BP神经网络(公式推导+举例应用)
引言
人工神经网络(Artificial Neural Networks,ANNs)作为一种模拟生物神经系统的计算模型,在模式识别、数据挖掘、图像处理等领域取得了显著的成功。其中,BP神经网络(Backpropagation Neural Network,BPNN)作为一种常见的前馈式神经网络,以其在模式学习和逼近函数方面的优越性受到广泛关注。BP神经网络不仅能够处理非线性关系,还能够通过训练不断调整网络参数,实现对复杂模型的逼近,具有较强的自适应性和泛化能力。
本文旨在深入探讨BP神经网络的基本原理和数学模型,通过对其公式的详细推导,为读者提供清晰的理论基础。此外,通过具体的举例应用,展示BP神经网络在实际问题中的有效性和应用前景。通过对BP神经网络的深入理解,我们可以更好地应用和优化该模型,推动人工智能领域的发展。
在神经网络研究的历史长河中,BP神经网络无疑是一个重要的里程碑,其不断演化和改进为解决实际问题提供了有力的工具。通过深入研究BP神经网络,我们有望更好地理解神经网络的内在机理,推动其在各个领域的广泛应用。在人工智能日益发展的今天,BP神经网络仍然是一个备受关注的研究方向,本文将为读者提供对其深入理解的途径和启发。
M-P神经元模型
在生物神经网络中,每个神经元与其他神经元相连接,当它“兴奋”时,就会向相连接的神经元发送化学物质,从而改变这些神经元内的电位;若某神经元的电位超过一个“阈值”,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。我们将上述所描述的情形抽象为下图所示(M-P神经元模型):
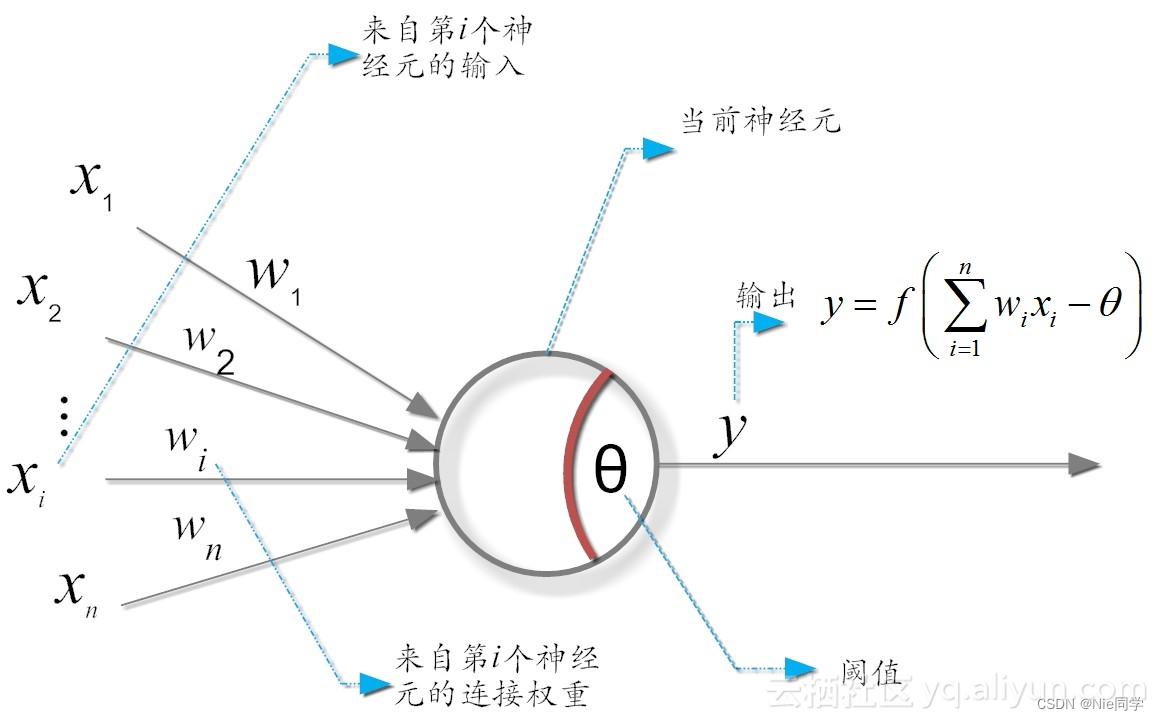
在这个模型中,神经元接受到来自
n
n
n个其他神经元传递过来的输入信号,这些输入信号通过带权的连接进行传递,神经元接受到的总输入值与神经元的阈值进行对比,然后通过”激活函数“处理以产生神经元的输出。
激活函数
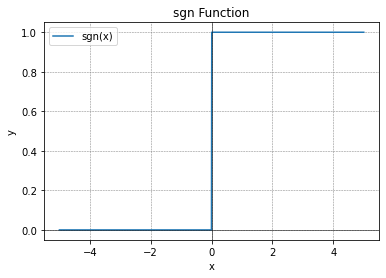
理想中的激活函数如下图所示:
s
g
n
(
x
)
=
{
1
,
x
≥
0
0
,
x
<
0
sgn(x)= \begin{cases} 1,\quad x\geq 0\\ 0, \quad x<0 \end{cases}
sgn(x)={1,x≥00,x<0?
