基于 P-Tuning的高效微调ChatGLM2-6B
1 ChatGLM2-6B介绍
ChatGLM是清华技术成果转化的公司智谱AI研发的支持中英双语的对话机器人。ChatGLM基于GLM130B千亿基础模型训练,它具备多领域知识、代码能力、常识推理及运用能力;支持与用户通过自然语言对话进行交互,处理多种自然语言任务。比如:对话聊天、智能问答、创作文章、创作剧本、事件抽取、生成代码等等。
代码地址:https://github.com/THUDM/ChatGLM2-6B

ChatGLM2-6B是第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,又增加许多新特性:
-
更强大的性能:基于ChatGLM初代模型的开发经验,全面升级了ChatGLM2-6B的基座模型。ChatGLM2-6B使用了GLM的混合目标函数,经过了1.4T中英标识符的预训练与人类偏好对齐训练。评测结果显示,与初代模型相比,ChatGLM2-6B在MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
-
更长的上下文:基于 FlashAttention 技术,研究人员将基座模型的上下文长度由 ChatGLM-6B 的2K扩展到了32K,并在对话阶段使用8K的上下文长度训练,允许更多轮次的对话。但当前版本的ChatGLM2-6B对单轮超长文档的理解能力有限,会在后续迭代升级中着重进行优化。
-
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B有更高效的推理速度和更低的显存占用。在官方的模型实现下,推理速度相比初代提升了42%,INT4量化下,6G显存支持的对话长度由1K提升到了8K。
-
更开放的协议:ChatGLM2-6B权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。
相比于初代模型,ChatGLM2-6B在数理逻辑、知识推理、长文档理解等多个维度的能力上,都取得了巨大的提升。
2 P-Tuning V2介绍
论文地址:https://arxiv.org/pdf/2110.07602.pdf
代码地址:https://github.com/THUDM/P-tuning-v2
2.1 背景
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
第一,缺乏模型参数规模和任务通用性。
-
缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
-
缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
- 由于序列长度的限制,可调参数的数量是有限的。
- 输入embedding对模型预测只有相对间接的影响。
