(2024|ICLR,三阶段训练和生成,紧凑图像表示)WURSTCHEN:大规模文本到图像扩散模型的高效架构
Wuerstchen: An Efficient Architecture for Large-Scale Text-to-Image Diffusion Models
公和众和号:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
我们介绍了 Wurstchen,这是一种用于文本到图像合成的新型架构,它将竞争性的性能与大规模文本到图像扩散模型的前所未有的成本效益相结合。我们工作的一个关键贡献是开发了一种潜在扩散技术,通过该技术我们学习了一种详细但极其紧凑的语义图像表示,用于引导扩散过程。与语言的潜在表示相比,图像的这种高度压缩表示提供了更详细的引导,从而显著降低了实现最先进结果的计算要求。我们的方法还通过用户偏好研究改善了基于文本条件的图像生成的质量。我们的方法的训练要求 24,602 个 A100-GPU 小时 - 相比于 Stable Diffusion 2.1 的 200,000 GPU 小时。我们的方法还需要更少的训练数据来实现这些结果。此外,我们紧凑的潜在表示使我们能够执行两倍速的推断,显著降低了最先进(SOTA)扩散模型的通常成本和碳足迹,而不影响最终性能。在与SOTA 模型的更广泛比较中,我们的方法在效率上更为显著,并在图像质量方面具有明显优势。我们相信这项工作鼓励更加强调性能和计算可访问性的优先考虑。
3. 方法
我们的方法包括三个阶段,全部实现为深度神经网络(见图 2)。
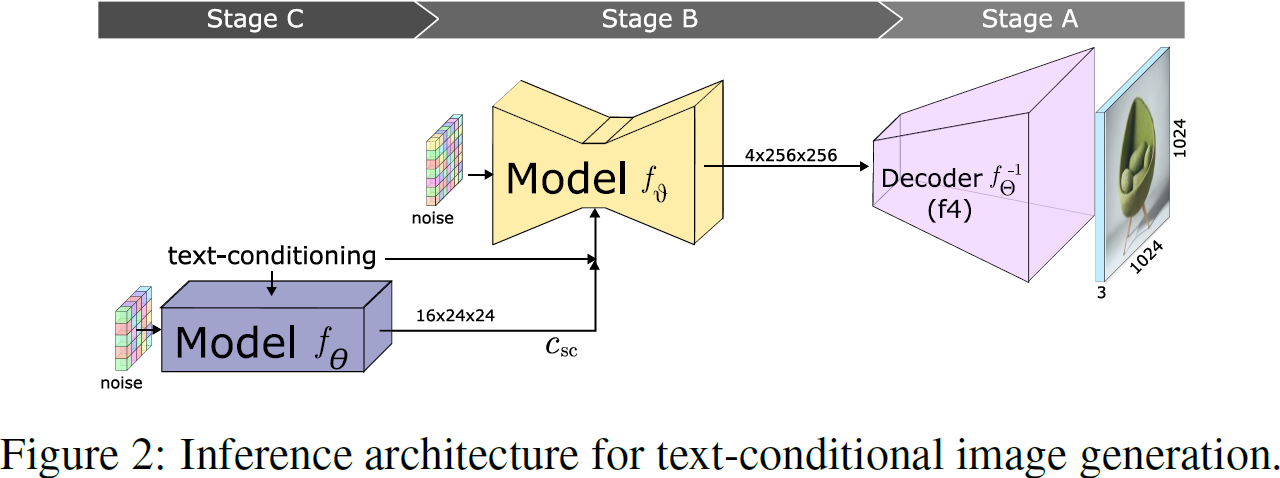
对于图像生成,
- 首先使用文本条件的 LDM(阶段 C)以强压缩比创建图像的低维潜在表示。
- 随后,使用这个潜在表示调节另一个 LDM(阶段B),产生在更高维度(较少压缩)的潜在空间中的潜在表示,该模型负责进行重建(阶段B)。
- 最后,通过 VQGAN 解码器对中间分辨率的潜解码,生成完整分辨率的输出图像(阶段A)。
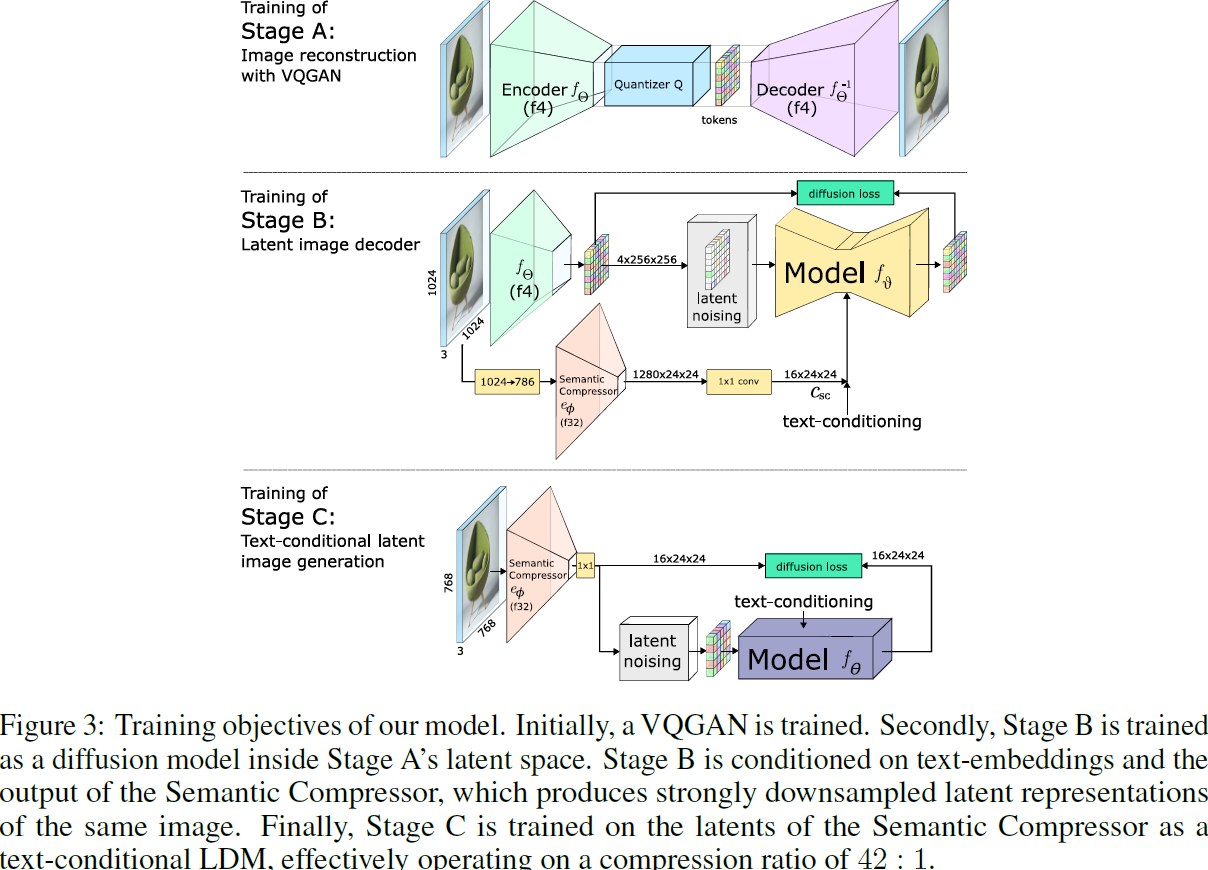
对该架构的训练是按与生成相反的顺序进行的(见图 3)。有关训练的详细信息可以在附录 E 中找到。
- 最初的训练在阶段 A 上进行,使用 VQGAN 创建潜在空间。这种紧凑的表示有助于学习和推理速度。
