elasticsearch[五]:深入探索ES搜索引擎的自动补全与拼写纠错:如何实现高效智能的搜索体验
elasticsearch[五]:深入探索ES搜索引擎的自动补全与拼写纠错:如何实现高效智能的搜索体验
前一章讲了搜索中的拼写纠错功能,里面一个很重要的概念就是莱文斯坦距离。这章会讲解搜索中提升用户体验的另一项功能 - [自动补全]。本章直接介绍 ES 中的实现方式以及真正的搜索引擎对自动补全功能的优化。

大家对上面的这个应该都不陌生,搜索引擎会根据你输入的关键字进行一些提示,这样用户只需要输入部分内容就可以进行选择了。尤其在移动端会比较方便。淘宝、京东的搜索也有类似的功能,只不过行业不同,提示出来的内容也不同罢了。
1、Lucene 中的搜索建议
1.1 使用步骤:
- 导入 lucene-suggest 组件
- 指定联想数据来源,lucene suggest 提供了几个 InputIteratior 的默认实现,也可以自定义实现
- BufferedInputIterator:对二进制类型的输入进行轮询;
- DocumentInputIterator:从索引中被 store 的 field 中轮询;
- FileIterator:从文件中每次读出单行的数据轮询,以 \ t 进行间隔(且 \ t 的个数最多为 2 个);
- HighFrequencyIterator:从索引中被 store 的 field 轮询,忽略长度小于设定值的文本;
- InputIteratorWrapper:遍历 BytesRefIterator 并且返回的内容不包含 payload 且 weight 均为 1;
- SortedInputIterator:二进制类型的输入轮询且按照指定的 comparator 算法进行排序;
InputIteratior 中几个方法的作用:
weight():此方法设置某个term的权重,设置的越高suggest的优先级越高;
payload():每个suggestion对应的元数据的二进制表示,我们在传输对象的时候需要转换对象或对象的某个属性为BytesRef类型,相应的suggester调用lookup的时候会返回payloads信息;
hasPayload():判断iterator是否有payloads;
contexts():获取某个term的contexts,用来过滤suggest的内容,如果suggest的列表为空,返回null
hasContexts():获取iterator是否有contexts;
- 建立 suggest 索引:suggester.build(new InputIteratorWrapper{});// 根据 InputIterator 的具体实现决定数据源以及创建索引的规则
- 索引建立完毕即可在索引上进行查询,输入模糊的字符,Lucene suggest 的内部算法会根据索引的建立规则提出 suggest 查询的内容。suggester.lookup(name, contexts, 2, true, false);
1.2.Lucene suggest 核心实现一览
Lucene 使用 AnalyzingInfixSuggester 类中的 lookup 方法去联想数据来源进行查询,其实就是一个普通的 search,所以我们的关键是要维护好这个联想数据来源,各行各业都应该有自己单独的语料库。
2 Elastic Search 中的搜索优化策略
应该从这几个方面入手:怎么优化 Suggest 词库、提升 Suggest 词准确率、怎么提高响应速度
2.1.Suggest 词库获取
- 冷启动可以从内容中提取热词数据来解决,或者人工设置
- 挖掘搜索日志:
- 挖掘近 1 个月搜索日志,按照每天独立 IP 进行统计频次,即每个 IP 用户天搜索同一关键词多次只记一次,用 IP 过滤也有其局限性,伪 IP,动态 IP,局域网共享同一公网 IP,都会影响到基于 IP 来判断用户的准确性,你也可以使用 sessionId 或者 userId 来判断
- 统计后搜索词频次之后,抽取搜索频次 > 100(自定阈值)的词,同时对日志数据进行清洗,过滤去除大于 10 个字(去除太长的长尾词),单字和符号内容
- 定时更新 suggest 词库中。
- 搜索日志里面包含大量 误输入词:
- 需要在 suggest 词库里面去掉误输入词,对于搜索频次高的词,可以挖掘其对应的正确词,通过同义词进行查询改写。
- 误输入词同义词挖掘可以通过挖掘搜索 session 序列,使用 word2vec 训练来获取误输入词的同义词,通过分词器同义词设置,对误输入词进行查询改写。
2.2. 提升 Suggest 词准确率
- 使用 fuzzy 模糊查询:基于编辑距离算法来匹配文档。编辑距离的计算基于我们提供的查询词条和被搜索文档。
- 排序:从搜索日志挖掘的 Suggest 词,可以根据搜索词的搜索频次作为热度来设置 weight,Suggest 会根据 weight 来排序。
2.3. 提升响应速度
当使用 completion suggester 的时候, 不是用于完成 类似于 " 关键词 " 这样的模糊匹配场景,而是用于完成关键词前缀匹配的。 对于汉字的处理,无需使用 ik/ HanLP 一类的分词器,直接使用 keyword analyzer,配合去除一些不需要的 stop word 即可。
代码参考:
LinkedHashSet<String> returnSet = new LinkedHashSet<>();
Client client = elasticsearchTemplate.getClient();
SuggestRequestBuilder suggestRequestBuilder = client.prepareSuggest(elasticsearchTemplate.getPersistentEntityFor(SuggestEntity.class).getIndexName());
