Linux:ELF 可执行文件的解析与其加载的原理
ELF 可执行文件
我们已经看到链接器如何将多个目标文件合并成一个可执行目标文件。我们的 C程序,开始时是一组 ASCII 文本文件,现在已经被转化为一个二进制文件,且这个二进制文件包含加载程序到内存并运行它所需的所有信息。
图 7-13 概括了一个典型的 ELF 可执行文件中的各类信息。
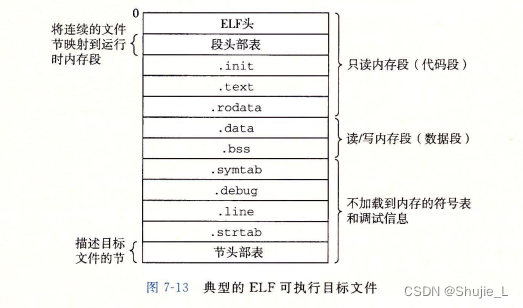
可执行目标文件的格式类似于可重定位目标文件的格式。
ELF 头描述文件的总体格式。它还包括程序的入口点(entry point),也就是当程序运行时要执行的第一条指令的地址。
.text、.rodata和.data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。.init 节定义了一个小函数,叫做 init,程序的初始化代码会调用它。因为可执行文件是完全链接的(已被重定位),所以它不再需要rel节。
需要的前置知识
看到这里,脑海里面没有相关概念的朋友可以先看看相关的前置篇:
ELF 可执行文件的程序头部表
ELF 可执行文件被设计得很容易加载到内存,可执行文件的连续的片(chunk)被映射到连续的内存段。程序头部表(program header table)描述了这种映射关系。图 7-14 展示了可执行文件 prog 的程序头部表,是由 OBJDUMP 显示的。

加载可执行目标文件
要运行可执行目标文件 prog,我们可以在 Linux shell 的命令行中输入它的名字:
linux> ./prog
因为 prog 不是一个内置的 shell 命令,所以 shell 会认为 prog 是一个可执行目标文件,通过调用某个驻留在存储器中称为加载器(lader)的操作系统代码来运行它。任何Linux程序都可以通过调用execve 函数来调用加载器。
加载器将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序。这个将程序复制到内存并运行的过程叫做加载。每个 Linux程序都有一个运行时内存映像,类似于图7-15 中所示。
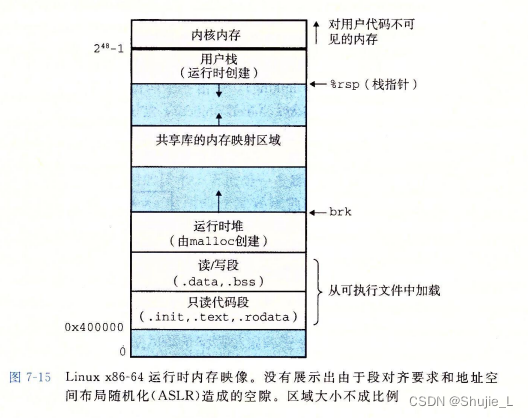
在 Linux x86-64系统中,代码段总是从地址 0x400000 处开始,后面是数据段。运行时堆在数据段之后通过调用 malloc 库往上增长。
堆后面的区域是为共享模块保留的。
用户栈总是从最大的合法用户地址(2的48次方-1)开始,向较小内存地址增长。栈上的区域,从地址 2的48次方开始,是为内核(kernel)中的代码和数据保留的,所谓内核就是操作系统驻留在内存的部分。
为了简洁,我们把堆、数据和代码段画得彼此相邻,并且把栈顶放在了最大的合法用户地址处。实际上,由于.data 段有对齐要求,所以代码段和数据段之间是有间隙的。
同时,在分配栈、共享库和堆段运行时地址的时候,链接器还会使用地址空间布局随机化(ASLR)。虽然每次程序运行时这些区域的地址都会改变,它们的相对位置是不变的。
当加载器运行时,它创建类似于图 7-15 所示的内存映像。在程序头部表的引导下加载器将可执行文件的片(chunk)复制到代码段和数据段。接下来,加载器跳转到程序的入口点,也就是 _start 函数的地址。这个函数是在系统目标文件 ctrl.o 中定义的,对所有的C程序都是一样的。_start 函数调用系统启动函数 __libc_start_main,该函数定义在 iibc.so中。它初始化执行环境,调用用户层的 main 函数,处理main 函数的返回值,并且在需要的时候把控制返回给内核。
QA
加载器如何工作?
下面是关于加载实际是如何工作的一个概述:
Linux 系统中的每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当 shell 运行一个程序时,父 shell 进程生成一个子进程,它是父进程的一个复制。子进程通过 execve 系统调用启动加载器。
加载器删除子进程现有的虚拟内存段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。
通过将虚拟地址空间中的页映射到可执行文件的页大小的片(chunk),新的代码和数据段被初始化为可执行文件的内容。
最后,加载器跳转到 start地址,它最终会调用应用程序的 main 函数。除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到 CPU 引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存。
参考
深入理解计算机系统(原书第三版)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Export Metadata to JSON Format Crack
- 【无标题】
- git 使用场景 提 PR 再 Revert PR后,源分支rebase目标分支后代码丢了
- 教师教育研究的意义有哪些
- 如何配置TLSv1.2版本的ssl
- 【MySQL】外连接 where 和 on 的区别
- 业务开发过程中的思考和实践系列一:自描述软件 DSL
- 多线程select并发
- 使用el-upload上传视频和文档,并且展示,真实项目中案例
- react之unpkg.com前端资源加载慢、加载不出