- 下一个阶段(阶段B)涉及第一个潜在扩散过程,它以语义压缩器(该编码器以非常高的空间压缩率运行)的输出和文本嵌入为条件。这个扩散过程的任务是重建由阶段 A 的训练建立的潜在空间,这受到语义压缩器提供的详细语义信息的强烈引导。
- 最后,对于阶段 C 的构建,来自阶段 B 的语义压缩器的强压缩潜在用于将图像投影到紧凑的潜在空间,其中训练了一个使用 CLIP-H 的文本调节的 LDM。在阶段 C 中空间维度的显著减少使得扩散模型的训练和推理更加高效,显著降低了所需的计算资源和所花费的时间。
3.1 阶段 A 和 B
通过将数据压缩成较小的表示来减轻计算负担是一种已知且深入研究的技术(Richter等,2021a;b; Chang等,2022)。我们的方法也遵循这一范例,并利用阶段 A 和 B 来实现比通常更高的压缩。设 H×W×C 为图像的尺寸。空间压缩将图像映射到分辨率为 h×w×z 的潜在表示,其中 h = H/f,w = W/f,其中 f 定义了压缩率。用于建模图像合成的常见方法使用 f4 到 f16 之间的单阶段压缩(Esser等,2021; Chang等,2023; Rombach等,2022),较高的因子通常导致较差的重建。我们的阶段 A 由一个 f4 VQGAN(Esser等,2021)组成,具有参数 Θ,最初将图像 X ∈ R^(3×1024×1024) 编码为大小为 8192 的学习码书的 256×256 离散标记:
![]()
网络由 Esser 等人描述的方式进行训练,并试图根据量化的潜在变量重建图像,以便:
![]()
其中,f^(-1)_Θ 类似于 VQGAN 的解码器部分。
然后,在阶段 A 中,量化被舍弃,对于以阶段 A 的编码器作为条件 LDM 的未量化潜在空间,阶段 B 在其中进行训练。在阶段 B 中,我们利用语义压缩器(Semantic Compressor),即一种编码器类型的网络,用于以较强的空间压缩率生成引导扩散过程的潜在表示。未量化的图像嵌入经过 LDM 训练过程后被加入噪声。加入噪声的表示 ?X_t,以及来自语义压缩器 C_sc 的视觉嵌入、文本条件 C_text 和时间步 t 都被提供给模型。
