2.1.3-数据标准化
跳转到根目录:知行合一:投资篇
已完成:
1、投资&技术
??1.1.1 投资-编程基础-numpy
??1.1.2 投资-编程基础-pandas
??1.2 金融数据处理
??1.3 金融数据可视化
2、投资方法论
??2.1.1 预期年化收益率
??2.1.2 一个关于y=ax+b的故事
??2.1.3-数据标准化
3、投资实证
??[3.1 2023这一年] 被鸽
文章目录
1. 什么是数据标准化?
数据标准化,就是把2个原先无法直接比较的数据,将其进行处理后,可以放在一起比较。
举个例子:
如果我们要比较贵州茅台和券商ETF的收盘价对比,直接对比是无法比较的,价格相差太多了。贵州茅台1600元一股,券商ETF是0.8元一股,画收盘价折线图是不太好画的。
所以,我们需要将2者标准化处理,变成可以在1个图中可以对比的。
2. 数据准备
这里,我们拿沪深300和医药ETF来看怎么做数据标准化。
操作流程相对比较简单:
- 使用qstock获取数据
- 将数据放在一起,拼接成dataframe
- 使用sklearn对dataframe的数据进行标准化处理
import qstock as qs
import pandas as pd
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '512010', 'name': '医药ETF'}
]
# 使用qstock获取数据
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 将数据放在一起,拼接成dataframe
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 使用sklearn对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
print('数据标准化后:\n', z_data)
数据标准化前:
沪深300 医药ETF
date
2012-05-28 2.004 NaN
2012-05-29 2.044 NaN
2012-05-30 2.036 NaN
2012-05-31 2.030 NaN
2012-06-01 2.030 NaN
... ... ...
2024-01-10 3.341 0.386
2024-01-11 3.360 0.390
2024-01-12 3.349 0.384
2024-01-15 3.345 0.385
2024-01-16 3.367 0.385
[2833 rows x 2 columns]
数据标准化后:
沪深300 医药ETF
date
2012-05-28 -1.316805 NaN
2012-05-29 -1.276481 NaN
2012-05-30 -1.284546 NaN
2012-05-31 -1.290595 NaN
2012-06-01 -1.290595 NaN
... ... ...
2024-01-10 0.031019 -0.292433
2024-01-11 0.050172 -0.265917
2024-01-12 0.039083 -0.305691
2024-01-15 0.035051 -0.299062
2024-01-16 0.057229 -0.299062
[2833 rows x 2 columns]
2.1. 拓展一下,仅一列标准化
可以只对一列进行标准化处理吗?答案是可以的。
import qstock as qs
import pandas as pd
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '512010', 'name': '医药ETF'}
]
# 使用qstock获取数据
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 将数据放在一起,拼接成dataframe
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 使用sklearn对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all.iloc[:, 0:2]) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
print('数据标准化后:\n', z_data)
数据标准化前:
沪深300 医药ETF
date
2012-05-28 2.004 NaN
2012-05-29 2.044 NaN
2012-05-30 2.036 NaN
2012-05-31 2.030 NaN
2012-06-01 2.030 NaN
... ... ...
2024-01-10 3.341 0.386
2024-01-11 3.360 0.390
2024-01-12 3.349 0.384
2024-01-15 3.345 0.385
2024-01-16 3.367 0.385
[2833 rows x 2 columns]
数据标准化后:
0
date
2012-05-28 -1.316805
2012-05-29 -1.276481
2012-05-30 -1.284546
2012-05-31 -1.290595
2012-06-01 -1.290595
... ...
2024-01-10 0.031019
2024-01-11 0.050172
2024-01-12 0.039083
2024-01-15 0.035051
2024-01-16 0.057229
[2833 rows x 1 columns]
3. 标准化数据绘图
上面的例子,已经把沪深300和医药ETF数据标准化了,那下面就是画2者的折线图。
import qstock as qs
import pandas as pd
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '512010', 'name': '医药ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
z_data = z_data.round(3)
print('数据标准化后:\n', z_data)
# 将标准化的数据绘图
g=(Line()
.add_xaxis(z_data.index.strftime('%Y-%m-%d').tolist())
.add_yaxis(series_name="沪深300",y_axis=z_data['沪深300'],symbol="circle",is_symbol_show=True,itemstyle_opts={"color": "green"},symbol_size=8)
.add_yaxis(series_name="医药ETF",y_axis=z_data['医药ETF'],symbol="pin",is_symbol_show=True,itemstyle_opts={"color": "red"},symbol_size=8)
)
g.render_notebook()

3.1. 标准化,走势是平移吗?