显然“1”对应神经元兴奋、“0”对应神经元抑制。然而
s
g
n
(
x
)
sgn(x)
sgn(x)数学性质不好,不具备连续性且不光滑。因此实际上我们采用
s
i
g
m
o
i
d
sigmoid
sigmoid函数作为激活函数,典型的
s
i
g
m
o
i
d
sigmoid
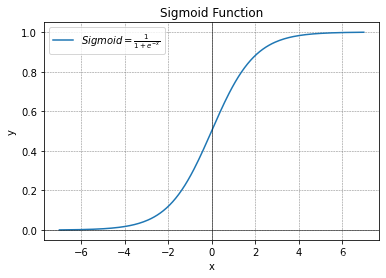
sigmoid函数如下图所示:
s
i
g
m
o
i
d
(
x
)
=
1
1
+
e
?
x
sigmoid(x)=\frac{1}{1+e^{-x}}
sigmoid(x)=1+e?x1?
然后将许多的神经元按一定的层次连接起来,就构成了一个神经网络。
多层前馈神经网络
常见的神经网络是形如下图所示的层级结构:
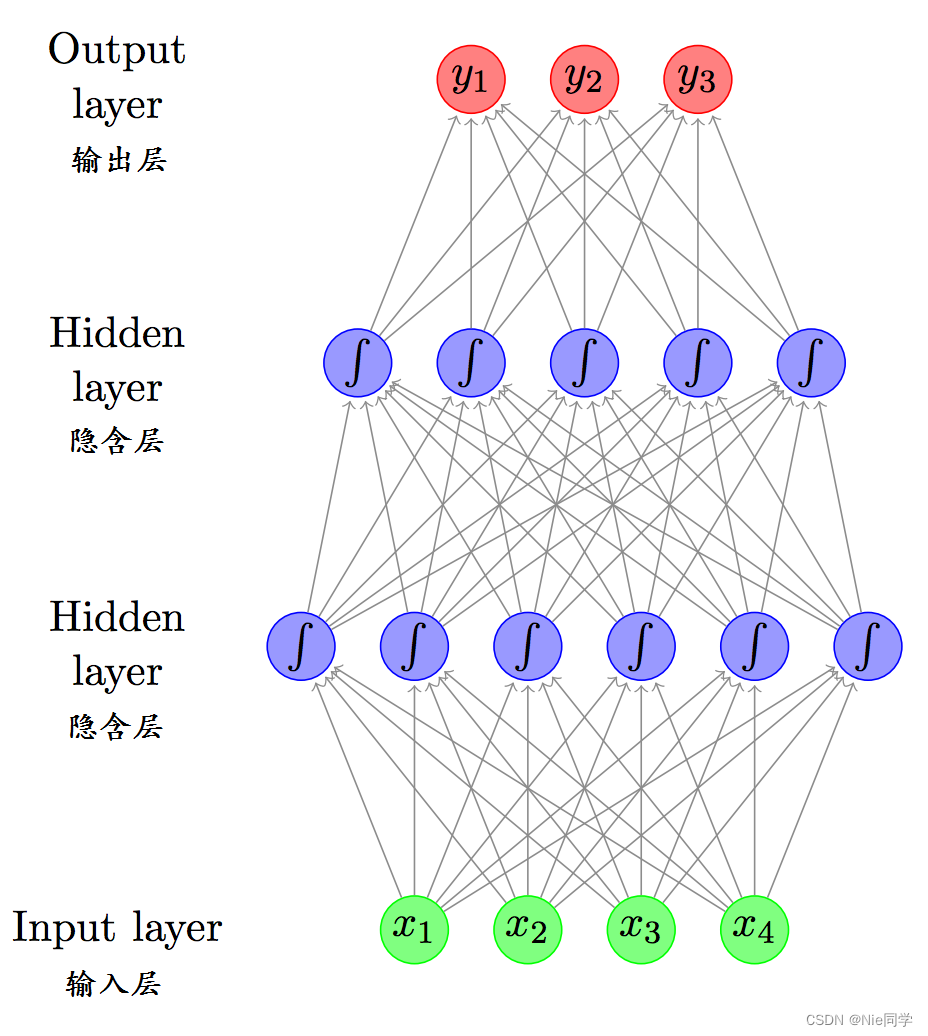
每层神经元与下一层神经元全连接,神经元之间不存在同层连接,也不存在跨层连接。这样的网络称为多层前馈神经网络。
误差逆传播算法
给定数据集
D
=
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
(
x
m
,
y
m
)
}
D=\{ (x_1,y_1),(x_2,y_2),...(x_m,y_m)\}
D={(x1?,y1?),(x2?,y2?),...(xm?,ym?)},
x
i
∈
?
d
,
y
i
∈
?
l
x_i\in \Re^d,y_i \in \Re^l
