大语言模型系列-总述
发布时间:2024年01月15日
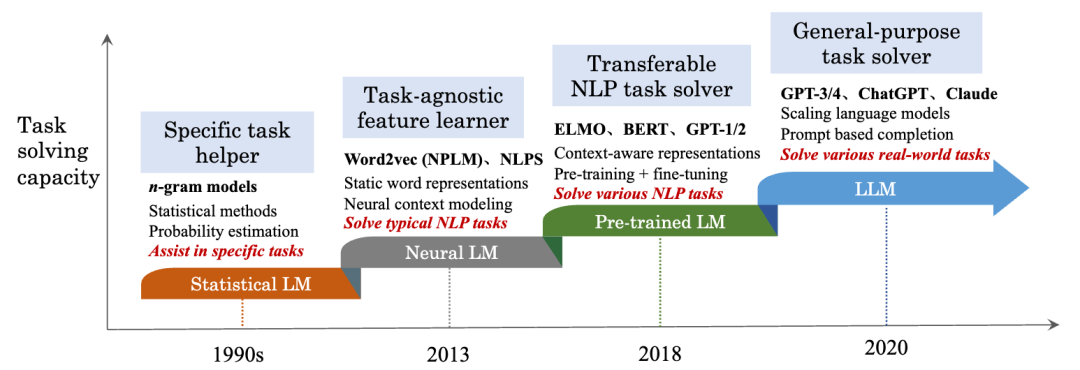
大语言模型发展史
研究人员发现,扩展预训练模型(Pre-training Language Model,PLM),例如扩展模型大小或数据大小,通常会提高下游任务的模型性能,模型大小从几十亿(1 B = 10亿)逐步扩展至千亿级别,后续研究者们将大型的PLM称之为LLM(Large Language Model)
从下图中可以看出大语言模型的发展阶段
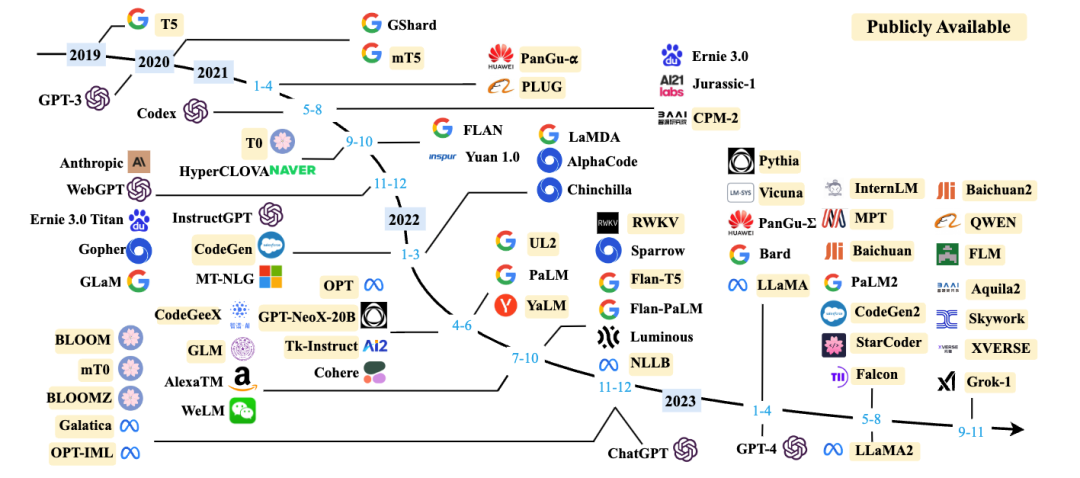
从下图中可以看出近年来主流的大语言模型
OpenAI发展史
![![[Pasted image 20231214154447.png]]](https://img-blog.csdnimg.cn/direct/b0bc705dd0d54cecb489a7404196c105.png)
大模型的技术路线
![![[Pasted image 20231213091014.png]]](https://img-blog.csdnimg.cn/direct/dd484456ceff4659997c48202137a12e.png)
从上图中可以看出,目前LLM的技术路线都是基于Transfomer架构的,主要分为Decoder only、Encoder only、Encoder-Decoder三种:
| 技术路线 | 预训练架构 | 模型 | 描述 |
|---|---|---|---|
| Decoder only | Causal LM/Left-to-right LM | GPT-1,GPT-2,GPT-3,LLaMA等 | 具有自回归特性,只能看到历史输入序列,预测下一个token仅依赖于当前和历史输入,而不能参考后续输入信息,既能处理自然语言生成式任务(NLG),又能处理自然语言理解式任务(NLU)。 |
| Encoder only | Masked LM | BERT,RoBERTa等 | 不具有自回归特性,更适合于自然语言理解式任务(NLG),包括文本分类、情感分析,命名实体识别。 |
| Encoder-Decoder | Transformer LM | T5, BART等 | 擅长处理输入和输出序列之间存在复杂映射关系的任务,比如翻译和文本总结。 |
| Encoder-Decoder | Prefix LM | UniLM、GLM等 | 可以看到输入序列的前几个token作为条件上下文,在预测下一个token时同时参考前后信息,模型轻于Transformer LM,生成类任务的效果相差不大,语言理解类任务则存在明显差距。 |
![![[Pasted image 20240115160337.png]]](https://img-blog.csdnimg.cn/direct/061f3d28b37e457f96a89ec0c89fa31a.png)
必读论文
| 类别 | 流程/算法 | 论文、年份 | Google学术引用次数 |
|---|---|---|---|
| Transormer | 《Attention is all you need》,2017 | 104596 | |
| Decoder only | |||
| GPT-1 | 《Improving language understanding by generative pre-training》,2018 | 7365 | |
| GPT-2 | 《Language models are unsupervised multitask learners》,2019 | 7780 | |
| GPT-3 | 《Language models are few-shot learners》,2020 | 17941 | |
| GPT-3.5(ChatGPT) | 《Training language models to follow instructions with human feedback》,2022 | 3535 | |
| Llama | 《Llama: Open and efficient foundation language models》,2023 | 2974 | |
| Llama 2 | 《Llama 2: Open Foundation and Fine-Tuned Chat Models》,2023 | 1345 | |
| Encoder only | |||
| BERT | 《Bert: Pre-training of deep bidirectional transformers for language understanding》,2018 | 85950 | |
| RoBERTa | 《Roberta: A robustly optimized bert pretraining approach》,2019 | 10439 | |
| Encoder-Decoder | |||
| T5 | 《Exploring the limits of transfer learning with a unified text-to-text transformer》,2020 | 12381 | |
| BART | 《Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension》,2019 | 7495 | |
文章来源:https://blog.csdn.net/long11350/article/details/135607574
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- HTML-鼠标悬浮文案效果
- K8s中Service Account和RBAC
- 计算机毕业设计 基于SpringBoot的大学生平时成绩量化管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- 【Java】猜数字小游戏
- k8s部署nginx-ingress服务
- 面试小知识点整合
- 开发安全之:Cross-Site Scripting: Poor Validation
- 使用AutoDL云计算平台训练并测试Pytorch版本NeRF代码
- 前端常见问题
- SSM整合-01