YOLOv8改进 | 2023注意力篇 | HAttention(HAT)超分辨率重建助力小目标检测 (全网首发)
一、本文介绍
本文给大家带来的改进机制是HAttention注意力机制,混合注意力变换器(HAT)的设计理念是通过融合通道注意力和自注意力机制来提升单图像超分辨率重建的性能。通道注意力关注于识别哪些通道更重要,而自注意力则关注于图像内部各个位置之间的关系。HAT利用这两种注意力机制,有效地整合了全局的像素信息,从而提供更为精确的结果(这个注意力机制挺复杂的光代码就700+行),但是效果挺好的也是10月份最新的成果非常适合添加到大家自己的论文中。
推荐指数:?????(最新的改进机制)
效果回顾展示->
目录
二、HAttention框架原理?
 官方论文地址:官方论文地址
官方论文地址:官方论文地址
官方代码地址:官方代码地址
 ?
?
这篇论文提出了一种新的混合注意力变换器(Hybrid Attention Transformer, HAT)用于单图像超分辨率重建。HAT结合了通道注意力和自注意力,以激活更多像素以进行高分辨率重建。此外,作者还提出了一个重叠交叉注意模块来增强跨窗口信息的交互。论文还引入了一种同任务预训练策略,以进一步发掘HAT的潜力。通过广泛的实验,论文展示了所提出模块和预训练策略的有效性,其方法在定量和定性方面显著优于现有的最先进方法。?
这篇论文的创新点主要包括:
1. 混合注意力变换器(HAT)的引入:它结合了通道注意力和自注意力机制,以改善单图像超分辨率重建。
2.重叠交叉注意模块:这一模块用于增强跨窗口信息的交互,以进一步提升超分辨率重建的性能。
3.同任务预训练策略:作者提出了一种新的预训练方法,专门针对HAT,以充分利用其潜力。
这些创新点使得所提出的方法在超分辨率重建方面的性能显著优于现有技术。
 ?
?
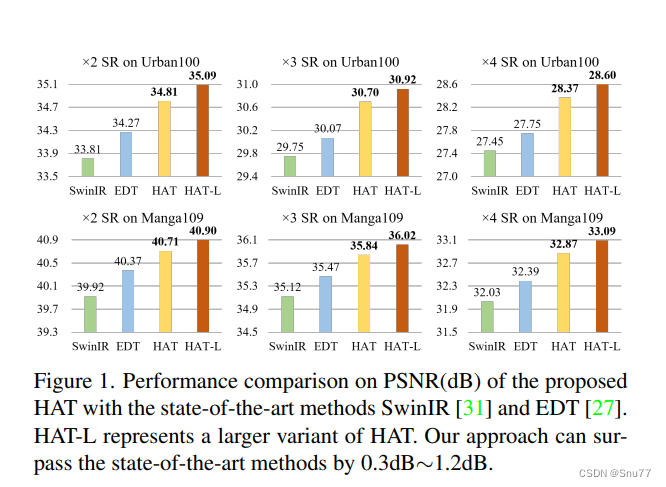
这个图表展示了所提出的混合注意力变换器(HAT)在不同放大倍数(x2, x3, x4)和不同数据集(Urban100和Manga109)上的性能对比。HAT模型与其他最先进模型,如SwinIR和EDT进行了比较。图表显示,HAT在PSNR(峰值信噪比)度量上,比SwinIR和EDT有显著提升。特别是在Urban100数据集上,HAT的改进幅度介于0.3dB到1.2dB之间。HAT-L是HAT的一个更大的变体,它在所有测试中都表现得非常好,进一步证明了HAT模型的有效性。?
