基于pytorch的层次分类
1、层次分类介绍
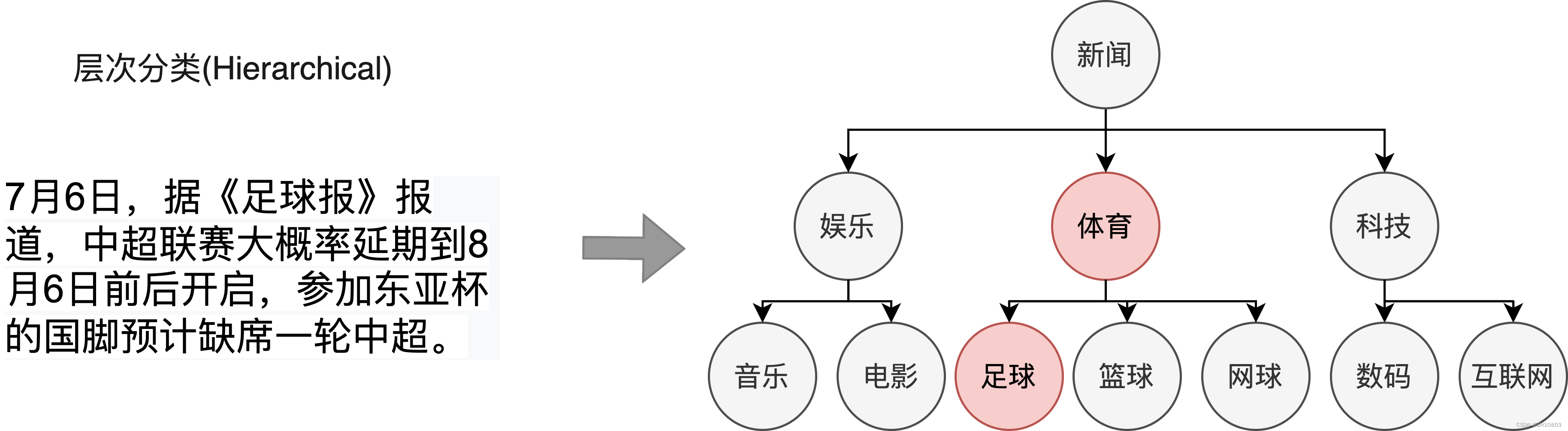
本项目提供通用场景下基于Bert+MLP的层次分类端到端应用方案,打通数据标注-模型训练-模型调优-模型转换-预测部署全流程,有效缩短开发周期,降低AI开发落地门槛。层次文本分类任务的中数据样本具有多个标签且标签之间存在特定的层级结构,目标是预测输入句子/文本可能来自于不同级标签类别中的某一个或几个类别。以下图新闻文本分类为例,该新闻的一级标签为体育,二级标签为足球,体育与足球之间存在层级关系。在现实场景中,大量的数据如新闻分类、专利分类、学术论文分类等标签集合存在层次化结构,需要利用算法为文本自动标注更细粒度和更准确的标签。
2、快速开始
2.1、运行环境
fastapi==0.108.0
numpy==1.24.4
onnxruntime==1.16.3
scikit_learn==1.0.2
torch==1.9.1+cu111
tqdm==4.64.0
transformers==4.30.2
uvicorn==0.25.0
python==3.8
2.2、代码结构
├──_apisever.py
├──_apisever_v1.py ##--API
├──_config.py
├──_data
│___└──_data.txt ##--训练数据
├──_data_load.py ##--数据加载
├──_Dockerfile
├──_gunicorn_conf.py ##--gunicorn高并发设置
├──_index_to_label.json
├──_label_to_index.json
├──_logs
├──_model
│___├──_bert-base-chinese_ ##--#预训练模型
│___└──_dx_model.pth ##--训练后得到的模型
├──_label.py ##--标签转换
├──_model_all.py
├──_model_predict.py ##--模型推理
├──_model_train.py ##--模型训练
├──predict.py
├── model_to_onnx.py ##--模型转换为onnx
├──pytorch_gpu.zip ##--环境
├──dx_pytorch_gpu_uvicorn.tar ##--最终镜像
└──_requirements.txt
2.3、数据准备
训练需要准备指定格式的标注数据集,如果没有已标注的数据集,进行文本分类数据标注。指定格式本地数据集目录结构:
data/
├── data.txt #训练数据
data.txt文件格式:
政治_政治竞选 土耳其大选投票倒计时 两阵营对决今再冲刺。土耳其总统选举倒计时,基里切达罗格卢和埃尔多安都在做最后的竞选活动。据本台驻伊斯坦布尔记者AnneAndlauer报道称,艾尔多安今天在伊斯坦布尔的几个地区举行多场集会。基里切达罗格卢则将在首都安卡拉他的竞选宣传,包括与低收入家庭会面,预计他将在集会上宣传他的经济计划。反对派在第一轮竞选前就将经济作为竞选的核心…
label包含:
外交合作,外交会晤,科技会议,军事演习,政治竞选、海洋安全、经济援助…等军事、政治、经济、安全、外交、科技等6大类领域且每个领域分别包含10类场景。
2.4、模型训练
CUDA_VISIBLE_DEVICES=1,6 python model_train.py --train_path ./data/data.txt --save_model_path ./model/dx_full_model.pth --num_labels 60 --batch_size 8 --num_epochs 50 --learning_rate 2e-5 --max_seq_len 512
可支持配置的参数:
save_model_path :保存训练模型的目录;默认保存在当前目录model文件夹下。
max_seq_length:分词器tokenizer使用的最大序列长度。请根据文本长度选择,通常推荐128、256或512,若出现显存不足,请适当调低这一参数;默认为512。
batch_size :批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为8。
learning_rate :训练最大学习率;默认为2e-5。
num_epochs: 训练轮次,使用早停法时可以选择100;默认为3。
num_labels :层次标签总数
from_pretrained:预训练模型地址。默认bert
model_train.py部分代码如下:
import torch
from torch.utils.data import Dataset, DataLoader, random_split
from transformers import BertTokenizer, AdamW
from transformers import BertModel
from data_load import load_data, CustomDataset
from sklearn.metrics import accuracy_score
from tqdm import tqdm
import torch.nn as nn
