根据音乐合成舞蹈;提升预训练扩散模型分辨率;基于扩散模型的视频超分;LLM推理加速框架;3D控制运动人像合成
本文首发于公众号:机器感知
根据音乐合成舞蹈;提升预训练扩散模型分辨率;基于扩散模型的视频超分;LLM推理加速框架;3D控制运动人像合成
DanceMeld: Unraveling Dance Phrases with Hierarchical Latent Codes for? Music-to-Dance Synthesis

In the realm of 3D digital human applications, music-to-dance presents a challenging task. Dance poses composed of a series of basic meaningful body postures, while dance movements can reflect dynamic changes such as the rhythm, melody, and style of dance. Taking inspiration from these concepts, we introduce an innovative dance generation pipeline called DanceMeld, which comprising two stages, i.e., the dance decouple stage and the dance generation stage.?Our approach has undergone qualitative and quantitative experiments on the AIST++ dataset, demonstrating its superiority over other methods.
Resolution Chromatography of Diffusion Models

In this paper, we introduce "resolution chromatography" that indicates the signal generation rate of each resolution, which is very helpful concept to mathematically explain this coarse-to-fine behavior in generation process, to understand the role of noise schedule, and to design time-dependent modulation. Using resolution chromatography, we determine which resolution level becomes dominant at a specific time step, and experimentally verify our theory with text-to-image diffusion models. We also propose some direct applications utilizing the concept: upscaling pre-trained models to higher resolutions and time-dependent prompt composing.
Inflation with Diffusion: Efficient Temporal Adaptation for ?Text-to-Video Super-Resolution

We propose an efficient diffusion-based text-to-video super-resolution (SR) tuning approach that leverages the readily learned capacity of pixel level image diffusion model to capture spatial information for video generation. To accomplish this goal, we design an efficient architecture by inflating the weightings of the text-to-image SR model into our video generation framework. Additionally, we incorporate a temporal adapter to ensure temporal coherence across video frames. Empirical evaluation, both quantitative and qualitative, on the Shutterstock video dataset, demonstrates that our approach is able to perform text-to-video SR generation with good visual quality and temporal consistency.
Medusa: Simple LLM Inference Acceleration Framework with Multiple ?Decoding Heads
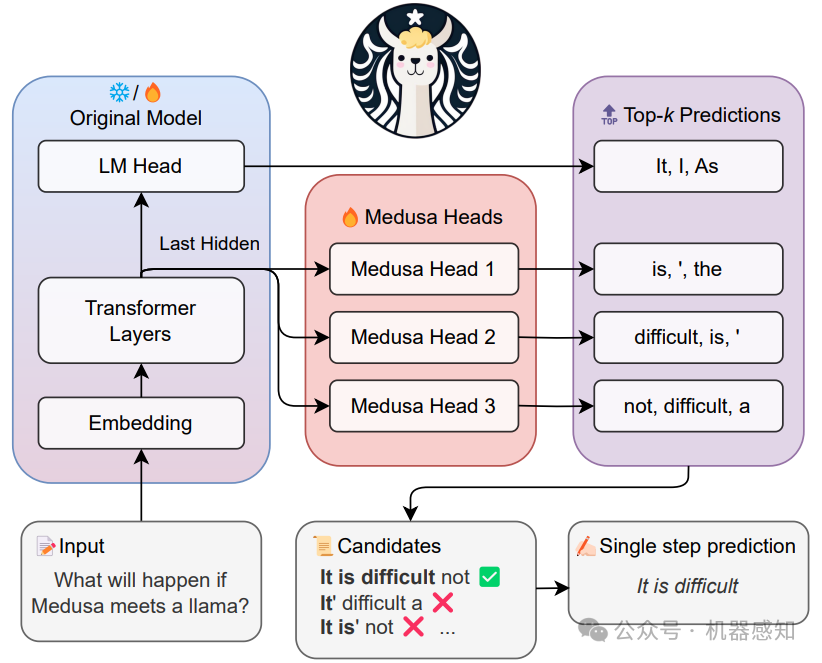
The inference process in Large Language Models (LLMs) is often limited due to the absence of parallelism in the auto-regressive decoding process, resulting in most operations being restricted by the memory bandwidth of accelerators. In this paper, we present Medusa, an efficient method that augments LLM inference by adding extra decoding heads to predict multiple subsequent tokens in parallel.
ActAnywhere: Subject-Aware Video Background Generation

Generating video background that tailors to foreground subject motion is an important problem for the movie industry and visual effects community. We introduce ActAnywhere, a generative model that automates this process which traditionally requires tedious manual efforts. Our model leverages the power of large-scale video diffusion models, and is specifically tailored for this task. ActAnywhere takes a sequence of foreground subject segmentation as input and an image that describes the desired scene as condition, to produce a coherent video with realistic foreground-background interactions while adhering to the condition frame.
Synthesizing Moving People with 3D Control

In this paper, we present a diffusion model-based framework for animating people from a single image for a given target 3D motion sequence. Our approach has two core components: a) learning priors about invisible parts of the human body and clothing, and b) rendering novel body poses with proper clothing and texture. This disentangled approach allows our method to generate a sequence of images that are faithful to the target motion in the 3D pose and, to the input image in terms of visual similarity. In addition to that, the 3D control allows various synthetic camera trajectories to render a person.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux基础知识
- css手机端图片截取 object-fit: cover;
- SpringIOC之support模块GenericApplicationContext
- Java解析XML
- linux:sed 用法详解
- 【k8s】Kubernetes技术和相关命令简介
- 骑砍战团MOD开发(37)-module_skin.py皮肤系统
- seata分布式事务
- 文心一言 —— 中国的语言大模型
- LinkedIn Datahub UI界面出现两个相同container