 这幅图描绘了混合注意力变换器(HAT)的整体架构及其关键组成部分的结构。HAT包括浅层特征提取,深层特征提取,以及图像重建三个主要步骤。在深层特征提取部分,有多个残差混合注意力组(RHAG),每个组内包含多个混合注意力块(HAB)和一个重叠交叉注意块(OCAB)。HAB利用通道注意力块(CAB)和窗口式多头自注意力(W-MSA),在提取特征时考虑了通道之间和空间位置之间的相关性。OCAB进一步增强了不同窗口间特征的交互。最后,经过多个RHAG处理的特征通过图像重建部分,恢复成高分辨率的图像(这个在代码中均有体现,这个注意力机制代码巨长,700多行)。
这幅图描绘了混合注意力变换器(HAT)的整体架构及其关键组成部分的结构。HAT包括浅层特征提取,深层特征提取,以及图像重建三个主要步骤。在深层特征提取部分,有多个残差混合注意力组(RHAG),每个组内包含多个混合注意力块(HAB)和一个重叠交叉注意块(OCAB)。HAB利用通道注意力块(CAB)和窗口式多头自注意力(W-MSA),在提取特征时考虑了通道之间和空间位置之间的相关性。OCAB进一步增强了不同窗口间特征的交互。最后,经过多个RHAG处理的特征通过图像重建部分,恢复成高分辨率的图像(这个在代码中均有体现,这个注意力机制代码巨长,700多行)。
2.1?混合注意力变换器(HAT)
混合注意力变换器(HAT)的设计理念是通过融合通道注意力和自注意力机制来提升单图像超分辨率重建的性能。通道注意力关注于识别哪些通道更重要,而自注意力则关注于图像内部各个位置之间的关系。HAT利用这两种注意力机制,有效地整合了全局的像素信息,从而提供更为精确的上采样结果。这种结合使得HAT能够更好地重建高频细节,提高重建图像的质量和精度。?
? 这幅图表展示了不同超分辨率网络的局部归因图(LAM)结果,以及对应的性能指标。LAM展示了在重建高分辨率(HR)图像中标记框内区域时,输入的低分辨率(LR)图像中每个像素的重要性。扩散指数(DI)表示参与的像素范围,数值越高表示使用的像素越多。结果表明,HAT(作者的模型)在重建时使用了最多的像素,相比于EDSR、RCAN和SwinIR,HAT显示了最强的像素利用和最高的PSNR/SSIM性能指标。这表明HAT在精细化重建细节方面具有优势。?
这幅图表展示了不同超分辨率网络的局部归因图(LAM)结果,以及对应的性能指标。LAM展示了在重建高分辨率(HR)图像中标记框内区域时,输入的低分辨率(LR)图像中每个像素的重要性。扩散指数(DI)表示参与的像素范围,数值越高表示使用的像素越多。结果表明,HAT(作者的模型)在重建时使用了最多的像素,相比于EDSR、RCAN和SwinIR,HAT显示了最强的像素利用和最高的PSNR/SSIM性能指标。这表明HAT在精细化重建细节方面具有优势。?
?
?
?
三、HAttention的核心代码
将下面的代码复制粘贴到'ultralytics/nn/modules'的目录下,创建一个py文件粘贴进去,我这里起名字的DAttention.py,其它使用方式看章节四。
import math
import torch
import torch.nn as nn
from basicsr.utils.registry import ARCH_REGISTRY
from basicsr.archs.arch_util import to_2tuple, trunc_normal_
from einops import rearrange
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
From: https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class ChannelAttention(nn.Module):
"""Channel attention used in RCAN.
Args:
num_feat (int): Channel number of intermediate features.
squeeze_factor (int): Channel squeeze factor. Default: 16.
"""
def __init__(self, num_feat, squeeze_factor=16):
super(ChannelAttention, self).__init__()
self.attention = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(num_feat, num_feat // squeeze_factor, 1, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(num_feat // squeeze_factor, num_feat, 1, padding=0),
nn.Sigmoid())
def forward(self, x):
y = self.attention(x)
return x * y
class CAB(nn.Module):
def __init__(self, num_feat, compress_ratio=3, squeeze_factor=30):
super(CAB, self).__init__()
self.cab = nn.Sequential(
nn.Conv2d(num_feat, num_feat // compress_ratio, 3, 1, 1),
nn.GELU(),
nn.Conv2d(num_feat // compress_ratio, num_feat, 3, 1, 1),
ChannelAttention(num_feat, squeeze_factor)
)
def forward(self, x):
return self.cab(x)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (b, h, w, c)
window_size (int): window size
Returns:
windows: (num_windows*b, window_size, window_size, c)
"""
b, h, w, c = x.shape
x = x.view(b, h // window_size, window_size, w // window_size, window_size, c)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, c)
return windows
def window_reverse(windows, window_size, h, w):
"""
Args:
windows: (num_windows*b, window_size, window_size, c)
window_size (int): Window size
h (int): Height of image
w (int): Width of image
Returns:
x: (b, h, w, c)
"""
b = int(windows.shape[0] / (h * w / window_size / window_size))
x = windows.view(b, h // window_size, w // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(b, h, w, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, rpi, mask=None):
"""
Args:
x: input features with shape of (num_windows*b, n, c)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
b_, n, c = x.shape
qkv = self.qkv(x).reshape(b_, n, 3, self.num_heads, c // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[rpi.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nw = mask.shape[0]
attn = attn.view(b_ // nw, nw, self.num_heads, n, n) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, n, n)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(b_, n, c)
x = self.proj(x)
x = self.proj_drop(x)
return x
class HAB(nn.Module):
r""" Hybrid Attention Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self,
dim,
