Linux:进程概念

文章目录
前言
本文是对于进程概念的知识总结。
一、基本概念
- 课本概念:程序的一个执行实例,正在执行的程序等
- 内核观点:担当分配系统资源(CPU时间,内存)的实体。
以上就是进程的基本概念,那进程就是可执行程序吗?答案为不是。为什么?那我们来进行如下的推导。
操作系统内可能会同时存在非常多的“进程”,那操作系统要不要管理所有的“进程”?要管理。那操作系统如何管理?先描述,再组织(对事物重要的属性描述成一个集合,再对该集合选用合适的数据结构,对该数据结构进行增删查改)。那要描述的对象肯定是“进程”,而操作系统是用C语言写的,也就是对“进程”的描述会形成struct XXX类型(该类型内部包含“进程的各种属性”),再以双向链表的这种数据结构对struct XXX类型对象进行管理,这就形成了进程的PCB(process control block)。
那么现在什么是进程?进程 = 可执行程序 + 内核级别的数据结构(PCB)。其中PCB方便OS对进程的管理(对进程的管理变为对双向链表的增删查改)。
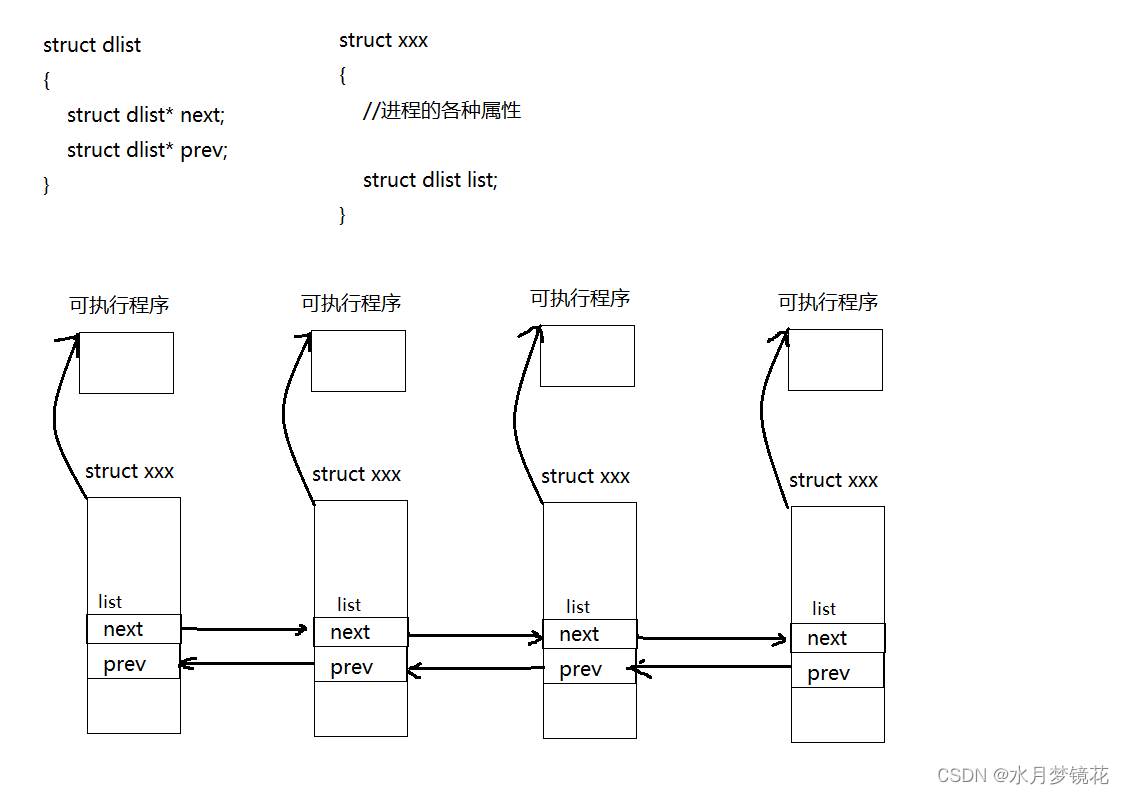
在上图,struct XXX对象中的lis成员,可以通过类似C语言 offset 宏[类似于 (int)&list - (int)(struct XXX*)0->list ]来指向struct XXX的首地址。
二、描述进程-PCB
- 进程信息被放在一个叫进程控制块的数据结构中,可以理解为进程属性的集合
- 课本上称之为PCB(process cintrol block),Linux操作系统下的PCB具体为task_struct
task_struct 为 PCB 的一种
- 在Linux中描述进程的结构体叫做task_struct。
- task_struct 是Linux内核的一种数据结构,它会被装载到RAM里并且包含进程的信息
task_struct内容分类
- 标识符(PID):描述本进程的唯一标识符,用来区分其它进程
- 状态:任务状态,退出代码,退出信息等
- 优先级:相对于其它进程的优先级
- 程序计数器:程序中即将被执行的下一条指令的地址