xi?∈?d,yi?∈?l,即输入样例由
d
d
d个属性描述,输出样例由
l
l
l维实值向量。下图给出一个拥有
d
d
d个输入神经元、
l
l
l个输出神经元、
q
q
q个隐层神经元的多层前反馈神经网络。其中输出层第
j
j
j个神经元的阈值用
θ
j
\theta_j
θj?表示,隐层第
h
h
h个神经元的阈值用
γ
h
\gamma_h
γh?表示。输入层第
i
i
i个神经元与隐层第
h
h
h个神经元之间的连接权为
v
i
h
v_{ih}
vih?,隐层第
h
h
h个神经元与输出层第
j
j
j个神经元之间的连接权为
w
h
j
w_{hj}
whj?。记隐层第
h
h
h个神经元接收到的输入为
α
h
=
∑
i
=
1
d
v
i
h
x
i
\alpha_h=\sum_{i=1}^dv_{ih}x_i
αh?=∑i=1d?vih?xi?,输出层第
j
j
j个神经元接收到的输入为
β
j
=
∑
h
=
1
q
w
h
j
b
h
\beta_j=\sum_{h=1}^qw_{hj}b_h
βj?=∑h=1q?whj?bh?。其中
b
h
b_h
bh?为隐层第
h
h
h个神经元的输出。
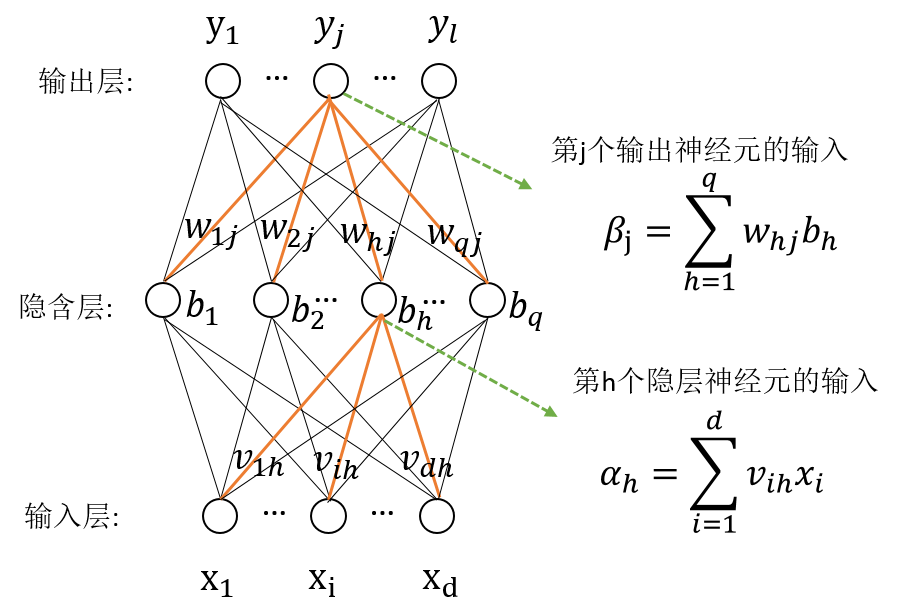
对训练集
(
x
k
,
y
k
)
(x_k,y_k)
(xk?,yk?),假定神经网络的输出为
y
^
j
k
=
(
y
^
1
k
,
y
^
1
k
,
.
