【Python排序算法系列】—— 希尔排序

🌈个人主页:?Aileen_0v0
🔥热门专栏:?华为鸿蒙系统学习|计算机网络|数据结构与算法
💫个人格言:"没有罗马,那就自己创造罗马~"
目录
希尔排序 (ShellSort)
由来和特点
希尔排序是一种高效的排序算法,由美国计算机科学家Donald Shell于1959年提出。希尔排序基于插入排序算法,通过比较相距一定间隔的元素来把元素移动到最终位置,从而实现排序。
希尔排序的基本思想是将待排序的数组按照一定的间隔分成若干个子序列,对子序列进行插入排序,然后缩小间隔,重复进行插入排序,直到间隔为1,最后通过插入排序将整个序列排序完成。
希尔排序的特点:
1. 缩小增量:希尔排序的一大特点是将数组分成若干个子序列进行排序,通过缩小增量的方式减少了插入排序的次数。增量的选择有多种方法,常用的是二分法,即每次将增量除以2,直到增量变为1为止。
2. 分组插入排序:希尔排序将数组按照一定的间隔分成若干个子序列,对每个子序列进行插入排序。由于子序列的长度较短,插入排序的时间复杂度较低,从而提高了排序的效率。
3. 大幅度减少逆序对:由于希尔排序是通过间隔分组进行插入排序的,每次排序都会将相距较远的元素进行比较和交换,从而大幅度减少了逆序对的数量。逆序对的数量是衡量一个排序算法效率的指标,逆序对越少,排序效率越高。
4. 非稳定性:希尔排序是一种非稳定的排序算法。在排序过程中,相同大小的元素可能会发生交换,导致原来相对顺序的改变。
总结起来,希尔排序是一种高效的排序算法,通过缩小增量和分组插入排序的方式,大幅度减少了逆序对的数量,从而提高了排序效率。虽然希尔排序存在一定的非稳定性,但在实际应用中并不影响排序结果的正确性。希尔排序在大多数情况下都能够比较好地工作,并且适用于各种规模的数据集。
