BloombergGPT—金融领域大模型
背景
GPT-3的发布证明了训练非常大的自回归语言模型(LLM)的强大优势。GPT-3有1750亿个参数,比以前的GPT-2模型增加了一百倍,并且在现在流行的一系列LLM任务中表现出色,包括阅读理解、开放式问答和代码生成。
在GPT-3之后,模型的规模逐渐增加到2800亿、5400亿和1万亿参数。工作还探讨了实现高性能LLM的其他重要方面,如不同的训练目标、优化多语言模型、寻找更高效和更小的模型,以及寻找数据和参数最优化的训练规模。
这些工作几乎完全集中在一般LLM(通用LLM)上,这种模型在涵盖广泛主题和领域的数据集上进行培训。虽然这些数据集包括一些专门领域的数据集(例如,代码或生物医学文章),但模型训练重点仍然是构建具有广泛能力的LLM。最近,仅使用特定领域数据训练模型的工作已经产生了一些成果,这些模型虽然小得多,但在这些领域内的任务上击败了通用LLM,例如科学和医学。这些发现推动了专注于特定领域的模型的进一步发展。
金融科技(FinTech)是一个庞大且不断发展的领域,NLP技术发挥着越来越重要的作用。金融NLP任务包括情绪分析、命名实体识别、新闻分类以及人机问答等。虽然任务范围与一般NLP基准中的任务范围相似,但金融领域的复杂性和特定术语需要适用于特定领域的系统。出于所有这些原因,将LLM专注于金融领域将是有价值的。
BloombergGPT
BloombergGPT来自于彭博社(Bloomberg)和约翰霍普金斯大学的Shijie Wu等人在2023年3月30日公开在arXiv的一篇文章:BloombergGPT: A Large Language Model for Finance,全文共76页。彭博社,是全球商业、金融信息和财经资讯的领先提供商,是一家资讯公司。
BloombergGPT是一个拥有500亿参数的语言模型,其训练主要是使用大规模的金融财务数据,即基于彭博社的广泛数据源构建了3630亿个标签的特有数据集(363 billion token dataset),这可能是迄今为止最大的特定领域数据集,并增加了3450亿个标签的通用数据集的数据,总数据量多达7000亿。
数据集
BloombergGPT采用将金融领域数据集和通用数据集混合构建的方式,使得模型兼具通用能力和特定领域任务的能力。
作者将数据集命名为FinPile,其中金融领域的数据是由一系列英文金融信息组成,包括新闻、文件、新闻稿、网络爬取的金融文件以及提取到的社交媒体消息。通用数据集包含如The Pile、C4和Wikipedia。FinPile的训练数据集中大约一半是特定领域的文本,一半是通用文本。为了提高数据质量,每个数据集都进行了去重处理。
