大模型+时空预测25篇高分论文分享,附开源数据集下载
面向时空数据的大模型是一类专门设计用于分析和挖掘时间序列和时空数据的复杂模型,它们不仅能够提高数据分析的效率和准确性,还能够在多个领域内发现有价值的信息,增强跨多个领域的模式识别和推理能力。
这次我就从大模型中的大语言模型LLMs和预训练基础模型PFMs两大主流方向入手,帮大家回顾总结面向时空数据的大模型相关研究,分为时空图、时态知识图和视频数据三个子方向。
另外,新的一年出现了很多更全面数据集和工具,我们做大模型研究自然是离不开数据集的,所以在论文梳理之外,我还给大家按主流应用分类整理了很多数据集,包含了金融、天气、交通等领域。
论文+代码+数据集需要的同学看文末
时空数据的LLMs
时空图
1.Language knowledgeassisted representation learning for skeleton-based action recognition
基于骨架的动作识别的语言知识辅助表示学习
「简述:」人类识别他人行为涉及复杂的认知和神经机制。研究表明,大脑特定区域负责处理动作信息和意图。基于骨架的动作识别是利用骨架运动模式来识别行为的方法。虽然现有技术取得了良好效果,但很少考虑结合先验知识来提高性能。LA-GCN是一个图卷积网络,它利用大规模语言模型的知识辅助进行动作识别。这种方法强调数据中的关键信息,并模拟大脑区域中的类别先验知识来学习有区分度的特征。此外,LA-GCN还提出了一种多跳注意力图卷积,以提高信息传递效率。在多个数据集上,LA-GCN达到了最先进的性能水平。

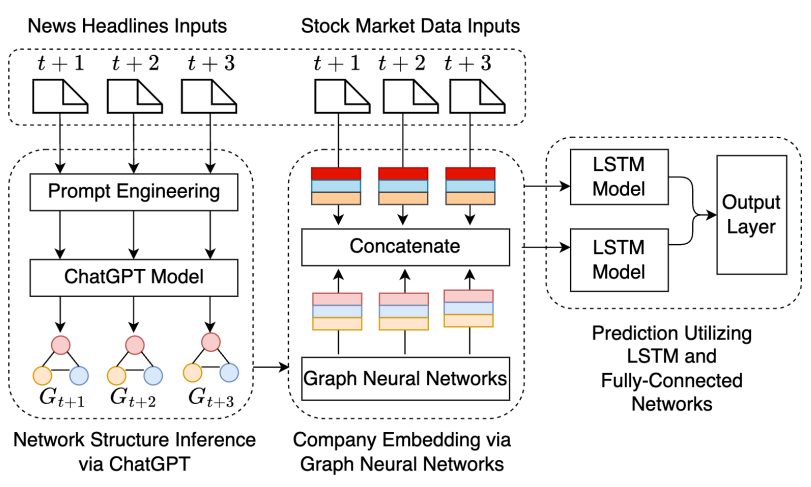
2.Chatgpt informed graph neural network for stock movement prediction
股票走势预测的图神经网络
「简述:」研究团队开发了一个新的模型,这个模型使用ChatGPT从财经新闻文本中推断出股票之间的关系网络,并将这些信息用于图神经网络来预测股票价格的变动。结果表明,该模型在预测股票走势方面比现有的最好深度学习模型表现得更好,并且基于该模型构建的投资组合取得了更高的收益和更低的风险。这说明了ChatGPT在理解和分析文本数据中的潜力,尤其是在金融领域中的应用前景。
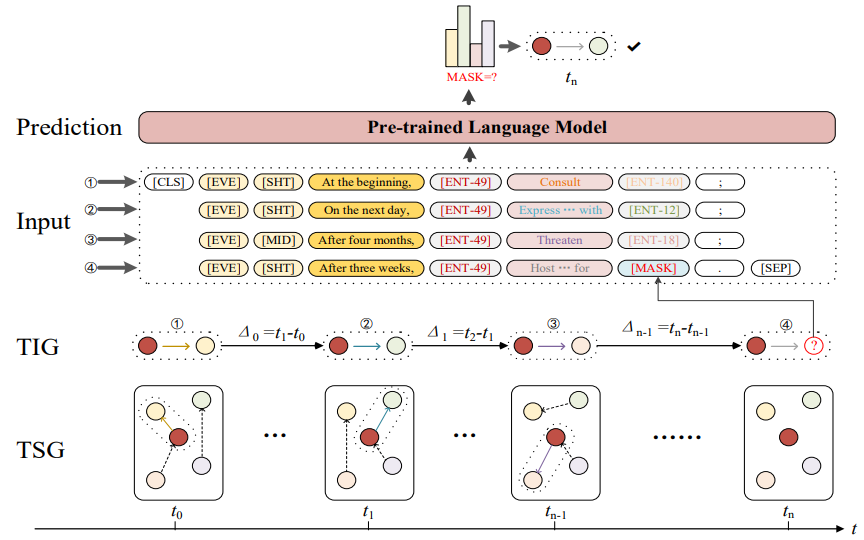
时序知识图谱
3.Pre-trained language model with prompts for temporal knowledge graph completion
具有时间知识图谱完成提示的预训练语言模型
「简述:」论文提出了一个新模型,叫做带有提示的预训练语言模型(PPT),用于完成时序知识图谱中缺失的信息。这个模型通过将时间信息转换成语言模型可以理解的形式,并利用预训练语言模型中的语义信息来提高预测准确性。实验结果表明,与其他模型相比,PPT模型在四个评估指标上表现更好,有效地利用了时间知识图谱的信息。
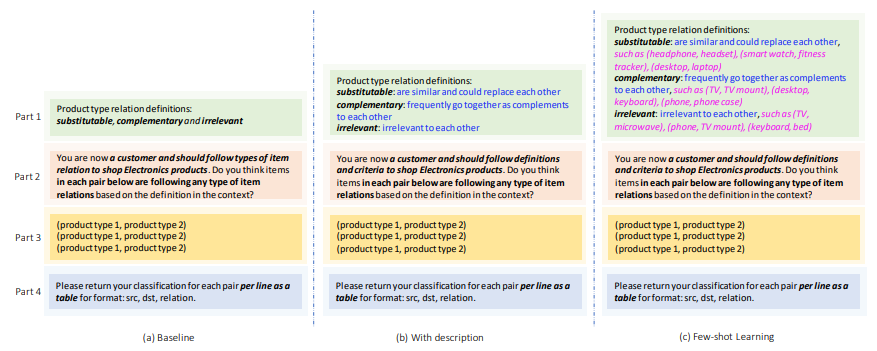
4.Knowledge graph completion models are few-shot learners: An empirical study of relation labeling in e-commerce with llms
