
char** pout = &out;
//返回转换字节数的数量,但是转GBK的时候经常不正确 >=0就是成功
size_t re = iconv(cd, pin, &inlen, pout, &outlen);
if (cd != 0)
{
iconv_close(cd);
}
cout << "re=" <<(int) re << endl;
return re;
}4.2.1、iconv库介绍
iconv库——linux的转换字符编码库
????????iconv_open()——作用:从字符编码from_char转换为to_char
iconv_open(to_char, from_cha);????????iconv_close():——?关闭参数所指定的转换描述符?
iconv_close(cd);?memset库——memset是C库函数
memset(out, 0, outlen);- out -- 指向要填充的内存块。
- 0 -- 要被设置的值。该值以 int 形式传递,但是函数在填充内存块时是使用该值的无符号字符形式。
- outlen -- 要被设置为该值的字符数。
4.3、统计转换后的字节数 使用内置函数
现在格式是UTF8,即CP_UTF8.
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);4.4、用wtring存储数据,并为其分配大小
wstring udata; //用wstring存储的
udata.resize(len);//分配大小?4.5、UTF-8转unicode。
将数据写进去,将数据强转为wchar_t类型,适用于windows和linux。
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);?4.6、unicode转GBK。
现在格式转成GBK,即CP_ACP。和UTF-8的参数数量不一样哦
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);?4.7、配置字符大小,转成GBK
utf8.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)utf8.data(), len, 0, 0);4.8、 UTF-8转GBK完整代码
其他都是一样的,只不过加了
#ifdef _WIN32?
......
.....
#else
//linux
re.resize(1024);
int inlen = strlen(data);
cout << "inlen=" << inlen << endl;
Convert((char*)"utf-8", (char*)"gbk", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endif
#endifstring UTF8ToGBK2(const char* data)
{
string re = "";
//1、UTF8 先要转为unicode windows utf16
#ifdef _WIN32
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return re;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 GBK 转成unicode
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return re;
}
re.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)re.data(), len, 0, 0);
#else
re.resize(1024);
int inlen = strlen(data);
cout << "inlen=" << inlen << endl;
Convert((char*)"utf-8", (char*)"gbk", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endif
return re;
}5、GBK ?转 UTF-8 ——C++代码:
5.1、统计转换后的字节数
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);5.2、用wstring存储数据,并为其分配大小?
wstring udata; //用wstring存储的
udata.resize(len);//分配大小5.3、GBK转unicode?
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);?5.4、unicode转UTF-8
//2 unicode 转 utf8
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);?5.5、配置字符大小,转成UTF-8
GBK.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)GBK.data(), len, 0, 0);5.6、GBK 转UTF-8 完整代码
其他都是一样的,只不过加了
#ifdef _WIN32
.....
.....
#else
//linux
re.resize(1024);
int inlen = strlen(data);
Convert((char*)"gbk", (char*)"utf-8", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endifstring GBKToUTF82(const char* data)
{
string re = "";
#ifdef _WIN32
//1、GBK转unicode
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return re;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 utf8 转成unicode
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return re;
}
re.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)re.data(), len, 0, 0);
#else
re.resize(1024);
int inlen = strlen(data);
Convert((char*)"gbk", (char*)"utf-8", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endif
return re;
}6、linux虚拟机测试
6.1、创建文件夹
mkdir test_GBK_UTF-86.2、进入文件夹
cd test_GBK_UTF-8
?6.3、创建test_GBK_UTF-8.cpp文件
vim test_GBK_UTF-8.cpp
将刚才代码放进去,按下esc键盘+输入? :wq (有一个:呦),回车

?
6.4、输入
//g++就是运行环境是C++
g++ test_GBK_UTF-8.cpp -o test_GBK_UTF-8?
