Python爬虫-爬取豆瓣Top250电影信息
🎈 博主:一只程序猿子
🎈?博客主页:一只程序猿子 博客主页
🎈?个人介绍:爱好(bushi)编程!
🎈 创作不易:喜欢的话麻烦您点个👍和?!
🎈?除此之外您还可以通过个人名片联系我

额滴名片儿
目录
1.介绍
? ? ? ? 本文将详细介绍如何编写Python爬虫爬取豆瓣电影排行榜Top250榜单电影信息!
????????首先,感谢各位童鞋们的点赞、关注、收藏!!!
????????其次,如果在编写代码的过程中,如果有任何疑问,可以在评论区留言、私信或名片联系我!!!
2.网页分析
(1)获取电影列表
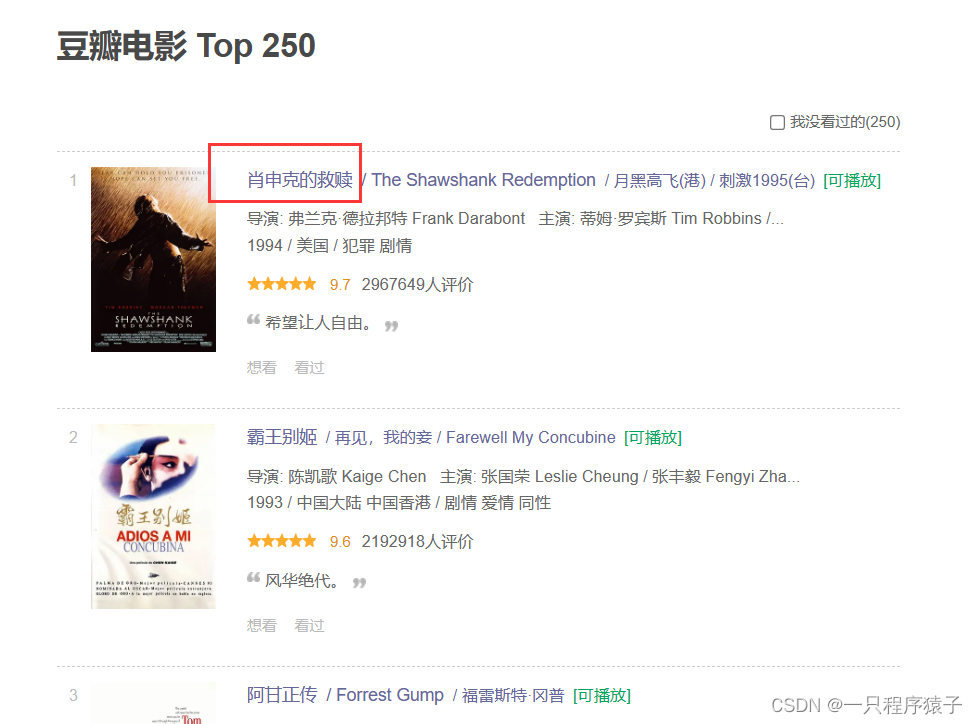
?????????这里我们需要获取电影的名称和对应的URL地址:
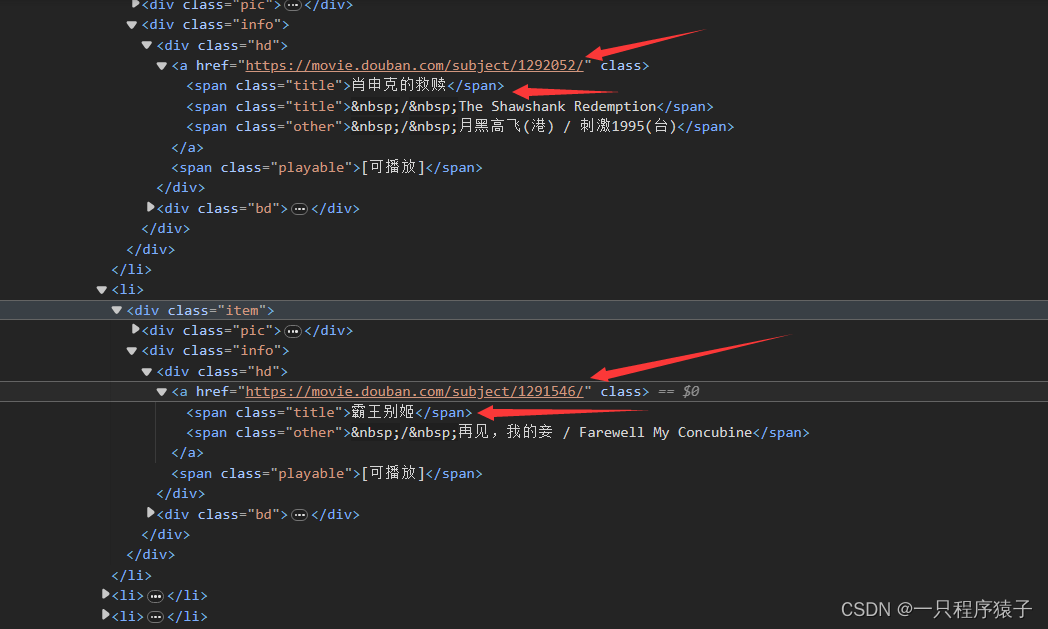
????????每一个li标签下都存放着一个电影,可见一页共有25个电影,一共有10个页面。我们需要把10个页面的电影名称和电影URL获取出来。
? ? ? ? 每一页的url变化:

? ? ? ? 可以看到只需要修改参数start=?即可实现换页!
