联邦边缘学习中的知识蒸馏综述
发布时间:2023年12月18日
联邦边缘学习中的知识蒸馏综述
移动互联网的快速发展伴随着智能终端海量用户数据的产生。如何在保护数据隐私的前提下,利用它们训练出性能优异的机器学习模型,一直是业界关注的难点。为此,联邦学习应运而生,它允许在终端本地训练并协同边缘服务器进行模型聚合来实现分布式机器学习。但是,联邦学习在边缘计算场景面临多个挑战,包括海量终端的计算资源有限且差异大、通信不稳定且带宽受限,用户使用习惯多样等。
近年来,将知识蒸馏技术引入边缘计算场景的联邦学习训练过程,成为较多研究关注的焦点。本文总结了知识蒸馏在联邦边缘学习中部署的四种主要形式:1) 知识传递,在终端侧或边缘侧进行知识迁移;2) 模型表示交换协议,终端和边缘模型基于交换的logits或特征进行协同优化;3) 骨干算法组件,以知识蒸馏为端侧优化技术;4) 数据集蒸馏,从终端数据中生成精炼的数据集。这些部署形式可以帮助应对联邦边缘学习面临的计算资源匮乏、系统异构性以及个性化需求等问题。具体而言,知识蒸馏可以:1)实现基于知识的协同优化,从而降低通信量;2)支持不同算力的终端使用异构模型;3)引导个性化模型迁移知识以适应本地数据分布;4)构建端云协同的学习框架等。现有方法在降低通信负载、支持终端异构、实现模型个性化定制等方面均取得一定进展。
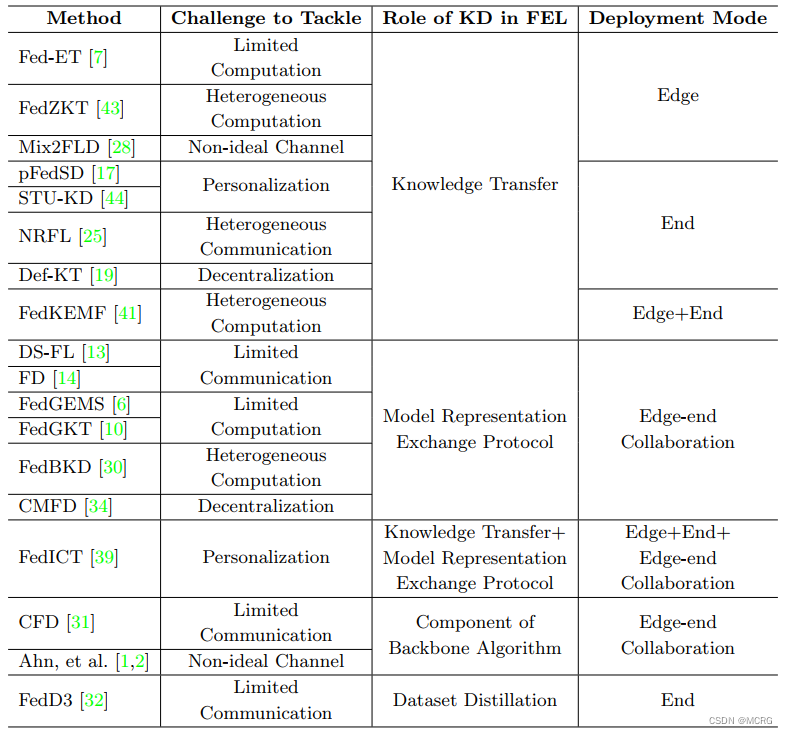
未来研究可能关注进一步提升模型性能、解决设备离线、训练加速、激励机制等问题,并在实际部署中实现技术整合。总体来看,知识蒸馏为联邦边缘学习提供了应对多样性和约束的重要技术手段,它在促进联邦边缘学习实际应用中将发挥日益重要的作用。
论文链接:https://arxiv.org/pdf/2301.05849.pdf
文章来源:https://blog.csdn.net/weixin_43869091/article/details/134959669
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- xdoj购票系统(多次循环)
- 【SpringBoot篇】优惠券秒杀 — 添加优惠劵操作(基本操作 | 一人仅一张券的操作)
- 前端食堂技术周刊第 111 期:2023 JS Rising Stars、2024 年如何写 CSS、htmx、两个 React、npm 年度回顾
- 你真的读懂了“in”运算符吗?
- 【DataGrip使用小技巧】2
- 代码是如何变混乱的?
- 【前端】NodeJS 部署到 Window 并以 EXE 文件运行
- JAVA设计模式(三)-原型
- 【LeetCode】每日一题 2023_12_27 保龄球游戏的获胜者(模拟)
- CSS实现的 Loading 效果