input_resolution,
num_heads,
window_size=7,
shift_size=0,
compress_ratio=3,
squeeze_factor=30,
conv_scale=0.01,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, 'shift_size must in 0-window_size'
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim,
window_size=to_2tuple(self.window_size),
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop)
self.conv_scale = conv_scale
self.conv_block = CAB(num_feat=dim, compress_ratio=compress_ratio, squeeze_factor=squeeze_factor)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, x_size, rpi_sa, attn_mask):
h, w = x_size
b, _, c = x.shape
# assert seq_len == h * w, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(b, h, w, c)
# Conv_X
conv_x = self.conv_block(x.permute(0, 3, 1, 2))
conv_x = conv_x.permute(0, 2, 3, 1).contiguous().view(b, h * w, c)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
attn_mask = attn_mask
else:
shifted_x = x
attn_mask = None
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nw*b, window_size, window_size, c
x_windows = x_windows.view(-1, self.window_size * self.window_size, c) # nw*b, window_size*window_size, c
# W-MSA/SW-MSA (to be compatible for testing on images whose shapes are the multiple of window size
attn_windows = self.attn(x_windows, rpi=rpi_sa, mask=attn_mask)
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, c)
shifted_x = window_reverse(attn_windows, self.window_size, h, w) # b h' w' c
# reverse cyclic shift
if self.shift_size > 0:
attn_x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
attn_x = shifted_x
attn_x = attn_x.view(b, h * w, c)
# FFN
x = shortcut + self.drop_path(attn_x) + conv_x * self.conv_scale
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: b, h*w, c
"""
h, w = self.input_resolution
b, seq_len, c = x.shape
assert seq_len == h * w, 'input feature has wrong size'
assert h % 2 == 0 and w % 2 == 0, f'x size ({h}*{w}) are not even.'
x = x.view(b, h, w, c)
x0 = x[:, 0::2, 0::2, :] # b h/2 w/2 c
x1 = x[:, 1::2, 0::2, :] # b h/2 w/2 c
x2 = x[:, 0::2, 1::2, :] # b h/2 w/2 c
x3 = x[:, 1::2, 1::2, :] # b h/2 w/2 c
x = torch.cat([x0, x1, x2, x3], -1) # b h/2 w/2 4*c
x = x.view(b, -1, 4 * c) # b h/2*w/2 4*c
x = self.norm(x)
x = self.reduction(x)
return x
class OCAB(nn.Module):
# overlapping cross-attention block
def __init__(self, dim,
input_resolution,
window_size,
overlap_ratio,
num_heads,
qkv_bias=True,
qk_scale=None,
mlp_ratio=2,
norm_layer=nn.LayerNorm
):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.overlap_win_size = int(window_size * overlap_ratio) + window_size
self.norm1 = norm_layer(dim)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.unfold = nn.Unfold(kernel_size=(self.overlap_win_size, self.overlap_win_size), stride=window_size, padding=(self.overlap_win_size-window_size)//2)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((window_size + self.overlap_win_size - 1) * (window_size + self.overlap_win_size - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
self.proj = nn.Linear(dim,dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=nn.GELU)
def forward(self, x, x_size, rpi):
h, w = x_size
b, _, c = x.shape
shortcut = x
x = self.norm1(x)
x = x.view(b, h, w, c)
qkv = self.qkv(x).reshape(b, h, w, 3, c).permute(3, 0, 4, 1, 2) # 3, b, c, h, w
q = qkv[0].permute(0, 2, 3, 1) # b, h, w, c
kv = torch.cat((qkv[1], qkv[2]), dim=1) # b, 2*c, h, w
# partition windows
q_windows = window_partition(q, self.window_size) # nw*b, window_size, window_size, c
q_windows = q_windows.view(-1, self.window_size * self.window_size, c) # nw*b, window_size*window_size, c
kv_windows = self.unfold(kv) # b, c*w*w, nw
kv_windows = rearrange(kv_windows, 'b (nc ch owh oww) nw -> nc (b nw) (owh oww) ch', nc=2, ch=c, owh=self.overlap_win_size, oww=self.overlap_win_size).contiguous() # 2, nw*b, ow*ow, c
k_windows, v_windows = kv_windows[0], kv_windows[1] # nw*b, ow*ow, c
b_, nq, _ = q_windows.shape
_, n, _ = k_windows.shape
d = self.dim // self.num_heads