(2)获取电影信息
? ? ? ? 第一步我们获取到了电影名称和电影URL,通过电影URL可以进入到电影的详情页面:
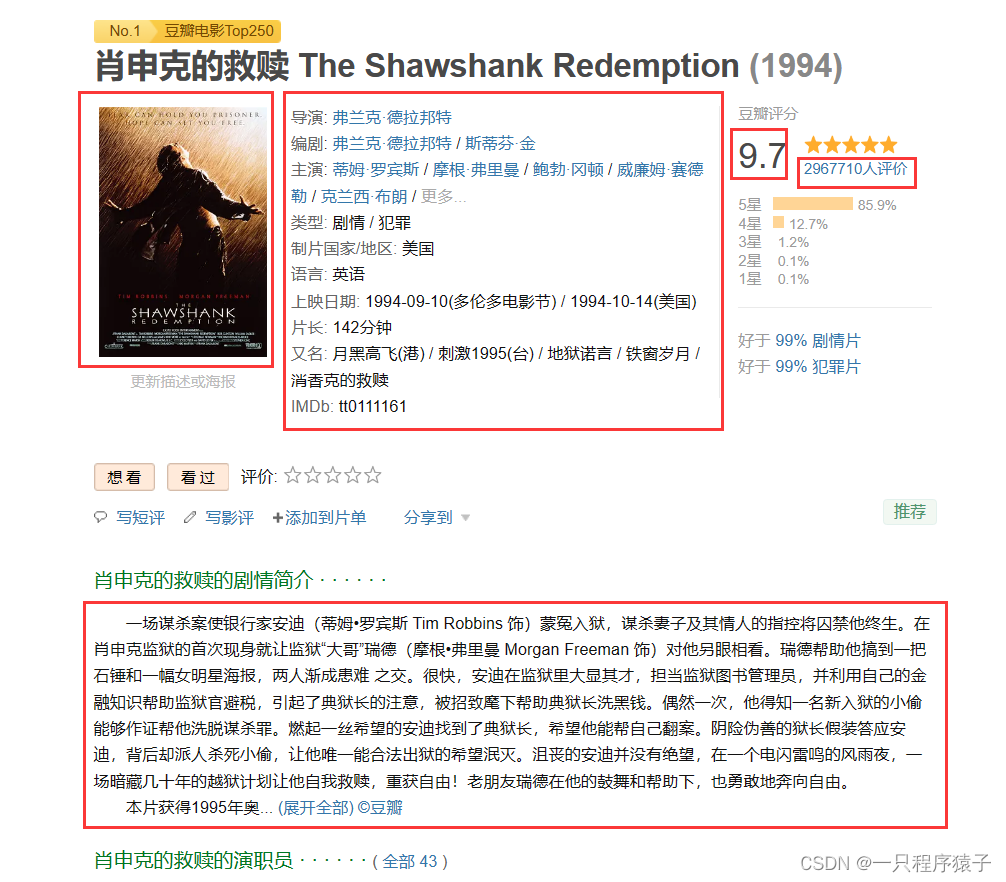
????????红色框标记出了我们需要获取的信息,我们将在代码中使用BeautifulSoup来匹配出对应的内容!当然,你也可以选择使用xpath或者正则表达式匹配数据!
