Hadoop3.3.5云服务器安装教程-单机/伪分布式配置
系列文章目录
华为云服务器试用领取
领取的试用云服务器在哪
Hadoop3.3.5云服务器安装教程-单机/伪分布式配置
文章目录
本篇文章是基于上一篇所配置好的云服务器进行实验软件安装,该系列文章是根据林子雨所讲述的课程就在云服务器上进行学习安装过程。
创建hadoop用户
在我们连接成功后打开是下图这样的,连接上即为root账户,在该服务器还是ctrl+v粘贴,ctrl+c复制。
切换至根目录
cd /

创建一个hadoop用户。
sudo useradd -m hadoop -s /bin/bash
我的hadoop用户已经创建完,会显示已经存在,如果是第一次创建不会出现任何提示。
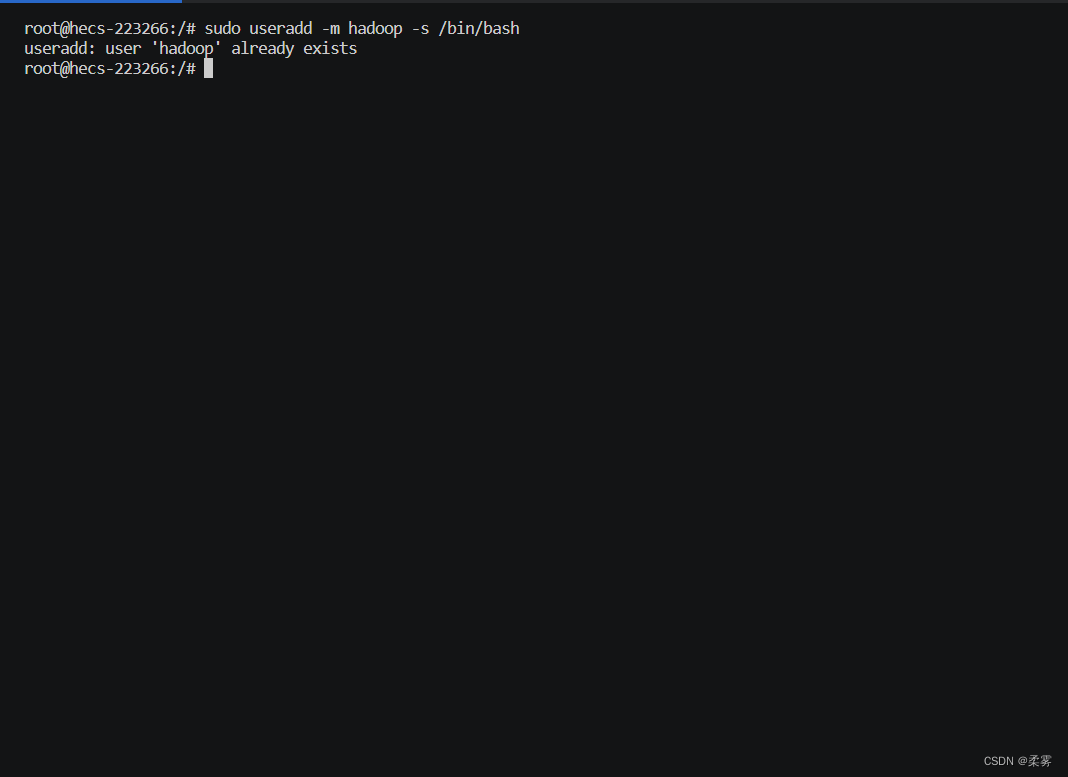
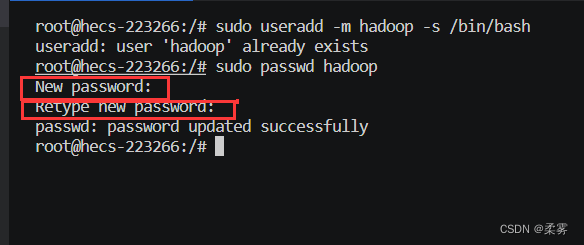
为hadoop用户设置密码。
sudo passwd hadoop
需输入两次相同密码,在Linux的终端中输入密码,终端是不会显示任何你当前输入的密码,也不会提示你已经输入了多少字符密码。而在windows系统中,输入密码一般都会以“*”表示你输入的密码字符。设置成功会出现提示信息。
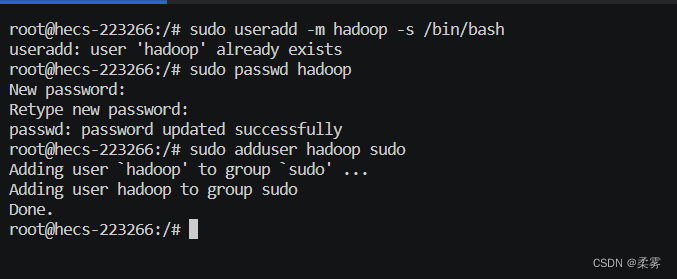
可为 hadoop 用户增加管理员权限,方便部署:
sudo adduser hadoop sudo
切换为hadoop用户
su hadoop
在/home文件夹下会有hadoop用户文件。