金融领域数据集
金融领域数据集共包含了3630亿个token,占总数据集token量的54.2%,具体由以下几个部分构成:
金融领域相关网页,2980亿token,占比42.01%;
金融领域知名新闻源,380亿token,占比5.31%;
公司财报,140亿token,占比2.04%;
金融相关公司的出版物,90亿token,占比1.21%;
bloomberg,50亿token,占比0.7%。
因为包含一部分收费和私有数据,所以这份数据集不会被公开。
通用数据集
通用数据集共包含了3450亿个token,占总数据集token量的48.73%,具体分为如下几个部分:
- The Pile数据集,1840亿token,占比25.9%;
- C4数据集,1380亿token,占比19.48%;
- Wikipedia数据集,240亿token,占比3.35%。
其中,The Pile 数据集是一个 825 GiB 多样化的开源语言建模数据集。其构成如下表,其中从Pile-CC是从Common Craw获取的网页数据,占比约18%,高质量数据占比越82%。
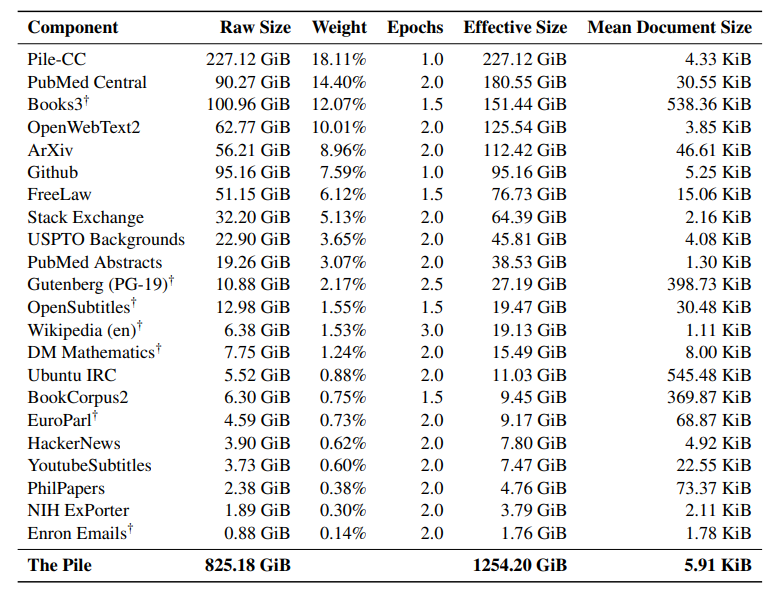
Common Crawl 是一个海量的、非结构化的、多语言的网页数据集。它包含了超过 8 年的网络爬虫数据集,包含原始网页数据(WARC)、元数据(WAT)和文本提取(WET),拥有PB级规模,可从 Amazon S3 上免费获取。下载地址:http://commoncrawl.org/the-data/get-started/
Colossal Clean crawl Corpus (C4)是一个用于训练大模型的常用数据集引入支持训练T5。虽然它和Pile-CC有重叠的部分,但C4的清洗和处理方式不同,因此具有很高的质量。
Wikipedia数据集:The Pile和C4都包含一些过时的维基百科的副本,所以包含最新维基百科页面的数据对模型的真实性可能是有好处的。因此,又选用了包括2022年7月1日起的英文维基百科数据。
分词
数据集使用Unigram tokenizer对原始文本进行tokenize。作者进行了两点改进:
- 在pre tokenization这一步,将数字视为单个token,并且允许词组的存在,以提高信息密度减少句子长度(参考了PaLM的处理方式);