3.源码
import random
import time
import requests
from bs4 import BeautifulSoup
class DouBan_top250(object):
def __init__(self):
self.cookies = {
'''换成你自己的cookies'''
}
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*'
'/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
def get_movie_list(self, start):
params = {
'start': str(start),
'filter': '',
}
html_content = requests.get('https://movie.douban.com/top250', params=params, cookies=self.cookies,
headers=self.headers).text
soup = BeautifulSoup(html_content, 'html.parser')
ol_tag = soup.find('ol', {'class': 'grid_view'})
li_tags = ol_tag.find_all('div', {'class': 'info'})
titles =[]
urls = []
for li_tag in li_tags:
title = li_tag.find('span', {'class': 'title'}).get_text()
url = li_tag.find('a').get('href')
titles.append(title)
urls.append(url)
return titles, urls
def get_movie_info(self, url):
resp = requests.get(url, headers=self.headers, cookies=self.cookies)
if resp.status_code == 200:
soup = BeautifulSoup(resp.text, 'html.parser')
info = soup.find('div', {'id': 'info'})
# 封面图片的URL
img_url = soup.find('a', {'class': 'nbgnbg'}).find('img').get('src')
# 导演
director = info.find_all('span', {'class': 'attrs'})[0].get_text()
# 编剧
scriptwriter = info.find_all('span', {'class': 'attrs'})[1].get_text().split(' /')
# 主演
actors = info.find_all('span', {'class': 'attrs'})[2].get_text().split(' /')
# 类型
type_tags = info.find_all('span', {'property': 'v:genre'})
types = []
for type_tag in type_tags:
types.append(type_tag.get_text())
# 制片国家/地区
country = info.find_all('span', {'class': 'pl'})[4].next_sibling.strip().split(' / ')
# 语言
language = info.find_all('span', {'class': 'pl'})[5].next_sibling.strip().split(' / ')
try:
# 简介
intro = soup.find('div', {'class': 'indent', 'id': 'link-report-intra'})\
.find('span', {'class': 'all hidden'}).get_text()\
.replace(' ', '').replace('\u3000', ' ').replace('\n\n', '\n').strip('\n')
except AttributeError as e:
# 简介
intro = soup.find('div', {'class': 'indent', 'id': 'link-report-intra'})\
.find('span').get_text()\
.replace(' ', '').replace('\u3000', ' ').replace('\n\n', '\n').strip('\n')
rating = soup.find('strong', {'class': 'll rating_num'}).get_text()
rating_people = soup.find('span', {'property': 'v:votes'}).get_text()
# print(director, scriptwriter, actors, types, country, language, intro, rating, rating_people, img_url)
movie_info = [director, scriptwriter, actors, types, country, language, intro, rating, rating_people, img_url]
else:
print(f'数据请求失败。。。状态码:{resp.status_code}')
movie_info = ['', '', '', '', '', '', '', '', '', '']
return movie_info
def main(self):
start = 0
while start <= 25:
titles, urls = self.get_movie_list(start)
time.sleep(1)
for title, url in zip(titles, urls):
print(title, url)
movie_info = self.get_movie_info(url)
movie_info.insert(0, title)
print(movie_info)
time.sleep(random.randint(2, 5))
start += 25
time.sleep(random.randint(2, 5))
if __name__ == '__main__':
douban = DouBan_top250()
douban.main()
????????这是一个完整的源码, 你拿到后只要不缺少相关的模块库,添加上你自己浏览器访问豆瓣网的cookies就可正常运行!!
? ? ? ? 因为时间关系,这次我在代码中添加的注释很少,后续有时间我再优化一下这一部分!争取添加更多的注释帮助你理解代码!!
