CUDA笔记2
发布时间:2024年01月23日
1、培训003
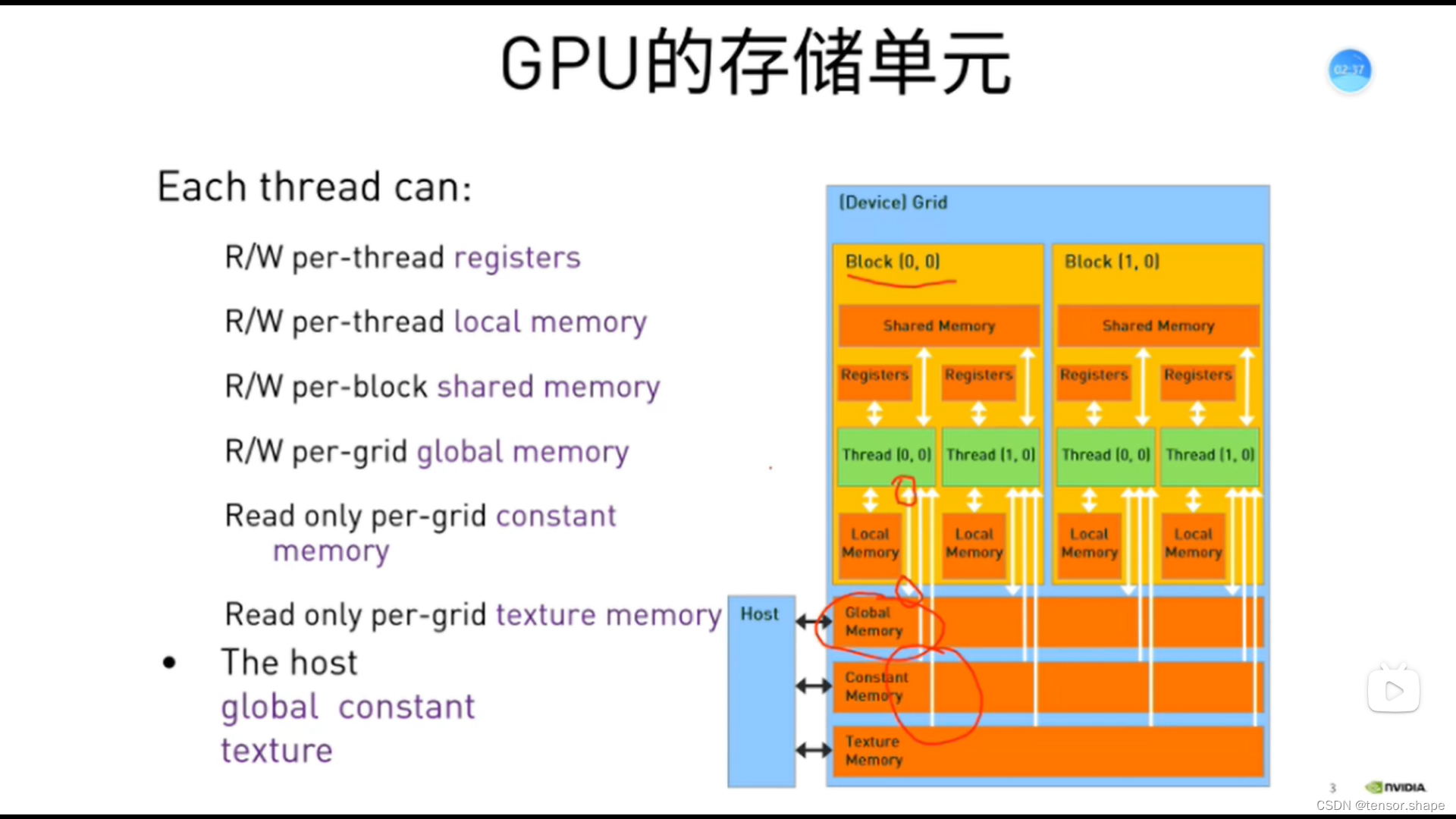

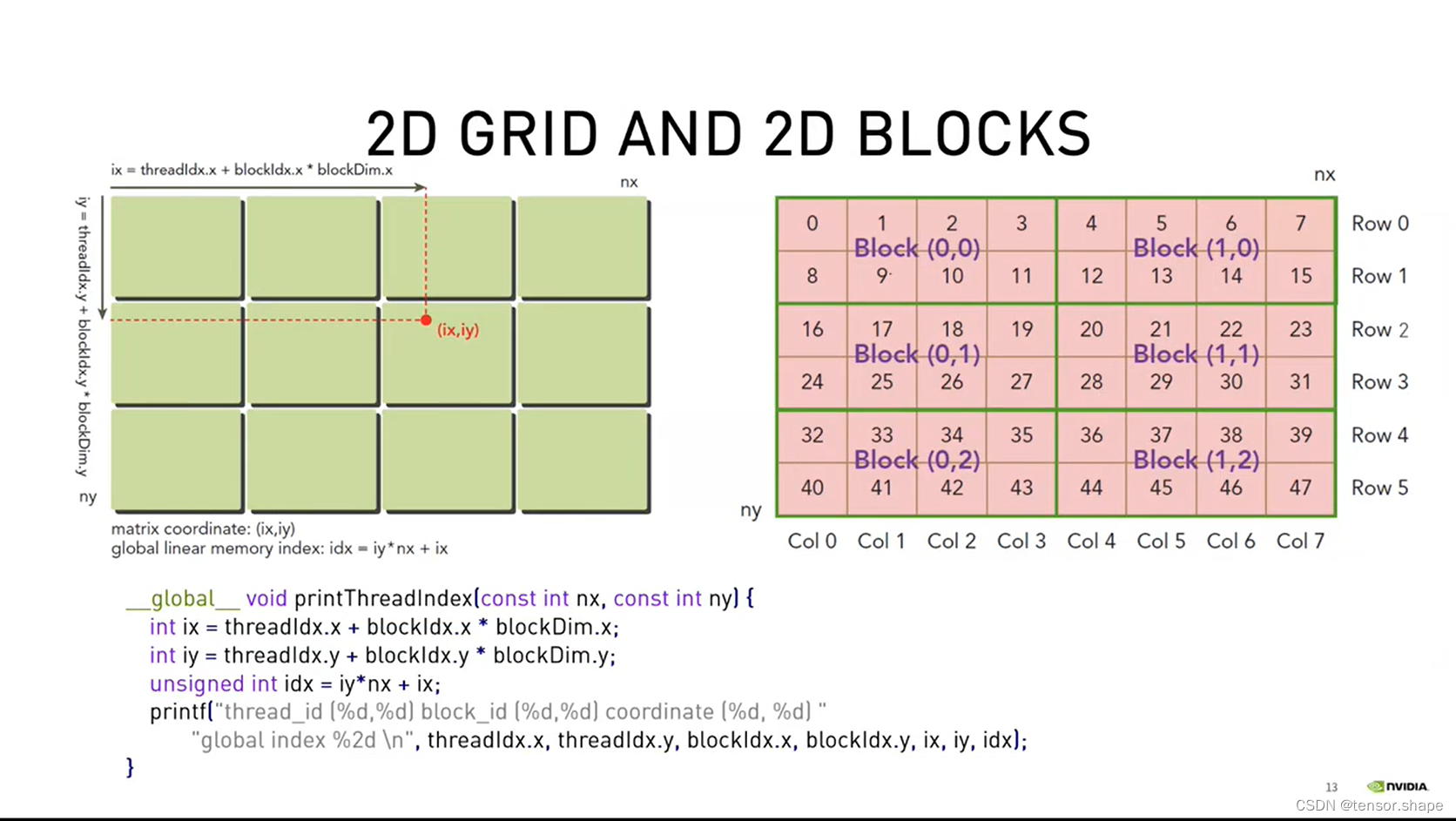