//全拼前缀匹配
CompletionSuggestionBuilder fullPinyinSuggest = new CompletionSuggestionBuilder("full_pinyin_suggest")
.field("full_pinyin").text(input).size(10);
//汉字前缀匹配
CompletionSuggestionBuilder suggestText = new CompletionSuggestionBuilder("suggestText")
.field("suggestText").text(input).size(size);
//拼音搜字母前缀匹配
CompletionSuggestionBuilder prefixPinyinSuggest = new CompletionSuggestionBuilder("prefix_pinyin_text")
.field("prefix_pinyin").text(input).size(size);
suggestRequestBuilder = suggestRequestBuilder.addSuggestion(fullPinyinSuggest).addSuggestion(suggestText).addSuggestion(prefixPinyinSuggest);
SuggestResponse suggestResponse = suggestRequestBuilder.execute().actionGet();
Suggest.Suggestion prefixPinyinSuggestion = suggestResponse.getSuggest().getSuggestion("prefix_pinyin_text");
Suggest.Suggestion fullPinyinSuggestion = suggestResponse.getSuggest().getSuggestion("full_pinyin_suggest");
Suggest.Suggestion suggestTextsuggestion = suggestResponse.getSuggest().getSuggestion("suggestText");
List<Suggest.Suggestion.Entry> entries = suggestTextsuggestion.getEntries();
//汉字前缀匹配
for (Suggest.Suggestion.Entry entry : entries) {
List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();
for (Suggest.Suggestion.Entry.Option option : options) {
returnSet.add(option.getText().toString());
}
}
//全拼suggest补充
if (returnSet.size() < 10) {
List<Suggest.Suggestion.Entry> fullPinyinEntries = fullPinyinSuggestion.getEntries();
for (Suggest.Suggestion.Entry entry : fullPinyinEntries) {
List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();
for (Suggest.Suggestion.Entry.Option option : options) {
if (returnSet.size() < 10) {
returnSet.add(option.getText().toString());
}
}
}
}
//首字母拼音suggest补充
if (returnSet.size() == 0) {
List<Suggest.Suggestion.Entry> prefixPinyinEntries = prefixPinyinSuggestion.getEntries();
for (Suggest.Suggestion.Entry entry : prefixPinyinEntries) {
List<Suggest.Suggestion.Entry.Option> options = entry.getOptions();
for (Suggest.Suggestion.Entry.Option option : options) {
returnSet.add(option.getText().toString());
}
}
}
return new ArrayList<>(returnSet);
3.搜索引擎对搜索提示的优化
搜索引擎的优化,需要更智能,每个人输入相同的关键字,提示出来的内容可能是完全不相同的,这就是所谓的 “千人千面”。这就用到了数据分析的知识,可以根据用户一段时间内的搜索历史,分析用户的搜索习惯,结合语料库实现对用户的精准提示。跟输入法的提升功能类似,会根据你过往的输入文本进行自动提示。所以,你付出了隐私,得到的是更大的便捷。这也是没有办法的事情。
- 搜索提示的一点小总结(重点)
- 需要一个搜索词库 / 语料库,各行各业均应该不同
- 对用户输入的关键字进行分词
- 根据分词及其他搜索条件去语料库中查询若干条(百度是 10 条)记录返回
- 为了提升准确率,通常都是前缀搜索
- 会根据莱温斯坦距离进行拼写纠错
4.搜索引擎中的智能提示 API 调用
如你所见,各大搜索引擎都提供了智能提示的 API 供广大用户调用,如果你司没有自研的能力,可以直接 js 中跨域调用,先把系统跑起来再说,给大家提供主流搜索引擎的调用地址,包含电商的哦。
4.1. 搜索引擎 JSONP 调用接口
提示:URL 中的 #content# 为搜索的 关键字