- 由于在整个Pile数据集上使用Unigram tokenizer进行分词会比较低效,因此使用分治的思想(先分割处理后进行合并)优化Unigram tokenizer在大数据集上的实现,将Pile中22个领域分别拆分为256个大小基本相同的块。然后在22个领域的256个(共5632个)块的每一个上训练一个词汇量为65,536(
2
16
2^{16}
216) 的Unigram tokenizer,最后对这些词表进行合并,并将最终词表大小控制在13万这个数量级上。
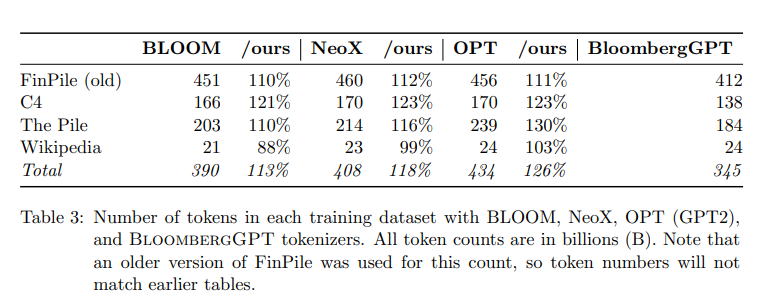
Byte Pair Encoding(字节对编码):就是寻找经常出现在一起的Byte对,合并成一个新的Byte加入词汇库中。
WordPiece算法
WordPiece算法可以看作是BPE的变种。**Google的Bert模型在分词的时候使用的是WordPiece算法。**不同点在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大的相邻子词加入词表。
- 准备足够大的训练语料
- 确定期望的subword词表大小
- 将单词拆分成字符序列
- 基于第3步数据训练语言模型
- 从所有可能的subword单元中选择加入语言模型后能最大程度地增加训练数据概率的单元作为新的单元
- 重复第5步直到达到第2步设定的subword词表大小或概率增量低于某一阈值。
Unigram Language Model (ULM)
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
SentencePiece算法
把一个句子看作一个整体,再拆分成片段,没有保留天然的词语的概念。把空格space当做一种特殊字符来处理,再用BPE或者Unigram算法来构造词表。
比如,XLNetTokenizer就采用了_来代替空格,解码的时候会再用空格替换回来。
目前,Tokenizers库中,所有使用了SentencePiece的都是与Unigram算法联合使用的,比如ALBERT、XLNet、Marian和T5。
模型
模型结构
模型基于BLOOM模型的自回归结构(decoder-only causal language model based on BLOOM),具体包含了70层transformer decoder。
- 前馈层(FFN)中的非线性函数采用GELU
- 位置编码采用ALiBi编码
- 模型在第一层多了一个layer normalization
模型相关参数
整个训练过程是在64台8卡的A100 GPU(40G显存)上进行的,一共花费了约130万美元,模型相关参数如下:
transformer decoder的层数:70
注意力层多头的头数:40