生成线程,每个线程处理哪些数据呢?如右图,0-47共48个数,申请48个线程,需找到每个元素在所有线程的坐标。即一维的坐标,下面展示二维的坐标
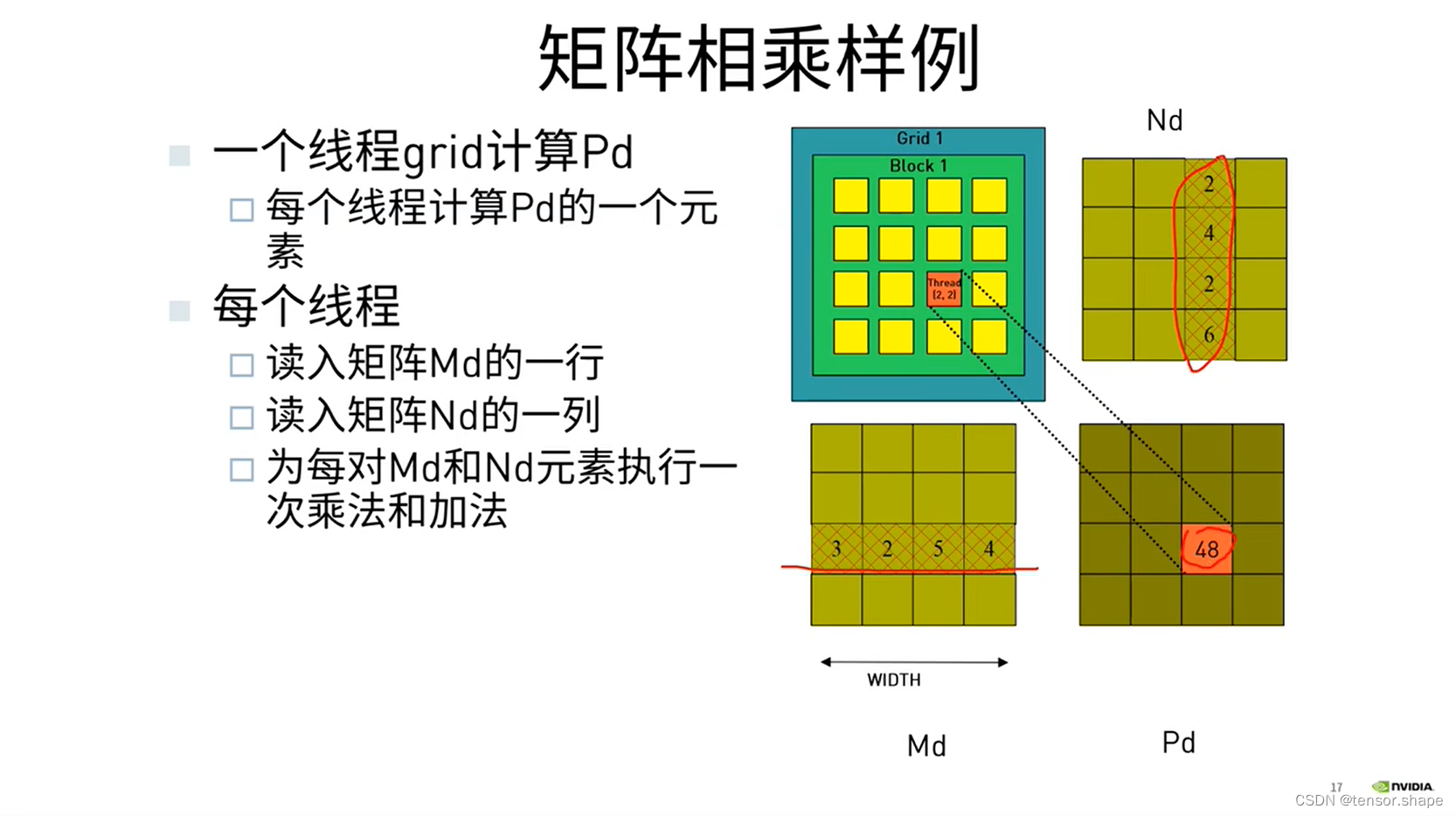
例子:矩阵相乘