- 内存指针:包括程序代码和进程相关数据的指针,还有和其它进程共享的内存块的指针
- 上下文数据:进程执行时处理器的寄存器中的数据
- I / O 状态信息:包含显示的I / O请求,分配给进程的 I / O设备和被进程使用的文件列表
- 记账信息:可能包括处理器时间总和,使用的时间钟总和,时间限制,记账好等
- 其它信息
三、组织进程
可以在内核数据结构里找到PCB,所有运行在系统里的进程都以task_struct链表的形式存在内核里
一个大佬写的文章Linux中进程控制块PCB-------task_struct结构体结构
四、查看进程
-
进程信息可以通过/proc系统文件夹查看,该目录为动态目录结构,存放所有存在的进程,目录的名称就是这个进程的id。
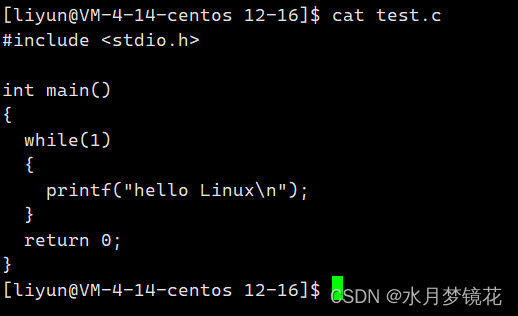
如我们启动如下程序,在/proc目录中查看该进程的信息
通过ps -axj | head -1 && ps -axj | grep mybin查看到该进程的pid为30725

再通过ll /proc/30725查看进程信息
