87 GB 模型种子,GPT-4 缩小版,超越ChatGPT3.5,多平台在线体验
瞬间爆火的Mixtral 8x7B
大家好,我是老章
最近风头最盛的大模型当属Mistral AI 发布的Mixtral 8x7B了,火爆程度压过Google的Gemini。

缘起是MistralAI二话不说,直接在其推特账号上甩出了一个87GB的种子
随后Mixtral公布了模型的一些细节:
- 具有编程能力
- 相比 Llama 2 70B,运算速度快 6 倍
- 可处理 32k 令牌的上下文
- 可通过 API 接口使用
- 可自行部署(它使用 Apache 2.0 开源协议
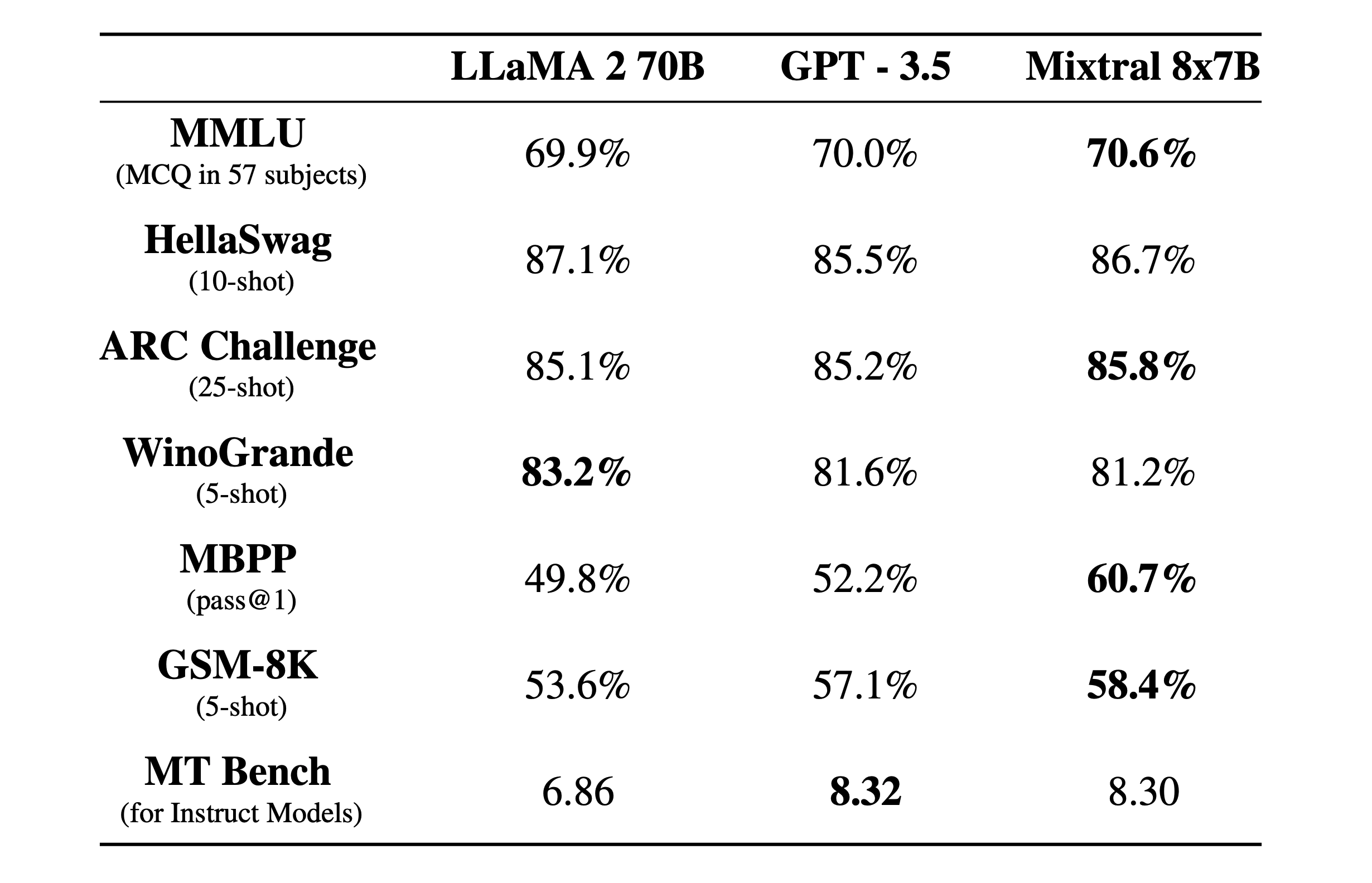
- 在大多数标准基准测试中匹配或优于 GPT3.5
- 可以微调为遵循指令的模型,在 MT-Bench 测试中获得 8.3 分
Mixtral 8x7B 技术细节
Mixtral 8x7B 是基于Mixture of Experts (专家混合,8x7B即 8 名专家,每个专家7B个参数 )的开源模型,
专家混合 (MoE) 是LLM中使用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或“专家”处理。
1、专家层:这些是较小的神经网络,经过训练,在特定领域具有高技能。每个专家处理相同的输入,但处理方式与其独特的专业相一致。
2、门控网络:这是MoE架构的决策者。它评估哪位专家最适合给定的输入数据。网络计算输入与每个专家之间的兼容性分数,然后使用这些分数来确定每个专家在任务中的参与程度。
Mixtral 是一个稀疏专家混合网络,仅包含解码器。其前馈网络从 8 组不同的参数中挑选,在每一层,对每个词元,路由网络会选择两组“专家”参数来处理该词元,并将其输出叠加。
这种技术在控制计算成本和延迟的同时扩大了模型规模,因为每个词元只使用参数总量的一小部分。具体来说,Mixtral 总参数量有 46.7 亿,但每个词元只使用 12.9 亿参数。因此,它的输入处理和输出生成速度与成本与 12.9 亿参数模型相当。
Mistral 8x7B 使用与 GPT-4 非常相似的架构,但缩小了:
- 总共 8 名专家,而不是 16 名(减少 2 倍)
- 每个专家 7B 个参数,而不是 166B(减少 24 倍)
- 42B 总参数(估计)而不是 1.8T(减少 42 倍)
- 与原始 GPT-4 相同的 32K 上下文
线上体验 Mixtral 8x7B
如果大家硬件资源真的很硬,可以下载这个87GB的模型种子本地运行