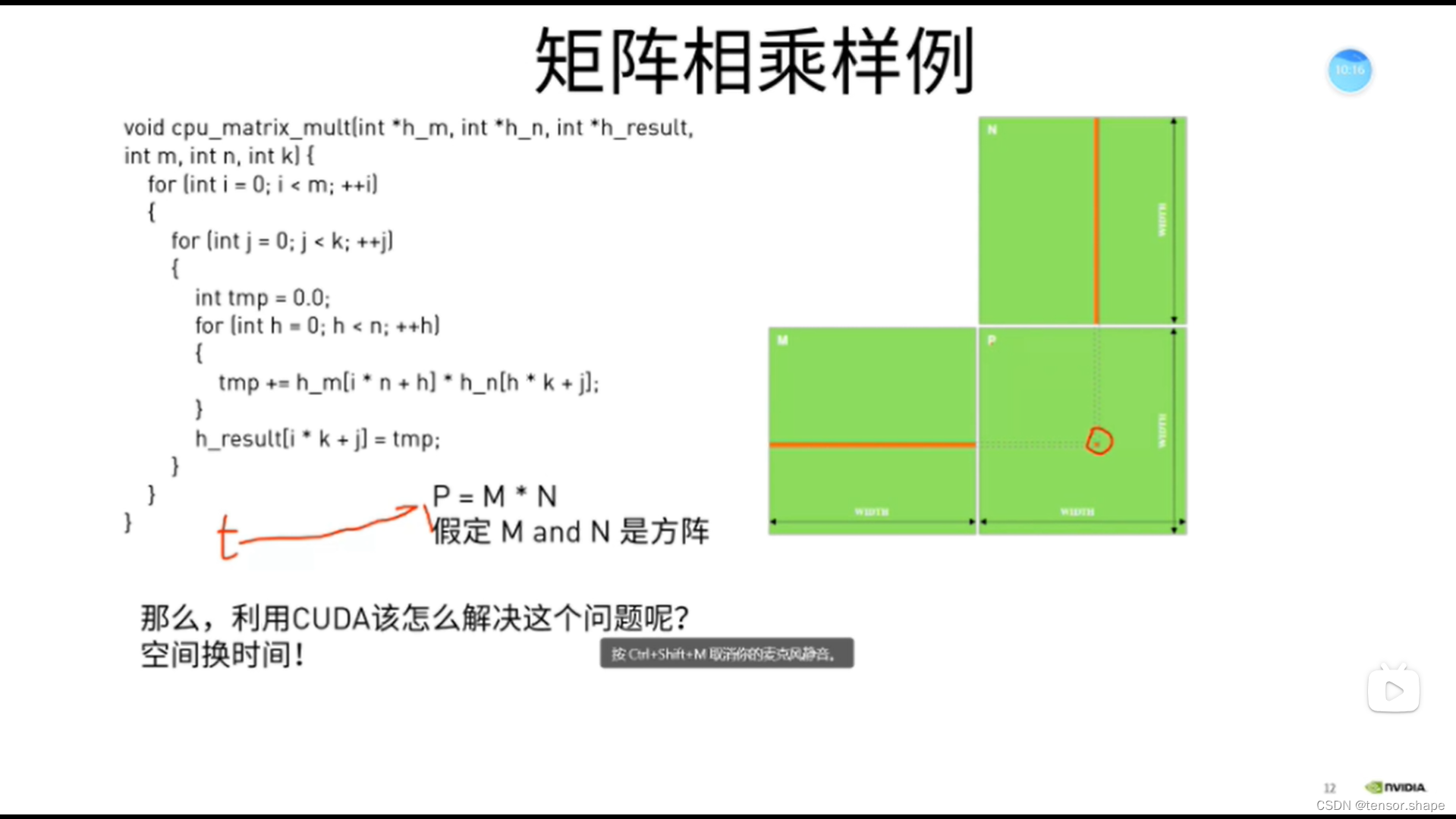
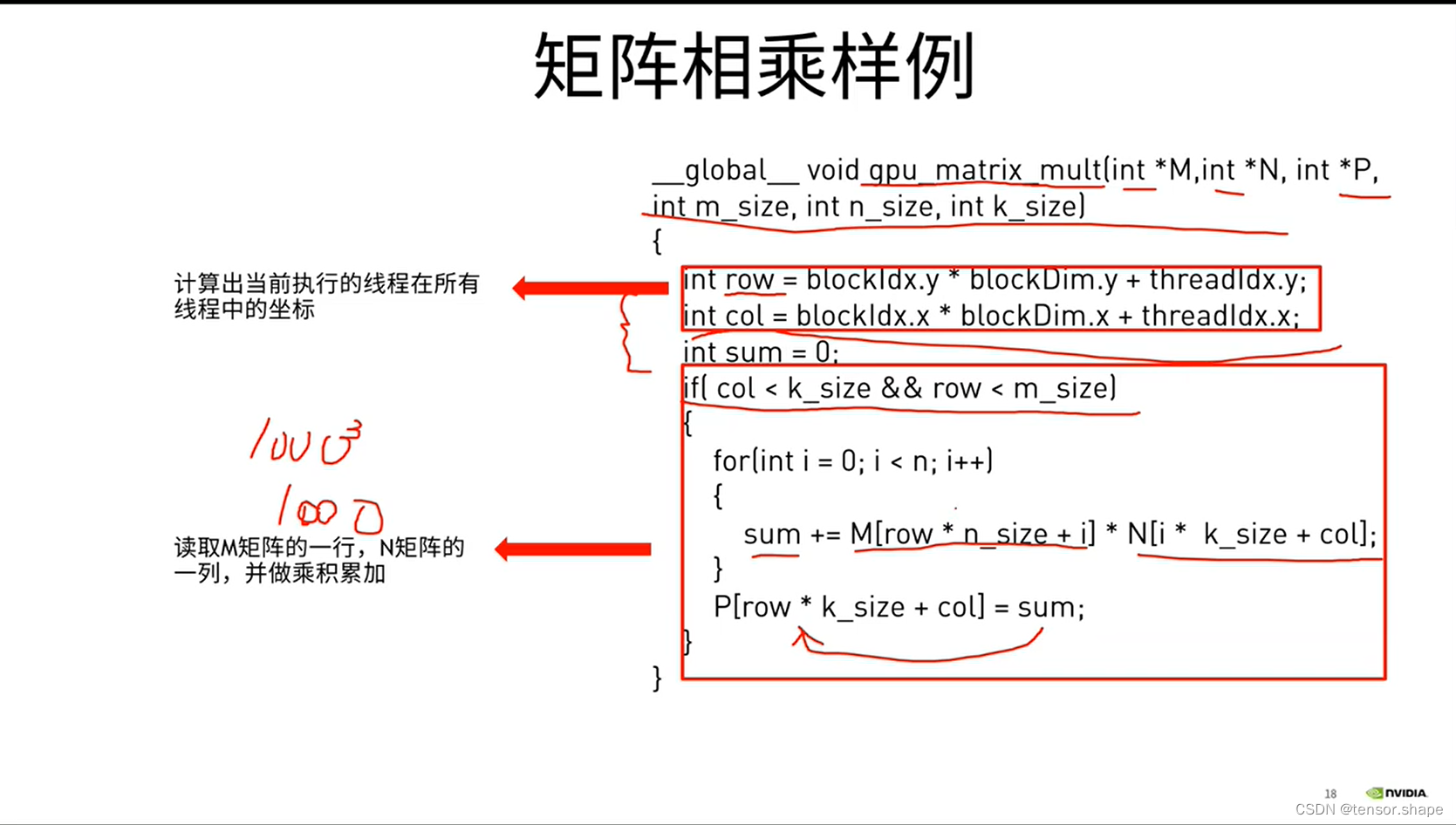
申请很多个thread,每个thread处理P矩阵中的一个元素。P当中有多少个元素,就申请多少个thread,每个线程读取一行,一列。