.
.
,
y
^
l
k
)
\hat y_j^k=(\hat y_1^k,\hat y_1^k,...,\hat y_l^k)
y^?jk?=(y^?1k?,y^?1k?,...,y^?lk?)即
y
^
j
k
=
f
(
β
j
?
θ
j
)
(1)
\hat y_j^k=f(\beta_j-\theta_j) \tag{1}
y^?jk?=f(βj??θj?)(1)
则网络在
x
k
,
y
k
x_k,y_k
xk?,yk?上的均方误差为:
E
k
=
1
2
∑
j
=
1
l
(
y
^
j
k
?
y
j
k
)
2
(2)
E_k=\frac{1}{2}\sum_{j=1}^l(\hat y_j^k-y_j^k)^2 \tag{2}
Ek?=21?j=1∑l?(y^?jk??yjk?)2(2)
其中
y
^
j
k
\hat y_j^k
y^?jk?为神经网络模型输出,
y
j
k
y_j^k
yjk?为训练集实际样例输出。
故在上图网络中共有
(
d
+
l
+
1
)
q
+
l
(d+l+1)q+l
(d+l+1)q+l个参数。BP是一个迭代学习算法,在迭代的每一轮中采用广义感知机学习规则对参数进行更新估计,任意参数
v
v
v的更新估计式为:
v
←
v
+
Δ
v
(3)
v\leftarrow v+\Delta v \tag{3}
v←v+Δv(3)
以上图的BP网络中隐层到输出层的连接权
w
h
j
w_{hj}
whj?为例来进行推导:
BP算法基于梯度下降法,以目标的负梯度方向对参数进行调整,对误差
E
k
E_k
Ek?,给定学习率
η
\eta
η,有:
Δ
w
h
j
=
?
η
?
E
k
?
w
h
j
(4)
\Delta w_{hj}=-\eta \frac{\partial E_k}{\partial w_{hj}} \tag{4}
Δwhj?=?η?whj??Ek??(4)
我们注意到
w
h
j
w_{hj}
whj?先影响到第
j
j
j个输出层神经元的输入值
β
j
\beta_j
βj?,再影响到输出值
y
^
j
k
\hat y_j^k
y^?jk?,最终影响到
E
k
E_k
Ek?,有:
?
E
k
?
w
h
j
=
?
E
k
?
y
^
j
k
?
?
y
^
j
k
?
β
j
?
?
β
j
?
w
h
j
(5)
\frac{\partial E_k}{\partial w_{hj}}=\frac{\partial E_k}{\partial \hat y_j^k}\cdot \frac{\partial \hat y_j^k}{\partial \beta_j}\cdot \frac{\partial \beta_j}{\partial w_{hj}} \tag{5}
?whj??Ek??=?y^?jk??Ek????βj??y^?jk????whj??βj??(5)
根据
β
j
=
∑
h
=
1
q
w
h
j
h
h
\beta_j=\sum_{h=1}^qw_{hj}h_h
βj?=∑h=1q?whj?hh?的定义,显然有:
?