下载:https://twitter.com/MistralAI/status/1733150512395038967
玩法:https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2
我相信99%的同学应该没有这个实力,现在市面上已经有很多可以在线试玩的平台了。
1、replicate
https://replicate.com/nateraw/mixtral-8x7b-32kseqlen
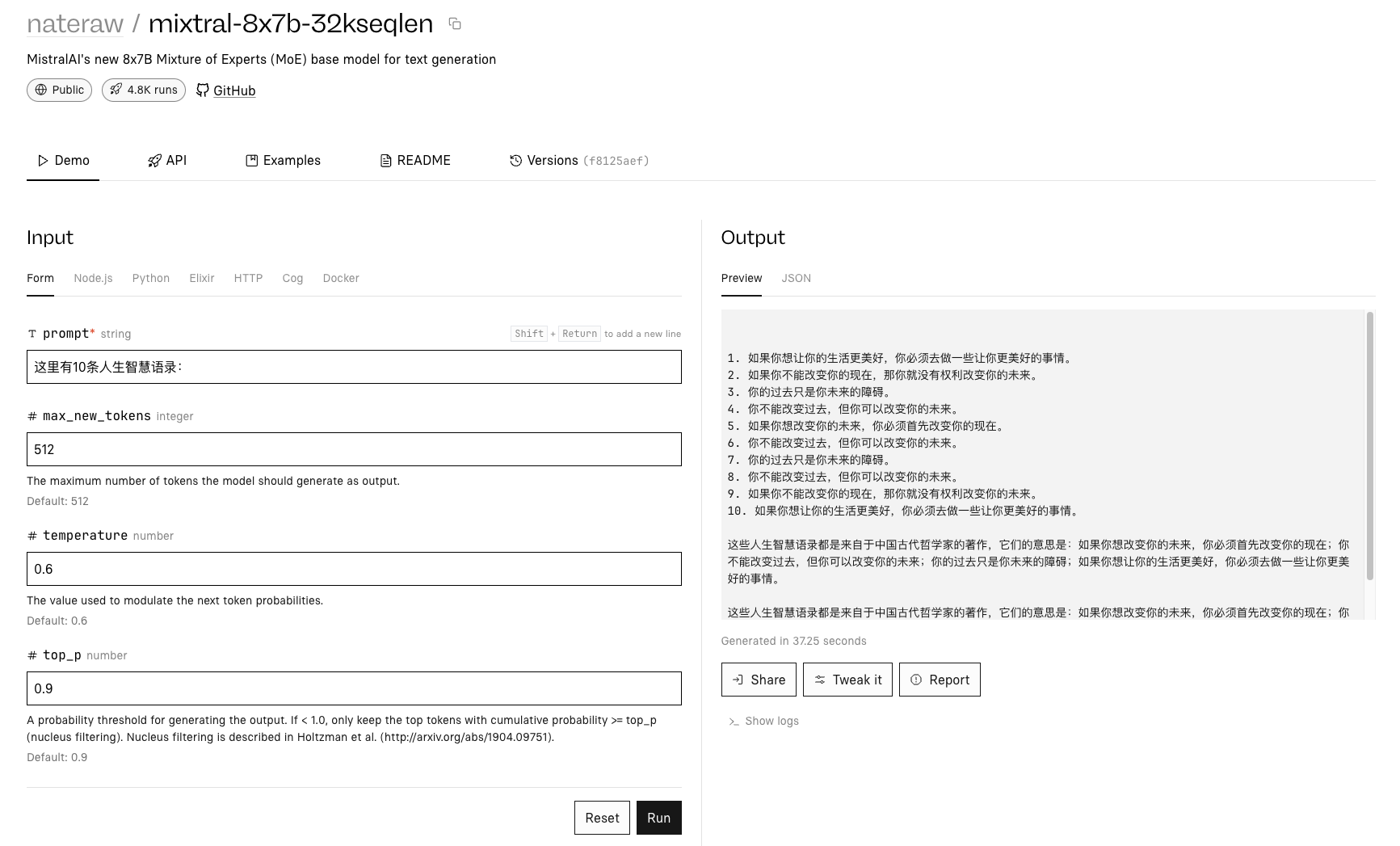
replicate还服了api调用的方法:
pip install replicate
export REPLICATE_API_TOKEN=<paste-your-token-here>
#API token https://replicate.com/account/api-tokens
import replicate
output = replicate.run(
"nateraw/mixtral-8x7b-32kseqlen:f8125aef9cd96d879f4e5c5c1ff78618818e62939ab76ab1e07425ac75d453bc",
input={"prompt": "你好",
"top_p": 0.9,
"temperature": 0.6,
"max_new_tokens": 512
}
)
print(output)
2、POE
https://poe.com/chat/2t377k6re3os2ha7z1e

3、fireworks.ai
https://app.fireworks.ai/models/fireworks/mixtral-8x7b-fw-chat

4、perplexity_ai
https://labs.perplexity.ai/


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!