由语义压缩器提取的高度压缩的视觉嵌入将充当阶段 C 的接口,该阶段将被训练以生成它们。这些嵌入的形状为 R^(1280×24×24),通过对形状为 X ∈ R^(3×786×786) 的图像进行编码获得。我们使用简单的双三次插值将图像从 1024×1024 调整大小到 786×786,这是足够高可充分利用语义压缩器参数的分辨率(Richter等人,2023年;Richter和Pal,2022年),同时也减小潜在表示的大小。此外,我们使用 1×1 卷积进一步压缩潜在变量,对嵌入进行归一化并投影到 C_sc ∈ R^(16×24×24)。将图像的这种压缩表示作为条件提供给阶段 B 的解码器,以引导解码过程。
![]()
以低维潜在表示对阶段 B 进行调节,我们可以有效地将图像从 R^(16×24×24) 的潜在空间解码为分辨率为 X ∈ R^(3×1024×1024),从而实现总体的空间压缩比为 42:1。
我们使用在 ImageNet 上预训练的权重初始化了语义压缩器,然而,这并不能捕捉到大型文本图像数据集中存在的图像的广泛分布,并且不适用于语义图像投影,因为它是根据区分 ImageNet 类别的目标进行训练的。因此,在训练过程中,我们更新了语义压缩器的权重,建立了一个具有高精度语义信息的潜在空间。我们使用交叉注意力(Vaswani等人,2017年)进行条件化,并将 C_sc(展平)投影到模型的每个块中的相同维度并连接它们。此外,在训练阶段 B 时,我们间歇性地向语义压缩器的嵌入中添加噪声,以教导模型理解非完美的嵌入,使用阶段 C 生成这些嵌入时可能会出现这种情况。最后,在采样过程中,我们还随机丢弃 C_sc,以便能够进行无分类器引导的采样(Ho和Salimans,2022年)。
3.2 阶段 C
在训练阶段 A 和阶段 B 后,开始了有文本条件的最后阶段训练。在我们的实现中,阶段 C 由 16 个 ConvNeXt 块(Liu 等,2022b)组成,没有下采样,文本和时间步骤的条件在每个块之后通过交叉注意力进行应用。我们遵循了一个标准的扩散过程,应用于经过微调的语义压缩器的潜在空间中。图像被编码为它们的潜在表示 X_sc = C_sc,表示目标。通过使用以下正向扩散公式对潜在进行加噪处理:
![]()
其中 ? 代表来自零均值单位方差正态分布的噪声。我们使用余弦调度(Nichol&Dhariwal,2021)生成 ˉα_t 并使用连续的时间步。扩散模型接收噪声嵌入 X_(sc,t),文本条件 C_text 和时间步 t。该模型以以下形式返回对噪声的预测:
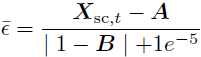
![]()