q = q_windows.reshape(b_, nq, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, nq, d
k = k_windows.reshape(b_, n, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, n, d
v = v_windows.reshape(b_, n, self.num_heads, d).permute(0, 2, 1, 3) # nw*b, nH, n, d
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[rpi.view(-1)].view(
self.window_size * self.window_size, self.overlap_win_size * self.overlap_win_size, -1) # ws*ws, wse*wse, nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, ws*ws, wse*wse
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn_windows = (attn @ v).transpose(1, 2).reshape(b_, nq, self.dim)
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, self.dim)
x = window_reverse(attn_windows, self.window_size, h, w) # b h w c
x = x.view(b, h * w, self.dim)
x = self.proj(x) + shortcut
x = x + self.mlp(self.norm2(x))
return x
class AttenBlocks(nn.Module):
""" A series of attention blocks for one RHAG.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self,
dim,
input_resolution,
depth,
num_heads,
window_size,
compress_ratio,
squeeze_factor,
conv_scale,
overlap_ratio,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
downsample=None,
use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList([
HAB(
dim=dim,
input_resolution=input_resolution,
num_heads=num_heads,
window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
compress_ratio=compress_ratio,
squeeze_factor=squeeze_factor,
conv_scale=conv_scale,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer) for i in range(depth)
])
# OCAB
self.overlap_attn = OCAB(
dim=dim,
input_resolution=input_resolution,
window_size=window_size,
overlap_ratio=overlap_ratio,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
mlp_ratio=mlp_ratio,
norm_layer=norm_layer
)
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x, x_size, params):
for blk in self.blocks:
x = blk(x, x_size, params['rpi_sa'], params['attn_mask'])
x = self.overlap_attn(x, x_size, params['rpi_oca'])
if self.downsample is not None:
x = self.downsample(x)
return x
class RHAG(nn.Module):
"""Residual Hybrid Attention Group (RHAG).
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
img_size: Input image size.
patch_size: Patch size.
resi_connection: The convolutional block before residual connection.
"""
def __init__(self,
dim,
input_resolution,
depth,
num_heads,
window_size,
compress_ratio,
squeeze_factor,
conv_scale,
overlap_ratio,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
norm_layer=nn.LayerNorm,
downsample=None,
use_checkpoint=False,
img_size=224,
patch_size=4,
resi_connection='1conv'):
super(RHAG, self).__init__()
self.dim = dim
self.input_resolution = input_resolution
self.residual_group = AttenBlocks(
dim=dim,
input_resolution=input_resolution,
depth=depth,
num_heads=num_heads,
window_size=window_size,
compress_ratio=compress_ratio,
squeeze_factor=squeeze_factor,
conv_scale=conv_scale,
overlap_ratio=overlap_ratio,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop,
attn_drop=attn_drop,
drop_path=drop_path,
norm_layer=norm_layer,
downsample=downsample,
use_checkpoint=use_checkpoint)
if resi_connection == '1conv':
self.conv = nn.Conv2d(dim, dim, 3, 1, 1)
elif resi_connection == 'identity':
self.conv = nn.Identity()
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim, norm_layer=None)
self.patch_unembed = PatchUnEmbed(
img_size=img_size, patch_size=patch_size, in_chans=0, embed_dim=dim, norm_layer=None)
def forward(self, x, x_size, params):
return self.patch_embed(self.conv(self.patch_unembed(self.residual_group(x, x_size, params), x_size))) + x
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
x = x.flatten(2).transpose(1, 2) # b Ph*Pw c
if self.norm is not None:
x = self.norm(x)
return x
class PatchUnEmbed(nn.Module):
r""" Image to Patch Unembedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
def forward(self, x, x_size):
x = x.transpose(1, 2).contiguous().view(x.shape[0], self.embed_dim, x_size[0], x_size[1]) # b Ph*Pw c
return x
class Upsample(nn.Sequential):
"""Upsample module.