from sklearn.preprocessing import LabelEncoder
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# import os
import argparse
parser = argparse.ArgumentParser(description='Model parameter description')
parser.add_argument("--batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--train_path", default=None, type=str, help="The path of train set.")
parser.add_argument("--save_model_path", default=None, type=str, help="Model saving address")
parser.add_argument("--max_seq_len", default=512, type=int, help="The maximum input sequence length. "
"Sequences longer than this will be split automatically.")
parser.add_argument("--num_epochs", default=3, type=int, help="Total number of training epochs to perform.")
parser.add_argument("--learning_rate", default=2e-5, type=float, help="Model learning rate")
parser.add_argument("--num_labels", default=None, type=int, help="Model num labels")
parser.add_argument("--from_pretrained", default='./model/bert-base-chinese', type=str,help="Pretrained model directory")
args = parser.parse_args()
......
def train_model(model, train_dataloader, val_dataloader, optimizer, criterion, num_epochs=5):
"""
这是一个用于训练深度学习模型的函数,主要包括以下几个部分:
"""
train_losses = []
val_losses = []
accuracies = []
early_stopping = EarlyStopping(patience=3)
best_val_loss = float('inf')
model.to(device)
model.train()
for epoch in range(num_epochs):
total_loss = 0
for batch in tqdm(train_dataloader, desc=f'Epoch {epoch + 1}/{num_epochs}'):
input_ids, attention_mask, labels = batch['input_ids'].to(device), batch['attention_mask'].to(device), \
batch['label'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs
loss = criterion(logits, labels)
total_loss += loss.item()
loss.backward()
optimizer.step()
average_loss = total_loss / len(train_dataloader)
print(f'Training Loss: {average_loss}')
# 在验证集上评估
val_loss, val_accuracy = evaluate_model(model, val_dataloader, criterion)
print(f'Validation Loss: {val_loss}, Accuracy: {val_accuracy}')
train_losses.append(average_loss)
val_losses.append(val_loss)
accuracies.append(val_accuracy)
# 早停检查
if early_stopping(val_loss):
print("Early stopping")
break
# 存储最佳模型
if val_loss < best_val_loss:
best_val_loss = val_loss
torch.save(model.state_dict(), args.save_model_path)
return train_losses, val_losses, accuracies
......