cd /home
ll
更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件。
sudo apt-get update
输入后会让你输入hadoop用户的密码(刚才所设置的密码不是root账户的密码)。
安装vim
vim的常用模式有分为命令模式,插入模式,可视模式,正常模式。本教程中,只需要用到正常模式和插入模式。二者间的切换即可以帮助你完成本指南的学习。
正常模式:
正常模式主要用来浏览文本内容。一开始打开vim都是正常模式。在任何模式下按下Esc键就可以返回正常模式。
插入编辑模式:
插入编辑模式则用来向文本中添加内容的。在正常模式下,输入i键即可进入插入编辑模式。
退出vim:
如果有利用vim修改任何的文本,一定要记得保存。Esc键退回到正常模式中,然后输入:wq即可保存文本并退出vim,输入:q!是强制退出。
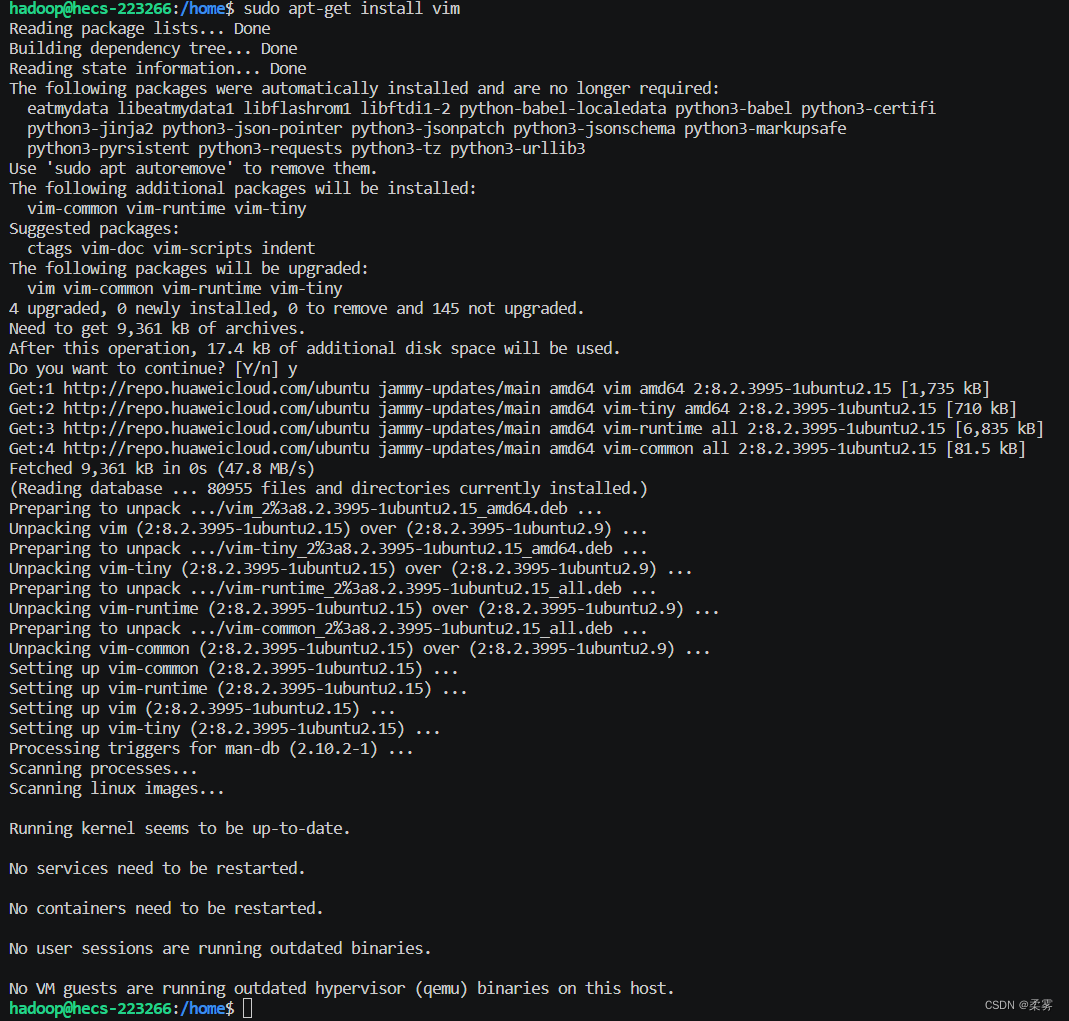
sudo apt-get install vim
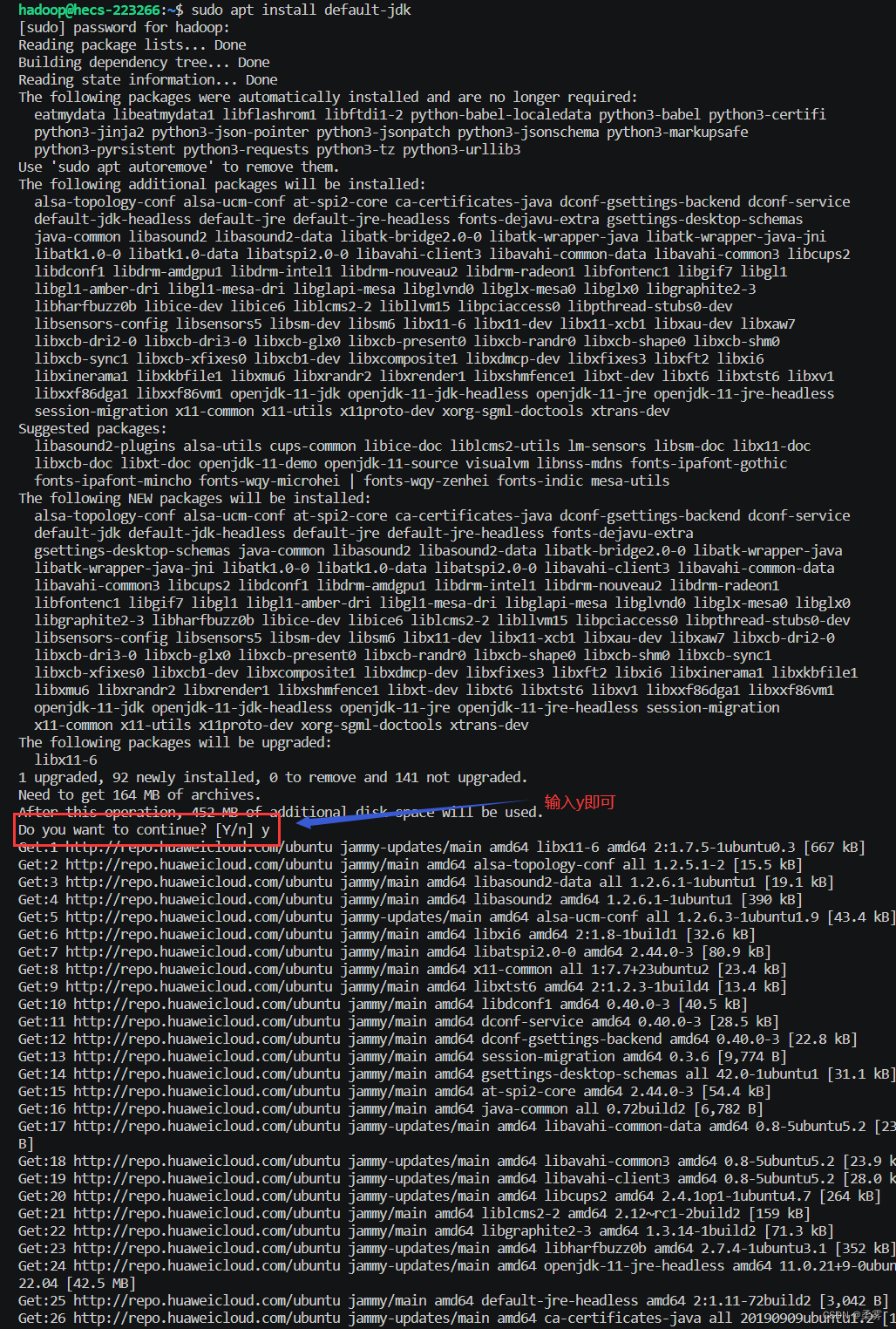
在安装过程中会弹出下面的提示输入y即可。
安装SSH、配置SSH无密码登陆
集群、单节点模式都需要用到 SSH 登陆。
安装 SSH server
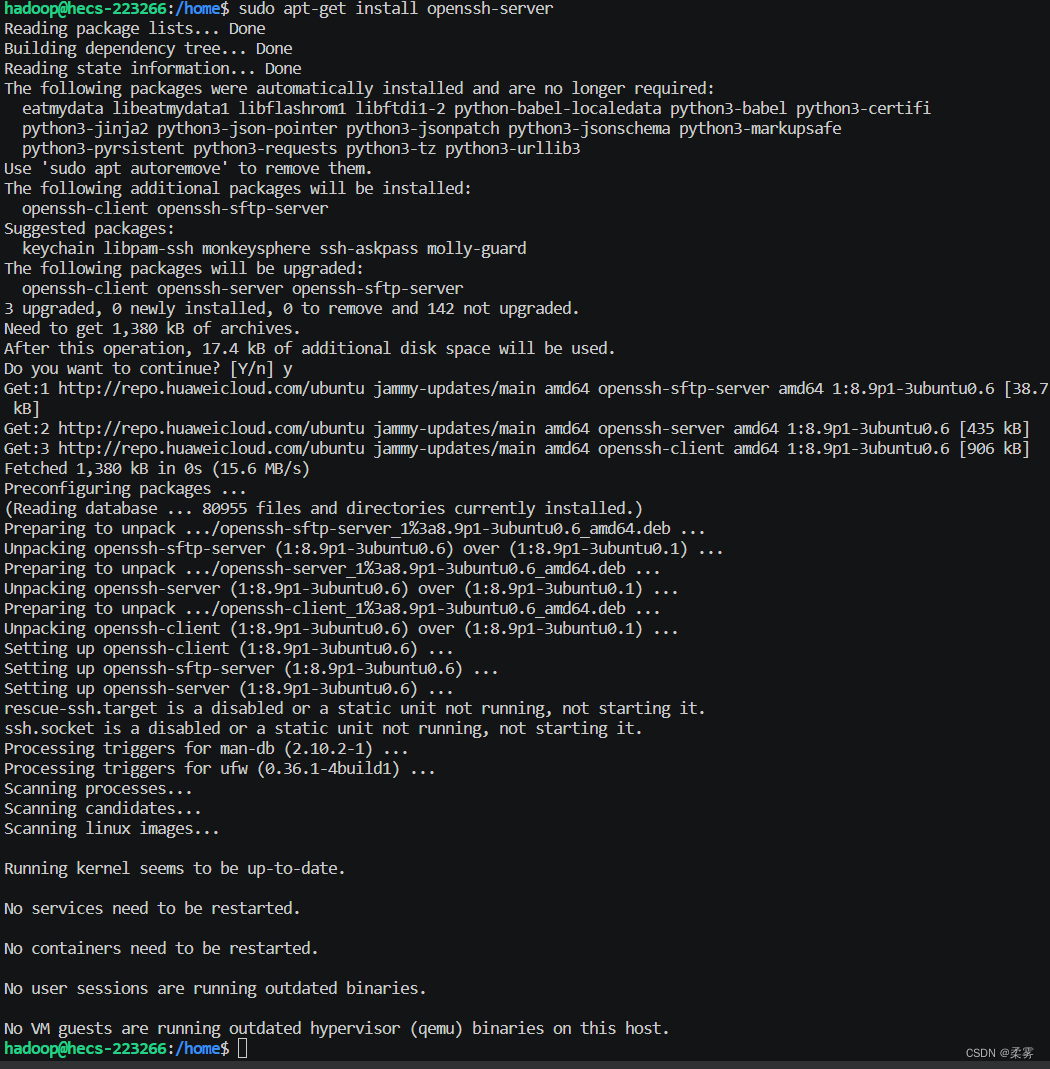
sudo apt-get install openssh-server
这个和上面一样输入y即可
安装后,可以使用如下命令登陆本机:
ssh localhost
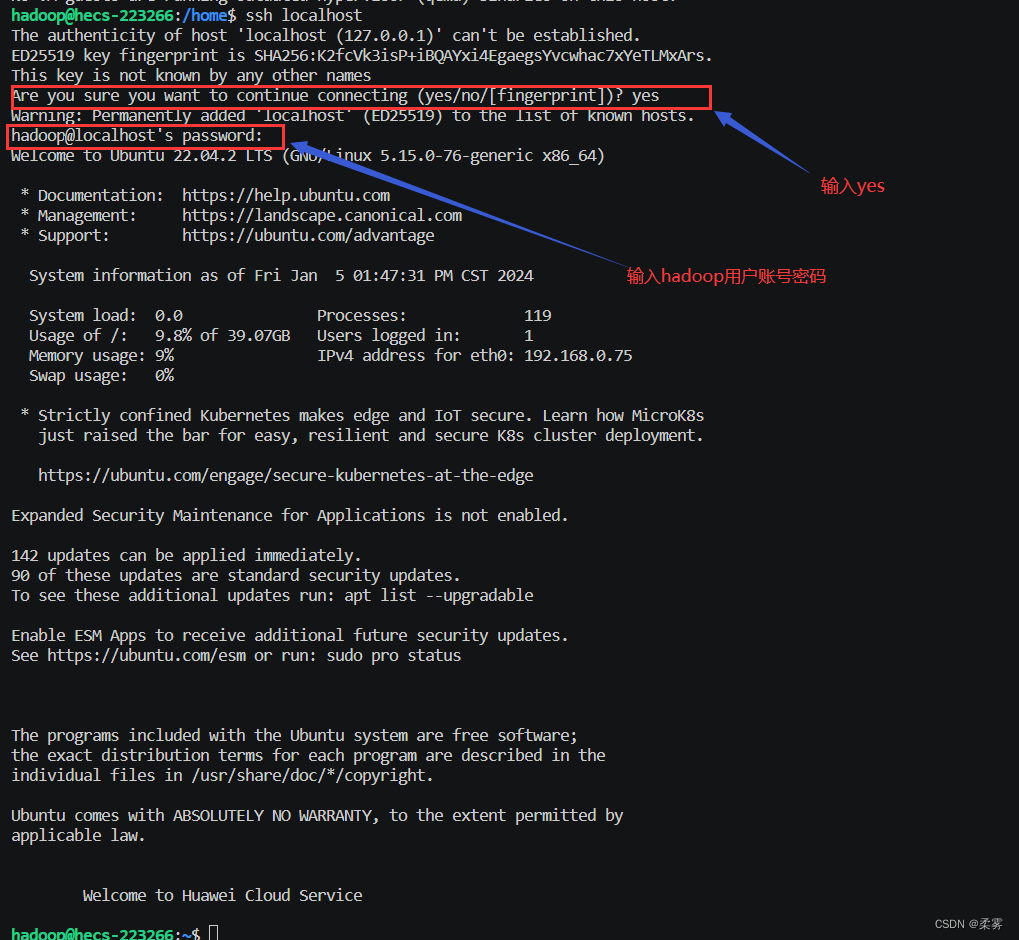
但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
exit # 退出刚才的 ssh localhost
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
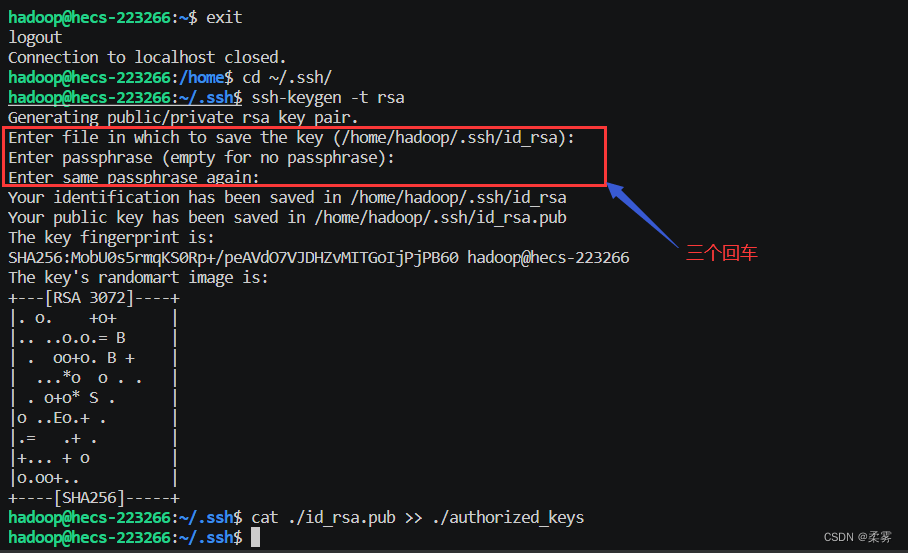
~的含义: 在 Linux 系统中,~ 代表的是用户的主文件夹,即 “/home/用户名” 这个目录,如你的用户名为 hadoop,则 ~ 就代表 “/home/hadoop/”。 此外,命令中的 # 后面的文字是注释,只需要输入前面命令即可。
在输入ssh localhost 即可直接登录。
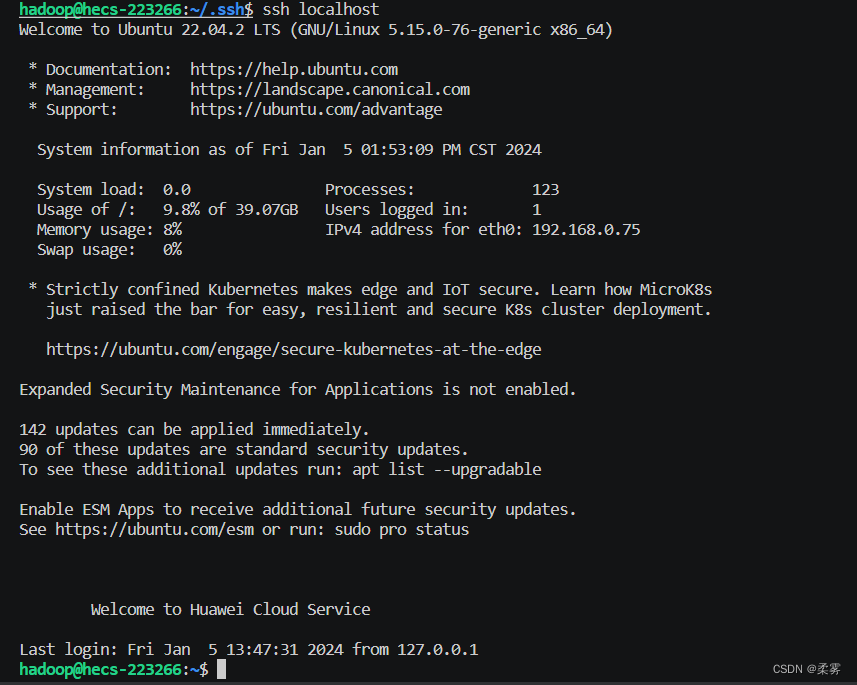
安装Java环境
还未安装Java-1.8
java -version
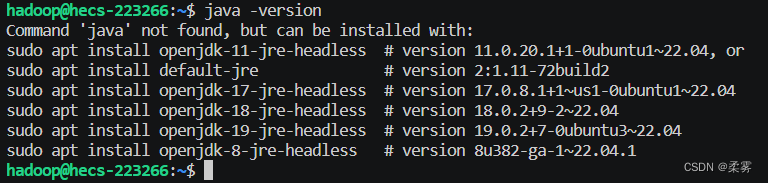
sudo apt install openjdk-8-jdk
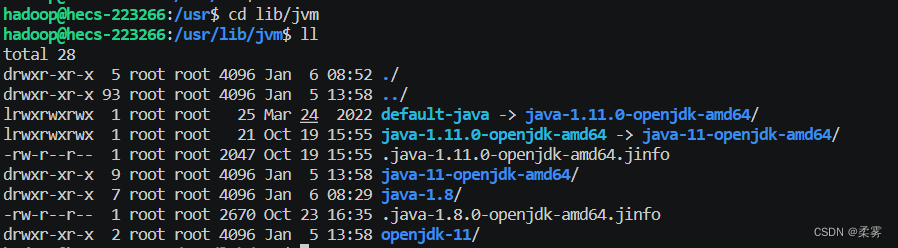
下载完进行改名,方便后续操作。
cd /usr/lib/jvm
ll
sudo mv ./java-8-openjdk-amd64/ ./java-1.8
ll
检查Java版本信息,下载完但是环境变量没配置。
java -version