Args:
scale (int): Scale factor. Supported scales: 2^n and 3.
num_feat (int): Channel number of intermediate features.
"""
def __init__(self, scale, num_feat):
m = []
if (scale & (scale - 1)) == 0: # scale = 2^n
for _ in range(int(math.log(scale, 2))):
m.append(nn.Conv2d(num_feat, 4 * num_feat, 3, 1, 1))
m.append(nn.PixelShuffle(2))
elif scale == 3:
m.append(nn.Conv2d(num_feat, 9 * num_feat, 3, 1, 1))
m.append(nn.PixelShuffle(3))
else:
raise ValueError(f'scale {scale} is not supported. ' 'Supported scales: 2^n and 3.')
super(Upsample, self).__init__(*m)
@ARCH_REGISTRY.register()
class HAT(nn.Module):
r""" Hybrid Attention Transformer
A PyTorch implementation of : `Activating More Pixels in Image Super-Resolution Transformer`.
Some codes are based on SwinIR.
Args:
img_size (int | tuple(int)): Input image size. Default 64
patch_size (int | tuple(int)): Patch size. Default: 1
in_chans (int): Number of input image channels. Default: 3
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
upscale: Upscale factor. 2/3/4/8 for image SR, 1 for denoising and compress artifact reduction
img_range: Image range. 1. or 255.
upsampler: The reconstruction reconstruction module. 'pixelshuffle'/'pixelshuffledirect'/'nearest+conv'/None
resi_connection: The convolutional block before residual connection. '1conv'/'3conv'
"""
def __init__(self,
in_chans=3,
img_size=64,
patch_size=1,
embed_dim=96,
depths=(6, 6, 6, 6),
num_heads=(6, 6, 6, 6),
window_size=7,
compress_ratio=3,
squeeze_factor=30,
conv_scale=0.01,
overlap_ratio=0.5,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.1,
norm_layer=nn.LayerNorm,
ape=False,
patch_norm=True,
use_checkpoint=False,
upscale=2,
img_range=1.,
upsampler='',
resi_connection='1conv',
**kwargs):
super(HAT, self).__init__()
self.window_size = window_size
self.shift_size = window_size // 2
self.overlap_ratio = overlap_ratio
num_in_ch = in_chans
num_out_ch = in_chans
num_feat = 64
self.img_range = img_range
if in_chans == 3:
rgb_mean = (0.4488, 0.4371, 0.4040)
self.mean = torch.Tensor(rgb_mean).view(1, 3, 1, 1)
else:
self.mean = torch.zeros(1, 1, 1, 1)
self.upscale = upscale
self.upsampler = upsampler
# relative position index
relative_position_index_SA = self.calculate_rpi_sa()
relative_position_index_OCA = self.calculate_rpi_oca()
self.register_buffer('relative_position_index_SA', relative_position_index_SA)
self.register_buffer('relative_position_index_OCA', relative_position_index_OCA)
# ------------------------- 1, shallow feature extraction ------------------------- #
self.conv_first = nn.Conv2d(num_in_ch, embed_dim, 3, 1, 1)
# ------------------------- 2, deep feature extraction ------------------------- #
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = embed_dim
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=embed_dim,
embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# merge non-overlapping patches into image
self.patch_unembed = PatchUnEmbed(
img_size=img_size,
patch_size=patch_size,
in_chans=embed_dim,
embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build Residual Hybrid Attention Groups (RHAG)
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = RHAG(
dim=embed_dim,
input_resolution=(patches_resolution[0], patches_resolution[1]),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
compress_ratio=compress_ratio,
squeeze_factor=squeeze_factor,
conv_scale=conv_scale,
overlap_ratio=overlap_ratio,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])], # no impact on SR results
norm_layer=norm_layer,
downsample=None,
use_checkpoint=use_checkpoint,
img_size=img_size,
patch_size=patch_size,
resi_connection=resi_connection)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
# build the last conv layer in deep feature extraction
if resi_connection == '1conv':