考虑到这些问题,作者提出了Ptuning v2,它利用深度提示优化(如:Prefix Tuning),对Prompt Tuning和P-Tuning进行改进,作为一个跨规模和NLU任务的通用解决方案。
P-Tuning v2是对prefix-tuning和p-tuning进行的优化。prefix-tuning等存在一些问题:
- 是针对于生成任务而言的,不能处理困难的序列标注任务、抽取式问答等,缺乏普遍性。【解决方法,分类还是使用CLS或者token。】
- 当模型规模较小,特别是小于100亿个参数时,它仍然不如微调法。【解决方法:在每一层都加上prompt。】
2.2 技术原理
P-Tuning v2是一个用于改进预训练语言模型(Pre-trained Language Model,PLM)偏见的方法。其原理可以总结如下:
-
样本选择:首先,从一个大规模的文本语料库中选择一部分样本作为训练集。这些样本应当具有多样性,包括不同的文化、背景和价值观。
-
PLM预训练:在选定的样本上进行预训练,生成一个初始的PLM模型。这个模型包含了很多词语的上下文信息,以及它们之间的关联性。
-
特征定义:定义一个特征函数,用来指示某个词对于特定偏见的敏感程度。这些特征函数可以包括词语的含义、出现上下文的频次等等。
-
偏见调整:通过修改样本中某些词语的上下文,缩小其与偏见之间的相关性。具体来说,对于某个特定的偏见,可以通过修改相关的样本以降低这个偏见对PLM的影响。
-
约束优化:为了控制偏见调整的程度,引入一个约束函数来度量样本的平衡性。这个约束函数可以包括不同群体的样本分布、词语的多样性等等。
-
迭代训练:在约束优化的框架下,反复调整样本和PLM模型,直到达到平衡的状态。这样可以在尽量保持语言模型质量的同时,尽量减小偏见。
P-Tuning v2的原理是通过定义特征函数和约束函数,以及调整样本和PLM模型的方法,来优化预训练语言模型的偏见问题。这个方法可以用于改进PLM的性别、种族、政治观点等各种偏见。
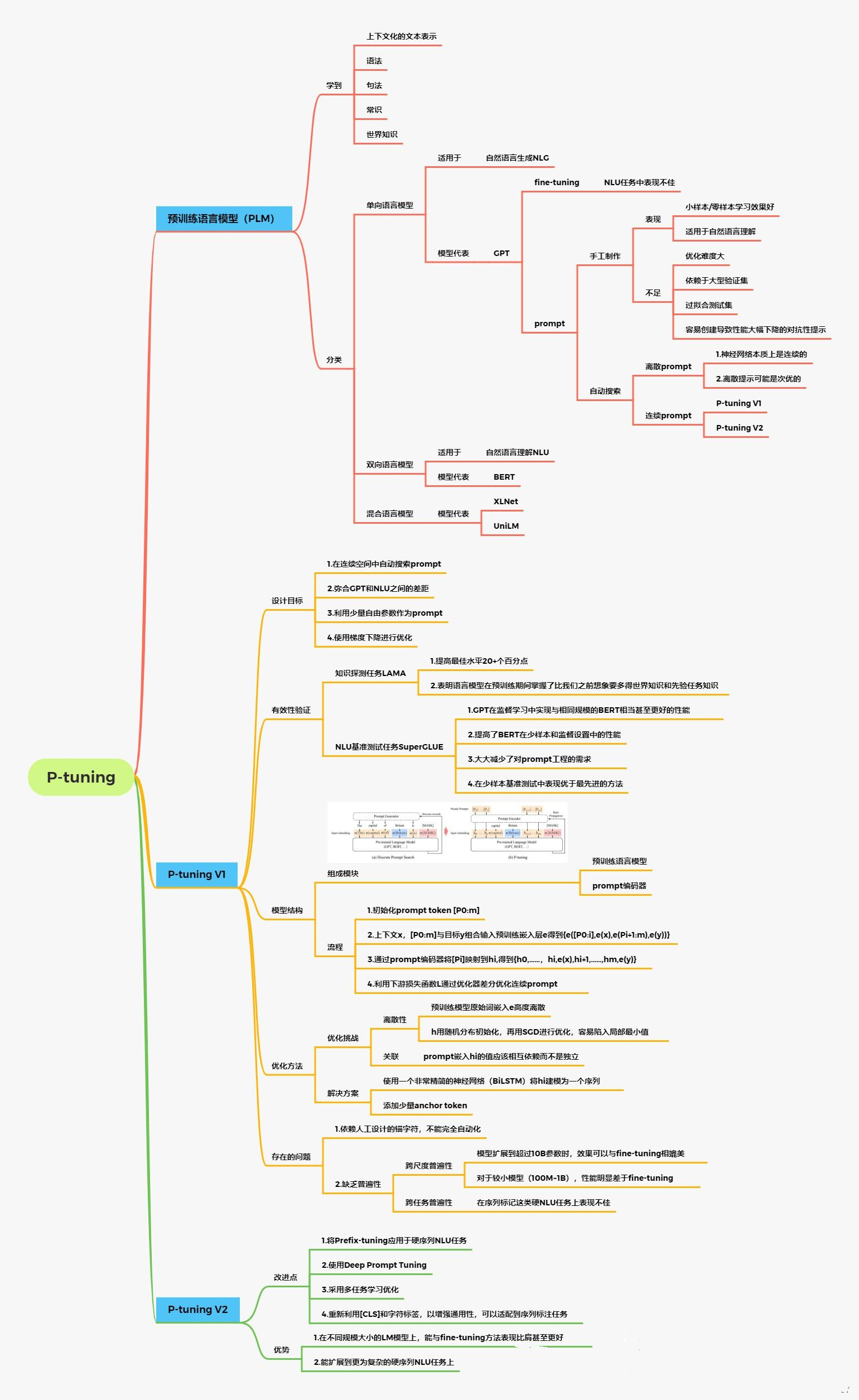
2.3 P-Tuning v2的优点
-
P-tuning v2在不同的模型规模(从300M到100B的参数)和各种困难的NLU任务(如问答和序列标注)上的表现与微调相匹配。
-
与微调相比,P-tuning v2每个任务的可训练参数为0.1%到3%,这大大降低了训练时间的内存消耗和每个任务的存储成本
4 基于P-Tuning微调ChatGLM2-6B
4.1 ChatGLM2-6B部署
部署文档详见:https://mp.csdn.net/mp_blog/creation/editor/135084490
4.2 数据集下载
ADGEN 数据集为根据输入(content)生成一段广告词(summary)。官方给出的数据处理格式:
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}数据格式是{“content”:"","summary":""}形式;如果是问答类数据,content就是问题,summary就是回答。?