β
j
?
w
h
j
=
b
h
(6)
\frac{\partial \beta_j}{\partial w_{hj}}=b_h \tag{6}
?whj??βj??=bh?(6)
又因为
s
i
g
m
o
i
d
sigmoid
sigmoid函数有一个很好的数学性质:
f
′
(
x
)
=
f
(
x
)
(
1
?
f
(
x
)
)
(7)
f^\prime(x)=f(x)(1-f(x)) \tag{7}
f′(x)=f(x)(1?f(x))(7)
根据式子(1)和(2),有:
g
j
=
?
?
E
k
?
y
^
j
k
?
?
y
^
j
k
?
β
j
=
?
(
y
^
j
k
?
y
j
k
)
f
′
(
β
j
?
θ
j
)
=
y
^
j
k
(
1
?
y
^
j
k
)
(
y
j
k
?
y
^
j
k
)
(8)
\begin{align*} g_j & = -\frac{\partial E_k}{\partial \hat y_j^k}\cdot \frac{\partial \hat y_j^k}{\partial \beta_j} \\ & = -(\hat y_j^k-y_j^k)f^\prime(\beta_j-\theta_j) \\ & = \hat y_j^k(1-\hat y_j^k)(y_j^k-\hat y_j^k) \end{align*} \tag{8}
gj??=??y^?jk??Ek????βj??y^?jk??=?(y^?jk??yjk?)f′(βj??θj?)=y^?jk?(1?y^?jk?)(yjk??y^?jk?)?(8)
其中
E
k
=
1
2
∑
j
=
1
l
(
y
^
j
k
?
y
j
k
)
2
E_k=\frac{1}{2}\sum_{j=1}^l(\hat y_j^k-y_j^k)^2
Ek?=21?∑j=1l?(y^?jk??yjk?)2,那么
?
E
k
?
y
^
j
k
=
y
^
j
k
?
y
j
k
\frac{\partial E_k}{\partial \hat y_j^k}=\hat y_j^k-y_j^k
?y^?jk??Ek??=y^?jk??yjk?。
y
^
j
k
=
f
(
β
j
?
θ
j
)
\hat y_j^k=f(\beta_j-\theta_j)
y^?jk?=f(βj??θj?),那么
?
y
^
j
k
?
β
j
=
f
′
(
β
j
?
θ
j
)
=
f
(
β
j
?
θ
j
)
?
(
1
?
f
(
β
j
?
θ
j
)
)
=
y
^
j
k
?
(
1
?
y
^
j
k
)
\frac{\partial \hat y_j^k}{\partial \beta_j}=f^\prime(\beta_j-\theta_j)=f(\beta_j-\theta_j)\cdot(1-f(\beta_j-\theta_j))=\hat y_j^k\cdot (1-\hat y_j^k)
?βj??y^?jk??=f′(βj??θj?)=f(βj??θj?)?(1?f(βj??θj?))=y^?jk??(1?y^?jk?)
将(6)和(8)带入(5)中有:
?
E
k
?
w
h
j
=
g
j
?
b
h
(9)
\frac{\partial E_k}{\partial w_{hj}}=g_j\cdot b_h \tag{9}
?whj??Ek??=gj??bh?(9)
再将(9)带入(4)中,得到BP算法 中关于
w
h
j
w_{hj}
whj?的更新公式:
Δ
w
h
j
=
?
η
g
j
b
h
(10)
\Delta w_{hj}=-\eta g_jb_h \tag{10}
Δwhj?=?ηgj?bh?(10)
同理可得:
Δ
θ
j
=
?
η
g
j
(11)
\Delta\theta_j=-\eta g_j \tag{11}
Δθj?=?ηgj?(11)
Δ
v
i
h
=
η
e
h
x
i
(12)
\Delta v_{ih}=\eta e_hx_i \tag{12}
Δvih?=ηeh?xi?(12)
Δ
γ
h
=
?
η
e
h
(13)
\Delta \gamma_h=-\eta e_h \tag{13}
Δγh?=?ηeh?(13)
其中
e
h
=
?
?
E
k
?
b
h
?
?
b
h
?
α
h
=
?
∑
j
=
1
l
?
E
k
?
β
j
?
?
β
j
?
b
h
f
′
(
α
h
?
γ
h
)
=
∑
j
=
1
l
w
h
j
g
j
f
′
(
α
h
?