好像看起来,这2者几乎走势差不多?难道是我们图画错了吗?为了验证,我们直接把沪深300标准化之前和之后的数据,一起画在图上,看看是否有问题。其实只要改一下第2条医药ETF的线的取数,取原先df_all[‘医药ETF’]就行了,完整代码如下:
import qstock as qs
import pandas as pd
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '512010', 'name': '医药ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
z_data = z_data.round(3)
print('数据标准化后:\n', z_data)
# 将标准化的数据绘图
g=(Line()
.add_xaxis(z_data.index.strftime('%Y-%m-%d').tolist())
.add_yaxis(series_name="沪深300标准化后",y_axis=z_data['沪深300'],symbol="circle",is_symbol_show=True,itemstyle_opts={"color": "green"},symbol_size=8)
.add_yaxis(series_name="沪深300标准化前",y_axis=df_all['沪深300'],symbol="pin",is_symbol_show=True,itemstyle_opts={"color": "red"},symbol_size=8)
)
g.render_notebook()

所以可以看出,这个趋势是没有任何的改变的,是可信的。
也就再次证明了我们看到的,沪深300和医药ETF,相关性是很高的。
3.2. 相关性(沪深300和创业板ETF)
我们是否能找一个看起来相关性不高的来验证一下?
之前市场上都有说法,大小盘,那我们就拿沪深300和创业板ETF159915来对比看看?
import qstock as qs
import pandas as pd
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
stocks_info = [
{'code': '510300', 'name': '沪深300'},
{'code': '159915', 'name': '创业板ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
z_data = z_data.round(3)
print('数据标准化后:\n', z_data)
# 将标准化的数据绘图
g=(Line()
.add_xaxis(z_data.index.strftime('%Y-%m-%d').tolist())
.add_yaxis(series_name=stocks_info[0]['name'],y_axis=z_data[stocks_info[0]['name']],symbol="circle",is_symbol_show=True,itemstyle_opts={"color": "green"},symbol_size=8)
.add_yaxis(series_name=stocks_info[1]['name'],y_axis=z_data[stocks_info[1]['name']],symbol="pin",is_symbol_show=True,itemstyle_opts={"color": "red"},symbol_size=8)
)
g.render_notebook()

怎么说呢,没有强烈的反差对比。
之前在可视化文章里,我们算出来黄金和新能源ETF,是相关性不高的,来确认一下。
3.3. 相关性(黄金和新能源ETF)
import qstock as qs
import pandas as pd
#导入pyecharts
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
stocks_info = [
{'code': '518880', 'name': '黄金ETF'},
{'code': '516160', 'name': '新能源ETF'}