谷歌(Google)
http://suggestqueries.google.com/complete/search?client=youtube&q=#content#&jsonp=window.google.ac.h
callback:window.google.ac.h
window.google.ac.h([“关键字”,[[“关键字”,0],[“关键字 歌词”,0],[“关键字参数”,0],[“关键字 lyrics”,0],[“关键字过滤”,0],[“关键字排名”,0],[“关键字查询”,0],[“关键字提取算法”,0],[“关键字规划师可通过以下哪种方式帮助您制作新的搜索网络广告系列”,0],[“关键字优化”,0]],{“k”:1,“q”:“uhaB8ZMjzJay-BACee_C0eVdUCA”}])
必应(Bing)
http://api.bing.com/qsonhs.aspx?type=cb&q=#content#&cb=window.bing.sug
callback:window.bing.sug
if(typeof window.bing.sug == 'function') window.bing.sug({"AS":{"Query":"关键字","FullResults":0}} /* pageview_candidate */);
百度(Baidu)
http://suggestion.baidu.com/su?wd=#content#&cb=window.baidu.sug
callback:window.baidu.sug
window.baidu.sug({q:"关键字",p:false,s:["关键字搜索排名","关键字怎么优化","关键字查询工具","关键字推广","关键词优化","关键词排名","关键字 英文","关键词挖掘","关键词查询","关键词搜索"]});
好搜(So)
**callback:**window.so.sug
window.so.sug({"query":"关键字","result":[{"word":"关键字查询"},{"word":"关键字工具"},{"word":"关键字查询工具"},{"word":"关键字挖掘"},{"word":"关键字搜索"},{"word":"关键字英文"},{"word":"关键字是什么"},{"word":"关键字广告"},{"word":"关键字分析"},{"word":"关键字规划师"}],"version":"b","rec":""});
搜狗(Sogou)
https://www.sogou.com/suggnew/ajajjson?type=web&key=#content#
**callback:**window.sogou.sug
window.sogou.sug(["关键字",["关键字查询","关键字搜索","关键字优化","关键字规划师","关键字查询lol","关键字是什么意思","关键字搜索工具","关键字广告图片","关键字排名查询","关键字生成器"],["0;0;0;0","1;0;0;0","2;0;0;0","3;0;0;0","4;0;0;0","5;0;0;0","6;0;0;0","7;0;0;0","8;0;0;0","9;0;0;0"],["","","","","","","","","",""],["0"],"","suglabId_1"],-1);
淘宝(Taobao)
https://suggest.taobao.com/sug?code=utf-8&q=#content#&callback=window.taobao.sug
**callback:**window.taobao.sug
window.taobao.sug({"result":[["关键字推广","204"],["关键字seo","198"],["关键字 网站","182"],["关键字搜索","119"],["关键字软件","44"],["关键字首页","50"],["关键字收录","35"],["关键字采集","16"],["关键字采集器","10"],["网站关键字","180"]]})
搜索建议使用方式
以百度为例,API 返回的是 JSONP 数据,JSONP 是跨域访问的一种方式。由于服务器返回的 JavaScript 代码可以直接引用,通过回调函数的方式就可以间接的获取服务器的数据。
下面是一个回调搜索建议的例子,window.baidu.sug 返回的是一个 json 对象:
<script type="text/javascript">
window.onload = function() {
//组装查询地址
var sugurl = "http://suggestion.baidu.com/su?wd=#content#&cb=window.baidu.sug";
var content = "关键字";
sugurl = sugurl.replace("#content#", content);
//定义回调函数
window.baidu = {
sug: function(json) {
console.log(json)
}
}
//动态添加JS脚本
var script = document.createElement("script");
script.src = sugurl;
document.getElementsByTagName("head")[0].appendChild(script);
}
</script>
控制台打印的结果:如果要将结果保存在一个字符串数组中,只需要 var arr = json.s 即可。
5.拼写纠错功能的实现
在使用搜索引擎时,当我们输入错误的关键词时,当然这里的错误是拼写错误,搜索引擎的下拉框中仍会显示以正确关键词为前前辍的提示,当你直接回车搜索错误的关键词时,搜索引擎的结果中仍包括正确关键词的结果。你有没有想过它是如何实现的呢?
