Kubernetes API 和流量控制:管理请求数量和排队进程
本文描述了我们最近遇到的一个真实案例:Kubernetes API 因其中一个集群中的大量请求而瘫痪。今天,我们将讨论我们如何处理这个问题,并提供一些关于如何预防它的提示。
高并发搞崩?Kubernetes API
一个非常普通的早晨,我们开始了对 Kubernetes API 的漫长研究,并确定了对它的请求的优先级。我们接到一位技术支持工程师的电话,他报告说客户的集群实际上无法运行(包括生产环境),并说必须采取一些措施。
我们连接到失败的集群,看到 Kube API 服务器已经耗尽了所有内存。它们会崩溃,重新启动,再次崩溃,然后一遍又一遍地重新启动。这最终导致 Kubernetes API 无法访问且完全无法运行。
由于这是一个生产集群,我们通过向控制平面节点添加处理器和内存来实施临时修复。我们一开始添加的资源不足。幸运的是,在下一批资源之后,API 稳定了下来。
寻找问题的根源
首先,我们评估了我们最终必须做出的改变的程度。最初,控制平面节点有 8 个 CPU 和 16 GB RAM。在我们的干预下,它们的大小增加到 16 个 CPU 和 64 GB RAM。
以下是问题发生时的内存消耗图:
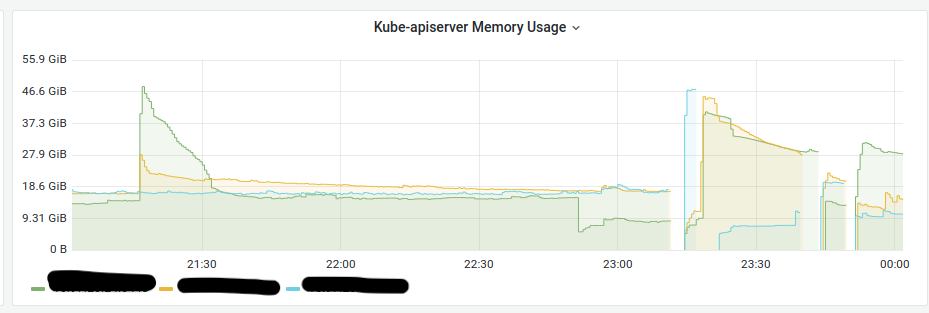
内存消耗高达 50 GB。后来,我们发现,由于某些因素,Cilium pod 正在向 API 大量发送?LIST?请求。由于集群很大,并且有大量的节点(超过 200 个),同时请求会大大增加使用的内存量。
我们与客户达成一致,操作一个测试窗口,重新启动了 Cilium 代理,我们发现以下情况:
- 其中一个 API 服务器上的负载正在增长。
- 它消耗内存。
- 它耗尽了节点上的所有内存。
- 然后崩溃了。
- 请求已重定向到另一台服务器。
- 然后,同样的事情再次发生。
我们认为限制对 API 的并发 cilium-agent 请求的数量是个好主意。在这种情况下,稍微慢一点的 LIST?请求执行不会影响 Cilium 的性能。
解决方案
我们创建了以下内容和清单:FlowSchema?PriorityLevelConfiguration
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- 'cilium.io'
clusterScope: true
namespaces:
- '*'
resources:
- '*'
verbs:
- 'list'
subjects:
- group:
name: system:serviceaccounts:d8-cni-cilium
kind: Group
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue...并将它们部署到集群中。
重新启动 cilium-agent 不再导致显著的内存消耗变化。因此,我们能够将节点资源削减到原始资源。
我们做了什么,这些操作如何帮助消除多个 Kubernetes API 请求时的问题?阅读下面的细分。
在 Kubernetes API 中管理请求
在 Kubernetes 中,请求队列管理由?API 优先级和公平性 (APF)?处理。默认情况下,它在 Kubernetes 1.20 及更高版本中处于启用状态。API 服务器还提供了两个参数,(默认为 400)和(默认为 200),用于限制请求数量。如果启用了 APF,则将这两个参数相加,这就是 API 服务器的总并发限制的定义方式。--max-requests-inflight?--max-mutating-requests-inflight
也就是说,还有一些更精细的细节需要考虑:
- 长时间运行的 API 请求(例如,在 Pod 中查看日志或执行命令)不受 APF 限制的约束,WATCH?请求也不受限制。
- 还有一个特殊的预定义优先级,称为 。来自此级别的请求将立即得到处理。
exempt
APF 确保 Cilium 代理请求不会“限制”用户 API 请求。APF 还允许您设置限制,以确保无论?K8s API 服务器负载如何,重要请求始终得到处理。
您可以使用以下两个资源配置 APF:
PriorityLevelConfiguration这定义了一个可用的优先级。FlowSchema将每个传入请求映射到单个 .PriorityLevelConfiguration
优先级配置
每个都有自己的并发限制(份额)。总并发限制按其份额的比例分配给现有用户。PiorityLevelConfiguration?PriorityLevelConfigurations
让我们按照以下示例计算该限制:
~# kubectl get prioritylevelconfigurations.flowcontrol.apiserver.k8s.io
NAME TYPE ASSUREDCONCURRENCYSHARES QUEUES HANDSIZE QUEUELENGTHLIMIT AGE
catch-all Limited 5 <none> <none> <none> 193d
d8-serviceaccounts Limited 5 32 8 50 53d
deckhouse-pod Limited 10 128 6 50 90d
exempt Exempt <none> <none> <none> <none> 193d
global-default Limited 20 128 6 50 193d