每个头的纬度:192
词表大小:131072
隐藏层维度:7680
模型参数量:500亿
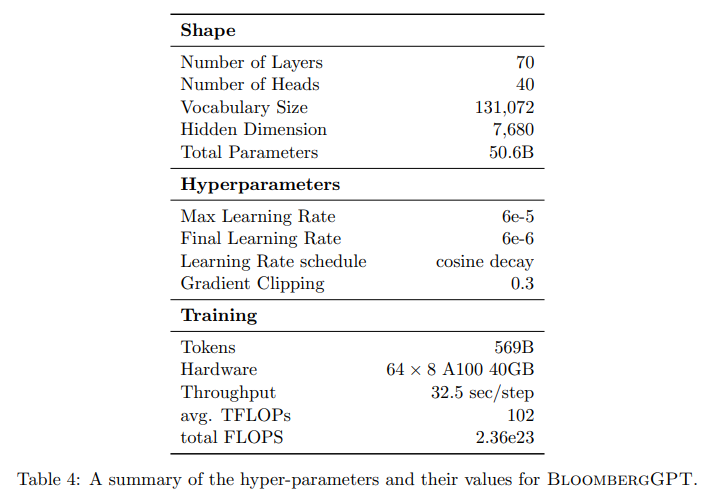
训练配置
- 作者在每篇文档的最后添加了特殊标记<|endoftext|>,模型训练时选取的句子长度为2048token
- 训练时采用的优化方法是AdamW,beta1、beta2、weight decay取值分别为0.9、0.95、0.1,初始学习率为6e-5,采用cosine衰减、线性warmup方式
- 模型参数随机初始化为均值0、标准差0.006588的正态分布,并对MLP的第二层和注意力层输出进行缩放
- 关于训练的不稳定性,文章中没有描述训练BloombergGPT时采用的方法,只是介绍了相关进展
- 关于计算使用到的硬件,使用了64个AWS的p4d.24xlarge实例,每个p4d.24xlarge实例包含了8块40GB的A100GPU
训练过程
训练使用AWS提供的AmazonSageMaker来训练和评估BloombergGPT,并在总共64个p4d.24xlarge实例上进行训练。每个p4d.24xlarge实例都有8个NVIDIA 40GB A100 GPU,这总共产生512个40GB A100 GPU。为了快速访问数据,还使用Amazon FSX For Lustre,它支持每个TiB存储单元高达1000 MB/s的读写吞吐量。
损失函数随训练步数变化曲线如下图:
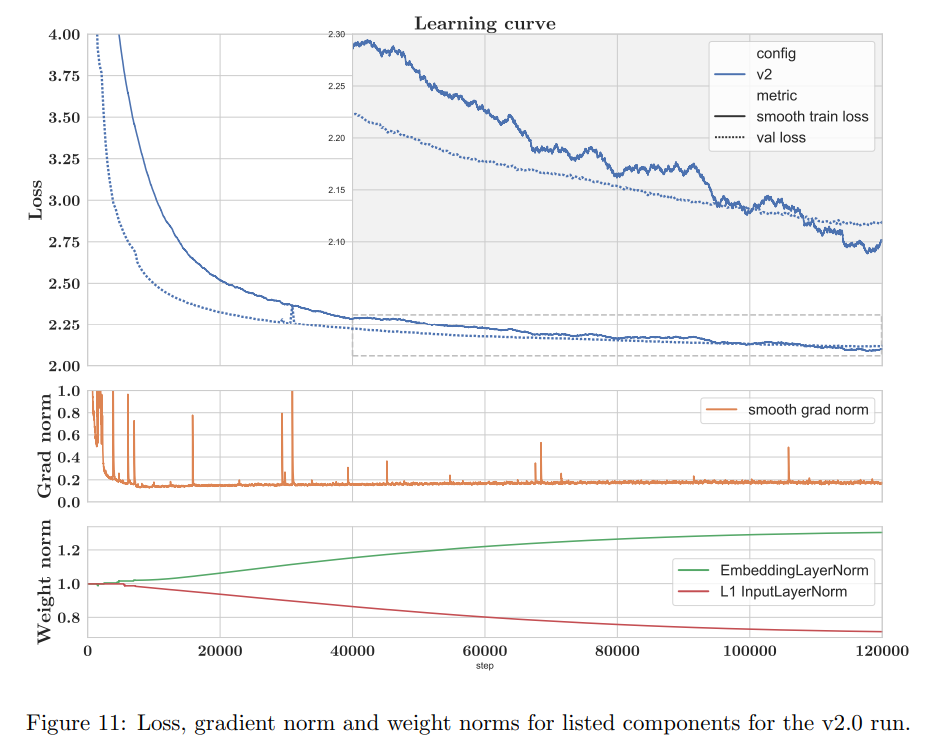
模型共训练了139,200步,进行了约0.8个epoch,训练了53天。
一个epoch都没有训练完的原因是这时验证集上的损失函数已经不再继续下降了。
具体训练过程如下:
- 初始训练的batch size大小为1024,warm-up过程持续了7200步,随后作者将batch size修改为2048。
- 115,500步之后,验证集上的损失不再下降,然后作者将学习率缩小为原始的2/3;
- 129,900步之后,学习率缩小为之前的1/2,同时增加dropout
- 137,100步之后,学习率再次缩小为之前的1/2
- 最终,训练在146,000步结束。作者选取139,200这一步的模型最为最终使用的模型。
模型评估
评估任务分布
对BloombergGPT的评估分成了两部分:金融领域任务与通用任务。这样做的目的也比较直观,就是验证在特定领域预训练后的模型能够在特定领域表现好,同时在通用领域的表现也不会差太多这一观点。