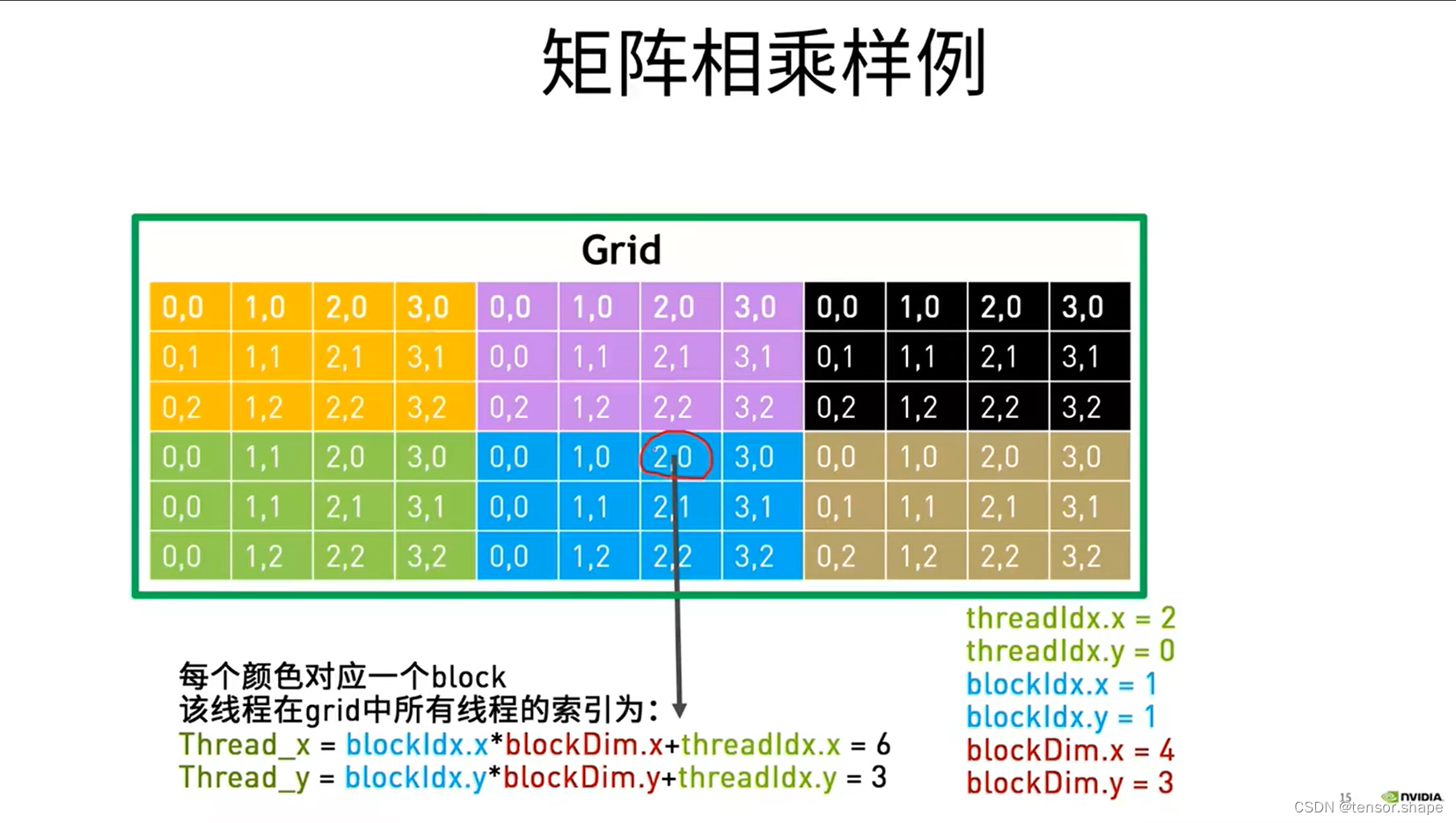
threadIdx.x和threadIdx.y分别是2和0
blockIdx.x和blockIdx.y分别是1和1,因为(1,1)
2、培训004