我们决定制定这样的目标,因为这使得训练更加稳定。我们假设这是因为模型参数在开始时被初始化为 0,从而放大了与具有大量噪声的时间步的差异。通过重新制定为 A 和 B 目标,模型最初返回输入,使得对于非常嘈杂的输入损失较小。我们使用预测噪声和地面实况噪声之间的标准均方误差损失。此外,我们采用 p2 损失加权(Choi 等,2022):
![]()
其中 p_2(t) 被定义为
![]()
使得更高的噪声水平对损失的贡献更大。文本条件 C_text 以?5% 的概率被随机丢弃,并用一个空标签替换,以使用无分类器引导(Ho&Salimans,2022)。
3.3 图像生成(采样)
采样流程的示意图如图 2 所示。采样始于阶段 C,该阶段主要负责图像合成(详见附录 D),从初始随机噪声 X_(sc,τ_C) = N(0, I) 开始。我们使用 DDPM(Ho 等,2020)算法对在文本嵌入条件下的语义压缩器潜在进行采样。为此,我们运行?τ_C 步以下操作:
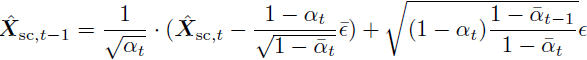
我们将结果表示为 ˉX_sc,其形状为 16 × 24 × 24。此输出被展平为形状为 576 × 16,并作为条件,与用于采样 ˉX_sc 的相同文本嵌入一起传递给阶段 B。该阶段在 4 × 256 × 256 未量化的 VQGAN 潜在空间中操作。我们将 X_(q,τ_B) 初始化为从 VQGAN 码本中随机选择的标记。我们使用标准的 LDM 方案对 ?X 进行 τB 步的采样。?
![]()
最后,?X 通过 VQGAN 的解码器 f^(-1)_Θ 投影回像素空间(阶段 A):?
![]()
3.4 模型决策
理论上,任何特征提取器都可以用作语义压缩器的骨干。然而,我们假设使用已经对各种图像具有良好特征表示的骨干是有益的。此外,拥有小的语义压缩器可以加快阶段 B 和 C 的训练速度。最后,特征维度至关重要。如果它过小,可能无法捕捉足够的图像细节或未充分利用参数(Richter&Pal,2022);相反,如果它过大,可能会不必要地增加计算要求并延长训练时间(Richter 等,2021a)。出于这个原因,我们决定使用经过 ImageNet1k 预训练的 EfficientV2 (S) 作为我们语义压缩器的骨干,因为它结合了高压缩率、良好的泛化特征表示和计算效率。
此外,在阶段 C 中,我们偏离了 U-Net 标准架构。由于图像已经经过 42 倍的压缩,我们发现进一步压缩对模型质量有害。相反,模型是一个由 16 个 ConvNeXt 块(Liu 等,2022b)组成的简单序列,没有下采样。在每个块之后应用时间和文本条件。?