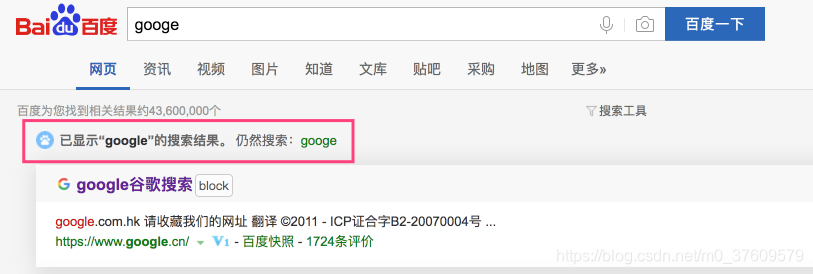
这个的实现可以有多种方案,常见的方法就是我们前面学习过的最长公共子序列和今天要讲的莱文斯坦距离方式。
最长公共子序列可以查看我前面的博文程序员的算法课(6)- 最长公共子序列(LCS)。
这两种方案都需要跟正确的词典进行对照,**计算编辑距离或者最长公共子序列,将编辑距离最小或子序列最长的单词,作为纠正之后的单词,**返回给用户。
- 莱文斯坦距离
莱文斯坦距离,又称 Levenshtein 距离,是[编辑距离]的一种。指两个[字串]之间,由一个转成另一个所需的最少编辑操作次数。允许的编辑操作包括将一个字符替换成另一个字符,插入一个[字符],删除一个字符。
如单词 three,我不小心手误打成了 ethre,可以看到 ethre 只需要把首字母 e 移动到末尾即可变成正确的单词 three。此时 ethre 相对于 three 的编辑距离就是 1。
莱文斯坦距离允许增加、删除、替换字符这三个编辑操作,最长公共子串长度只允许增加、删除字符这两个编辑操作。
莱文斯坦距离和最长公共子串长度,从两个截然相反的角度,分析字符串的相似程度。莱文斯坦距离的大小,表示两个字符串差异的大小;而最长公共子串的大小,表示两个字符串相似程度的大小。
5.1.Lucene 中通过 Suggest 模块下的 SpellChecker 功能来实现拼写纠错。
源码中,定义了两个 public 的静态成员变量, DEFAULT_ACCURACY 表示默认的最小分数,SpellCheck 会对字典里的每个词与用户输入的搜索关键字进行一个相似度打分,默认该值是 0.5,相似度分值范围是 0 到 1 之间,数字越大表示越相似,小于 0.5 会认为不是同一个结果。F_WORD 是对于字典文件里每一行创建索引时使用的默认域名称,默认值为:word。
几个重要的 API:
**[getAccuracy](http://www.tuicool.com/admin/blogs/):**accuracy 是精确度的意思,这里表示最小评分,评分越大表示与用户输入的关键字越相似- suggestSimilar:这个方法就是用来决定哪些 word 会被判定为比较相似的然后以数组的形式返回,这是 SpellChecker 的核心;
- setComparator:设置比较器,既然涉及到相似度问题,那肯定有相似度大小问题,有大小必然存在比较,有比较必然需要比较器,通过比较器决定返回的建议词的顺序,因为一般需要把最相关的显示在最前面,然后依次排序显示;
- setSpellIndex:设置拼写检查索引目录的
- setStringDistance:设置编辑距离
看到了 setStringDistance 这个方法,想都不用想,Lucene 肯定也是使用编辑距离的方式进行匹配的。
源码中还有两个私有属性,分别代表前缀和后缀的权重,前缀要比后缀大。
private float bStart = 2.0f;
private float bEnd = 1.0f;
几个重要的方法:
- formGrams:对输入的字符串按指定长度分割,返回分割后的数组。
- indexDictionary:将字典文件里的词进行 ngram 操作后得到多个词然后分别写入索引。
- suggestSimilar:用来计算最后返回的建议词。有三种建议模式:
- SUGGEST_WHEN_NOT_IN_INDEX:意思就是只有当用户提供的搜索关键字在索引 Term 中不存在我才提供建议,否则我会认为用户输入的搜索关键字是正确的不需要提供建议。
- SUGGEST_MORE_POPULAR:表示只返回频率较高的词组,用户输入的搜索关键字首先需要经过 ngram 分割,创建索引的时候也需要进行分词,如果用户输入的词分割后得到的 word 在索引中出现的频率比索引中实际存在的 Term 还要高,那说明不需要进行拼写建议了。
- SUGGEST_ALWAYS:永远进行建议,只是返回的建议结果受 numSug 数量限制即最多返回几条拼写建议。
最终返回用户输入关键字和索引中当前 Term 的相似度,这个取决于你 Distance 实现,默认实现是 LevenshteinDistance
(莱文斯坦距离)即计算编辑距离。采用三个一维数组代替了一个二维数组,一个数组为上一轮计算的值,一个数组保存本轮计算的值,最后一个数组用于交换两个数组的值。核心源码如下:
package org.apache.lucene.search.spell;
public class LevenshteinDistance implements StringDistance {
@Override
public float getDistance (String target, String other) {