self.conv_after_body = nn.Conv2d(embed_dim, embed_dim, 3, 1, 1)
elif resi_connection == 'identity':
self.conv_after_body = nn.Identity()
# ------------------------- 3, high quality image reconstruction ------------------------- #
if self.upsampler == 'pixelshuffle':
# for classical SR
self.conv_before_upsample = nn.Sequential(
nn.Conv2d(embed_dim, num_feat, 3, 1, 1), nn.LeakyReLU(inplace=True))
self.upsample = Upsample(upscale, num_feat)
self.conv_last = nn.Conv2d(num_feat, num_out_ch, 3, 1, 1)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def calculate_rpi_sa(self):
# calculate relative position index for SA
coords_h = torch.arange(self.window_size)
coords_w = torch.arange(self.window_size)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size - 1
relative_coords[:, :, 0] *= 2 * self.window_size - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
return relative_position_index
def calculate_rpi_oca(self):
# calculate relative position index for OCA
window_size_ori = self.window_size
window_size_ext = self.window_size + int(self.overlap_ratio * self.window_size)
coords_h = torch.arange(window_size_ori)
coords_w = torch.arange(window_size_ori)
coords_ori = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, ws, ws
coords_ori_flatten = torch.flatten(coords_ori, 1) # 2, ws*ws
coords_h = torch.arange(window_size_ext)
coords_w = torch.arange(window_size_ext)
coords_ext = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, wse, wse
coords_ext_flatten = torch.flatten(coords_ext, 1) # 2, wse*wse
relative_coords = coords_ext_flatten[:, None, :] - coords_ori_flatten[:, :, None] # 2, ws*ws, wse*wse
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # ws*ws, wse*wse, 2
relative_coords[:, :, 0] += window_size_ori - window_size_ext + 1 # shift to start from 0
relative_coords[:, :, 1] += window_size_ori - window_size_ext + 1
relative_coords[:, :, 0] *= window_size_ori + window_size_ext - 1
relative_position_index = relative_coords.sum(-1)
return relative_position_index
def calculate_mask(self, x_size):
# calculate attention mask for SW-MSA
h, w = x_size
img_mask = torch.zeros((1, h, w, 1)) # 1 h w 1
h_slices = (slice(0, -self.window_size), slice(-self.window_size,
-self.shift_size), slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size), slice(-self.window_size,
-self.shift_size), slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nw, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x_size = (x.shape[2], x.shape[3])
# Calculate attention mask and relative position index in advance to speed up inference.
# The original code is very time-consuming for large window size.
attn_mask = self.calculate_mask(x_size).to(x.device)
params = {'attn_mask': attn_mask, 'rpi_sa': self.relative_position_index_SA, 'rpi_oca': self.relative_position_index_OCA}
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x, x_size, params)
x = self.norm(x) # b seq_len c
x = self.patch_unembed(x, x_size)
return x
def forward(self, x):
self.mean = self.mean.type_as(x)
x = (x - self.mean) * self.img_range
if self.upsampler == 'pixelshuffle':
# for classical SR
x = self.conv_first(x)
x = self.conv_after_body(self.forward_features(x)) + x
x = self.conv_before_upsample(x)
x = self.conv_last(self.upsample(x))
x = x / self.img_range + self.mean
return x
四、手把手教你添加HAttention机制?
这个HAttention代码刚拿来不能够直接使用的,我在官方的代码基础上做了一定的修改,方便大家使用,所以希望大家给博主点点赞收藏以下,如果你能够成功复现希望大家给博文评论支持以下。
下面是使用教程->
修改一
在上面我们已经将代码复制粘贴到'ultralytics/nn/modules'的目录下,创建一个py文件粘贴进去DAttention.py。下面我们找到文件'ultralytics/nn/tasks.py'在开头导入我们的注意力机制,如下图所示。

?
修改二?
我们找到七百多行的代码,按照我的方法进行添加,可以看到红框内有好多代码,我们只保留字典里你需要的DAT就行,其余的你没有大家不用添加。

elif m in {HAT}:
args = [ch[f], *args]到此就修改完成了,我们直接就可以使用该代码了(为什么这么简单是因为我修改了官方的代码,让使用方法统一起来所以大家用着很简单。)?
?
