【openGauss】数据库存储过程与触发器的应用
一、存储过程
存储过程是一组可以完成特定功能的SQL语句集合,经编译后存储在数据库中。存储过程的执行效率比逐条执行的SQL语句高很多,因为普通的SQL语句,每次都会对SQL进行解析、编译、执行,而存储过程只是在第一次执行时进行解析、编译、执行,以后都是对结果进行调用。
存储过程解析工作就是在SOL引擎模块中完成。
1.存储过程语法如下:
CREATE [ OR REPLACE ] [DEFINER = user] PROCEDURE procedure_name
[ ( {[ argname ] [ argmode ] argtype [ { DEFAULT | := | = } expression ]}[,...]) ]
{ IS | AS }
BEGIN
procedure_body
END
/
- OR REPLACE:存储过程没有alter procedure,但可以使用or replace替换原存储过程,create or replace当存储过程不存在时做创建,当存储过程存在时做替换。
- DEFINER = user:用于指定当前存储过程定义者,默认DEFINER=CURRENT_USER。
- argmode:参数模式,取值为:IN(输入参数)、OUT(输出参数)、INOUT(输入输出参数),默认是IN。
- { DEFAULT | := | = } :可以给输入参数设置默认值,DEFAULT、:=、=作用是一样的。
- IS、AS:语法格式要求,必须写其中一个。两个相同。
- BRGIN、END:语法格式要求,必须写。
2.存储过程实例:
(1)实例1:创建存储过程
CREATE OR REPLACE PROCEDURE proc_test(a int,b out int)
AS
BEGIN
b=a;
END;
/
(2)实例2:调用存储过程
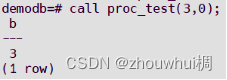
call proc_test(3,0);
虽然第二个参数是输出参数,但是在调用存储过程的时候也需要传值,否则会报错

正常调用执行结果如下所示:
(3)实例3:删除存储过程
DROP PROCEDURE proc_test;
(4)实例4:在存储过程中执行判断
在存储过程编写过程中可能会出现需要根据不同情况执行不同操作的情况,那么此时可以使用流程控制即判断来实现,openGauss数据库支持if…else if…else…end if也支持case when…then…end case完成流程控制。
① if…else if…else
CREATE OR REPLACE PROCEDURE proc_if(a int,b out int)
AS
BEGIN
if a<0 then
b=-1;
else if a=0 then -- else if可以是0或多个
b=0;
else
b=1;
end if;
end if;
END;
/
使用了几次if最终判断结束的时候就需要几个end if
② case when…then…end case
CREATE OR REPLACE PROCEDURE proc_case(a int,b out int)
AS
BEGIN
case when a<0 then
b=-1;
when a=0 then
b=0;
else
b=1;
end case;
END;
/
(5)实例5:在存储过程中执行循环
在存储过程中如果想要分别获取数据集中的数据,此时就需要循环遍历数据集,或需要重复执行相同操作也可以使用循环实现,openGauss数据支持的循环有for、while、loop
CREATE TABLE t2(c1 int); – 创建一张新表用于测试
① for循环
CREATE OR REPLACE PROCEDURE proc_for(startnum int,endnum int)
AS
BEGIN
for i in startnum .. endnum loop
insert into t2 values(i);
end loop;
END;
/
startnum … endnum相当于生成了一个startnum开始到endnum结束的整数序列,如果startnum=1,endnum=10,那么此时整数序列为1-10(包含10),一共循环10次,i的取值分别是1,2,3,4,5,6,7,8,9,10
② while循环
CREATE OR REPLACE PROCEDURE proc_while(startnum int,endnum int)
AS
declare a int;
BEGIN
a=startnum;
while a<=endnum loop -- 当a>endnum时循环结束
insert into t2 values(a);
a=a+1; -- 每循环一次a+1
end loop;
END;
/
③ loop循环
CREATE OR REPLACE PROCEDURE proc_loop(startnum int,endnum int)
AS
declare a int;
BEGIN
a=startnum;
loop
if a>endnum then -- 当a>endnum时,exit退出循环
exit;
end if;
insert into t2 values(a);
a=a+1; -- 每循环一次a+1
end loop;
END;
/
(6)实例6:使用存储过程从表中查询一个具体值
当确定查询的内容仅一行一列时,可以将该单元格的数据赋值给输出参数进行输出
① 创建表并插入数据
CREATE TABLE t1(c1 int,c2 varchar(20));
INSERT INTO t1 VALUES(1001,'zhangsan'),(1002,'lisi');