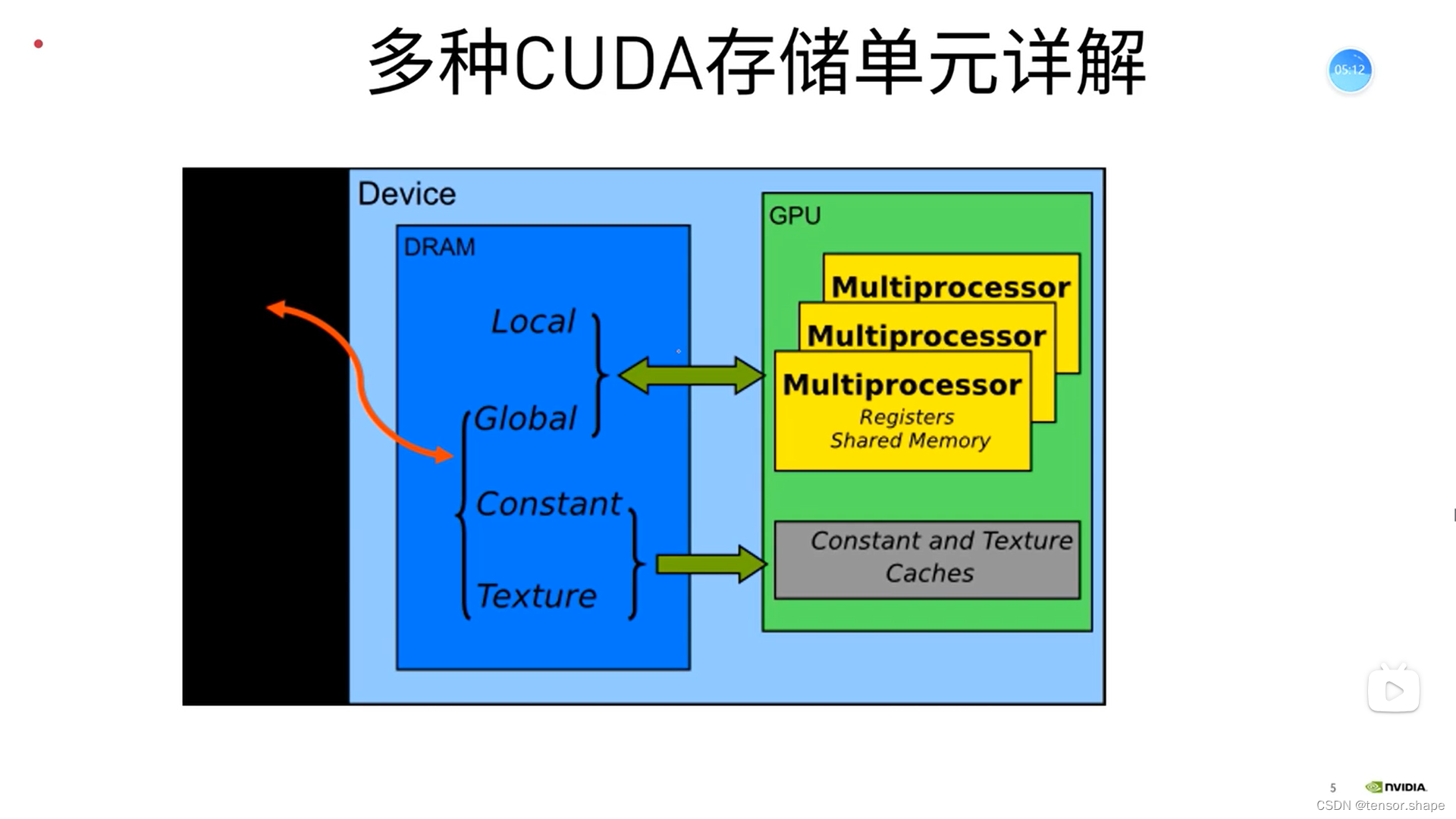


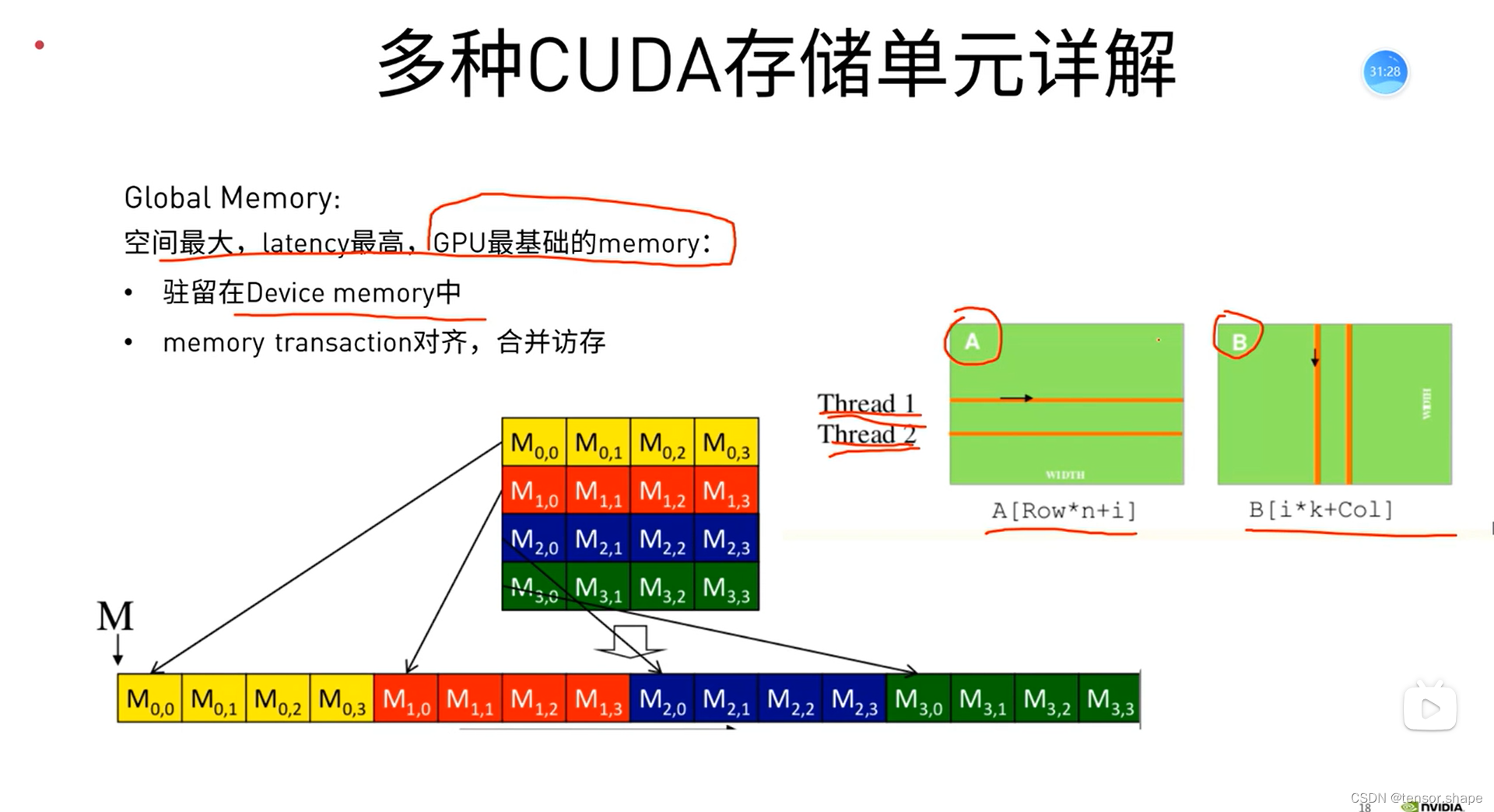
矩阵AB保存在全局存储中,每个thread读取一行,或一列,问那个更快?