4.效果展示
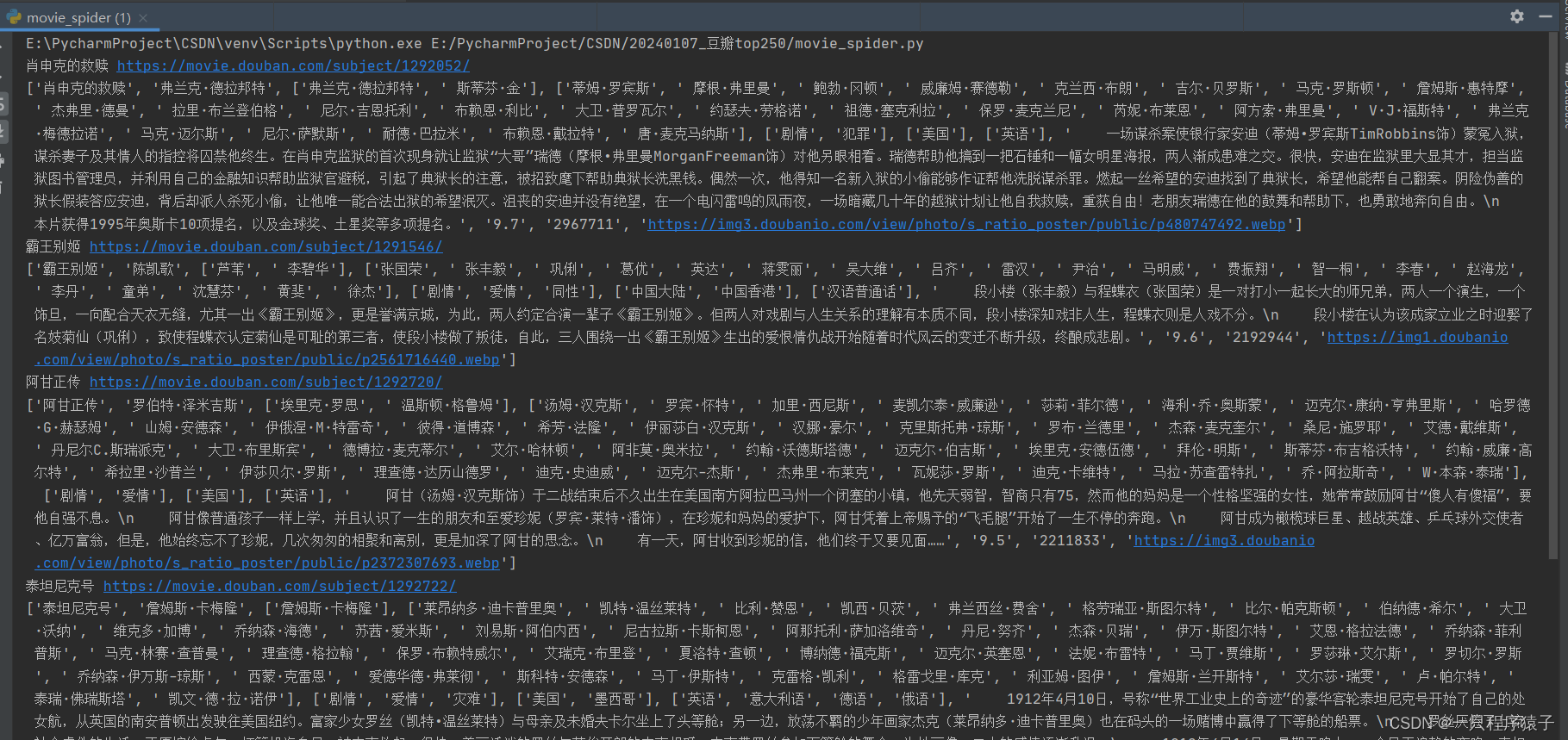
列表中的数据分别对应的是:【电影名称、导演、编剧、主演、电影类型、制片国家、?语言、电影简介、评分、评分人数、封面URL】?
5.结语
? ? ? ? 本篇文章中,我仅实现了获取到豆瓣网电影排行榜Top250的电影信息,但是我还没有实现把获取到的信息保存到表格中或保存到数据库,把电影封面图片下载到本地,后续的文章中我将把这些功能实现!
????????如果你对本文感兴趣且想要把数据持久化存储,可以留意我后续发布的文章!
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PHP语言B/S架构医院(安全)不良事件上报系统源码
- 基于YOLOv7算法的高精度实时六类水果目标检测识别系统(PyTorch+Pyside6+YOLOv7)
- 数的高次幂运算取余,解决大数溢出问题
- 选择排序(二)——堆排序(性能)与直接选择排序
- 【大数据实训】基于当当网图书信息的数据分析与可视化(八)
- SpringBoot 全局异常统一处理:BindException(绑定异常)
- v_116 基于微信小程序的计算机等级考试移动学习平台设计与实现(源码+论文)
- 如何用docke启动redis?(解决双击docker服务闪退问题)
- 软件工程_复习
- Docker 配置 Gitea + Drone 搭建 CI/CD 平台