② 创建存储过程
CREATE OR REPLACE PROCEDURE proc_test(b out varchar)
AS
BEGIN
select c2 into b from t1 where c1=1001; -- into将c2的值赋值给输出参数b
END;
/
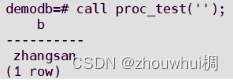
③ 调用存储过程
call test_pro('');
查询结果如下:
(7)实例7:使用存储过程查询表数据
当查询一个单元格的数据是可以使用输出参数,但当查询多行/多列/多行多列时需要借助于循环进行遍历。可以使用游标也可以不使用
① 不使用游标
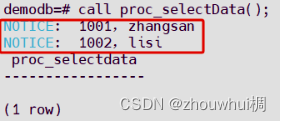
CREATE OR REPLACE PROCEDURE proc_selectData()
AS
BEGIN
for i in (select * from t1) loop -- 循环遍历查询结果集
raise notice 'ID:%,NAME:%',i.c1,i.c2; -- 输出
end loop;
END;
/
raise notice表示已notice日志的形式输出数据,输出字符串
'%,%'就是要输出的字符串,%为占位符,字符串后的第一个值传给第一个占位符,依次赋值。
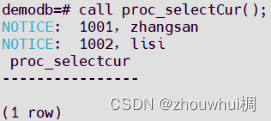
② 使用游标,for遍历游标
CREATE OR REPLACE PROCEDURE proc_selectCur()
AS
declare cursor cur1 is select * from t1; -- 定义游标
BEGIN
for i in cur1 loop -- 循环遍历游标
raise notice '%,%',i.c1,i.c2; -- 输出
end loop;
END;
/
for会自动打开并关闭游标,不需要用户操作游标的打开、取值、关闭。
③ 使用游标,按游标操作使用
CREATE OR REPLACE PROCEDURE proc_selectCur2()
AS
declare cursor cur1 is select * from t1; -- 定义游标
declare data record; -- 用于接收游标中的记录
BEGIN
open cur1; -- 打开游标
loop
if cur1%notfound then -- 判断游标是否结束
close cur1; -- 关闭游标
exit; -- 跳出循环
end if;
fetch next from cur1 into data; -- 遍历游标(取下一个值)
raise notice '%,%',data.c1,data.c2; -- 输出
end loop;
END;
/
二、自定义函数
自定义函数的整体语法与存储过程类似,但有些区别:
(1)数据库默认兼容的是Oracle,所以默认自定义函数必须要有返回值,存储过程不需要返回值。
(2)数据库兼容模式为Oracle时,自定义函数支持IN/OUT/INOUT模式的参数。
(3)存储过程的调用使用call,自定义函数的调用使用select。
(4)自定义函数可用于触发器。
1.自定义函数语法如下:
CREATE [ OR REPLACE ] [DEFINER = user] FUNCTION function_name
( [ { argname [ argmode ] argtype [ { DEFAULT | := | = } expression ] } [, ...] ] )
RETURNS rettype [ DETERMINISTIC ] [...]
{ IS | AS }
$$
BEGIN
plsql_body
RETURN value;
END
$$LANGUAGE PLPGSQL
- OR REPLACE:存储过程没有alter procedure,但可以使用or replace替换原存储过程,create or replace当存储过程不存在时做创建,当存储过程存在时做替换。
- DEFINER = user:用于指定当前存储过程定义者,默认DEFINER=CURRENT_USER。
- argmode:参数模式,取值为:IN(输入参数)、OUT(输出参数)、INOUT(输入输出参数),默认是IN。
- { DEFAULT | := | = } :可以给输入参数设置默认值,DEFAULT、:=、=作用是一样的。
- RETURNS:配置返回值类型
- IS、AS:语法格式要求,必须写其中一个。两个相同。
- BRGIN、END:语法格式要求,必须写。
2.自定义函数实例:
(1)实例1:创建一个自定义函数
CREATE OR REPLACE FUNCTION func_test() RETURNS int
AS
$$
declare a int; -- 定义变量
BEGIN
a=1;
return a;
END;
$$LANGUAGE PLPGSQL;
(2)实例2:调用函数
select func_test();
(3)实例3:删除函数
DROP FUNCTION func_test();
(4)实例4:创建一个应用于触发器的函数
CREATE OR REPLACE FUNCTION func_trigger() RETURNS TRIGGER
AS
$$
BEGIN
.....(处理代码)
return null;
END;
$$LANGUAGE PLPGSQL;
三、触发器
自定义函数的整体语法与存储过程类似,但有些区别:
(1)数据库默认兼容的是Oracle,所以默认自定义函数必须要有返回值,存储过程不需要返回值。
(2)数据库兼容模式为Oracle时,自定义函数支持IN/OUT/INOUT模式的参数。