使用大型语言模型在电子商务中进行关系标注的实证研究
「简述:」知识图谱在电商中非常重要,因为它提供了关于产品和它们之间的关系的信息。但标注这些关系很费时和费力。最近的大型语言模型(LLMs)在很多任务中都表现得很好。作者研究了这些模型在电商知识图谱的关系标注上的表现,发现它们只需要很少的标注数据就能做得很好。作者还发现,使用不同的提示工程技术可以进一步提高它们的性能。总的来说,LLMs在电商知识图谱的关系标注上表现得非常好,甚至可以取代人工标注。
5.Temporal knowledge graph forecasting without knowledge using incontext learning
使用上下文学习进行无知识的时间知识图谱预测
「简述:」本文研究了如何使用大型语言模型(LLMs)来预测时序知识图谱中未来的事实。通过将历史事实转换成提示,并用这些提示来生成预测,作者们发现,即使不进行专门的训练或调整,这些现成的LLMs也能与专门为时序知识图谱预测设计并训练的模型表现相当。此外,隐藏实体和关系的语义信息对性能影响不大,表明LLMs能够利用上下文中的模式来进行预测,而不需要依赖明确的语义知识。
视频任务
6.Vid2seq: Large-scale pretraining of a visual language model for dense video captioning
用于密集视频字幕的视觉语言模型的大规模预训练
「简述:」论文开发了一个叫做Vid2Seq的新模型,用于自动给视频生成详细字幕。这个模型通过预训练处理大量带解说的视频数据,能够同时识别视频中的事件并给出文字描述。实验结果显示,Vid2Seq在多个视频字幕基准测试中都取得了最好的成绩,并且还能很好地适应不同类型的视频字幕任务和少样本学习场景。

-
Zero-shot video question answering via frozen bidirectional language models
-
Retrieving-to-answer: Zero-shot video question answering with frozen large language models
-
Videochat: Chat-centric video understanding
-
Moviechat: From dense token to sparse memory for long video understanding
-
Language models are causal knowledge extractors for zero-shot video question answering
-
Language models with image descriptors are strong few-shot video-language learners
时空数据的PFMs
时空图
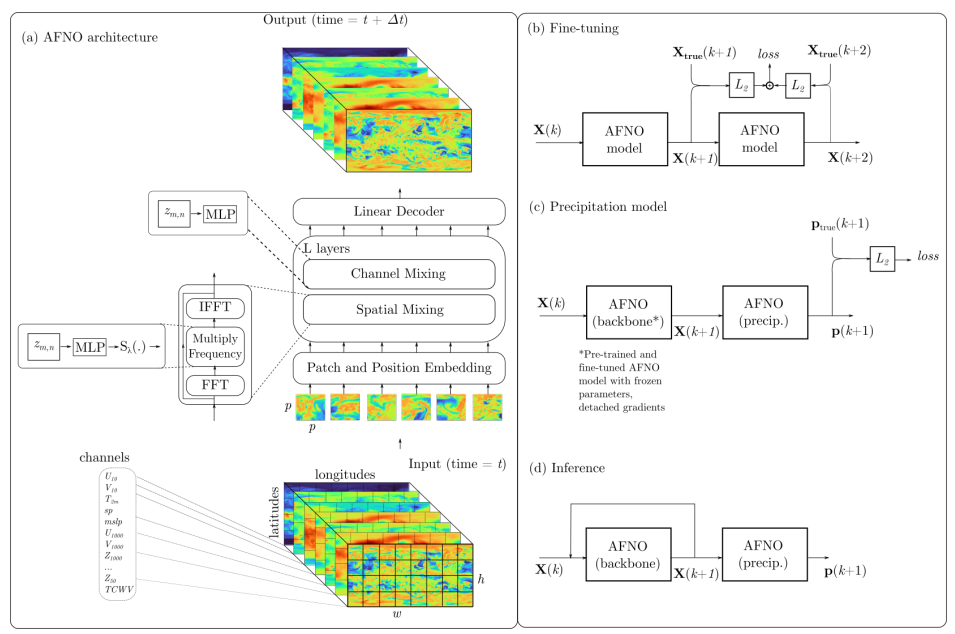
1.Fourcastnet: A global data-driven high-resolution weather model using adaptive fourier neural operators
使用自适应傅里叶神经算子的全球数据驱动高分辨率天气模型