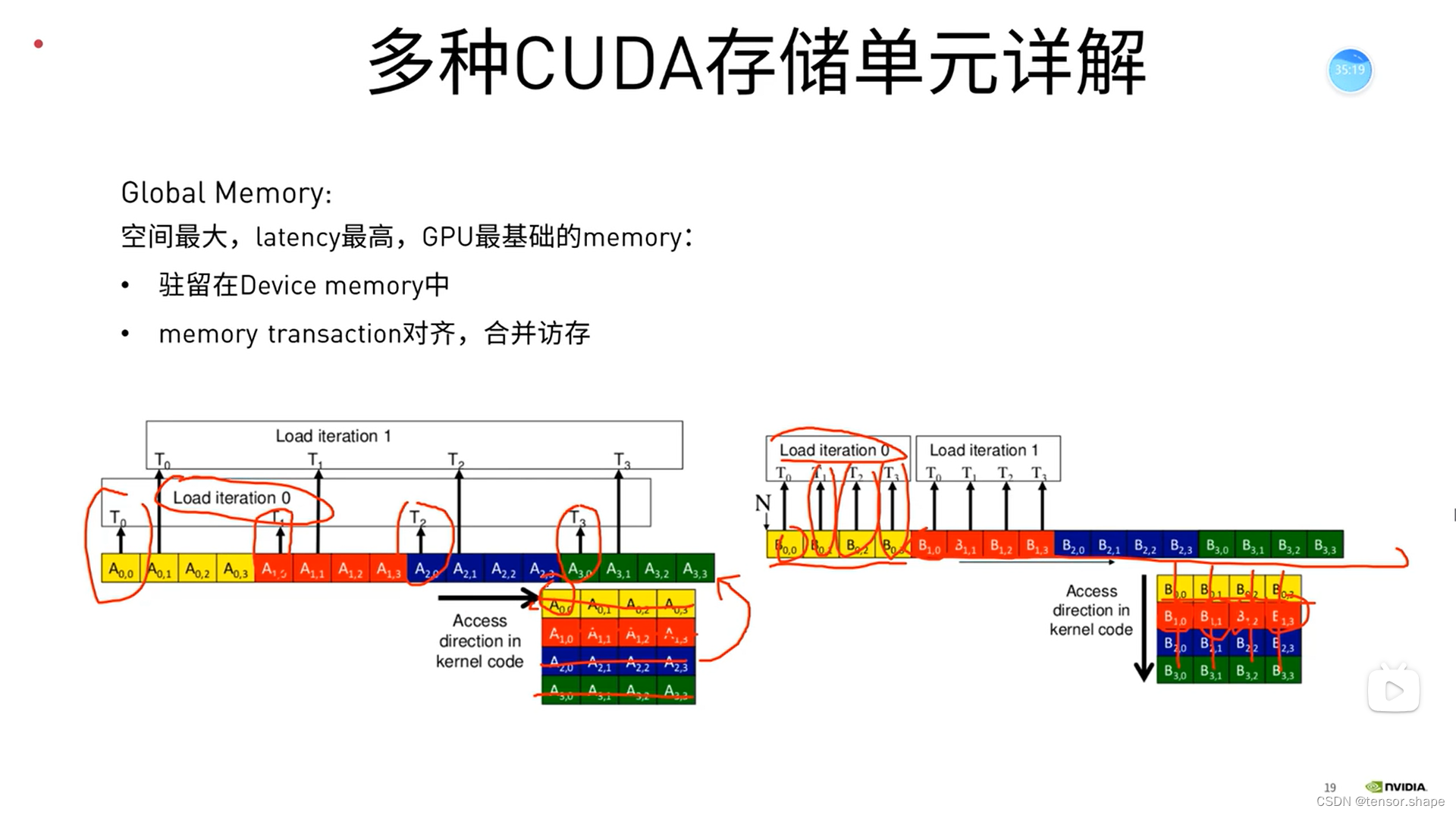
列快,因为T0、T1、T2、T3是按顺序读取即可
(1)如何优化矩阵乘?