char[] sa;
int n;
int p[]; //上一行计算的值
int d[]; //当前行计算的值
int _d[]; //用于交换p和d
sa = target.toCharArray();
n = sa.length;
p = new int[n+1];
d = new int[n+1];
final int m = other.length();
if (n == 0 || m == 0) {
if (n == m) {
return 1;
}
else {
return 0;
}
}
int i; // target的索引
int j; // other的索引
char t_j; //other的第j个字符
int cost;
//初始化,将空字符串转换为长度为i的target字符串的操作次数
for (i = 0; i<=n; i++) {
p[i] = i;
}
for (j = 1; j<=m; j++) {
t_j = other.charAt(j-1);
//左方的初始值为将长度为j的other字符串转换为空字符串的操作次数
d[0] = j;
//计算将长度为i的target字符串转换为长度为j的other字符串的操作次数
for (i=1; i<=n; i++) {
cost = sa[i-1]==t_j ? 0 : 1;
//d[i-1]左方、p[i]上方、p[i-1]左上
d[i] = Math.min(Math.min(d[i-1]+1, p[i]+1), p[i-1]+cost);
}
//交换p和d,用于下一轮计算
_d = p;
p = d;
d = _d;
}
//计算相似度,p中最后一个元素为LevensteinDistance
return 1.0f - ((float) p[n] / Math.max(other.length(), sa.length));
}
}
Lucene 还内置了另外几种相似度实现,都是基于距离计算的:JaroWinklerDistance、LuceneLevenshteinDistance 和 NGramDistance。
源码中还有大量同步锁的使用,跟本次内容关系不大,暂时先不考虑。
5.2.solr 有 SpellCheckComponent 拼写纠错功能,此外还有依靠文件来纠错和主索引纠错的方式。
solr 的纠错依赖于 lucene,主要通过插件的方式进行使用。solr 通过配置文件的方式指定纠错的规则,里面一个非常重要的属性:
accuracy,这个值每下降 0.1 就可以纠错一个字母, 下降 0.2 可以纠错一个汉字,例如:将其调整到 0.8 时可以搜索到数据但是仅仅只能出错一个汉字或者两个字母。
5.3.es 纠错
官方公式:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-phrase.html
es 中使用 phrase Suggester 来进行拼写纠错。phrase suggester 在 term suggester 之上添加了额外的逻辑以选择整体更正的 phrase,而不是基于单个分词加权的 ngram 语言模型。在实际中 phrase suggester 能够根据单词的词频等信息作出更好的选择。
ES 中常用的 4 种 Suggester 类型:Term、Phrase、Completion、Context。
- Term suggester 正如其名,只基于 analyze 过的单个 term 去提供建议,并不会考虑多个 term 之间的关系。API 调用方只需为每个 token 挑选 options 里的词,组合在一起返回给用户前端即可。 那么有无更直接办法,API 直接给出和用户输入文本相似的内容? 答案是有,这就要求助 Phrase Suggester 了。
- Phrase suggester 在 Term suggester 的基础上,会考量多个 term 之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等等。
- Completion Suggester,它主要针对的应用场景就是 “Auto Completion”。 此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个 Suggester 采用了不同的数据结构,索引并非通过倒排来完成,而是将 analyze 过的数据编码成 FST 和索引一起存放。对于一个 open 状态的索引,FST 会被 ES 整个装载到内存里的,进行前缀查找速度极快。但是 FST 只能用于前缀查找,这也是 Completion Suggester 的局限所在。