「简述:」FourCastNet是一个全球性的天气预报模型,它能快速准确地预测天气情况。这个模型特别擅长预测风速、降雨和水汽等小尺度、变化快的天气变量。它的预报速度非常快,可以在几秒钟内做出一周的预报,而且准确度很高。这对于规划能源使用和预测极端天气事件非常有用。FourCastNet模型可以作为传统数值天气预报模型的一个很好的补充工具。
-
Prompt federated learning for weather forecasting: Toward foundation models on meteorological data
-
Spatialtemporal prompt learning for federated weather forecasting
-
Climax: A foundation model for weather and climate
-
FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead
-
Accurate medium-range global weather forecasting with 3d neural networks
-
W-mae: Pre-trained weather model with masked autoencoder for multi-variable weather forecasting
-
Pre-trained bidirectional temporal representation for crowd flows prediction in regular region
-
Building transportation foundation model via generative graph transformer
视频任务
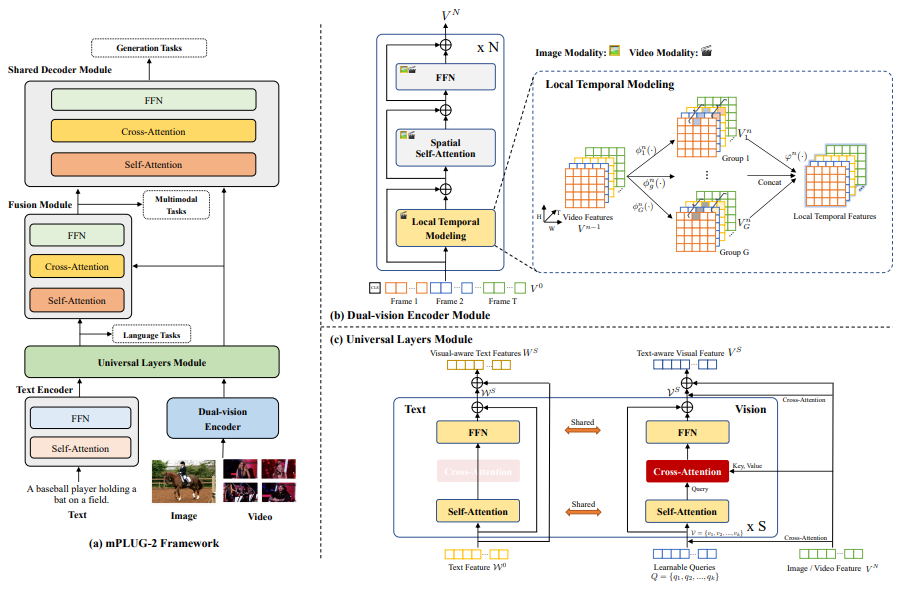
10.mplug-2: A modularized multi-modal foundation model across text, image and video
一种模块化的多模态基础模型,涵盖文本、图像和视频
「简述:」mPLUG-2是一个新型的多模态预训练模型,它可以处理文本、图像和视频。这个模型的特点是模块化设计,可以灵活地组合不同模块来完成不同的任务,比如理解图片和文字或者生成视频描述。实验显示,mPLUG-2在很多不同类型的任务上都取得了很好的效果,包括理解图像和文字、生成视频描述等。而且,即使在数据量较小的情况下,它也能达到很高的准确率和生成质量。
-
Omnivl: One foundation model for image-language and video-language tasks
-
Youku-mplug: A 10 million large-scale chinese video-language dataset for pre-training and benchmarks
-
Paxion: Patching action knowledge in video-language foundation models
常见数据集、模型和工具
交通
1.TaxiNYC
统计数据:22349490 taxi trips in 2015