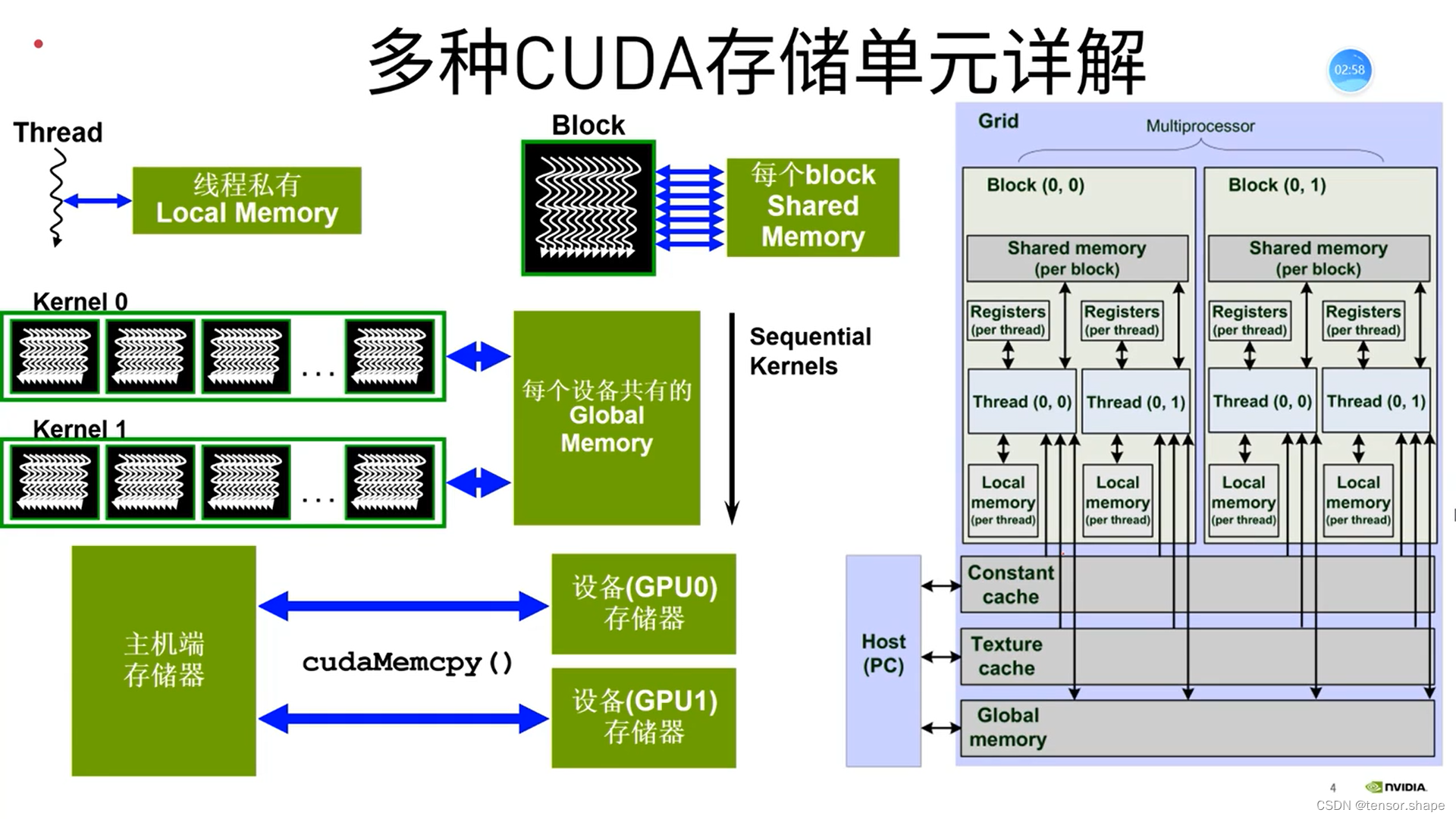
(1)共享存储


常用的两个功能:数据交换的时候(两个正方形),当一个临时buffer(圆);很多次需要从全局存储(矩形)读取数据,可以先把数据放到共享存储(圆)中。
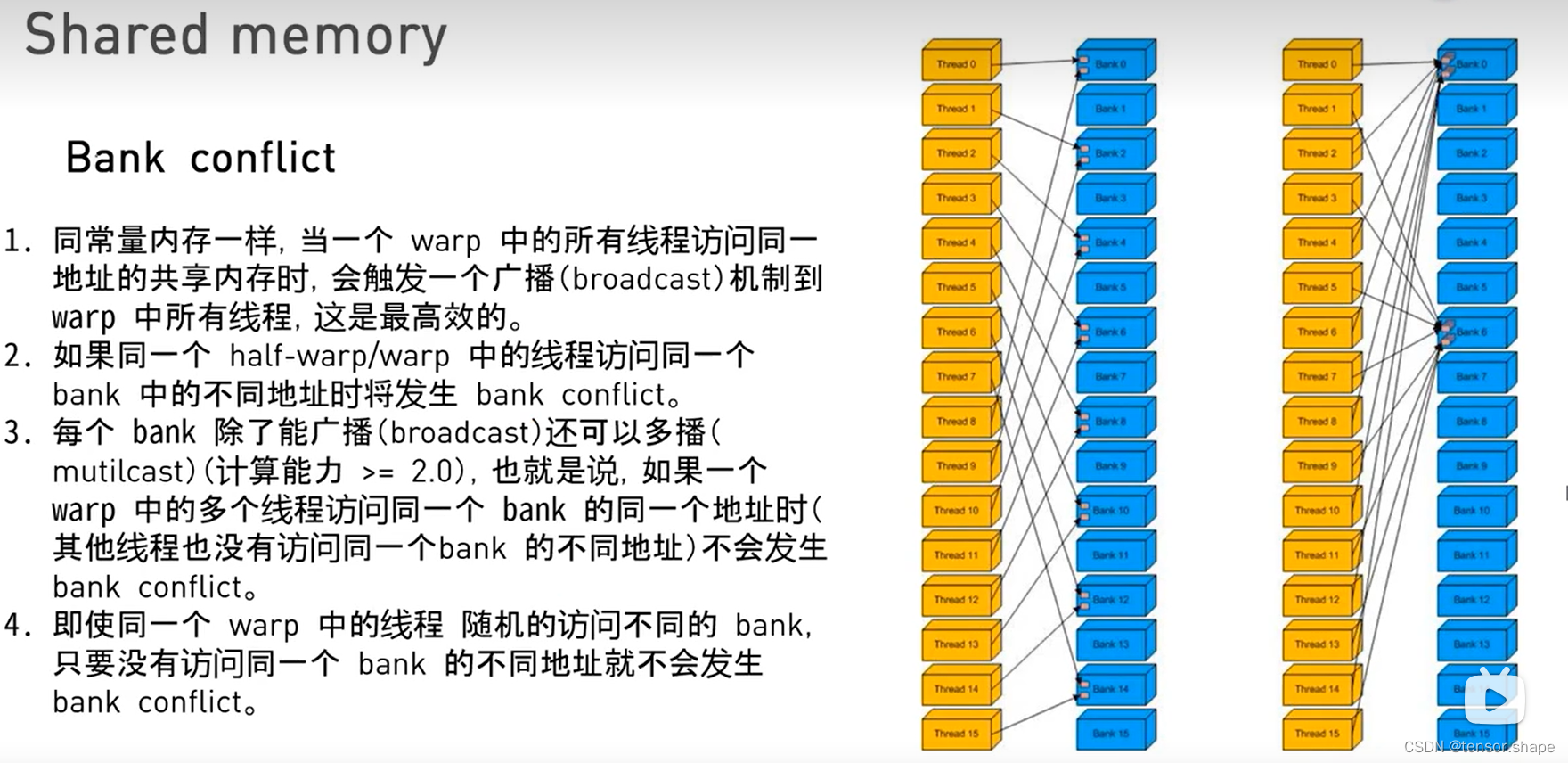
bank冲突的定义:同一个warp中的线程访问同一个bank中的不同地址,如图同一个warp中的thread0和thread8访问同一个bank0的不同地址
解决办法:

如图,每个bank有很多小格,代表不同地址。同一个warp的thread访问的是不同bank,也就避免了。

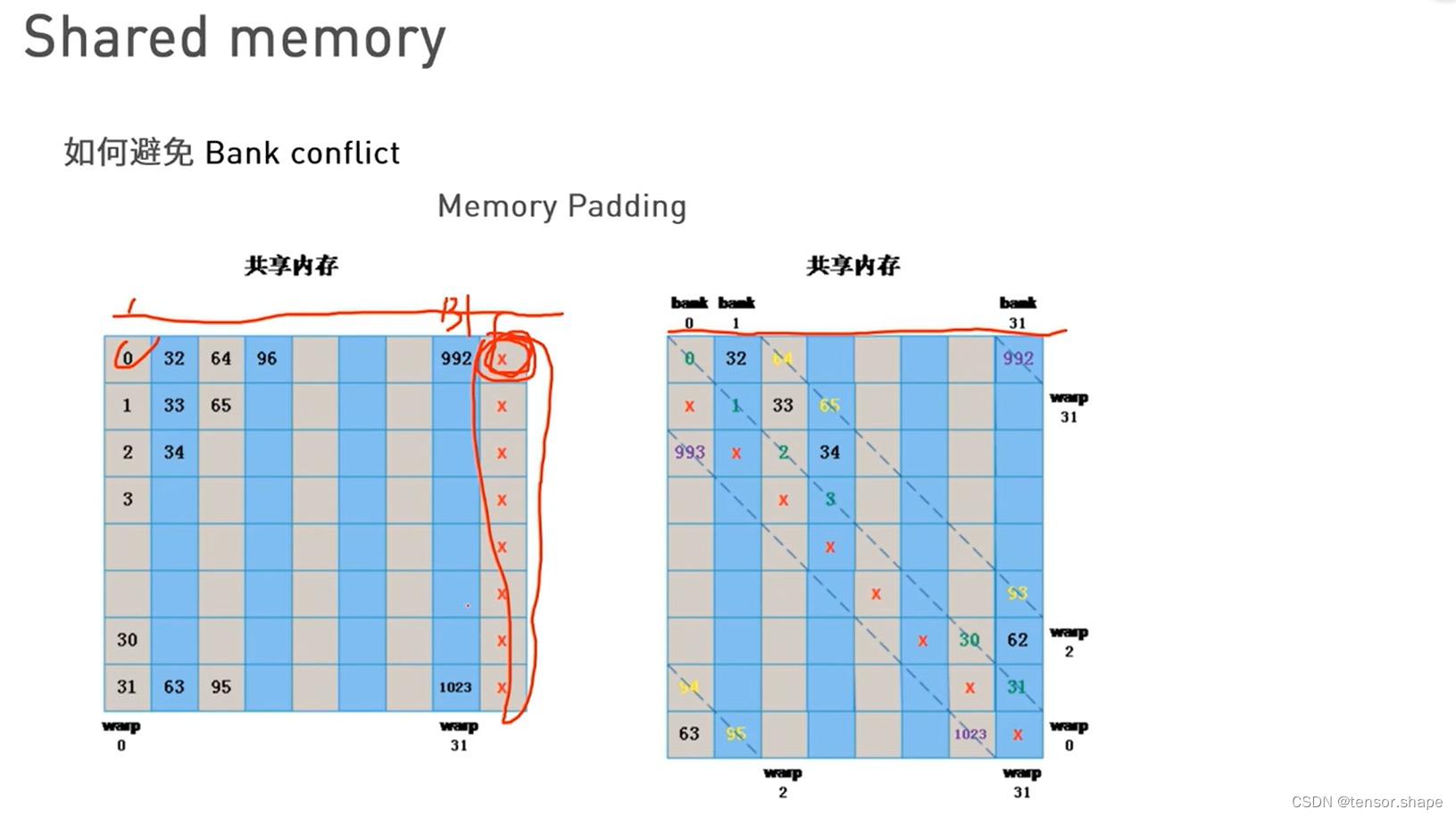
只需加一列,然后错位就行了。
矩阵优化:

参考链接:
https://www.bilibili.com/video/BV1dq4y1k7RD?p=1
https://www.bilibili.com/video/BV17T4y117vK?p=1
《NVIDIA-CUDA-冬令营》
文章来源:https://blog.csdn.net/qq_44576434/article/details/135728880
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 解决git错误:error: failed to push some refs to ‘git xxx xxxx‘
- Java概念性内容:字节码文件和JVM虚拟机、Java的基本命令(java,javac)
- 探索Web开发的未来——使用KendoReact服务器组件
- Arduino开发实例-LoRa通信(基于SX1278 LoRa)
- .NET 弹性和瞬时处理库Polly
- 地图自定义省市区合并展示数据整合
- mysql多表查询
- Ambiq推出语音增强人工智能以消除物联网应用中的噪声
- Leetcode-142:环形链表II
- 【SQL】加快SQL查询的九种优秀实践