金融特定任务有助于检验假设,即对高质量金融特定数据进行训练将在金融任务中产生更好的结果。通用任务主要评估模型的性能是否与之前公布的结果直接可比。
对于金融相关的任务,分别收集了公开可用的金融数据任务,我们还包括了从Bloomberg内部高质量评估集中提取的任务,如用于情绪分析和命名实体识别等。对于通用任务,我们从多个现有的基准和小组结果中得出以下类别:BIG bench Hard、知识评估、阅读理解和语言任务。每种类型的任务数量和组的定义如下表所示。
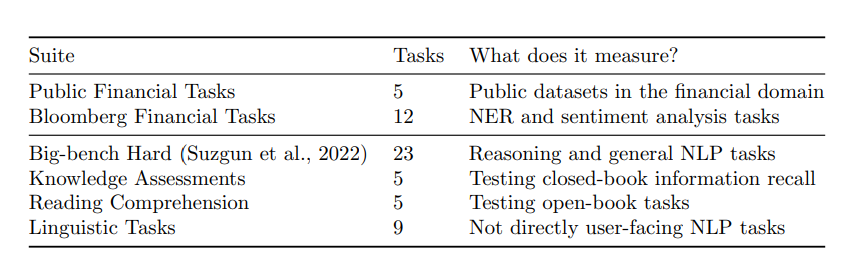
模型对比
对比了BloombergGPT、GPT-NeoX、OPT、BLOOM、GPT-3在不同任务上的表现。注意,这里因为GPT-3模型无法获取,故仅在部分通用任务上进行了评测。
各个模型使用到的token数量、参数数量、计算量如下:
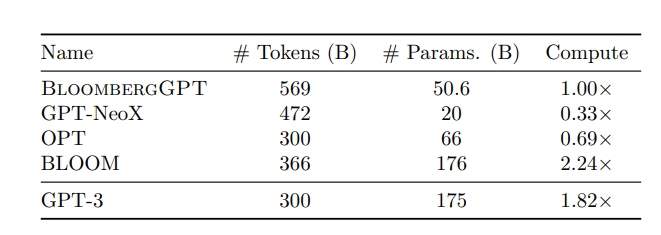
作者对每一个模型均独立进行了评测,并且在每一个任务中使用相同的标准prompt、相同的样例、不使用任务描述和任何CoT prompt,以保证评测结果的公平性。
对于有多个答案的任务,文章中采用了**基于似然的分类方法(likelihood-based classification)进行评估;对于其他任务,文章采用贪心解码(greedy decoding)**的方式进行评估。
holdout loss
作者首先在FinPile数据集预留的部分样本上对各个模型进行了bits per byte的评估。
bits per byte指标是评估语言模型的一种常见指标,类似于perplexity,取值越小,模型越好。具体计算方法可见**How to compute bits per character (BPC)?**
各个模型在各个类型的数据上的bits per byte值如下:
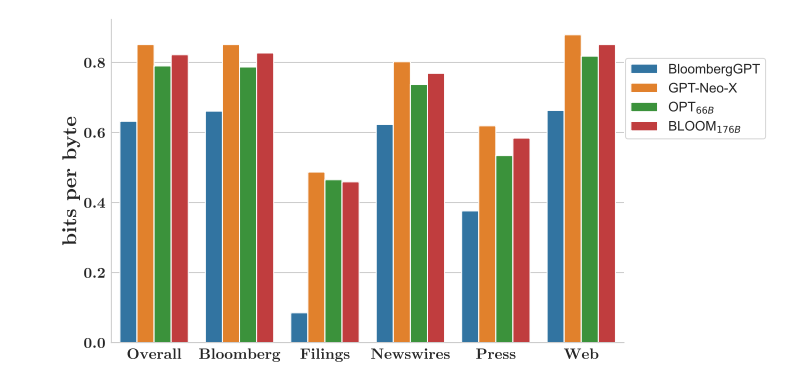
可以看出,BloombergGPT在金融语料上的bits per byte均好于其他模型,并且在财报(Filings)这个类别上表现尤其突出。这个结果也符合预期。否则可能就没有后面任务对比的必要了。
金融领域评估
金融领域任务共有6种类型,3种判别式任务、3种生成式任务。具体任务的格式如下:
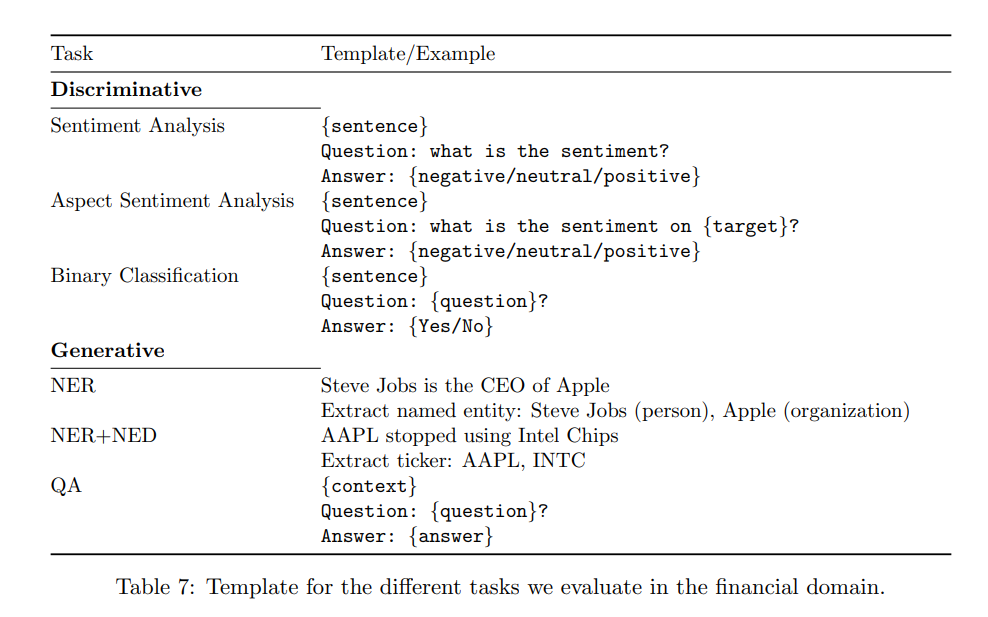
文章又将金融领域任务分成了外部任务和Bloomberg内部任务。在每个任务上,作者除了评估模型在任务上的表现,还评估了同一任务下不同模型生成结果之间两两比较的胜率(WR)。
外部任务
外部任务主要如下:
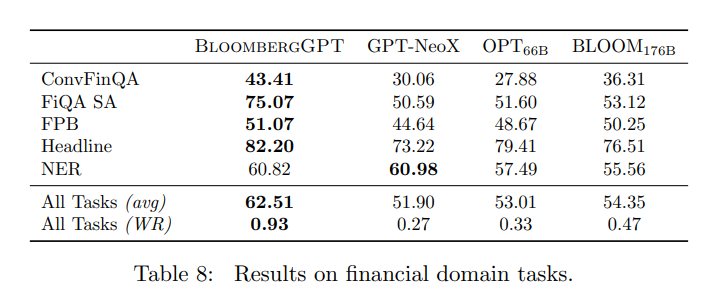
- ConvFinQA数据集是一个针对金融领域的问答数据集,包括从新闻文章中提取出的问题和答案,旨在测试模型对金融领域相关问题的理解和推理能力。
- FiQA SA,情感分析任务,测试英语金融新闻和社交媒体标题中的情感走向。
- Headline,新闻标题在预定义标签下的二分类。数据集包括关于黄金商品领域的英文新闻标题,标注了不同的子集。任务是判断新闻标题是否包含特定信息,例如价格上涨或价格下跌等。
- FPB,金融短语库数据集包括来自金融新闻的句子情绪分类任务。
- NER,命名实体识别任务,针对从提交给SEC的金融协议中收集金融数据,进行信用风险评估。
对于ConvFinQA来说,这个差距尤为显著,因为它需要使用对话式输入来对表格进行推理并生成答案,具有一定挑战性。
从评估结果来看,BloombergGPT在五项任务中的四项(ConvFinQA,FiQA SA,FPB和Headline)表现最佳,在NER(Named Entity Recognition)中排名第二。因此,BloombergGPT有其优势性。
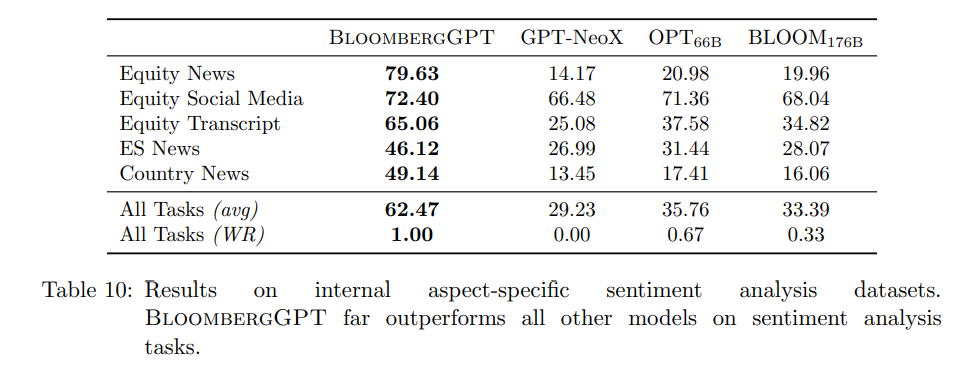
Bloomberg内部任务之情感分析
这个任务中的情感分析均为基于内部特定方面的情感分析数据集(aspect-specific)。
探索性任务:NER
NER(Named Entity Recognition,命名实体识别)在很大程度上是生成LLM尚未探索的任务,我们研究的LLM论文中没有一篇报告NER性能。因此,我们将NER视为一项探索性任务,并报告初步结果。
对于生成性LLM来说,NER可能是一项艰巨的任务,这有几个原因。
- 首先,NER是一项信息提取任务,更适合于编码器-解码器或仅编码器架构。LLM的生成性并没有给NER带来优势。
- 与其他任务相比,NER需要大量的即时工程和更多的案例训练才能获得合理的结果。特定于金融的NER有一些微妙之处,这使得零次或少次学习变得特别困难。
例如,如果有这样一个标题“彭博社:马斯克为推特和对中国的评论添加了新功能(Bloomberg: Mr. Musk adds new features to Twitter and comments on China)”。
根据说明和下游任务需求:
(1)报道新闻机构“彭博社”是否可以被标记,这取决于我们是否想要突出的实体,
(2)“马斯克先生”或“马斯克”是要被标记为PER(人物),
(3)“推特”可以被标记为ORG(组织)或PRD(产品),因为推特产品中添加了功能,而不是组织,