数据下载地址:https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
下载完成后,将解压后的 AdvertiseGen 目录放到ptuning本目录下,如下所示:
(chatglm) [root@localhost ChatGLM2-6B]# ll ptuning/
总用量 96
drwxr-xr-x 2 root root 40 12月 18 20:17 AdvertiseGen
-rw-r--r-- 1 root root 8474 12月 18 20:17 arguments.py
-rw-r--r-- 1 root root 489 12月 18 20:17 deepspeed.json
-rw-r--r-- 1 root root 768 12月 18 20:17 ds_train_finetune.sh
-rw-r--r-- 1 root root 603 12月 18 20:17 evaluate_finetune.sh
-rw-r--r-- 1 root root 702 12月 18 20:17 evaluate.sh
-rwxr-xr-x 1 root root 17804 12月 18 20:17 main.py
drwxr-xr-x 2 root root 106 12月 18 20:18 __pycache__
-rw-r--r-- 1 root root 9567 12月 18 20:17 README.md
-rw-r--r-- 1 root root 823 12月 18 20:17 train_chat.sh
-rw-r--r-- 1 root root 3155 12月 18 20:17 trainer.py
-rw-r--r-- 1 root root 11508 12月 18 20:17 trainer_seq2seq.py
-rw-r--r-- 1 root root 833 12月 18 20:17 train.sh
-rw-r--r-- 1 root root 6014 12月 18 20:17 web_demo.py
-rw-r--r-- 1 root root 219 12月 18 20:17 web_demo.sh4.3 环境构建
pip install rouge_chinese nltk jieba datasets
pip install transformers==4.30.24.4 启动P-Tuning微调
仓库代码实现了对于 ChatGLM2-6B 模型基于 P-Tuning v2 的微调。P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。
代码地址:https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning
更改训练脚本:
vi ptuning/train.sh PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ../THUDM/chatglm2-6b \
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4-
train.sh中的PRE_SEQ_LEN和LR分别是 soft prompt 长度和训练的学习率,可以进行调节以取得最佳的效果。P-Tuning-v2 方法会冻结全部的模型参数,可通过调整quantization_bit来被原始模型的量化等级,不加此选项则为 FP16 精度加载。 -
在默认配置
