MySQL与PostgreSQL对比
对比
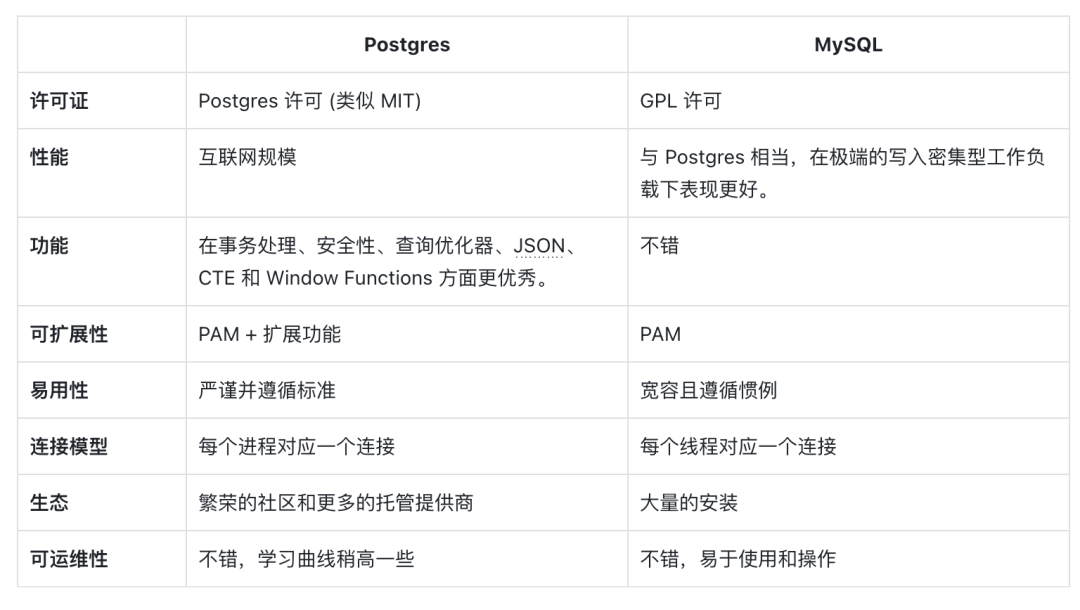
许可证 License
- MySQL 社区版采用 GPL 许可证。
- Postgres 发布在 PostgreSQL 许可下,是一种类似于 BSD 或 MIT 的自由开源许可。
即便 MySQL 采用了 GPL,仍有人担心 MySQL 归 Oracle 所有,这也是为什么 MariaDB 从 MySQL 分叉出来。
性能 Performance
对于大多数工作负载来说,Postgres 和 MySQL 的性能相当,最多只有 30% 的差异。无论选择哪个数据库,如果查询缺少索引,则可能导致 x10 ~ x1000 的降级。 话虽如此,在极端的写入密集型工作负载方面,MySQL 确实比 Postgres 更具优势。可以参考下文了解更多:
除非你的业务达到了 Uber 的规模,否则纯粹的数据库性能不是决定因素。像 Instagram, Notion 这样的公司也能够在超大规模下使用 Postgres。
JSON查询
PostgreSQL:?平均时间(毫秒):写入:2279.25、读取:31.65、更新:26.26
MySQL:?平均时间(毫秒):写入:3501.05、读取:49.99、更新:62.45
从上面的数据可以看出,PostgreSQL 在处理 JSON 时的性能要比 MySQL 更好,当然这也是 PostgreSQL 亮点之一。
QPS
1、QPS
QPS?
Queries Per Second?是每秒查询率 ,是一台服务器每秒能够相应的查询次数,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准, 即每秒的响应请求数,也即是最大吞吐能力。2、TPS
TPS?