2.5、模型转为onnx并推理
model_to_onnx.py部分代码如下:
......
onnx_path= "./model/custom_bert_model.onnx"
# 导出模型为 ONNX 格式
torch.onnx.export(
model,
(dummy_input_ids, dummy_attention_mask),
onnx_path,
input_names=["input_ids", "attention_mask"],
output_names=["output"],
dynamic_axes={
"input_ids": {0: "batch_size"},
"attention_mask": {0: "batch_size"},
"output": {0: "batch_size"}
},
opset_version=11 # Use a supported opset version
)
......
测试结果如下
Model exported to ./model/custom_bert_model.onnx
Predicted Label: 安全_海洋安全
2.6、构建镜像,使用uvicorn做异步加速推理
Dockerfile如下
FROM python:3.8
ADD . /code
WORKDIR /code
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
##uvicorn :速度快于gunicorn+uvicorn
RUN chmod +x apisever.py
ENTRYPOINT ["python3", "apisever.py"]
##gunicorn+uvicorn
#RUN chmod +x apisever_v1.py
#CMD ["gunicorn", "-c", "./gunicorn_conf.py", "apisever_v1:app"]
apisever.py部分代码如下:
from data_load import *
from sklearn.preprocessing import LabelEncoder
from fastapi import FastAPI, Response
from fastapi.encoders import jsonable_encoder
from fastapi.responses import JSONResponse
import torch,json
from transformers import BertTokenizer
from model_predict import predict
from model_train import CustomBERTModel
app = FastAPI()
class hyperparams():
def __init__(self):
self.index_to_label = json.load(open('./index_to_label.json', 'r', encoding='utf-8'))
self.tokenizer = BertTokenizer.from_pretrained('./model/bert-base-chinese')
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.max_len = 512
self.num_labels = 60
@app.post("/dx")
async def get_geo(request_data: dict) -> Response:
return_result = {"code": 200, "message": "success", "data": None}
try:
texts = request_data["text"]
model = CustomBERTModel(num_labels=hyperparams().num_labels).to(hyperparams().device)
model.load_state_dict(torch.load('./model/dx_model.pth'))
predicted_label_index = predict(model, hyperparams().tokenizer, texts, max_len=hyperparams().max_len)
index_to_label=hyperparams().index_to_label
predicted_label =index_to_label[str(predicted_label_index)]
return_result['data'] = predicted_label
except Exception as e:
return_result["code"] = 400
return_result["message"] = str(e)
.......
2.7、服务部署
docker部署服务后测试结果如下:
输入:{"text":"印度警告:xx企图在新德里破坏火炬接力。环球时报·环球网消息印度首都新德里17日将举行北京奥运火炬接力活动,有情报显示,“xx”分子已经准备进行破坏。 据《印度斯坦时报》15日报道,来自印度xx部门的确切消息说,目前德里有来自xx自治区的5名中国公民,对火炬接力活动造成了威胁。报道说,这5人是中国维吾尔族人,日前从尼泊尔进入印度,涉嫌与“xx运动”有关。 这份情报还提供了这5人的姓名、照片,在德里的住所以及他们一个朋友的手机号码。 情报表示,考虑到火炬接力迫在眉睫,有必要采取行动逮捕这5人,并检查他们旅行证件的有效性,并调查其行为。"}
输出:{
"code": 200,
"message": "success",
"data": "安全_国土安全"
}
2.8、不足
现阶段数据量较少,拿全量数据进行训练,没有做数据拆分,模型准确率不高,只有78%左右。后续会继续优化算法,加一些注意力机制。推理方面:只尝试了onnx+gunicorn+uvicorn和onnx+uvicorn多路并发的方法。后续会继续尝试做tensorRT加速推理,Nginx+gunicorn+flask加速推理,对比推理速度。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Ansible hanlder是啥?Ansible Block是啥?
- Cortex-M3/M4内核NVIC及HAL库函数详解(3):HAL库中断应用层函数实现
- opencv中叠加Sobel算子与Laplacian算子实现边缘检测
- 按摩上门预约小程序源码系统 开发组合:PHP+MySQL 附带完整的搭建教程
- 【Unity】GPU骨骼动画 渲染性能开挂 动画合批渲染 支持武器挂载
- 51-16 FusionAD 用于自动驾驶预测与规划任务的多模态融合论文精读
- GC6153步进电机驱动芯片——低噪声、低振动,应用于摄像机,机器人等产品上
- Spring5系列学习文章分享---第二篇(IOC的bean管理factory+Bean作用域与生命周期+自动装配+基于注解管理+外部属性管理之druid)
- 品牌企业怎么去落地新闻营销?
- ARM 内核架构分类?