γ
h
)
=
b
h
(
1
?
b
h
)
∑
j
=
1
l
w
h
j
g
j
(14)
\begin{align*} e_h & = -\frac{\partial E_k}{\partial b_h}\cdot \frac{\partial b_h}{\partial \alpha_h} \\ & = -\sum_{j=1}^l \frac{\partial E_k}{\partial \beta_j}\cdot\frac{\partial \beta_j}{\partial b_h}f^\prime(\alpha_h-\gamma_h) \\ & = \sum_{j=1}^lw_{hj}g_jf^\prime(\alpha_h-\gamma_h) \\ & = b_h(1-b_h)\sum_{j=1}^lw_{hj}g_j \end{align*} \tag{14}
eh??=??bh??Ek????αh??bh??=?j=1∑l??βj??Ek????bh??βj??f′(αh??γh?)=j=1∑l?whj?gj?f′(αh??γh?)=bh?(1?bh?)j=1∑l?whj?gj??(14)
其中
b
h
b_h
bh?是隐层神经元的输出
b
h
=
f
(
α
h
?
γ
h
)
b_h=f(\alpha_h-\gamma_h)
bh?=f(αh??γh?),
γ
h
\gamma_h
γh?是隐层神经元的阈值,
α
h
\alpha_h
αh?是隐层神经元的输入。
直到所有参数调整至累计误差最小即:
E
m
i
n
=
1
m
∑
k
=
1
m
E
k
(15)
E_{min}=\frac{1}{m}\sum_{k=1}^mE_k \tag{15}
Emin?=m1?k=1∑m?Ek?(15)
缓解过拟合化
由于BP神经网络强大的表示能力,BP神经网络经常遭遇过拟合化,其训练误差持续降低,但测试误差却可能上升。共有两种策略来缓解BP网络的过拟合化。
- 早停:基本思想是在训练过程中监测验证集(一部分未参与训练的数据)上的性能,并在验证集性能达到最优时停止训练,而不是继续训练直到训练误差降为零。
- 正则化:正则化通过修改损失函数,向优化过程中引入额外的惩罚项,从而限制模型的复杂性。这有助于防止神经网络对训练数据过度拟合。在神经网络中,L2(范数) 正则化的损失函数,则误差目标函数为:
E = λ 1 m ∑ k = 1 m E k + ( 1 ? λ ) ∑ i w i 2 (16) E=\lambda\frac{1}{m}\sum_{k=1}^mE_k+(1-\lambda)\sum_{i}w_i^2 \tag{16} E=λm1?k=1∑m?Ek?+(1?λ)i∑?wi2?(16)
其中 λ ∈ ( 0 , 1 ) \lambda \in (0,1) λ∈(0,1),用来对经验风险和结构风险进行折中处理。其中经验风险为 1 m ∑ k = 1 m E k \frac{1}{m}\sum_{k=1}^mE_k m1?∑k=1m?Ek?,结构风险为 ∑ i w i 2 \sum_{i}w_i^2 ∑i?wi2?。
结论
在神经网络领域,BP神经网络是一种重要的前馈神经网络,以其在模式学习和逼近函数方面的优越性而备受关注。本文深入探讨了BP神经网络的基本原理和数学模型,通过对其公式的详细推导,为读者提供了清晰的理论基础。
文章首先介绍了M-P神经元模型,将其抽象为神经网络的基本组成单元。激活函数的选择是神经网络设计中关键的一步,文中提到了理想中的激活函数以及实际中常用的 s i g m o i d sigmoid sigmoid函数。
多层前馈神经网络的结构被详细介绍,说明了其层级结构和连接方式。这种结构的神经网络被广泛应用于各个领域,能够处理非线性关系,通过训练调整网络参数,实现对复杂模型的逼近,具有较强的自适应性和泛化能力。
误差逆传播算法是BP神经网络训练的核心,文章通过数学推导详细解释了权重和阈值的更新过程。梯度下降法是其中的关键步骤,通过计算误差对参数的偏导数,实现对参数的调整。
然后,文章提到了BP神经网络容易面临的问题之一,即过拟合。为了缓解过拟合,介绍了两种常用的方法:早停和正则化。早停通过在训练过程中监测验证集性能,及时停止训练,避免过度拟合。正则化通过修改损失函数引入额外的惩罚项,限制模型复杂性,有助于防止神经网络对训练数据过度拟合。
实验分析
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPRegressor
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# 读入数据集
data = pd.read_csv('data/predict_room_price.csv')
进行数据的预处理
# 特征和标签
X = data.drop('Price', axis=1)
y = data['Price']
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集