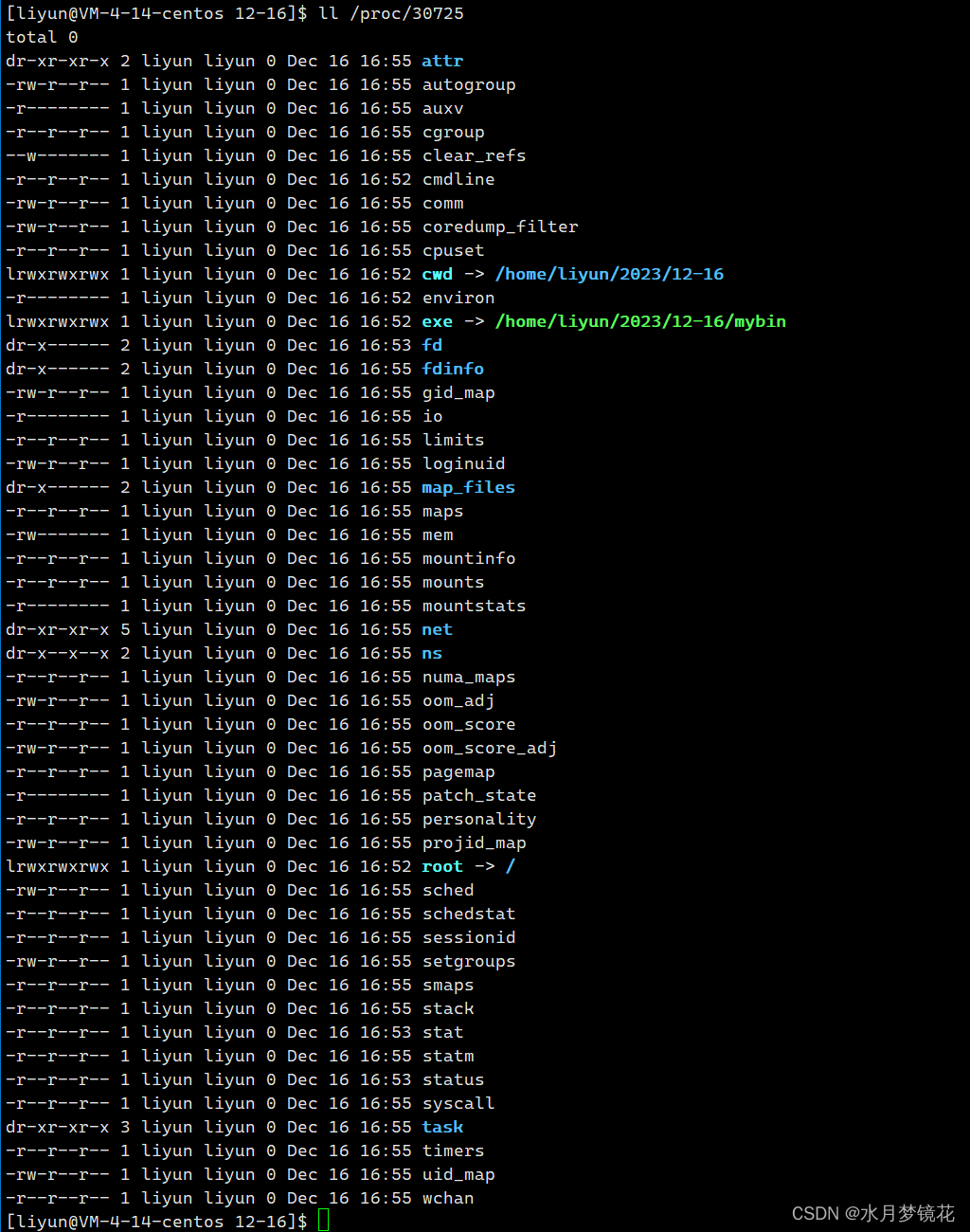
其中cwd就是当前工作目录(默认情况下,进程启动所处的路径),可以通过chdir()系统调用来改变 -
大多数进程信息同样可以使用top和ps这些用户级工具来获取。
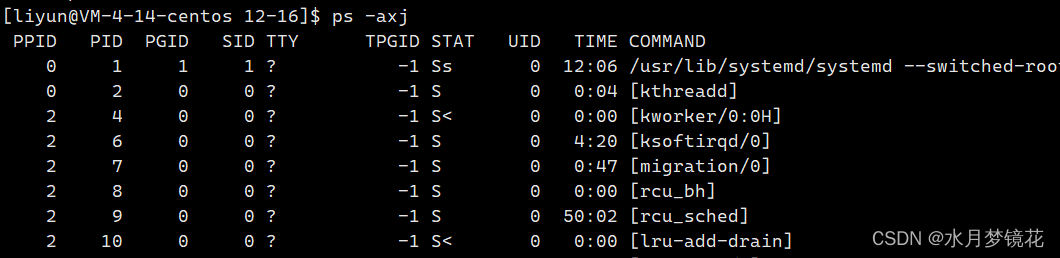
一般ps -axj 配合 grep指令使用。如ps -axj | grep 程序名

五、通过系统调用获取进程标识符
我们可以通过getpid,getppid来获取进程的pid(进程id),ppid(父进程id)。
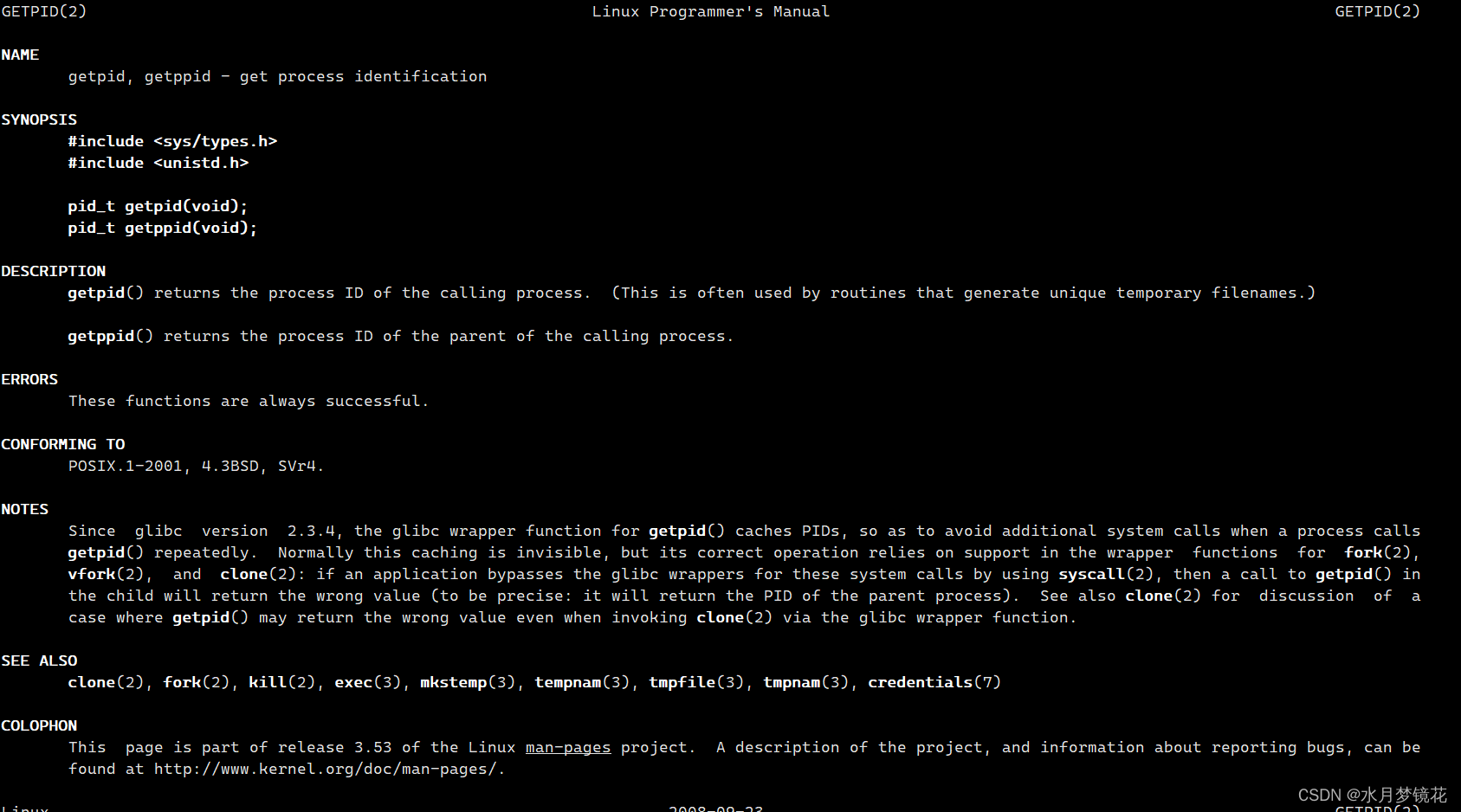
我们运行下面代码:
其结果为:
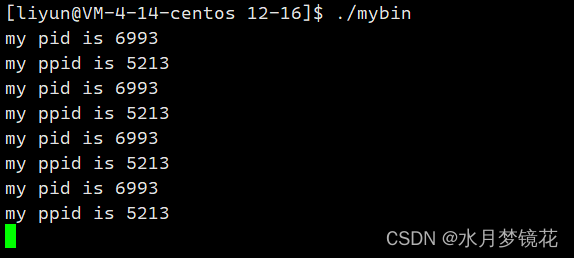

我们可以知道该进程的pid为6993,ppid为5213。
这里有个小问题,如果我们多次运行该程序(不关闭shell),我们会发现其ppid的值是不变的,那ppid是谁的pid呢?
