百度一面整理
面试时间:2023.11.13 19:00
三分钟自我介绍
工程相关
1、解释一下pipeline。
输入、推理、decode、推理结果业务处理
2、输入图片时GPU、CPU利用率上不来怎么解决。
微服务
CUDA相关
1、解释一下cuda中stream的作用?
cuda中的stream是GPU中的操作隊列。相同流串行執行,不同流并行執行。当不手动创建流时,cuda将会默认一个流操作。
stream的創建和銷毀:cudaStreamCreate、cudaStreamDestroy
stream的同步和查询:cudaStreamSyncronize、cudaStreamQuery
stream的优先级和属性设置:cudaStreamCreateWithPriority cudaStreamGetPriority
stream的错误处理:cudaStreamGetLastError cudaStreamGetEvent
stream的内存管理:cudaMallocAsync cudaFreeAsync异步的分配和释放
stream的数据传输:cudaMemcpyAsync cudaMemsetAsync异步的拷贝和初始化
stream的内核执行:<<<...>>> 或者 cudaLaunchKernel在stream中异步执行kernel函数
stream的事件管理:cudaEventCreate cudaEventDestroy cudaEventRecord cudaEventSyncronize
stream的图管理:cudaGraph创建和使用cuda图,使用cudaGraphLaunch,在steam中执行CUDA图。
这是我输入的提示让ChatGPT帮我生成的代码用于API的学习:
帮我使用cudaStreamCreate创建一个流,在该stream中我需要使用cudaMallocAsync异步分配一段内存,该内存用来存储一个数组。在我的kernel函数中给定一个数,查询数组中是否有相同的元素,查询成功并返回下标,我需要要用cudaEventCreate进行事件管理,并使用cudaGetLastError来捕捉错误信息。根据我的描述帮我生成一段cuda代码。
2、GPU的线程层次?
线程(thread):
线程是GPU上的最基本的执行单元,每个线程负责处理一部分数据,多个线程执行相同的计算任务。
线程块(block):
1、线程块是由一组线程组成的。
2、同一个线程块中的线程可以并发的在一个SM上执行,访问同一块共享内存。
3、block之间是相互独立的,不能通信和协作。
线程网格(grid):
一个线程网格中由一组线程块组成,同一线程网格中的所有线程块共享全局内存空间,可以通过kernel函数启动线程网格。
线程束(wrapper管理器):
线程束是sm上基本调度和执行单元。一个线程束包含32个线程。
一个SM上有一个或者多个线程束。
一个SP在一个时钟周期只有一个线程。
网格和块的维度:x,y,z
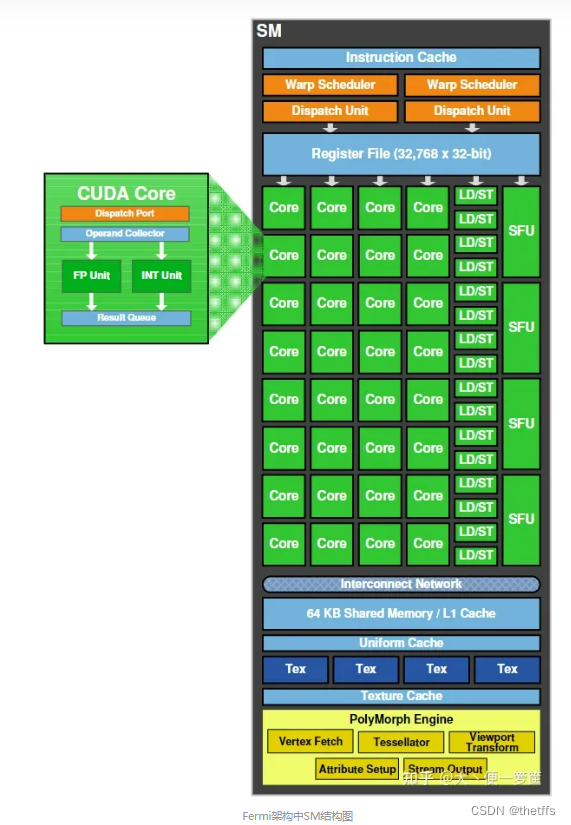
3、sp和sm的包含关系,各自对应软件层面、硬件层面?