X_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
X_valid, X_test, y_valid, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
构建神经网络模型
# 创建BP神经网络模型
model = MLPRegressor(hidden_layer_sizes=(20, 20), max_iter=1000, random_state=42, alpha=0.01, learning_rate='adaptive')
训练、预测并评估模型性能
# 训练模型
model.fit(X_train, y_train)
# 在验证集上预测
y_valid_pred = model.predict(X_valid)
# 评估模型性能
valid_loss = mean_squared_error(y_valid, y_valid_pred)
print(f'Validation Loss: {valid_loss}')
# 在测试集上预测
y_test_pred = model.predict(X_test)
# 评估模型性能
test_loss = mean_squared_error(y_test, y_test_pred)
print(f'Test Loss: {test_loss}')
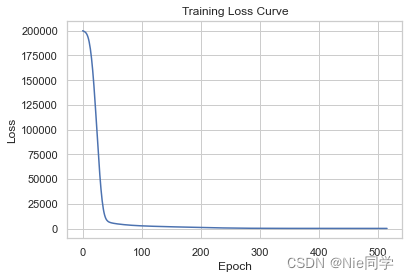
# 绘制损失曲线
plt.plot(model.loss_curve_)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.show()
Validation Loss: 429.78130878683345
Test Loss: 436.7118813730095
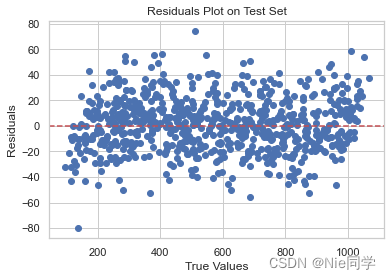
residuals = y_test - y_test_pred
plt.scatter(y_test, residuals)
plt.axhline(y=0, color='r', linestyle='--')
plt.xlabel('True Values')
plt.ylabel('Residuals')
plt.title('Residuals Plot on Test Set')
plt.show()
from sklearn.metrics import r2_score
r2_valid = r2_score(y_valid, y_valid_pred)
print(f'R2 Score on Validation Set: {r2_valid}')
r2_test = r2_score(y_test, y_test_pred)
print(f'R2 Score on Test Set: {r2_test}')
R2 Score on Validation Set: 0.9939169086519464
R2 Score on Test Set: 0.9934083540996065
由上述评价指标可知:
-
残差图:
- 散点在区间[-80, 80]内,说明模型的预测相对较为准确,大多数样本的预测误差在这个范围内。
- 点集中在[-20, 20]上,表示大部分样本的残差(实际值与预测值之差)都集中在这个范围内,这也表明模型的整体性能较好。
-
Validation Loss 和 Test Loss:非常低的Validation Loss和Test Loss,说明模型在验证集和测试集上都取得了很好的性能。这表明模型对数据的拟合效果很好,预测值与实际值之间的误差很小。
-
R2 Score on Validation Set 和 Test Set:非常接近于1的R2 Score,表明模型对于验证集和测试集的解释方差非常高。R2 Score是一个用于评估模型拟合程度的指标,接近1表示模型能够很好地解释目标变量的变异性。
总体来说,根据残差图、Validation Loss、Test Loss以及R2 Score的结果,模型表现出色,能够很好地拟合数据并具有较高的泛化能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SpringCloud(H版&alibaba)框架开发教程之gateway——附源码(5)
- 【sklearn练习】model常用属性和功能
- 电子签名实名认证的必要性解析
- 少儿编程:从兴趣到升学的关键之路
- scrapy爬虫实战
- Efficient Classification of Very Large Images with Tiny Objects(CVPR2022补1)
- 技术变革下的职业危机
- Python为何那么流行?Python火的资本在哪里?
- JavaScript初级知识(2)
- Vue2.0 -- 组件局部注册