(3)存储过程的调用使用call,自定义函数的调用使用select。
(4)自定义函数可用于触发器。
1.触发器语法如下:
CREATE [ CONSTRAINT ] TRIGGER name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] }
ON table_name
[ FROM referenced_table_name ]
{ NOT DEFERRABLE | [ DEFERRABLE ] { INITIALLY IMMEDIATE | INITIALLY DEFERRED } }
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN ( condition ) ]
EXECUTE PROCEDURE function_name ( arguments )
- CONSTRAINT :触发器作为约束来使用。
- BEFORE | AFTER | INSTEAD OF:用于指定触发器在什么时候被处罚,BEFORE表示在执行event前,AFTER表示在event之后,INSTEAD OF表示触发器操作直接替换event,也就是event不会被执行。
- event:触发触发器的事件,当在指定表上执行event指定的操作时触发触发器,event取值为INSERT(插入数据时)/UPDATE(更新数据时)/UPDATE OF COLUMN(更新指定列时,列可以是多个)/DELETE(删除数据时)/TRUNCATE(清空表时)。
- ON table_name:触发器是作用于一张具体的表,结合上两个参数形成了触发器条件(在对指定表执行具体的操作(event)的前/后触发)。
- FOR [ EACH ] { ROW | STATEMENT }:默认值为STATEMENT,触发器的执行只在被触发时执行一次,可选值ROW表示当触发器被触发后原操作每操作一行,触发器就会被触发一次,常用值FOR EACH ROW。
- WHEN ( condition ):触发器执行过滤条件。
- EXECUTE PROCEDURE function_name:触发器被触发的时候执行的操作。
2.自定义函数实例:
创建两张表t1和t2用于测试
CREATE TABLE t1(c1 int);
CREATE TABLE t2(c1 int);
(1)实例1:创建一个触发器,实现当用户往t1表插入数据后,将该数据也同步插入一条道t2表中
触发器所需要的函数定义
CREATE OR REPLACE FUNCTION func_insert() RETURNS trigger
AS
$$
BEGIN
insert into t2 values(new.c1); -- new为当前插入的新纪录,new.c1就是新纪录的c1列
return null; -- 作用于触发器的函数不需要返回结果,但必须有return所以返回null
END;
$$LANGUAGE PLPGSQL;
触发器定义
CREATE TRIGGER insert_t1_t2() AFTER INSERT ON t1 FOR EACH ROW EXECUTE func_insert();
insert可以批量插入多条记录,为了保证插入t1表的每条数据都能插入t2表,所以选择FOR EACH ROW。
(2)实例2:创建一个触发器,实现当用户删除t1表中的数据前,同步删除t2表的数据
触发器所需要的函数定义
CREATE OR REPLACE FUNCTION func_delete() RETURNS trigger
AS
$$
BEGIN
delete from t2 where c1=old.c1; -- old为当前操作的旧记录,old.c1为当前记录的c1列
return null; -- 作用于触发器的函数不需要返回结果,但必须有return所以返回null
END;
$$LANGUAGE PLPGSQL;
触发器定义
CREATE TRIGGER delete_t1_t2() BEFORE DELETE ON t1 FOR EACH ROW EXECUTE func_delete();
如果触发器处理更改为:当用户删除t1表数据时,同步删除t2的数据,t1表保留不动
CREATE TRIGGER delete_t1_t2() INSTEAD OF DELETE ON t1 FOR EACH ROW EXECUTE func_delete();
(3)实例3:创建一个触发器,实现当用户更新t1表中的数据时,同步更新t2表的数据
触发器所需要的函数定义
CREATE OR REPLACE FUNCTION func_update() RETURNS trigger
AS
$$
BEGIN
update t2 set c1=new.c1 where c1=old.c1; -- new.c1就是更改后的值,old.c1为更改前的
return null; -- 作用于触发器的函数不需要返回结果,但必须有return所以返回null
END;
$$LANGUAGE PLPGSQL;
触发器定义
CREATE TRIGGER update_t1_t2() AFTER UPDATE ON t1 FOR EACH ROW EXECUTE func_update();
如果需要指定触发器仅在更改c1列时才会被触发,配置如下:
CREATE TRIGGER insert_t1_t2() AFTER UPDATE OF c1 ON t1 FOR EACH ROW EXECUTE func_update();
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!