4. 实验
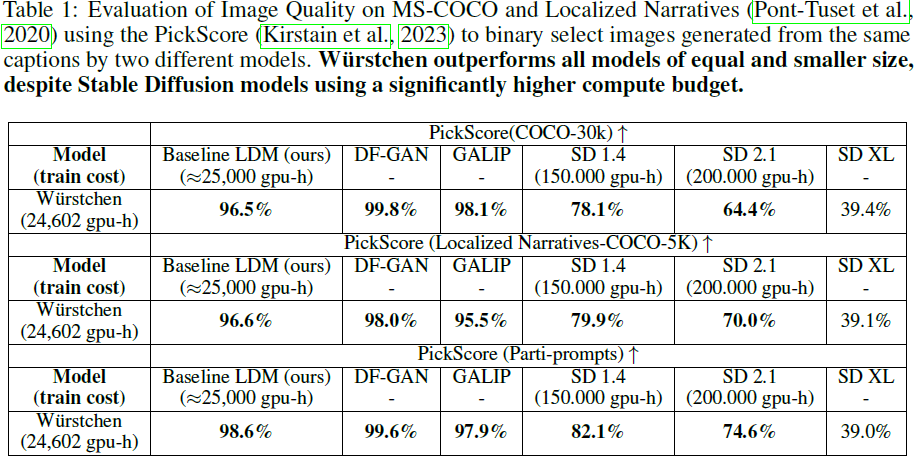
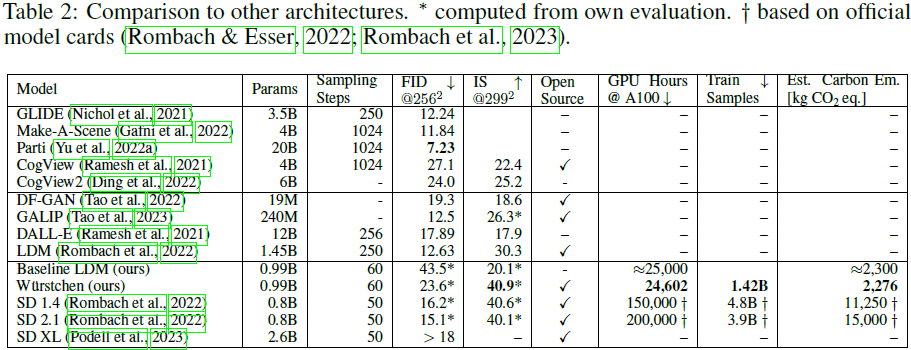
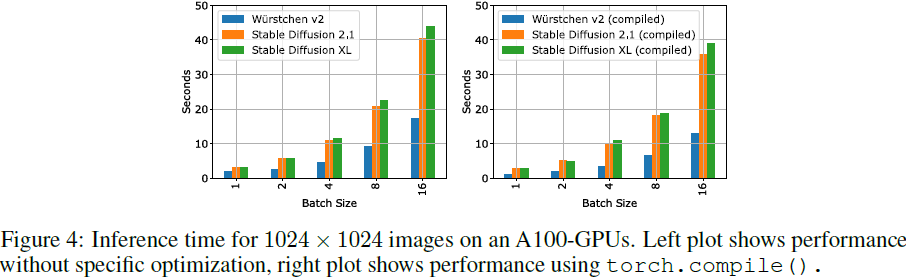
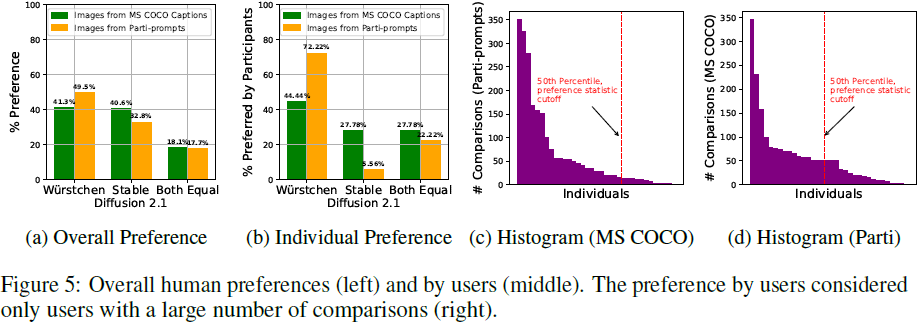

?
附录
D. 阶段 B 和 C 如何分担工作负担?
在我们的工作中,当涉及从文本生成图像时,我们将阶段 C 视为模型的主要工作部分。然而,从架构上并不立即清楚,因为阶段 B 和 C 都是生成模型,并且具有类似的能力。在本节中,我们将简要探讨阶段 B 和阶段 C 如何分担图像生成的工作负担。通过这样做,我们演示了阶段 C 负责图像的内容,而阶段 B 充当一个精细化模型,添加细节并增加分辨率,但最终并没有在语义上改变图像。为了调查这一点,我们训练了一个小型(3.9M 参数)解码器,用于从阶段 C 生成的潜在中重建图像,并将其与在阶段 C 的条件下对阶段 B 进行的重建进行比较。图17、18、19 和 20 中的结果显示,由阶段 C 生成的图像与从阶段 B 和 C 结合生成的图像非常相似。从视觉检查中,我们可以观察到主要区别是一些细节和模糊度的减少。这些变化可以看作是阶段 B 的主要贡献。从这里我们得出结论,当涉及将文本转化为图像时,阶段 C 是主要因素。这一结论得到了支持,因为对替代训练方案进行的短期实验表明,阶段 B 上的文本条件并不会提高图像的质量,并且在我们模型的未来版本中可能会被取消。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Minecraft Fabric模组开发教程#6 多语言 合成表 提示
- 在 App 设计工具的设计视图中布局 App
- 使用easyexcel 导出多级表头demo
- sklearn网格搜索找寻最优参数
- Page 251~254 Win32 GUI项目
- 用通俗易懂的方式讲解:LSTM原理及生成藏头诗(Python)
- WSL的导出与导入
- 【C++ STL】unordered_set/multiset的概念和其成员方法具体使用
- 信息处理和传递的革命和趋势
- 涛思数据获评北京市“专精特新”中小企业