查看Java的安装路径在哪(大部分下载完都在/usr/lib/jvm中)
java -verbose
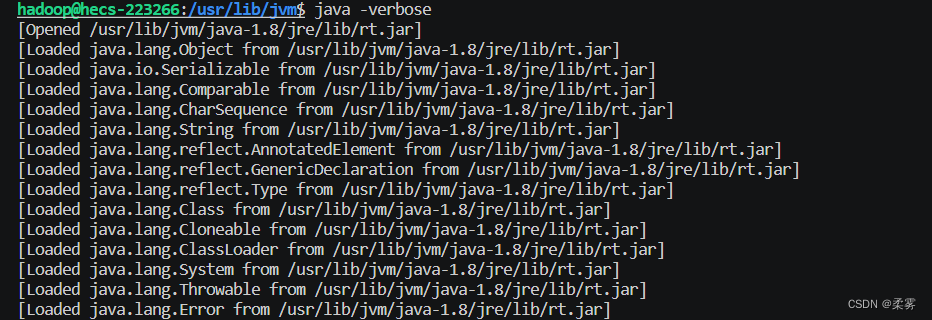
配置Java环境变量。
cd ~
vim ~/.bashrc
在文本开头添加如下代码(按i进入编辑模式,:wq保存并退出)。
export JAVA_HOME=/usr/lib/jvm/java-1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
如果在配置完环境后发现linux命令出现报错如下图:

就是你在配置环境变量时添加了一些其他文字和符号。
解决办法:
export PATH=/usr/bin:/usr/sbin:/bin:/sbin:/usr/X11R6/bin
vi /etc/profile
source /etc/profile

执行下面命令让.bashrc文件的配置立即生效。
source ~/.bashrc
查看Java是否安装成功。
java -version

安装 Hadoop3.3.5
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.5/hadoop-3.3.5-aarch64.tar.gz
需要等待一会,下载完就会显示,下载到当前目录下。
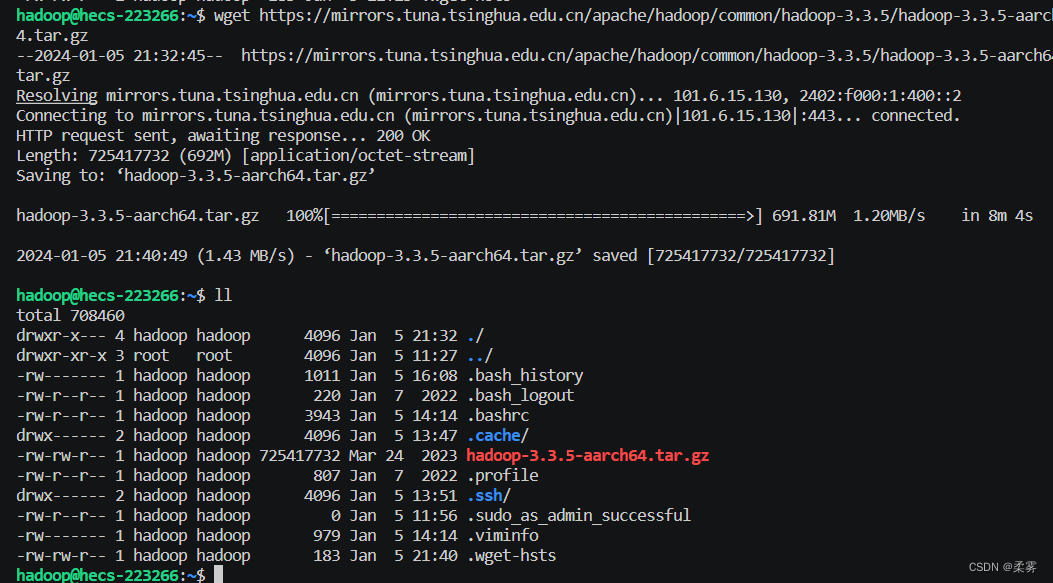
将hadoop-3.3.5解压到/usr/local下。
sudo tar -zxvf ./hadoop-3.3.5-aarch64.tar.gz -C /usr/local
会显示要你输入hadoop用户密码
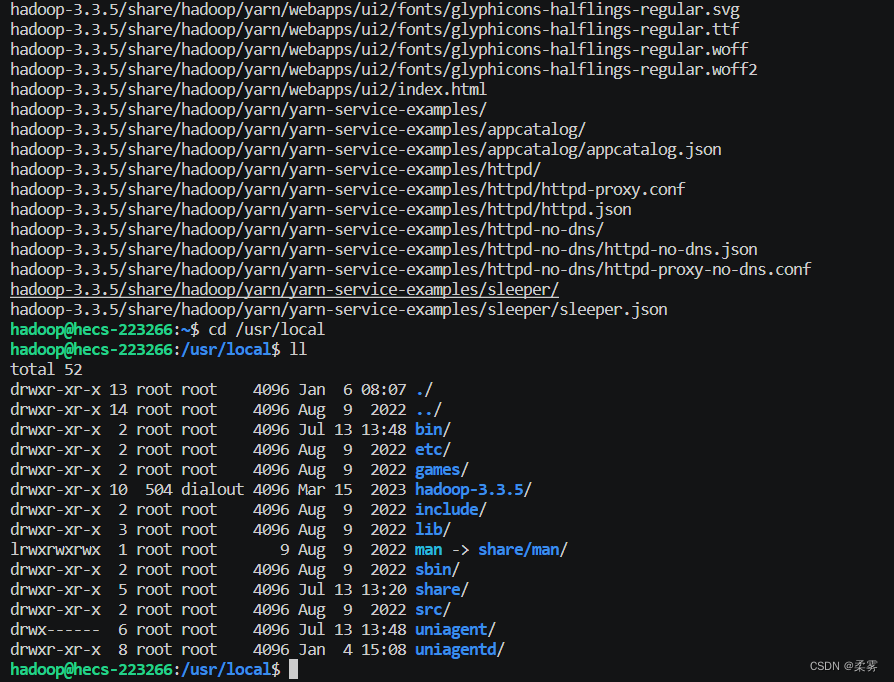
将文件夹名改为hadoop,方便后续操作。
sudo mv ./hadoop-3.3.5/ ./hadoop