- Context Suggester,会根据上下文进行补全,这种方式补全效果较好,但性能较差,用的人不多。这也是 es 中拼写纠错的高级用法。
小结搜索引擎中对拼写纠错的算法猜想
Google 搜索框的补全 / 纠错功能,如果用 ES 怎么实现呢?我能想到的一个的实现方式:
- 在用户刚开始输入的过程中,使用 Completion Suggester 进行关键词前缀匹配,刚开始匹配项会比较多,随着用户输入字符增多,匹配项越来越少。如果用户输入比较精准,可能 Completion Suggester 的结果已经够好,用户已经可以看到理想的备选项了。
- 如果 Completion Suggester 已经到了零匹配,那么可以猜测是否用户有输入错误,这时候可以尝试一下 Phrase Suggester。
- 如果 Phrase Suggester 没有找到任何 option,开始尝试 term Suggester。
精准程度上 (Precision) 看: Completion > Phrase > term, 而召回率上 (Recall) 则反之。从性能上看,Completion Suggester 是最快的,如果能满足业务需求,只用 Completion Suggester 做前缀匹配是最理想的。 Phrase 和 Term 由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制 suggester 用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量 map 到内存。
真正的搜索引擎的拼写纠错优化,肯定不止我讲的这么简单,但是万变不离其宗。掌握了核心原理,就是掌握了解决问题的方法,剩下就靠你自己的灵活运用和实战操练了。
参考文章
- https://baike.baidu.com/item/%E8%8E%B1%E6%96%87%E6%96%AF%E5%9D%A6%E8%B7%9D%E7%A6%BB/14448097?fr=aladdin
- https://www.jianshu.com/p/f2cacf1d5d1b
- http://www.chepoo.com/spelling-correction-function-realization.html
- https://blog.csdn.net/qq_25800311/article/details/90665244
- https://blog.csdn.net/yzl_8877/article/details/53375132
- https://blog.csdn.net/sqh201030412/article/details/51038870
- https://blog.csdn.net/github_26672553/article/details/72639396
- https://elasticsearch.cn/article/142
参考文章
- https://www.cnblogs.com/woider/p/5805248.html
- https://blog.csdn.net/m0_37556444/article/details/82734959
- https://www.jianshu.com/p/69d56f9c0576
https://blog.csdn.net/m0_37609579/article/details/101001985
https://blog.csdn.net/m0_37609579/article/details/101039881?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-1-101039881-blog-130149985.235v40pc_relevant_anti_vip&spm=1001.2101.3001.4242.2&utm_relevant_index=4
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- springboot整合kafka附源码
- Python办公—pandas简单的A表匹配B表(B表可多个)通过唯一键(附代码)
- 汽车ECU BootLoader升级
- 辞旧岁,赢新篇,创维汽车召开年度会议立足过去,展望未来
- 《动手学深度学习》学习笔记 第4章 多层感知机
- Multimodal Chain-of-Thought Reasoning in Language Models语言模型中的多模态思维链推理
- 案例138:基于微信小程序的社区互助养老
- Oracle11gR2限制指定IP访问
- 旧硬盘插电脑上显示要初始化怎么办?了解原因和解决方案
- 【无标题】