理解
希尔排序是插入排序的优化,他把整个列表按照定义的gap(为步长【也叫增量】)切割【隔着gap切割而非连续切割】成多个子列表,然后对子列表进行排序,排完序以后的整个列表,若还是存在无序,我们可以将增量递减,继续进行插入排序,直到增量为1,当增量为1的时候整个列表直接进行插入排序,此时,已经在前面排好的基础上进一步进行插排,因此希尔排序在最后进行插排的时候比整个无序表进行插排的速度快很多。
子列表的个数 = 步长
过程演示
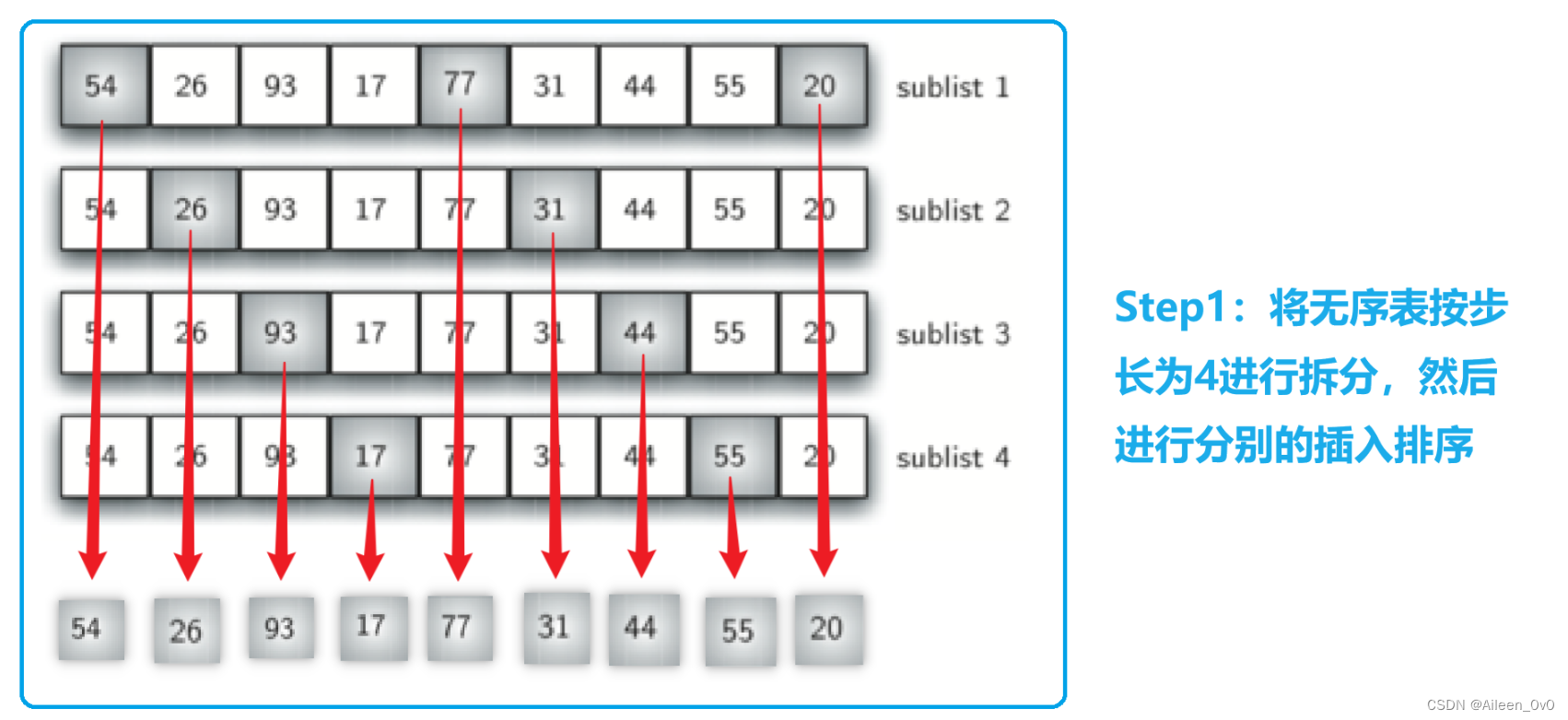
Step1:
 ?
?
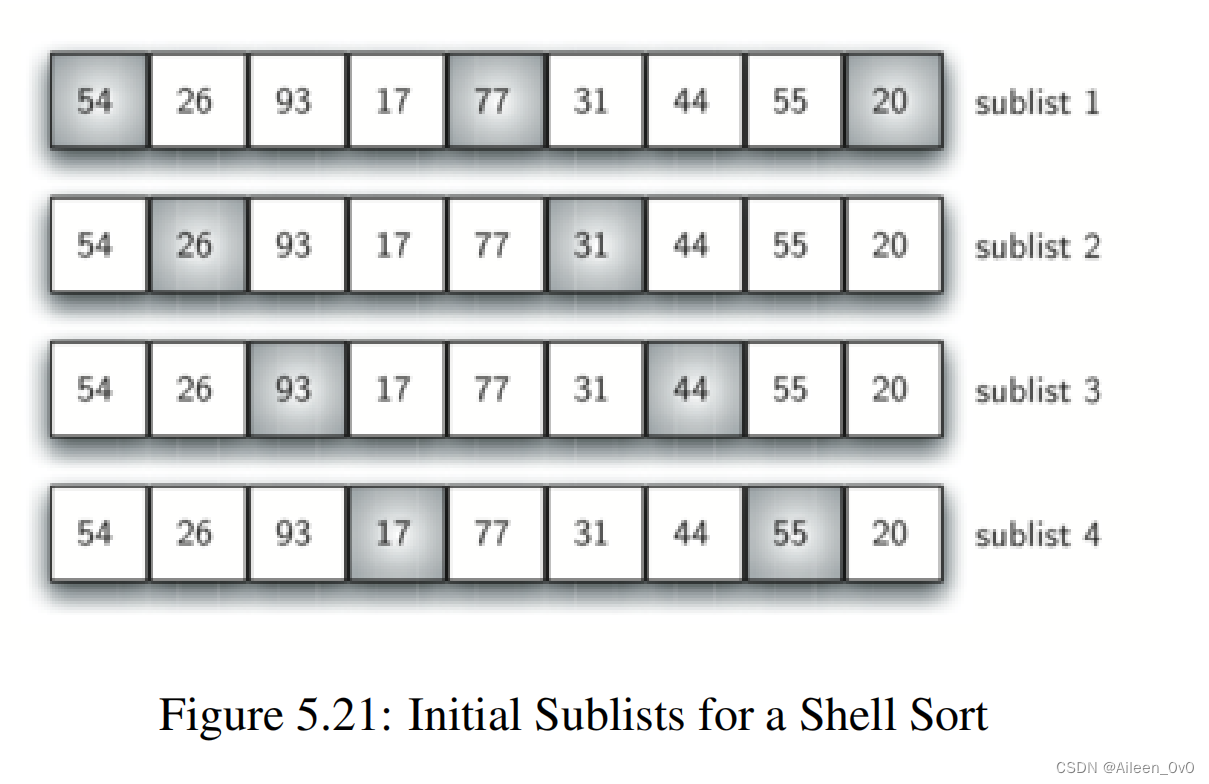
希尔排序第一步:这里我们选择二分法,?按照步长 gap = len (alist)?/ /? 2 进行列表的切割。
原来的无序表的长度是9,所以它的步长gap = 9 / / 2 = 4,如上图切割成4个子列表。
【注意】:实际上他不会像图上一样分开成四个,而是按照原来的进行切分,只是为了更好的理解,我们才分开画的。
 ?
?
Step2:
第二轮,继续按照步长 gap = len (alist)?/ /? 2 进行列表的切割。
原来的无序表个数是4,所以它的步长gap = 4 / / 2 = 2,如下图切割成2个子列表。

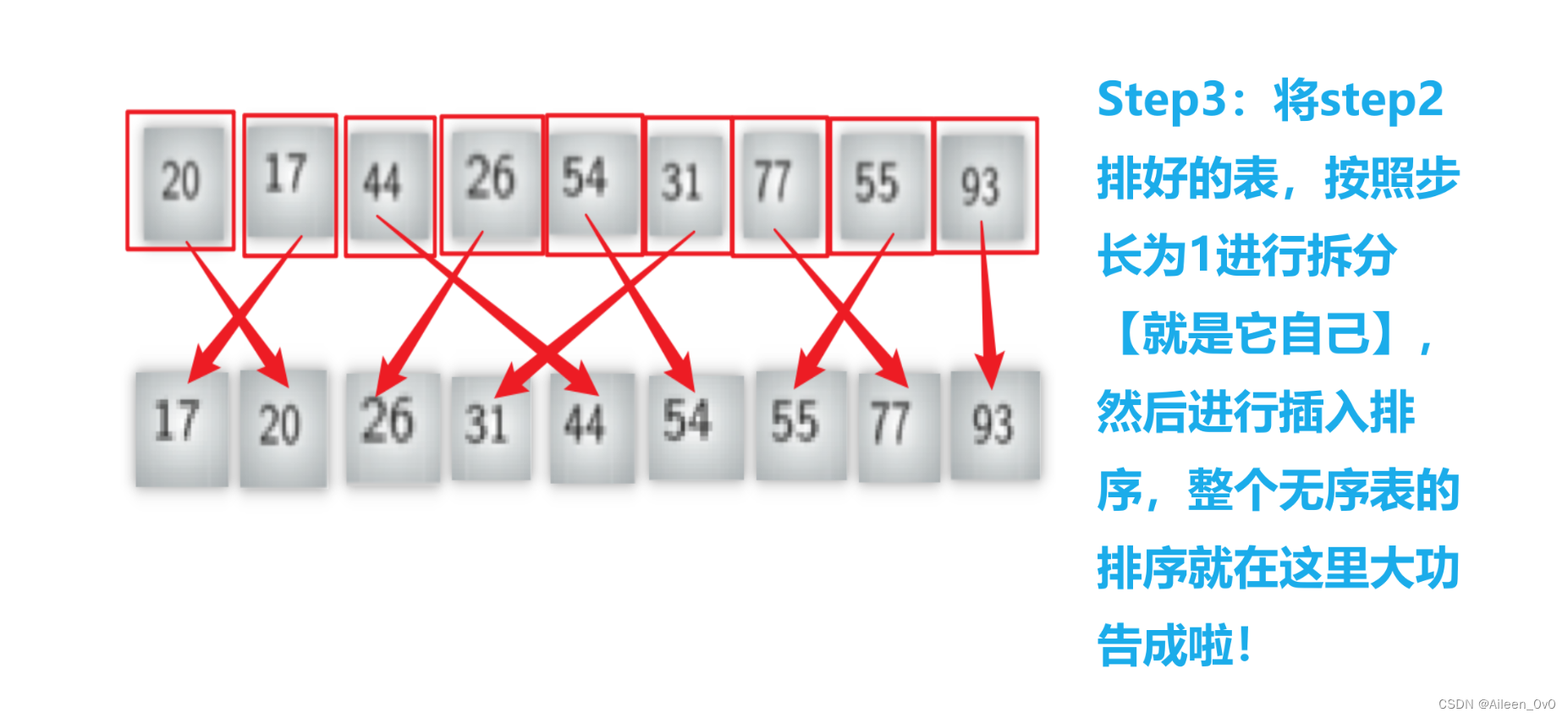
Step3:?
第三轮,继续按照步长 gap = len (alist)?/ /? 2 进行列表的切割。
