支持向量机(Support Vector Machines,SVM)
什么是机器学习
支持向量机(Support Vector Machines,SVM)是一种强大的机器学习算法,可用于解决分类和回归问题。SVM的目标是找到一个最优的超平面,以在特征空间中有效地划分不同类别的样本。
基本原理
超平面
在二维空间中,超平面是一条直线,而在更高维的空间中,它是一个平面。对于二分类问题,SVM试图找到一个超平面,使得两个类别的样本被最大间隔分开。
支持向量
在SVM中,支持向量是离超平面最近的样本点。这些支持向量对决定超平面的位置和方向起关键作用。
间隔
SVM的目标是最大化支持向量到超平面的间隔,即最大化决策边界的宽度。
核函数
SVM可以使用核函数将数据映射到高维空间,从而在低维空间中无法线性分离的数据可以在高维空间中变得线性可分。
支持向量机(SVM)可以使用不同的核函数来处理线性不可分的问题,将数据映射到高维空间,以便在该空间中找到线性的超平面。以下是一些常见的SVM核函数:
线性核函数(Linear Kernel):
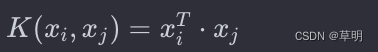
在特征空间中直接进行线性划分。适用于线性可分的情况。
多项式核函数(Polynomial Kernel):
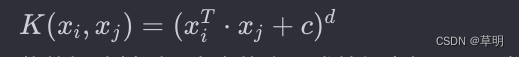
将数据映射到更高次的多项式特征空间。c 是常数,d 是多项式的次数。
径向基核函数(Radial Basis Function,RBF或Gaussian Kernel):
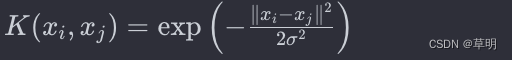
使用高斯分布函数进行映射,可以处理非线性问题。σ 是控制核函数宽度的参数。
Sigmoid核函数(Sigmoid Kernel):
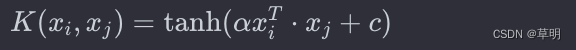
使用双曲正切函数进行映射,常用于神经网络。
Laplacian核函数(Laplacian Kernel):
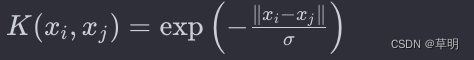
使用拉普拉斯分布进行映射,与RBF核类似,但对异常值更敏感。
这些核函数允许SVM在更高维度的空间中进行非线性映射,从而使得在原始特征空间中线性不可分的问题变得可分。选择适当的核函数通常依赖于具体问题和数据的性质,以及对模型的理解。
软间隔
对于非线性可分的数据,SVM引入软间隔,允许一些样本不满足硬间隔条件,以提高模型的泛化能力。
优点
- 适用于高维空间,对于特征数量大于样本数量的情况仍然有效。
- 在处理非线性问题时,可以使用核技巧。
- 对于二分类和多分类问题都有良好的适应性。
适用场景
- 二分类和多分类问题。
- 高维数据集,例如文本分类、图像分类等。
- 数据维度较小但需要有较好泛化性能的情况。
代码示例(使用Python和scikit-learn):
以下是一个简单的SVM分类示例:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM模型
model = SVC(kernel='linear') # 使用线性核函数
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型性能
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
这是一个使用线性核函数的示例。对于非线性问题,可以尝试使用不同的核函数,如径向基核函数(RBF kernel)。SVM的性能和调参密切相关,通常需要根据具体问题进行调优。
kernel 参数的值
线性核函数(Linear Kernel):
kernel='linear'
这是最简单的核函数,对应于线性SVM,适用于线性可分的情况。
多项式核函数(Polynomial Kernel):
kernel='poly'
除了指定kernel外,还可以设置degree参数来指定多项式的次数。例如,degree=3表示使用三次多项式。
径向基核函数(Radial Basis Function,RBF或Gaussian Kernel):
kernel='rbf'
这是一种常用的非线性核函数,通过调整gamma参数可以影响决策边界的“柔软性”。
Sigmoid核函数(Sigmoid Kernel):
kernel='sigmoid'
使用双曲正切函数进行映射,通常在神经网络中使用。
自定义核函数:
除了上述常见的核函数,scikit-learn还允许使用自定义的核函数,通过指定kernel='precomputed’并传递预计算的核矩阵。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Elasticsearch 性能调优基础知识
- AUTOSAR中的Crypto Stack(六)-- IdsM(入侵检测管理)
- Vue3使用dayjs以及dayjs日期工具类
- vue+element中table列表最后一行添加合计
- 银行数仓建模方法论
- 【Linux C | 进程】进程环境 | 什么是进程?进程的开始、终止、存储空间布局、命令行参数、环境变量
- 企业如何做好客户管理?有哪些关键因素?
- 30道多选题,40道判断题 背会这些,参加数据分析笔试,妥了~
- 档案库房环境安全自动化管控系统方案【档案十防】
- 用户口碑推荐:亚马逊鲲鹏系统,购物体验的全新革命