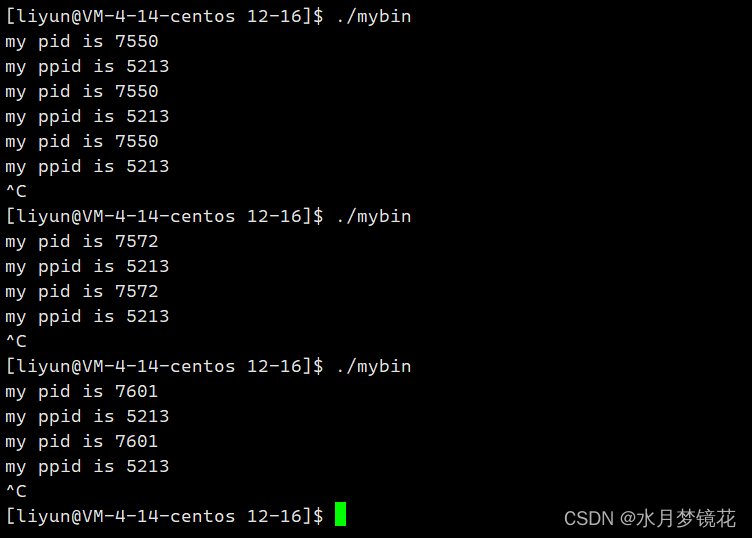
运行该指令ps -axj | head -1 && ps -axj | grep 5213

我们可以明显的发型bash的pid为5213。所以在命令行中执行的进程,父进程一般是命令行解释器
六、通过系统调用创建进程 fork初始
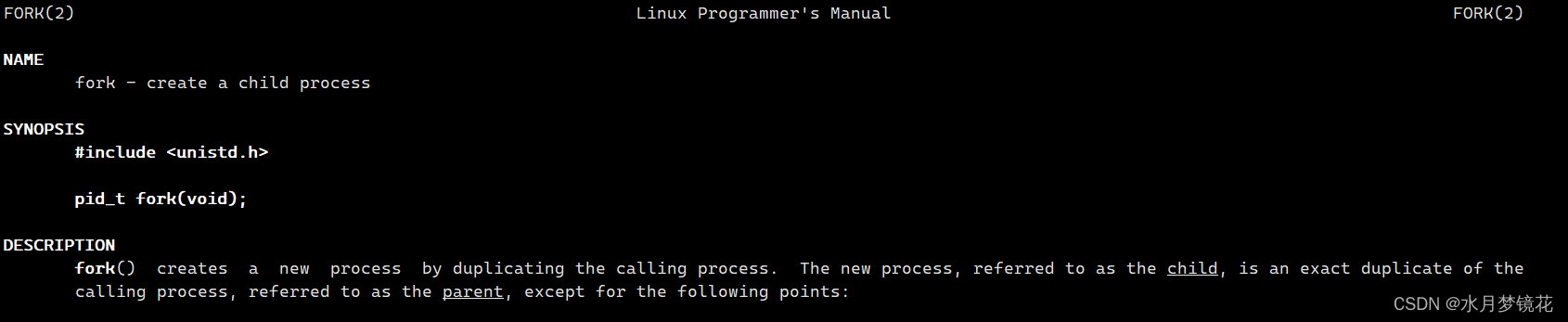

由上图,我们可以通过fork来创建新的进程,对于父进程,其返回子进程的pid;对于子进程,其返回0;如果创建进程失败,其返回-1。
我们运用如下代码:
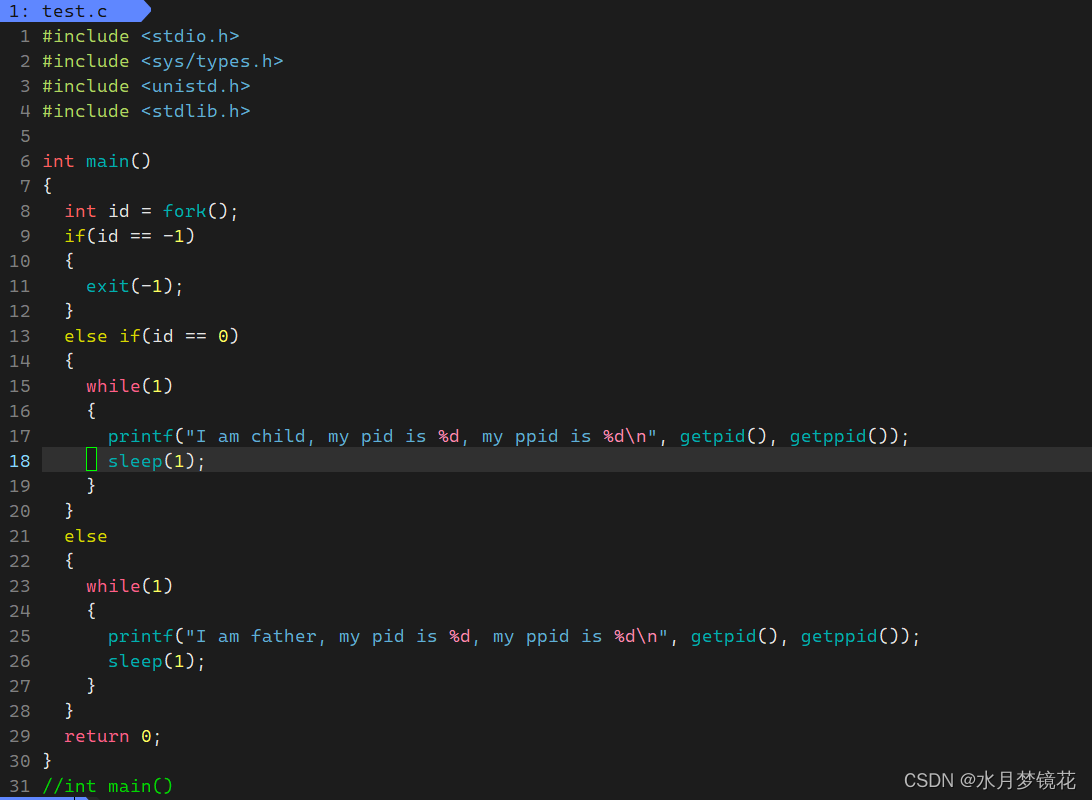
其结果为:

从运行结果而言,我们可以通过fork创建一个新的进程,父子进程都执行fork之后的代码;if的两个分支也都被执行,这表示一个函数有两个返回值?
fork干了什么?
fork创建子进程,系统中会多出一个子进程。
1.以父进程为模版,为子进程创建PCB
2.创建的子进程是没有代码和数据的,目前和父进程共享代码和数据。
因为父子进程共享代码,所以fork之后,父子进程会执行一样的代码,fork之前的代码,父子进程也都能看到。
那父子进程之间是如何保证进程的独立性?
代码本身是只读的,父子进程都不会影响,所以代码是可以共享的。但父子进程对数据是会修改的,当父子进程对数据进行写入,会发生写时拷贝,来保证进程的数据是独立的。
为什么fork会有两个返回值?
我们先想一个问题,如果一个函数已经执行到return语句了,那么该函数的核心工作做完了吗?
答案是:做完了。那不也就说明fork函数在执行到return语句时,子进程已经创建出来了,而fork函数之后(子进程创建出来后),代码共享,那return语句不也共享了吗。那不就是父进程被调度,就要执行return,子进程被调度,就有执行return。