原来的无序表的个数是2,所以它的步长gap = 2?/ / 2 = 1,如下图切割成1个子列表。
实现代码:?
#切割列表,然后利用for循环进行插排
def shell_sort(alist):
sublistcount = len(alist) // 2 #切割子列表的步长
while sublistcount > 0: #只要还可以切割
# 通过循环遍历每个字列表
for i in range(sublistcount):
insert_sort(alist, i , sublistcount) #对每一个子列表进行插排
sublistcount = sublistcount // 2 #改变步长的长度
return alist
# 定义插排的函数
def insert_sort(alist, start, gap):
for i in range(start +gap, len(alist), gap):
currentvalue = alist[i] #记录当前循环列表里的值
position = i #记录当前位置
while position >= gap and alist[position - gap] > currentvalue:
alist[position] = alist[position - gap] #整体后移
position = position - gap # 记录当前位置
alist[position] = currentvalue#当前位置等于要插入的那个位置
li = [54,26,93,17,77,31,44,55,20]
print(shell_sort(li))
Self Check
 我的解题思路:
我的解题思路:
根据希尔排序的特点,根据gap先进行分组然后进行跳跃切割。
题目中的gap = 3,所以我们首先可以知道要分三组:
他们的下标和对应的分组元素如下图所示
然后每组按照插入排序的方法进行排序
最后排完的结果是: 5 , 3, 8 , 7 , 16, 19 , 9 , 17, 20, 12。

📝总结:
粗看上去,谢尔排序以插入排序为基础可能并不会比插入排序好,但由于每趟都使得列表更加接近有序,这个过程会减少很多原先需要的“无效”比对
对谢尔排序的详尽分析比较复杂,大致说是介于0(n)和0(n2)之间
如果将间隔保持在2^(k) - 1(1、3、5、7、15、31等等),谢尔排序的时间复杂度约为0 ( n^(3/2))?



?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 汇编语言8086 期末考试 笔记总结(内容补充)【个人复习向】【欢迎各位斧正错误之处】(所借鉴部分资料侵删)
- 车联网之电子围栏模型使用翻滚窗口【二十一】
- 基于SpringBoot + Vue的图书管理系统的设计与实现
- 【菜鸡常见网络问题汇总】之:网络丢包
- C语言关于指针函数可变参数的使用方法和打印相应数据
- CSS 压重按钮 效果
- 安全与认证Week3 Tutorial
- 基于Apache POI-操作Excel数据-读写
- 8.前端--CSS-显示模式
- 2.4G水墨屏电子标签|RFID电子纸基站CK-RTLS0501G_VT硬件功能与联机方法