五、HAttention的yaml文件
在这里我给大家推荐两种添加的方式,像这种注意力机制不要添加在主干上,添加在检测头里(涨点效果最好)或者Neck的输出部分是最好的,你放在主干上,后面经过各种处理信息早已经丢失了,所以没啥效果。
5.1 HAttention的yaml文件一
这个我在大目标检测的输出添加了一个HAttention注意力机制,也是我实验跑出来的版本,这个文章是有个读者指定的所以实验结果都是刚刚出炉的,后面大家有什么想看的机制都可以指定。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [-1, 1, HAT, []] # 22
- [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.2 HAttention的yaml文件二
这个版本在三个目标检测层都添加了,HAT机制,具体效果我没有尝试,但是此版本估计显存需要的比较大,使用时候需要注意降低一定的batch否则爆显存的错误大家尽量不要在评论区评论,有时候真的被大家搞得很无奈一些低级报错发在评论区好像我发的机制有问题,刚才有一个同学用我的SPD-Conv,里面报错autopad,就是没有导入这个模块他发在了评论区,我觉得这 就是简单导入一下这个模块鼠标放在上面点一下的问题,我希望大家看我的博客的同时也要提高自己的动手能力我也是真希望大家能够学到一些,只会照搬也不行的。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOP
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, HAT, []] # 16
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, HAT, []] # 20
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [-1, 1, HAT, []] # 24
- [[16, 20, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)
?
5.3 推荐HAttention可添加的位置?
HAttention是一种即插即用的注意力机制模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入MHSA。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加MSDA可以帮助模型更有效地融合不同层次的特征(yaml文件一和二)。
Backbone:可以替换中干网络中的卷积部分(只能替换不改变通道数的卷积)
能添加的位置很多,一篇文章很难全部介绍到,后期我会发文件里面集成上百种的改进机制,然后还有许多融合模块,给大家,尤其是检测头里改进非常困难,这些属于进阶篇后期会发。
?
5.4 HAttention的训练过程截图?
下面是添加了HAttention的训练截图。
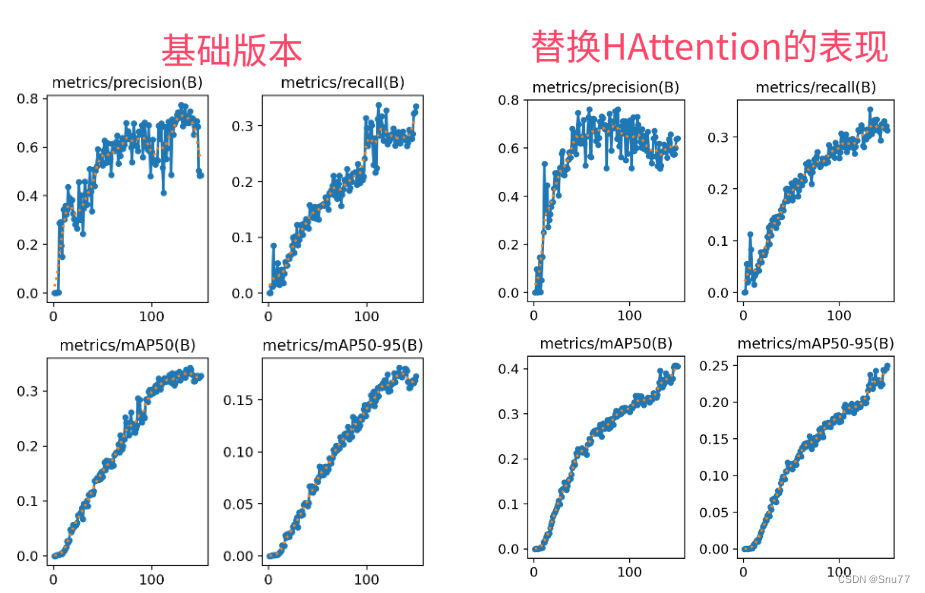
大家可以看下面的运行结果和添加的位置所以不存在我发的代码不全或者运行不了的问题大家有问题也可以在评论区评论我看到都会为大家解答(我知道的),这里我运行的时候有一个警告我没有关,估计也不影响运行和精度就没去处理。
 ?
?
 ?
?
??????
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
 ??
??
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis面试题4
- 智能指针的延迟报错问题
- 通用交通灯带倒计时quartus红绿灯时间可调
- 慎投!新增2本期刊剔除!中科院2区TOP仍被标记长达6个月!(内附1区TOP仅21天录用)
- STL容器之string(上)
- 2024史上最全的 iOS 各种测试工具集锦!
- 大数据HCIE成神之路之数据预处理(5)——偏态数据处理
- GZ075 云计算应用赛题第3套
- Spring通信传参的方法
- 为什么 Go 开发者一定要会 Rust?