Transactions Per Second?也就是事务数/秒。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数,

PostgreSQL 到底性能有多强?点查 QPS 60万+,最高达 200 万。读写 TPS (4写1读)每秒 7 万+,最高达14万。
PostgreSQL 与 MySQL 的极限性能对比极限条件下,PgSQL点查性能显著压倒 MySQL,其他性能基本与MySQL持平。
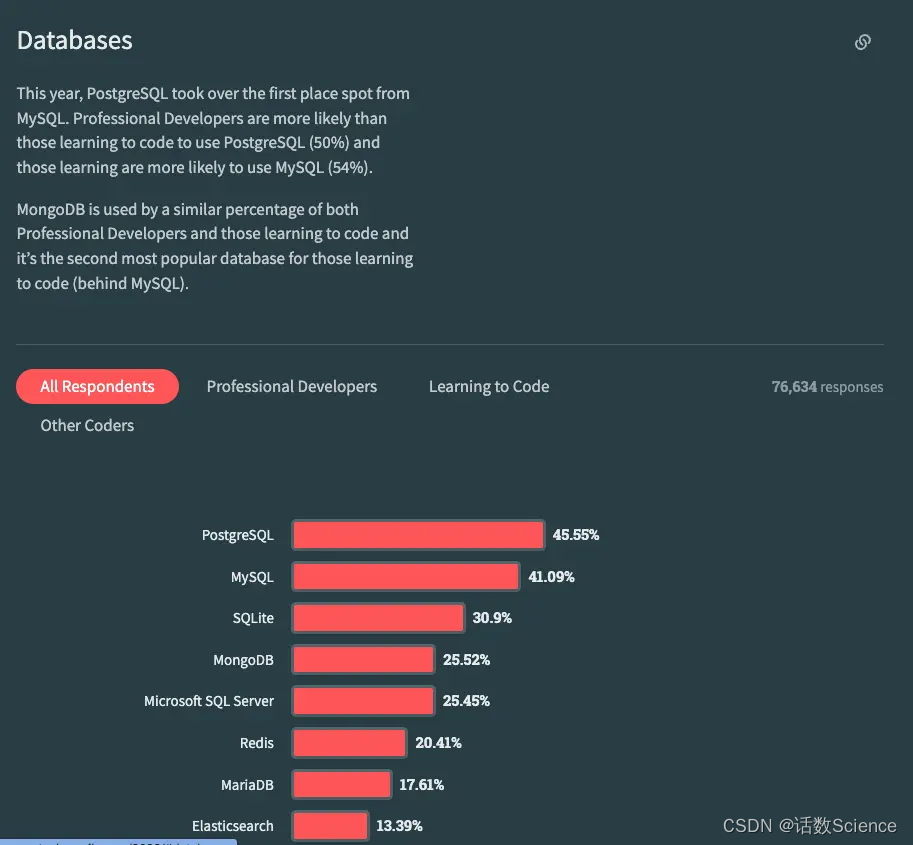
总的来说,Postgres 有更多功能、更繁荣的社区和生态;而 MySQL 则更易学习并且拥有庞大的用户群体。 我们观察到与 Stack Overflow 结果相同的行业趋势,即 Postgres 在开发者中变得越来越受欢迎。但根据我们的实际体验,精密的 Postgres 牺牲了一些便利性。如果你对 Postgres 不太熟悉,最好从云服务提供商那里启动一个实例,并运行几个查询来上手。有时候,这些额外好处可能并不值得,选择 MySQL 会更容易一些。
MySQL
限制
原则上来说应该是无限的, 但是又受到了某些参数的限制,内存大小的限制,主要与操作系统支持的大小有关!
| 实体 | 最大值 |
|---|---|
| 表 | 64 TB |
| 行 | 8KB |
| 主键 | 767 字节 |
| 索引(B-Tree) | 767 字节 |
| 索引(Hash) | 2 GB |
| BLOB 和 TEXT 字段 | 4 GB |
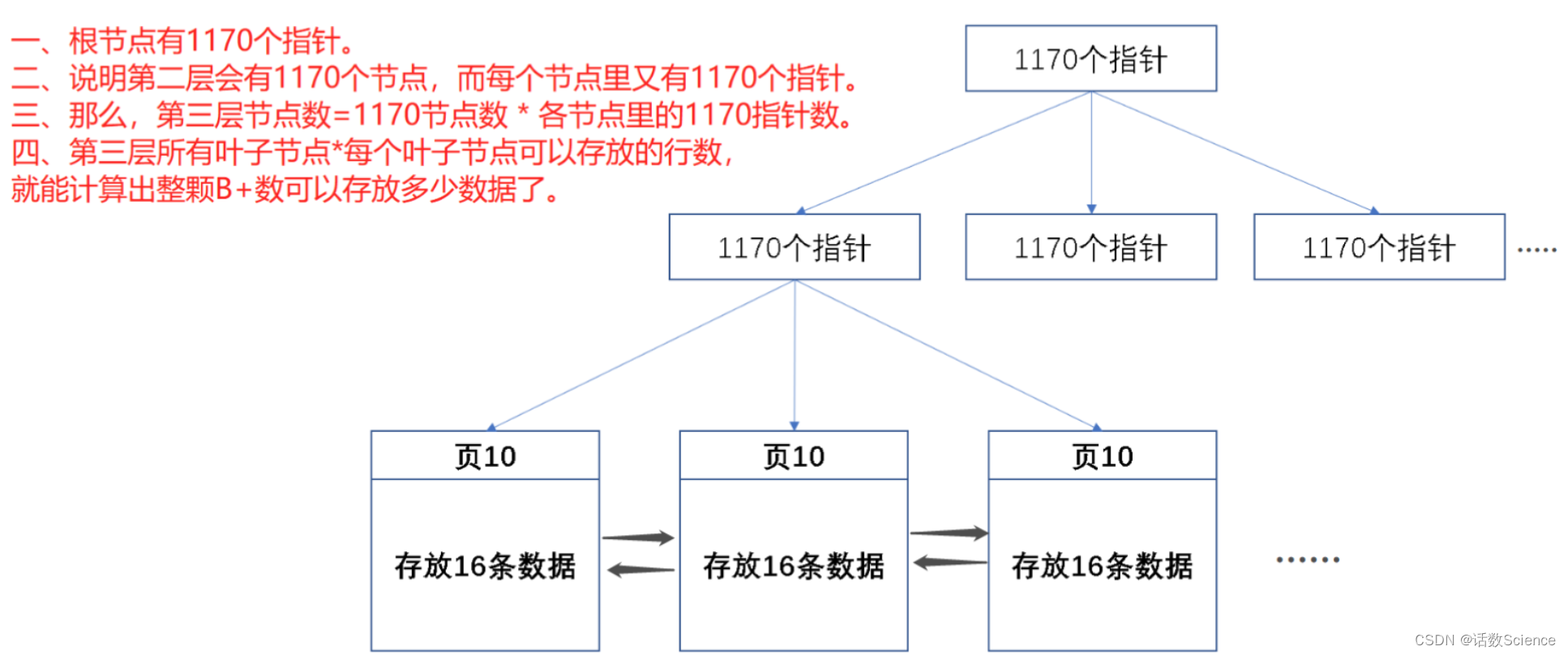
索引最大数据量
MySQL InnoDB默认页大小是16KB。
叶子节点
假设一行数据占用1KB的空间大小,然而实际上,除去字段很多的宽表外,其实很多简单的表行记录都远达不到1KB空间占比。这里我们用最坏的情况来假设一行记录大小为1KB,那么,一个16KB的页就可以存储16行数据。