真实情况是,操作系统是通过一些寄存器做到返回值返回两次。
为什么fork里的两个返回值,会给父进程返回子进程pid,给子进程返回0?
在我们人类血缘关系中,父与子的比例永远是1 : n,也就是说一位孩子只能有一个父亲,一位父亲可以有多个孩子。换而言之,对于父进程,我们需要唯一标识子进程的标识符(pid)来区分子进程,对于子进程,我们只有一个父进程,不需要特殊表示,我们只需要表示子进程创建成功即可。
fork之后,父子进程谁先运行?
创建完成子进程后,系统的其它进程,父进程,子进程接下来要被调度执行。当父子进程的PCB都被创建并在运行队列中排队的时候,那个进程的PCB先被选择调度,哪个进程就先运行。但这是由操作系统决定的,由各自PCB中的调度信息(时间片,优先级等) + 调度算法共同决定。我们无法确定
总结
以上就是我对于进程概念知识的总结。感谢支持!!!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Net Core Ocelot+Consul实现网关、服务注册、服务发现
- 最新多模态大模型SOTA - EMU (Generative Multimodal Models are In-Context Learners)
- 数据结构学习 jz45 把数组排成最小的数
- 反序列化漏洞原理、成因、危害、攻击、防护、修复方法
- Laravel 10.x 里如何使用ffmpeg
- c++24.1.19逻辑运算符—非
- 客服语音呼叫中心的优势有哪些?
- GitHub项目推荐: free-programming-books
- 全网最全Stable Diffusion原理快速上手,模型结构、关键组件、训练预测方式!!!!
- 【密码学基础】Diffie-Hellman密钥交换协议