6.5、执行
./test_GBK_UTF-8
?6.6、结果
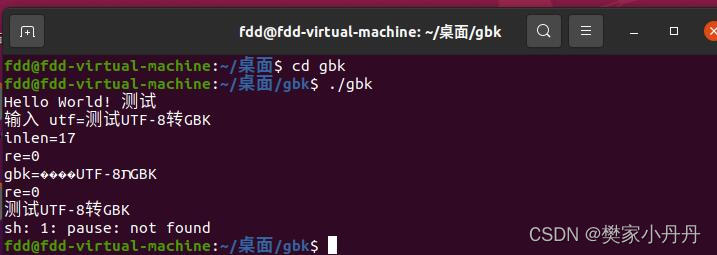
如果不转码,会输出乱码
7、完整代码——基于linux
//GBK转utf-8
#include<iostream>
#include<string>
#include<string.h>
#ifdef _WIN32
#include<Windows.h>
#else
#include<iconv.h>
#endif // _WIN32
using namespace std;
#ifndef _WIN32
static size_t Convert(char* from_cha, char* to_char, char* in, size_t inlen, char* out, size_t outlen)
{
//转换上下文
iconv_t cd;
cd = iconv_open(to_char, from_cha);
if (cd == 0)
{
return -1;
}
memset(out, 0, outlen);
char** pin = ∈
char** pout = &out;
//返回转换字节数的数量,但是转GBK的时候经常不正确 >=0就是成功
size_t re = iconv(cd, pin, &inlen, pout, &outlen);
if (cd != 0)
{
iconv_close(cd);
}
cout << "re=" <<(int) re << endl;
return re;
}
#endif // !_WIN32
string UTF8ToGBK(const char* data)
{
string re = "";
//1、UTF8 先要转为unicode windows utf16
#ifdef _WIN32
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_UTF8, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return re;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_UTF8, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 GBK 转成unicode
len = WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return re;
}
re.resize(len);
WideCharToMultiByte(CP_ACP, 0, (wchar_t*)udata.data(), -1, (char*)re.data(), len, 0, 0);
#else
re.resize(1024);
int inlen = strlen(data);
cout << "inlen=" << inlen << endl;
Convert((char*)"utf-8", (char*)"gbk", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endif
return re;
}
string GBKToUTF8(const char* data)
{
string re = "";
#ifdef _WIN32
//1、GBK转unicode
//1.1 统计转换后的字节数
int len = MultiByteToWideChar(CP_ACP, //转换的格式
0, //默认的转换方式
data, //输入的字节
-1, //输入的字符串大小 -1找\0结束 自己去算
0, //输出(不输出,统计转换后的字节数)
0 //输出的空间大小
);
if (len <= 0)
{
return re;
}
wstring udata; //用wstring存储的
udata.resize(len);//分配大小
//开始写进去
MultiByteToWideChar(CP_ACP, 0, data, -1, (wchar_t*)udata.data(), len);
//2 unicode 转 utf8 转成unicode
len = WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, 0, 0,
0, //失败替代默认字符
0 //是否使用默认替代 0 false
);
if (len <= 0)
{
return re;
}
re.resize(len);
WideCharToMultiByte(CP_UTF8, 0, (wchar_t*)udata.data(), -1, (char*)re.data(), len, 0, 0);
#else
re.resize(1024);
int inlen = strlen(data);
Convert((char*)"gbk", (char*)"utf-8", (char*)data, inlen, (char*)re.data(), re.size());
int outlen = strlen(re.data());
re.resize(outlen);
#endif
return re;
return re;
}
int main()
{
std::cout << "Hello World! 测试\n";
//1、测试utf-8转GBK
//cout << UTF8ToGBK(u8"测试UTF-8转GBK") << endl;
string in = u8"测试UTF-8转GBK";
cout << "输入 utf=" << in << endl;
string gbk = UTF8ToGBK2(in.c_str());
cout << "gbk=" << gbk << endl;
cout << GBKToUTF82(gbk.c_str()) << endl;
system("pause");
return 0;
}
文章来源:https://blog.csdn.net/wjl990316fddwjl/article/details/135417961
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue3 全局配置Axios实例
- 基于深度学习的垃圾检测与分类系统(含UI界面、yolov5、Python代码、数据集)
- 基于Python的在线考试系统-计算机毕业设计源码78268
- SBE(Specification By Example)实例化需求介绍
- Elasticsearch:为现代搜索工作流程和生成式人工智能应用程序铺平道路
- C语言 文件I/O(备查)
- Chatgpt如何共享可以防止封号!
- RCD负载箱的技术支持
- 【漏洞复现】先锋WEB燃气收费系统文件上传漏洞 1day
- C++进阶--AVL树