]
for stock in stocks_info:
df = qs.get_data(stock['code']) # 从qstock获取对应的股票历史数据
stock['history_df'] = df # 将其存在 history_df 这个key里面。
# 只保留收盘价,合并数据
df_all = pd.DataFrame()
for stock in stocks_info:
df = stock['history_df']
df = df[['close']] # 只需要 date 和 close 2列就行了。
df.rename(columns={'close': stock['name']}, inplace=True) # 用股票的名字来重命名close列
if df_all.size == 0:
df_all = df
else:
df_all = df_all.join(df) # join是按照index来连接的。
print('数据标准化前:\n', df_all) # 取第1列和第2列的方法: df_all.iloc[:, 0:2]
# 对dataframe的数据进行标准化处理
import sklearn
from sklearn import preprocessing
z_scaler = preprocessing.StandardScaler() # 建立 StandardScaler 对象
z_data = z_scaler.fit_transform(df_all) #数据标准化
z_data = pd.DataFrame(z_data) #将数据转为Dataframe
z_data.columns = df_all.columns
z_data.index = df_all.index
z_data = z_data.round(3)
print('数据标准化后:\n', z_data)
# 将标准化的数据绘图
g=(Line()
.add_xaxis(z_data.index.strftime('%Y-%m-%d').tolist())
.add_yaxis(series_name=stocks_info[0]['name'],y_axis=z_data[stocks_info[0]['name']],symbol="circle",is_symbol_show=True,itemstyle_opts={"color": "green"},symbol_size=8)
.add_yaxis(series_name=stocks_info[1]['name'],y_axis=z_data[stocks_info[1]['name']],symbol="pin",is_symbol_show=True,itemstyle_opts={"color": "red"},symbol_size=8)
)
g.render_notebook()
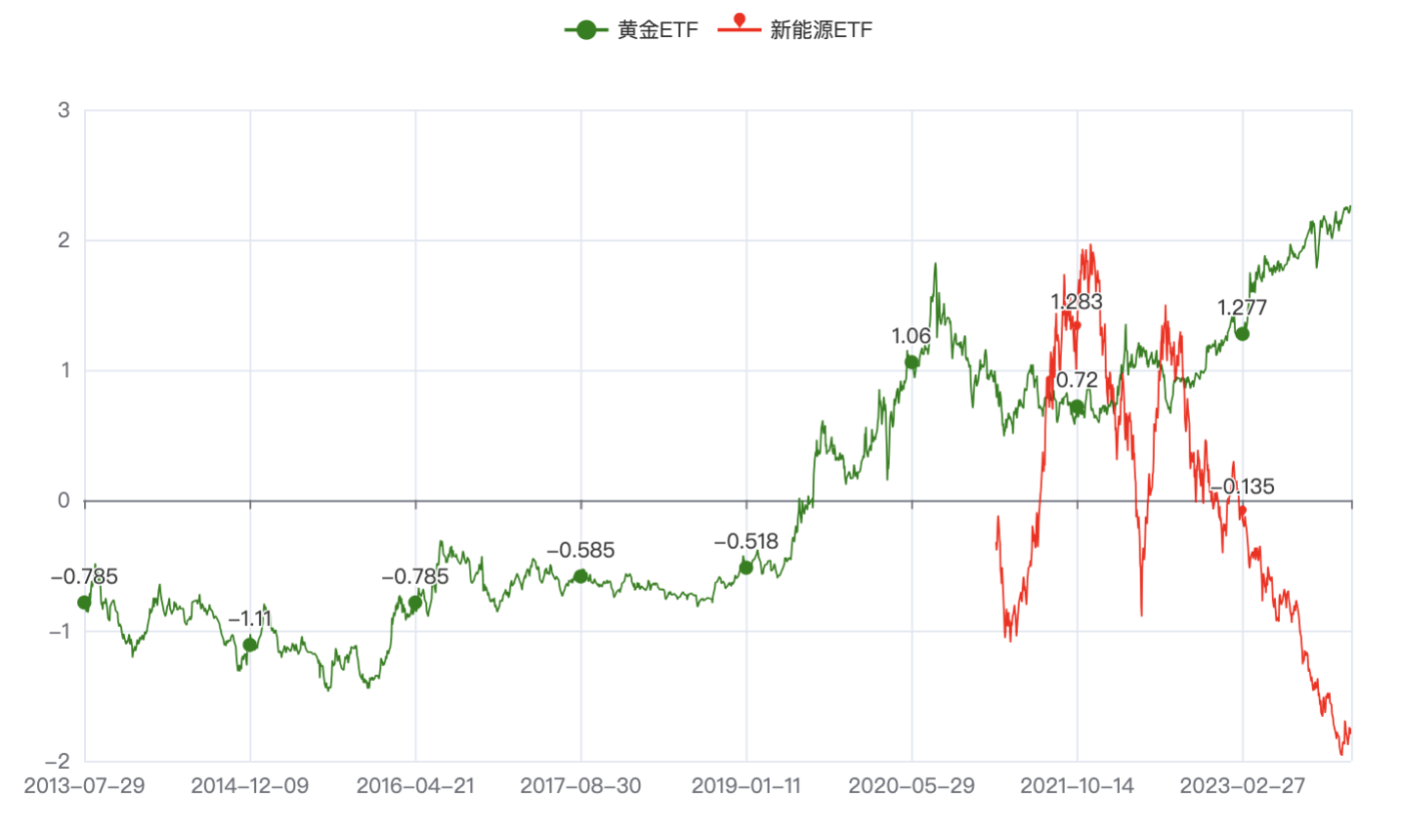
4. 结语
当2个标的由于绝对值偏差比较大而无法放在一起比较的时候,可以使用标准化处理,将数据进行同比例的放大或缩小。
这里用到的是sklearn.preprocessing导入StandardScaler,StandardScaler().fit_transform(df_data),属于数据分析机器学习的内容,后面再继续系统补充这个方面的细节。
进而,就可以放在一起比较直观的去对比数据趋势,从而获得我们想要的结论。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智慧校园统一信息门户平台介绍
- 网络名称解读 -入门4
- 出版时间1月!软考系统集成新教材即将出版!
- python排序
- keil编译报错:No space in execution regions with .ANY selector matching
- 剪映业务的大前端实践:创新以用户需求为导向
- 调用merge函数,实现将指针s所指的字符串的反序和正序连接后形成一个新的字符串并放在原处
- PyQt中的冒号(:)
- POSTGRESQL中ON CONFLICT的使用
- 妙手ERP功能更新:优化各平台描述设置、Ozon去除会员价设置、对接速虎速运.......