(4)“中国”可能标记为ORG或LOC(地区),尽管正确的标记可能是ORG。
如果没有在提示中添加更详细的说明,LLM就不知道预期的标记行为。基于初步测试,将要预测的实体类型限制为ORG、PER和LOC,以在所有模型的内部NER任务中获得最佳性能。总的来说,过滤掉的实体不到1%。
因此,这里的NER只涉及到ORG、PER、LOC这三类实体。
同时探索性任务NER+NED是指识别出实体后再将实体链接到上市公司的股票简称。比如“AAPL announced that they will stop using Intel chips in future products.” 这句话NER的结果是“AAPL, Intel”,NER+NED的结果是 “AAPL, INTC”。
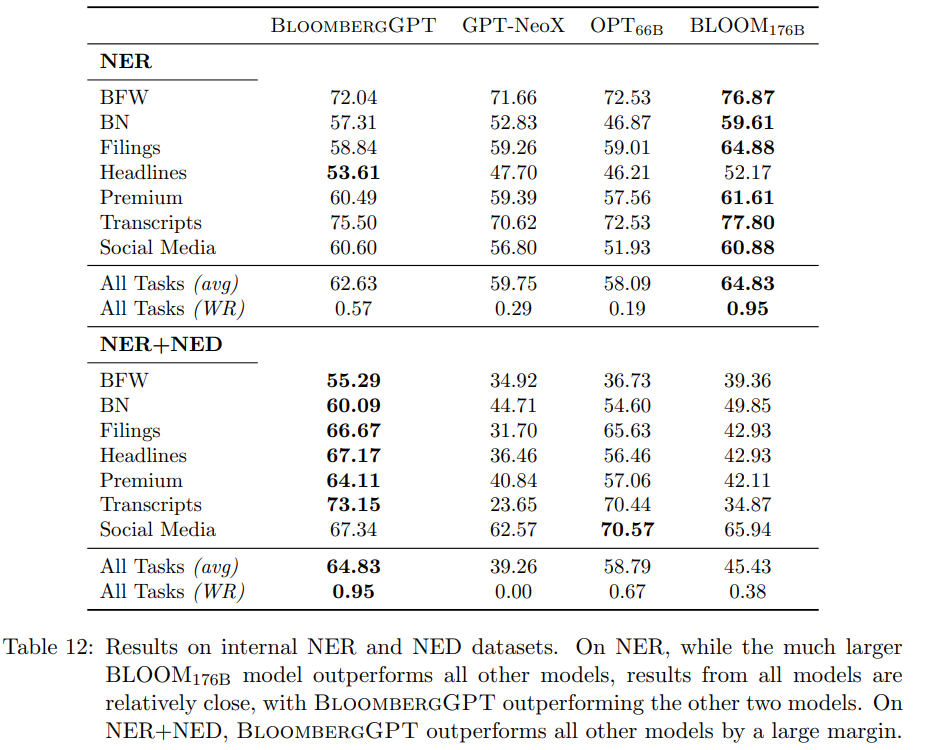
这两类任务涉及到的数据集包括了7个数据集,分别为BN(Bloomberg BN wire上内容)、BFW(Bloomberg First Word上的内容)、Filings(财报内容)、Headlines(Bloomberg news内容)、Premium(Bloogberg收录 的第三方新闻内容)、Transcripts(公司新闻发布会的文字记录)、Social Media。
最终,NER任务下,BloombergGPT仅在Headlines这一个数据集上得分最高;但在NER+NED任务下,BloombergGPT在除了Social Media任务的其他任务上均得分第一。
具体结果如下:
通用领域评估
作者在BIG-bench Hard(BIG-bench的一个子集,仅包含目前模型表现无法超过人类的任务)、常识测试(不提供任何背景知识,仅可以训练时使用的数据)、阅读理解、语言学(消歧、语法识别、蕴含判别等)等任务上进行了测试。
在BIG-bench Hard任务上,BloombergGPT得分低于参数量更大的PaLM和BLOOM,但是与参数规模类似的GPT-NeoX或OPT66B相比,BloombergGPT的性能更接近BLOOM,这说明开发金融专用的大语言模型并没有明显牺牲其通用能力。
在常识测试任务中,BloombergGPT在1个任务上取得了第一名,在其余3个任务上取得了第二名(这里未考虑GPT-3)。
在阅读理解任务上,GPT-3在所有任务上排名第一,BloombergGPT在5/6个任务上排名第二,且得分远高于BLOOM模型。
在语言学任务上,GPT-3在综合排名第一,BloombergGPT综合排名第二,且综合得分高于BLOOM模型。
评测总结