叶子节点,存放的是大小为16KB的页数据,页数据里每一行记录大小为1KB,那么,一个叶子节点的页里就可以存放16条数据。
非叶子节点
MySQL中,指针地址大小为6字节,若索引是bigint类型,那么就为8字节,两者加起来总共是14字节。16384 字节 / 14 字节 = 1170 ,意味着,根节点有1170个页地址指针,然后,每个页地址指针指向的叶子节点可以存放16条数据。
三层情况下:1170 * 1170 * 16 = 21902400,得出两千万左右条数据。
PostgreSQL
限制
| 最大单个数据库大小 | 不限 |
| 最大数据单表大小 | 32 TB |
| 单条记录最大 | 1.6 TB |
| 单字段最大允许 | 1 GB |
| 单表允许最大记录数 | 不限 |
| 单表最大字段数 | 250 - 1600 (取决于字段类型) |
| 单表最大索引数 | 不限 |
PostgreSQL单表最大32T,不限制记录数,但最多能存多少条记录还要看单条记录大小和对查询性能的要求,如果没有复杂的查询或统计操作正常单表上亿条记录查询性能也是能接受的。否则就要考虑分区或分库分表操作。看网上经验值,为保证较好的查询性能,MySQL在单表1000w~2000w数据记录时就要考虑分库分表操作。
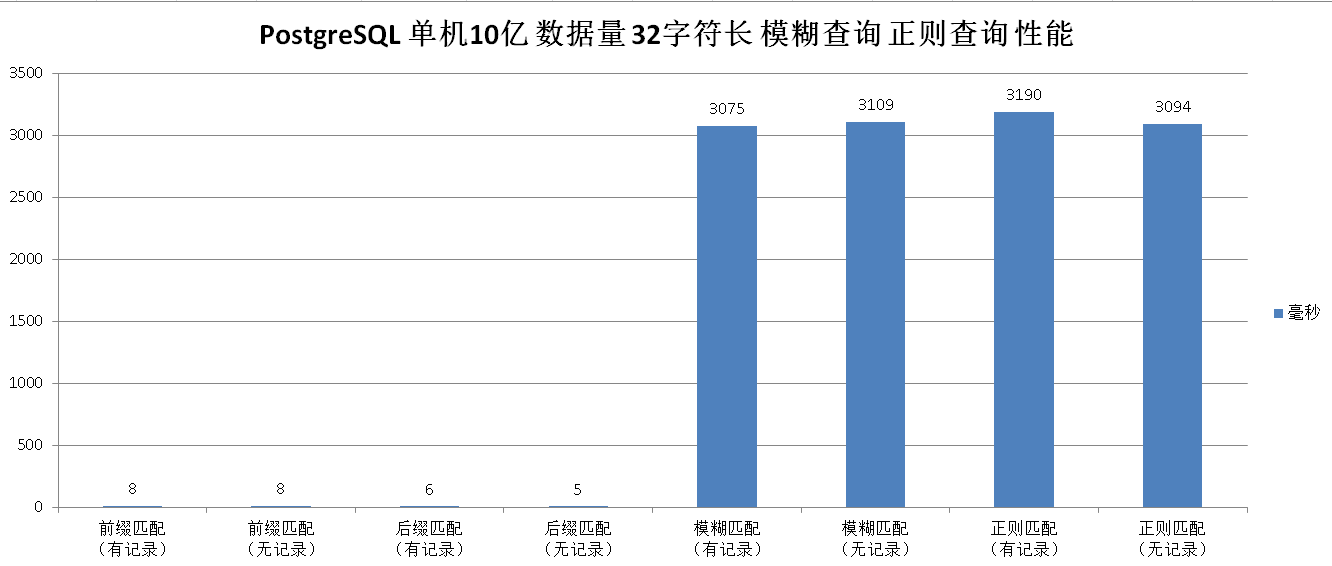
分库分表后会出现实物一致性、跨表Join查询、查询结果合并等一些列困难的问题,所以除非特殊情况,可以先考虑PgSql分区操作,分区可让数据文件存在不同硬盘分区上,但无法跨数据库,更不能跨服务器。但分区可以提供若干好处:
-
某些类型的查询性能可以得到极大提升。特别是表中访问率较高的行位于一个单独分区或少数几个分区上的情况下。分区可以减少索引体积从而可以将高使用率部分的索引存放在内存中。如果索引不能全部放在内存中,那么在索引上的读和写都会产生更多的磁盘访问。
-