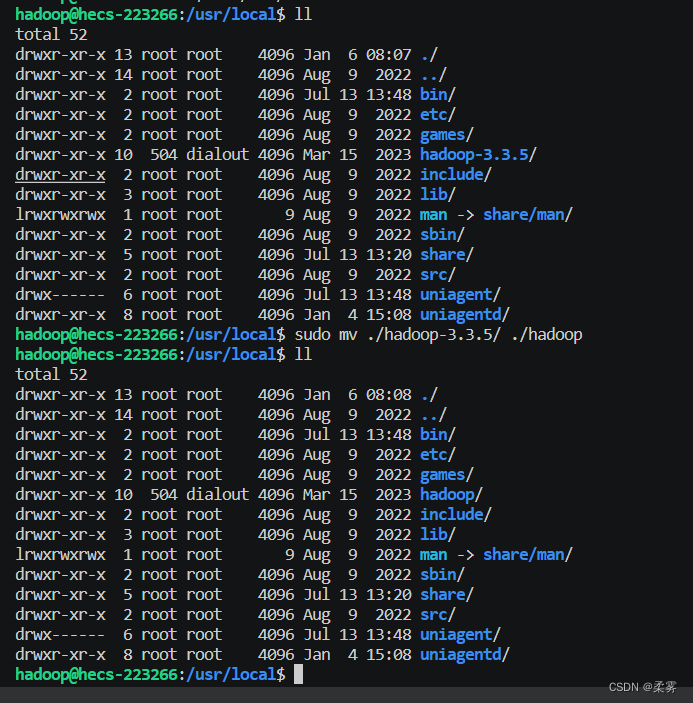
修改文件权限,在该命令中,sudo 表示以超级用户权限执行命令,chown 是修改文件/目录所有权的命令,-R 选项表示递归地修改目录及其子目录下的所有文件和目录的所有权。hadoop 是要将所有权更改为的用户名称,./hadoop 是要更改所有权的目录路径。
sudo chown -R hadoop ./hadoop
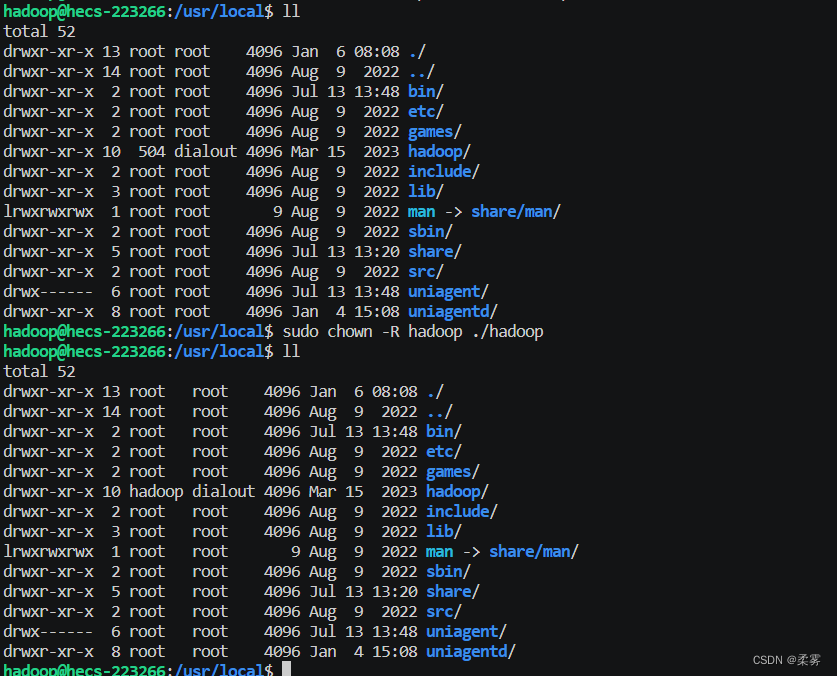
要是安装错了文件可以输入以下命令删除文件。
rm -f hadoop-3.3.5.tar.gz.1
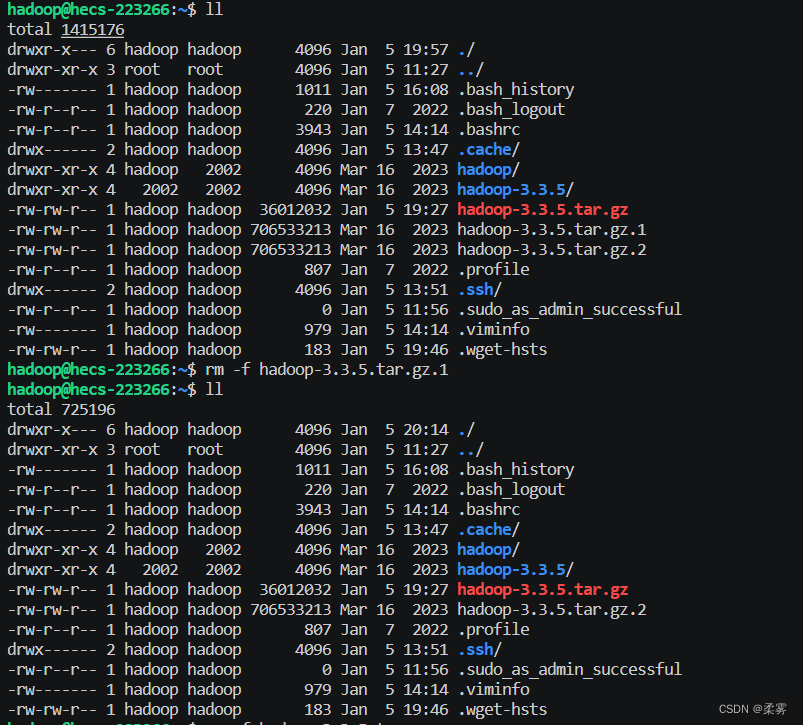
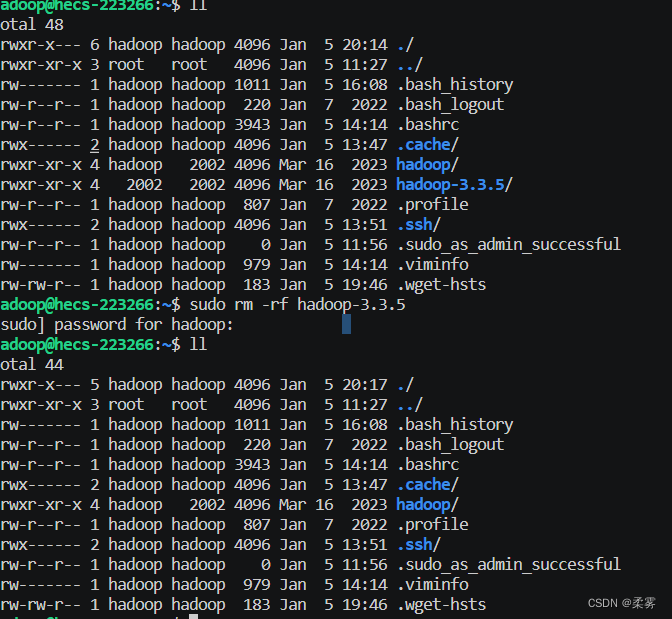
删除文件夹可以输入以下命令。
sudo rm -rf hadoop-3.3.5
会要求你输入hadoop用户的密码。
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息。
cd /usr/local/hadoop
./bin/hadoop version