leader-election Limited 10 16 4 50 193d
node-high Limited 40 64 6 50 183d
system Limited 30 64 6 50 193d
workload-high Limited 40 128 6 50 193d
workload-low Limited 100 128 6 50 193d- 首先,将所有(260)相加。
AssuredConcurrencyShares - 现在,计算请求限制,例如,优先级:(400+200)/260*100 = 每秒 230 个请求。
workload-low
让我们更改其中一个值,看看会发生什么。例如,让我们从 10 增加到 100。请求限制将降至 (400+200)/350*100 = 每秒 171 个请求。AssuredConcurrencyShares?deckhouse-pod
通过增加?AssuredConcurrencyShares?数量,我们增加了特定级别的查询限制,但降低了所有其他级别的查询限制。
如果优先级中的请求数大于允许的限制,则请求将排队。您可以选择自定义队列参数。您还可以将 APF 配置为立即丢弃超出特定优先级限制的请求。
让我们看一下下面的例子:
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: PriorityLevelConfiguration
metadata:
name: cilium-pods
spec:
type: Limited
limited:
assuredConcurrencyShares: 5
limitResponse:
queuing:
handSize: 4
queueLengthLimit: 50
queues: 16
type: Queue在这里,优先级配置为具有 .如果没有其他自定义优先级,则每秒会产生 12 个请求。请求队列设置为 200 个请求 (),并创建 16 个内部队列,以便更均匀地分配来自不同代理的请求。AssuredConcurrencyShares = 5?handSize * queueLengthLimit
关于 K8s 流量控制中优先级配置的一些重要细节:
- 拥有更多队列可减少流之间的冲突次数,但会增加内存使用量。将其设置为禁用公平性逻辑,但仍允许对请求进行排队。
1 - 增加渲染,可以在不忽略单个请求的情况下处理高流量突发。但是,查询的处理速度较慢,并且需要更多的内存。
queueLengthLimit - 通过更改 ,可以调整流之间发生冲突的可能性,以及在高负载情况下单个流可用的整体并发性。
handSize
这些参数是通过实验选择的:
- 一方面,我们需要确保此优先级的请求不会处理得太慢。
- 另一方面,我们需要确保 API 服务器不会因突然的流量峰值而过载。
流架构
现在让我们继续讨论资源。它的作用是将请求映射到相应的 .FlowSchemaPriorityLevel
其主要参数有:
matchingPrecedence:定义应用顺序。数字越小,优先级越高。这样,您就可以从更具体的案例到更一般的案例编写重叠。FlowSchemaFlowSchemasrules:定义请求过滤规则;格式与 Kubernetes RBAC 中的格式相同。distinguisherMethod:指定一个参数(用户或命名空间),用于在将请求转发到优先级时将请求分成流。如果省略该参数,则所有请求都将分配给同一流。
例:
---
apiVersion: flowcontrol.apiserver.k8s.io/v1beta1
kind: FlowSchema
metadata:
name: cilium-pods
spec:
distinguisherMethod:
type: ByUser
matchingPrecedence: 1000
priorityLevelConfiguration:
name: cilium-pods
rules:
- resourceRules:
- apiGroups:
- 'cilium.io'
clusterScope: true
namespaces:
- '*'
resources:
- '*'
verbs:
- 'list'
subjects:
- group:
name: system:serviceaccounts:d8-cni-cilium
kind: Group在上面的示例中,我们选取了所有?LIST?请求,包括集群范围的请求以及从所有命名空间发送到所有资源的请求。主题包括来自服务帐户的所有请求。apiGroup: cilium.io?d8-cni-cilium
我如何找出请求所在的位置和请求?FlowSchema?PriorityLevelConfiguration
响应时,API 服务器会提供特殊标头 X-Kubernetes-PF-FlowSchema-UID 和?X-Kubernetes-PF-PriorityLevel-UID。您可以使用它们来查看请求的去向。
例如,让我们从 Cilium 代理的服务帐户向 API 发出请求:
TOKEN=$(kubectl -n d8-cni-cilium get secrets agent-token-45s7n -o json | jq -r .data.token | base64 -d)
curl https://127.0.0.1:6445/apis/cilium.io/v2/ciliumclusterwidenetworkpolicies?limit=500 -X GET --header "Authorization: Bearer $TOKEN" -k -I