论文:Revisiting Spatial-Temporal Similarity: A Deep Learning Framework for Traffic Prediction
天气
2.SEVIR
统计数据:10000
论文:Sevir: A storm event imagery dataset for deep learning applications in radar and satellite meteorology
金融
3.Finance (Employment)
统计数据:15321
论文:Aa-forecast: Anomaly-aware forecast for extreme events
视频
4.MSR-VTI
统计数据:10,000 video clips
论文:Msr-vtt: A large video description dataset for bridging video and language
5.WebVid
统计数据:10 million video clips
论文:Frozen in time: A joint video and image encoder for end-to-end retrieval
6.DiDeMo
统计数据: 26,892 moments
论文:Localizing moments in video with natural language
其他
7.Alibaba Cluster Trace
统计数据:1313 machines
论文:Characterizing co-located datacenter workloads: An alibaba case study
8.LargeST
包括加州总数8,600个传感器,覆盖时间为5年,并包括全面的元数据。
论文:LargeST: A Benchmark Dataset for Large-Scale Traffic Forecasting
9.LaDe
包含数以百万计的真实包裹数据
论文:LaDe: The First Comprehensive Last-mile Delivery Dataset from Industry
10.SynMob
一个高保真的合成轨迹数据集
论文:SynMob: Creating High-Fidelity Synthetic GPS Trajectory Dataset for Urban Mobility Analysis
关注下方《学姐带你玩AI》🚀🚀🚀
回复“时空大模型”获取论文+代码+数据集
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于FPGA的万兆以太网学习(1)
- 资产管理:打造全面、高效的资产管理体系
- <软考高项备考>《论文专题 - 55 进度管理(6) 》
- 论数据资源持有权(上)
- 设计模式之-桥梁模式,快速掌握桥梁模式,通俗易懂的讲解桥梁模式以及它的使用场景
- linux装NVIDIA驱动详细教程
- Python - 深夜数据结构与算法之 Recursion
- CentOS 6 制作openssh 9.6 p1 rpm包(含ssh-copy-id、openssl) —— 筑梦之路
- 从有向带权图判断最短路径里各目标顶点顺序
- Null和undefined区别