Hadoop单机配置(非分布式)
在hadoop文件夹下进行操作。
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果

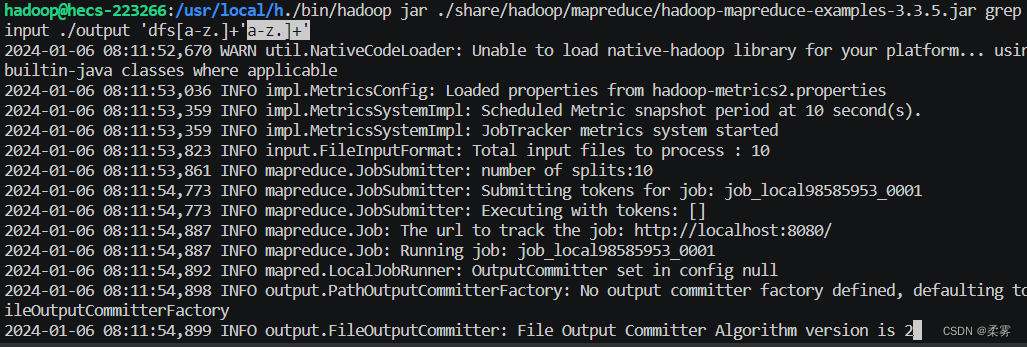
运行结果查看。
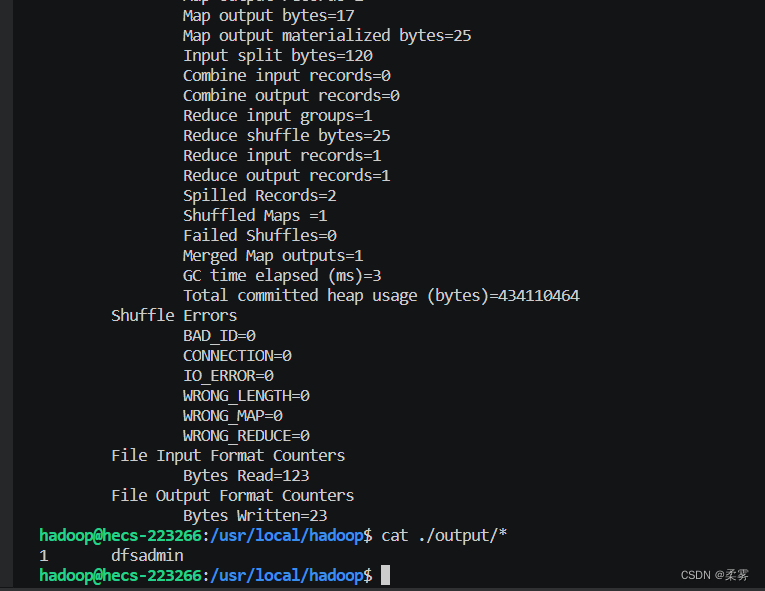
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先将 ./output 删除。
rm -r ./output
Hadoop伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改配置文件 core-site.xml
vim ./etc/hadoop/core-site.xml
按i进入编辑模式。
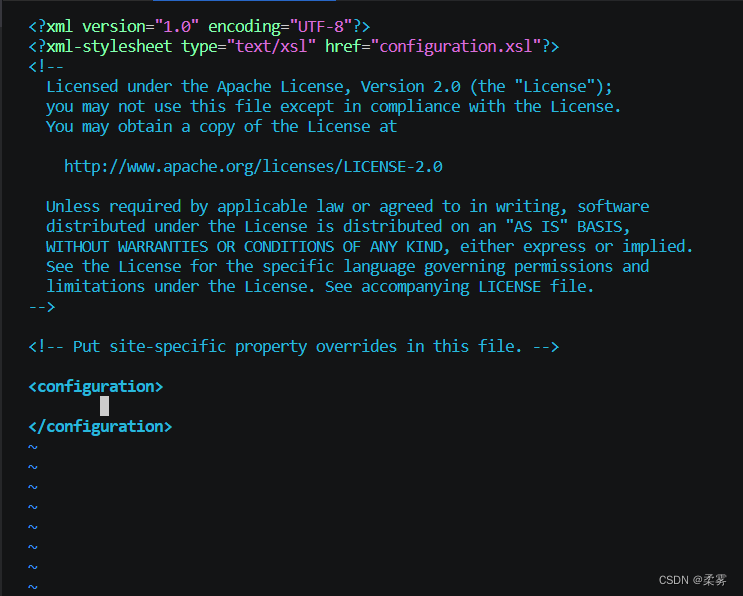
修改为下面的格式。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
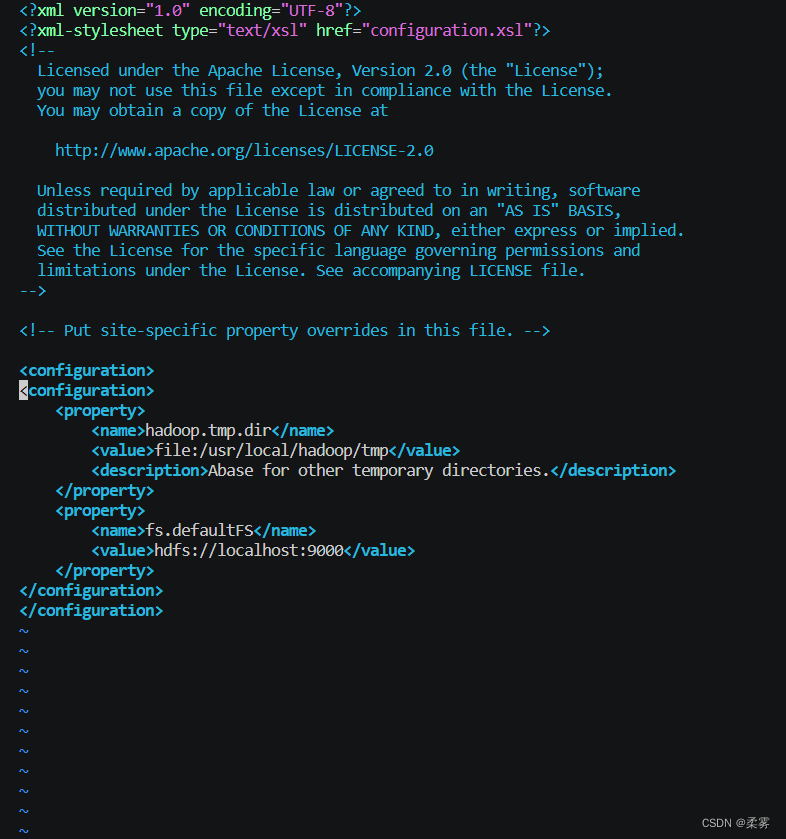
按ESC输入:wq保存并退出。
修改配置文件 hdfs-site.xml。
vim ./etc/hadoop/hdfs-site.xml
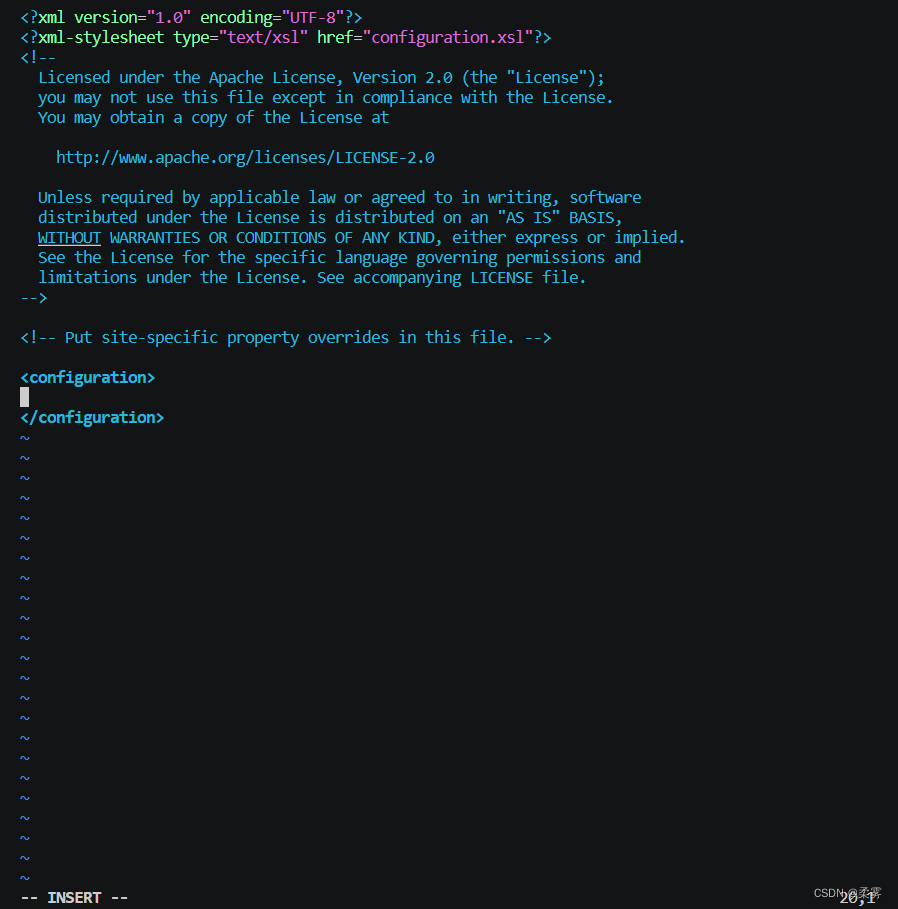
修改成下面的样子。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

按ESC输入:wq保存并退出。
Hadoop配置文件说明:
Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完成后,执行 NameNode 的格式化:
cd /usr/local/hadoop
./bin/hdfs namenode -format
该过程中会提示输入,输入y即可。