当查询或更新一个分区的大部分记录时,连续扫描那个分区而不是使用索引离散的访问整个表可以获得巨大的性能提升。
-
如果需要大量加载或者删除的记录位于单独的分区上,那么可以通过直接读取或删除那个分区以获得巨大的性能提升,因为?ALTER TABLE?比操作大量的数据要快的多。它同时还可以避免由于大量?DELETE?导致的?VACUUM?超载。
-
很少用的数据可以移动到便宜一些的慢速存储介质上。
这种好处通常只有在表可能会变得非常大的情况下才有价值。到底多大的表会从分区中收益取决于具体的应用,不过有个基本的拇指规则就是表的大小超过了数据库服务器的物理内存大小。
索引
默认B-Tree索引
- B-Tree索引:?PostgreSQL 支持 B-Tree 索引和 Hash 索引。同时 PostgreSQL 还支持以下特性:
- 表达式索引:?我们可以为表达式或函数来创建一个索引,而不是用字段。
- 局部索引:?索引只是表的一部分
MVCC
Postgres 是第一个推出多版本并发控制(MVCC)的 DBMS,这意味着读取永远不会阻止写入,反之亦然。此功能是企业偏爱 Postgres 而不是 MySQL 的主要原因之一。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Oracle Linux 8.9 安装图解
- 代码救火队:try-catch-finally带你走出异常困境
- 【无标题】vue自定义表单验证的时候报错TypeError: callback is not a function
- 计算机网络实验二:Packet Tracer的简单使用
- go 设计模式之观察者模式
- 鸿蒙开发之Touch事件拦截stopPropagation()
- node中使用JWT实现token身份验证
- React16源码: Suspense与lazy源码实现
- 企业私有云容器化架构
- 鸿蒙开发之数据持久化存储Preferences