HTTP/2 200
audit-id: 4f647505-8581-4a99-8e4c-f3f4322f79fe
cache-control: no-cache, private
content-type: application/json
x-kubernetes-pf-flowschema-uid: 7f0afa35-07c3-4601-b92c-dfe7e74780f8
x-kubernetes-pf-prioritylevel-uid: df8f409a-ebe7-4d54-9f21-1f2a6bee2e81
content-length: 173
date: Sun, 26 Mar 2023 17:45:02 GMT
kubectl get flowschemas -o custom-columns="uid:{metadata.uid},name:{metadata.name}" | grep 7f0afa35-07c3-4601-b92c-dfe7e74780f8
7f0afa35-07c3-4601-b92c-dfe7e74780f8 d8-serviceaccounts
kubectl get prioritylevelconfiguration -o custom-columns="uid:{metadata.uid},name:{metadata.name}" | grep df8f409a-ebe7-4d54-9f21-1f2a6bee2e81
df8f409a-ebe7-4d54-9f21-1f2a6bee2e81 d8-serviceaccounts输出显示请求属于?d8-serviceaccounts?和?d8-serviceaccounts?。FlowSchema?PriorityLevelConfiguration
需要关注的指标
Kubernetes API 提供了几个有用的指标来关注:
Apiserver_flowcontrol_rejected_requests_total:被拒绝的请求总数。Apiserver_current_inqueue_requests:队列中当前的请求数量。Apiserver_flowcontrol_request_execution_seconds:请求执行时间。
一些调试终结点也可能有助于获取有用的信息:
kubectl get --raw /debug/api_priority_and_fairness/dump_priority_levels
PriorityLevelName, ActiveQueues, IsIdle, IsQuiescing, WaitingRequests, ExecutingRequests
system, 0, true, false, 0, 0
workload-high, 0, true, false, 0, 0
catch-all, 0, true, false, 0, 0
exempt, <none>, <none>, <none>, <none>, <none>
d8-serviceaccounts, 0, true, false, 0, 0
deckhouse-pod, 0, true, false, 0, 0
node-high, 0, true, false, 0, 0
global-default, 0, true, false, 0, 0
leader-election, 0, true, false, 0, 0
workload-low, 0, true, false, 0, 0
kubectl get --raw /debug/api_priority_and_fairness/dump_queues
PriorityLevelName, Index, PendingRequests, ExecutingRequests, SeatsInUse, NextDispatchR, InitialSeatsSum, MaxSeatsSum, TotalWorkSum
exempt, <none>, <none>, <none>, <none>, <none>, <none>, <none>, <none>
d8-serviceaccounts, 0, 0, 0, 0, 71194.55330547ss, 0, 0, 0.00000000ss
d8-serviceaccounts, 1, 0, 0, 0, 71195.15951496ss, 0, 0, 0.00000000ss
...
global-default, 125, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ss
global-default, 126, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ss
global-default, 127, 0, 0, 0, 0.00000000ss, 0, 0, 0.00000000ss结论
我们最终通过设置请求队列管理解决了我们的问题。需要注意的是,这并不是我们在实践中遇到的唯一这种情况。在多次需要限制 API 请求之后,我们将 APF 配置作为 Kubernetes 平台的重要组成部分。利用它可以帮助我们和我们的客户减少大型、高负载 Kubernetes 集群中的 API 拥塞问题的数量。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!