如果在这一步时提示 Error: JAVA_HOME is not set and could not be found. 的错误,说明之前设置 JAVA_HOME 环境变量那边就没设置好,请按教程先设置好 JAVA_HOME 变量,否则后面的过程都是进行不下去的。如果已经按照前面教程在.bashrc文件中设置了JAVA_HOME,还是出现 Error: JAVA_HOME is not set and could not be found. 的错误,那么,请到hadoop的安装目录修改配置文件“/usr/local/hadoop/etc/hadoop/hadoop-env.sh”,在里面找到“export JAVA_HOME=${JAVA_HOME}”这行,然后,把它修改成JAVA安装路径的具体地址,比如,“export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64”,然后,再次启动Hadoop。
接着开启 NameNode 和 DataNode 守护进程。
start-dfs.sh是个完整的可执行文件,中间没有空格
cd /usr/local/hadoop
./sbin/start-dfs.sh

启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
输入jps即可查看节点信息
jps

进行hadoop环境变量的配置。
输入改代码检查hadoop是否已经配置环境变量。
echo $HADOOP_HOME

如果输出为空或指向错误的路径,请编辑您的bashrc文件并添加以下行。
cd ~
vim ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
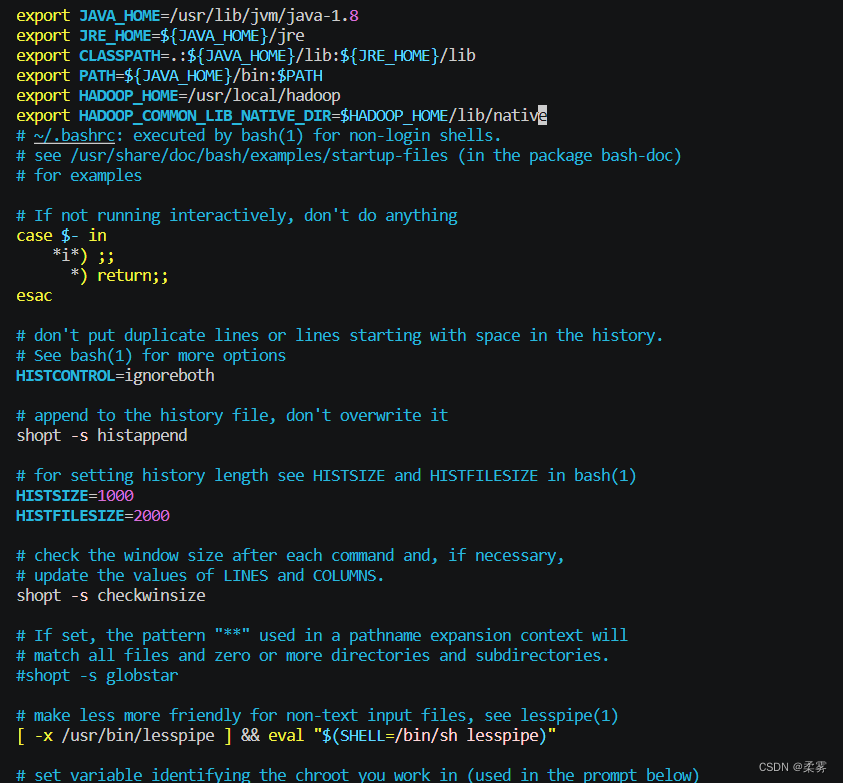
source ~/.bashrc
运行Hadoop伪分布式实例
上面的单机模式,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录。
./bin/hdfs dfs -mkdir -p /user/hadoop

三种shell命令方式
1.hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
2.hadoop dfs只能适用于HDFS文件系统
3.hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
接着将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中,即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中。我们使用的是 hadoop 用户,并且已创建相应的用户目录 /user/hadoop ,因此在命令中就可以使用相对路径如 input,其对应的绝对路径就是 /user/hadoop/input。
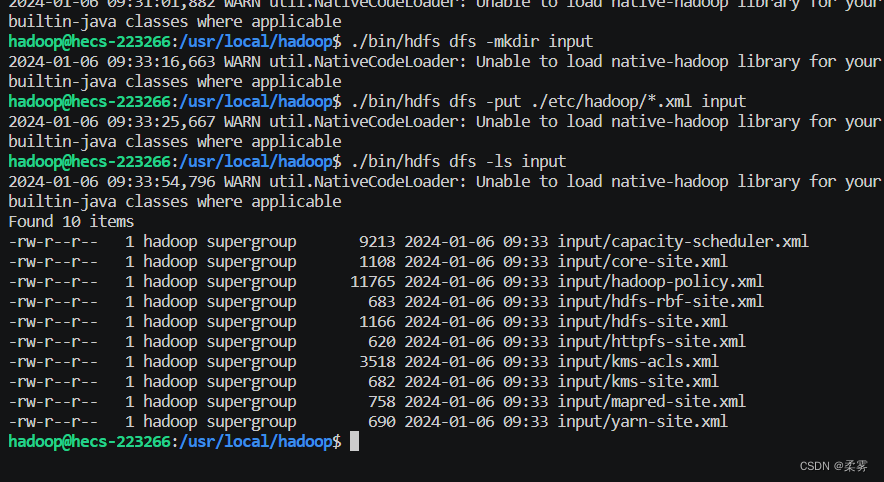
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表。
./bin/hdfs dfs -ls input
伪分布式运行 MapReduce 作业的方式跟单机模式相同,区别在于伪分布式读取的是HDFS中的文件(可以将单机步骤中创建的本地 input 文件夹,输出结果 output 文件夹都删掉来验证这一点)。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+'
查看运行结果的命令(查看的是位于 HDFS 中的输出结果)。
./bin/hdfs dfs -cat output/*
结果如下,注意到刚才我们已经更改了配置文件,所以运行结果不同。

我们也可以将运行结果取回到本地。
rm -r ./output # 先删除本地的 output 文件夹(如果存在)
./bin/hdfs dfs -get output ./output # 将 HDFS 上的 output 文件夹拷贝到本机
cat ./output/*

Hadoop 运行程序时,输出目录不能存在,否则会提示错误 “org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://localhost:9000/user/hadoop/output already exists” ,因此若要再次执行,需要执行如下命令删除 output 文件夹。
./bin/hdfs dfs -rm -r output

运行程序时,输出目录不能存在: 运行 Hadoop 程序时,为了防止覆盖结果,程序指定的输出目录(如 output)不能存在,否则会提示错误,因此运行前需要先删除输出目录。在实际开发应用程序时,可考虑在程序中加上如下代码,能在每次运行时自动删除输出目录,避免繁琐的命令行操作。
Configuration conf = new Configuration();
Job job = new Job(conf);
/* 删除输出目录 */
Path outputPath = new Path(args[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
关闭hadoop
./sbin/stop-dfs.sh
注意: 下次启动 hadoop 时,无需进行 NameNode 的初始化,只需要运行 ./sbin/start-dfs.sh 就可以。
总结
以上就是对hadoop在云服务器上的部署,若有问题可留言。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 全面解析ps缺失MSVCP140.dll无法运行问题,快速解决dll报错问题
- IDEA使用之打包Jar,指定main方法
- Golang leetcode206 翻转链表 迭代 递归 双指针
- Python自动化测试框架【生成测试报告】
- 基于差分进化算法的移动边缘计算 (MEC) 的资源调度分配优化(提供MATLAB代码)
- matlab串口数据交互的使用
- TS中的类
- 生信分析代谢通路可视化分析R工具包ggkegg的使用案例
- idea 连接docker
- C++ 具名要求-布局