在金融领域任务上,BloombergGPT综合表现最好;
在通用任务上,BloombergGPT的综合得分优于相同参数量级的其他模型,并且在某些任务上的得分要高于参数量更大的模型。
这都说明,开发金融专用的大语言模型在金融领域取得好效果的同时,并没有以牺牲模型通用能力为代价。
要点总结:
- BloombergGPT是Bloomberg训练出来的金融大语言模型(LLM for Finance)
- 模型参数量为500亿,使用了包含3630亿token的金融领域数据集以及3450亿token的通用数据集
- 隐藏层维度为7680,多头的头数为40
- 模型采用Unigram tokenizer,AdamW优化器
- 模型在64个AWS的p4d.24xlarge实例上训练了53天,其中每个p4d.24xlarge实例包含了8块40GB的A100GPU
- 对BloombergGPT的评估包含了两部分:金融领域评估与通用领域评估
- 评估对比的其他大语言模型有GPT-NeoX、OPT、BLOOM、GPT-3
- 在金融领域任务上,BloombergGPT综合表现最好;在通用任务上,BloombergGPT的综合得分同样优于相同参数量级的其他模型,并且在某些任务上的得分要高于参数量更大的模型
- BloombergGPT模型在金融领域取得好效果的同时,并没有以牺牲模型通用能力为代价
- 对模型定性评估的结果表明,BloombergGPT可以提高工作效率
- 出于安全性的考虑,BloogbergGPT模型不会被公开,但是模型训练和评估的相关经验和思考会被分享出来
- 作者认为,对模型效果提升促进最大的三个因素(按影响从高到低排序)分别为精心清洗的数据集、合理的tokenizer、流行的模型结构
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [电磁学]大学物理陈秉乾老师课程笔记
- 确保CentOS系统中的静态HTTP服务器的数据安全
- Uniapp软件库全新带勋章功能(包含前后端源码)
- [元带你学: eMMC协议 31] CRC 错误检测保证可靠性
- 2024年【电工(高级)】考试题库及电工(高级)报名考试
- niushop靶场漏洞查找-文件上传漏洞等(超详细)
- 最新版 BaseRecyclerViewAdapterHelper4:4.1.2 最简单的QuickViewHolder用法,最简洁的代码,复制可用
- ardupilot 罗德里格公式的两种推导
- 某60内网渗透之利用iodine构建专属dns隧道
- 机房动环监控:打造智能、高效的机房管理解决方案