SP和SM都是GPU上的硬件单元。SP是流处理器,是GPU上最基本的处理单元,每个SP负责处理一部分数据,执行相同的计算任务。
SM是流式多处理器,是由多个SP加上其他的一些资源组成的,每个SM可以并行地处理多个warp。
从以下几个维度理解SM:
基本定义:
- 在NVIDIA GPU中,每个SM都可以并行执行多个线程。
- 一个SM包含了多个CUDA核心(或称为ALU、SP、CUDA核心),每个核心可以在一个时钟周期内执行一个线程。
线程束(Warp):
- 一个线程束是由32个线程组成的,它们会被同时调度到一个SM上执行。
- 但这32个线程执行相同的指令但对不同的数据,即SIMD(单指令多数据)的并行执行模式。
块与SM的关系:
- 当我们在CUDA中启动一个内核,线程块会被分派到可用的SM上执行。
- 一个SM可以同时执行多个线程块,但一个线程块在其生命周期中只会执行在一个SM上。
- 一个SM上可以运行的线程数受到其寄存器和共享内存的限制。
资源分配:
- 每个SM都有一定数量的寄存器、共享内存、L1缓存和其他资源。
- 线程块内的线程共享这些资源。
- 寄存器和共享内存的使用量决定了一个SM上可以执行的最大线程和线程块数量。
调度与执行:
- SM包含一个或多个调度器,它们会从多个线程束中选择线程束进行执行。
- 当一个线程束在等待某事件(例如内存读取)时,调度器可以快速切换到另一个线程束,以保持ALUs的忙碌并隐藏延迟。
架构的差异:
- 不同的NVIDIA GPU架构(例如Turing, Pascal, Maxwell, Kepler等)具有不同的SM设计和资源配置。
- 例如,某些架构可能在每个SM上有更多的CUDA核心,而其他架构可能有更多的共享内存或寄存器。
重要性:
- SM是NVIDIA GPU的计算引擎。为了充分利用GPU,我们需要充分利用所有的SM。
- 当设计CUDA程序时,考虑如何均匀地将工作负载分配到每个SM上并最大化其利用率是很重要的。
4、cuda kernel函数的优化方法?
????????根据GPU的硬件特性和核函数的特点,合理地配置线程数、块数、网格数等参数,以达到最大化并行执行和最高的占用率。
????????优化内存使用方法,尽量减少对全局内存的访问次数和重复数据的访问,利用共享内存、纹理内存、常量内存等高速缓存来提高内存吞吐量。
????????优化指令使用方式,尽量避免使用循环、分支等导致控制流发散的指令,使用模板参数、内联函数、位运算等技巧来减少指令数和提高指令吞吐量。
????????使用数学库、算法库、性能分析工具等辅助工具,如cuBLAS、cuFFT、cuDNN、nvprof等,来提供高效的数学运算、算法实现、性能分析等功能。
- GPU编程2–CUDA核函数和线程配置
- 如何实现一个高效的Softmax CUDA kernel?——OneFlow 性能优化分享
- CUDA优化总结
- CUDA程序调优指南(二):性能调优
- CUDA程序优化方法
5、写kernel函数的时候如果分配的线程不足32个,wrapper管理器会怎么分配?
补充了解的概念
设备重叠:GPU中的设备重叠是指能够并行数据传输和内核执行,这样有利于提高GPU利用率。
设备重叠的原理是,CPU中有两个复制引擎队列,一个负责从将数据从主机拷贝到设备,一个负责将数据从设备拷贝到主机。这两个队列和内核队列可以并行或者乱序执行。从而实现数据传输和内核执行的设别重叠。
设备重叠的具体使用方法是:将cuda操作分配到不同的流中。
内存分页:内存分页是操作系统内存管理技术,将进程的逻辑地址划分成页,将磁盘的物理地址划分页框。进程访问内存时,系统将从磁盘加载对应的页到页框中,并用页表对应起来。
cuda中为什么要设计pinned memory?
pinned memory是操作系统分配在主机上固定的、不可分页的、页锁定的内存,它不会被交换到虚拟内存中。
优点:
它可以加快主机和设备间内存传输速度。不需要操作系统的分页机制访问内存,不需要主机和设备间的内存拷贝,采用直接内存访问(DMA)。
可以让GPU实现零拷贝,减少内存占用和数据传输带来的开销,提高内核执行效率。
缺点:
会占用更多的物理内存,因为它不能被操作系统释放或交换,如果分配过多的pinned memory可能会影响程序的性能。
降低GPU的内存缓存效率,因为它不会被GPU缓存,如果对pinned memory进行过多的访问,可能会导致更多的GPU-CPU数据传输,影响内核执行的性能。
因此pinned memory要根据具体的应用场景和硬件条件来权衡利弊,选择合适的内存管理方案。
加速相关:
1、pytorch onnx tensorRT生成的模型分别是动态图还是静态图?
2、tensorRT算子加速的方法有哪些?
算法相关:
1、一个模型图中有哪些网络层可以剪枝,剪枝策略是什么?
2、给我一个模型图该怎么剪?
3、了解量化原理吗?量化后一定会快吗? 量化后不快的原因是什么?
不问原理,偏向遇到了实际问题该怎么解决。
智力题:
一根香燃烧是1个小时,怎么精准测量半个小时。
算法题:
二分查找的变种
总结:需要系统充分的准备!
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大型产研团队项目管理最佳实践:项目管理如何实现业界四倍人效?
- 【贪心算法】之 分糖果(中等题)
- RHCE8 资料整理(十一)
- [足式机器人]Part2 Dr. CAN学习笔记- Kalman Filter卡尔曼滤波器Ch05-3+4
- 【算法Hot100系列】下一个排列
- js面试题
- Leetcode1143. 最长公共子序列
- 2023年全国职业院校技能大赛网络系统管理网络模块 网络构建答题卡(600)(还原截图锐捷)
- OpenAI推出GPT商店和ChatGPT Team服务
- MySQL中的SIGNAL语句