quantization_bit=4、per_device_train_batch_size=1、gradient_accumulation_steps=16下,INT4 的模型参数被冻结,一次训练迭代会以 1 的批处理大小进行 16 次累加的前后向传播,等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在同等批处理大小下提升训练效率,可在二者乘积不变的情况下,加大per_device_train_batch_size的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。 -
为本地加载模型,将
train.sh中的THUDM/chatglm2-6b改为你本地的模型路径。
通过bash命令启动训练:
cd ptuning/
bash train.sh 查看GPU使用:
(chatglm) [root@localhost ptuning]# nvidia-smi
Thu Jan 4 14:16:59 2024
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100S-PCI... Off | 00000000:0B:00.0 Off | 0 |
| N/A 75C P0 245W / 250W | 7830MiB / 32768MiB | 97% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 16098 C ...nvs/chatglm/bin/python3.9 7826MiB |
+-----------------------------------------------------------------------------+4.5 P-Tuning微调结果测试
修改ptuning/web_demo.py
vi ptuning/web_demo.py demo.queue().launch(share=False, inbrowser=True)
修改为:
demo.queue().launch(share=False, server_name='0.0.0.0', inbrowser=True)修改ptuning/web_demo.sh
vi ptuning/web_demo.sh PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path THUDM/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LEN
修改为:
PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path ../THUDM/chatglm2-6b \
--ptuning_checkpoint output/adgen-chatglm2-6b-pt-128-2e-2/checkpoint-3000 \
--pre_seq_len $PRE_SEQ_LEN
?运行微调后的模型:
cd ptuning/
bash web_demo.sh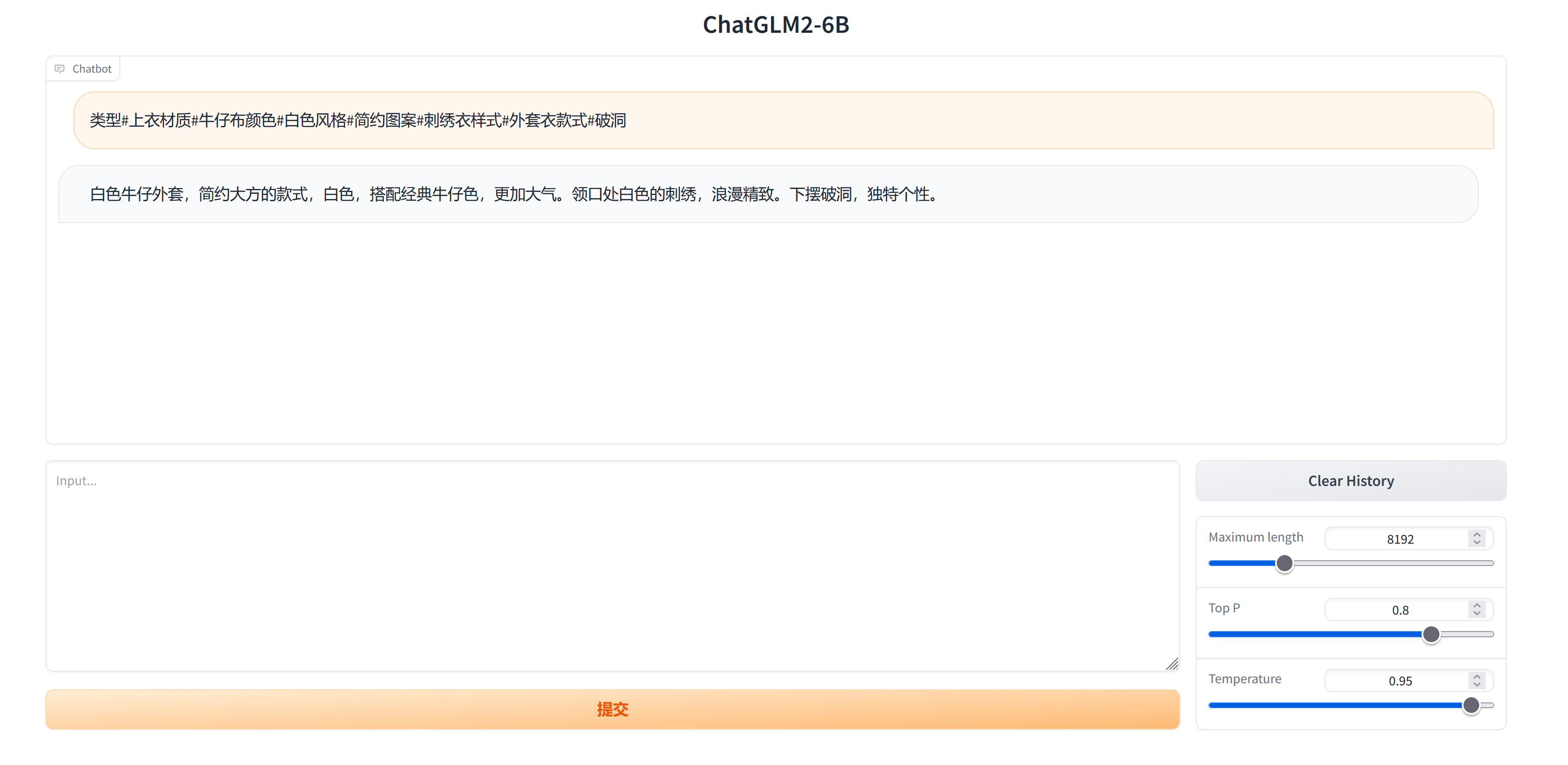 ?
?
测试1:
input:类型#上衣材质#牛仔布颜色#白色风格#简约图案#刺绣衣样式#外套衣款式#破洞
Label: 简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。
微调前输出:这件上衣由牛仔布材质制成,采用了简约风格,图案为刺绣设计,衣样式为外套,衣款式为破洞。
微调后输出:白色牛仔外套,简约大方的款式,白色,搭配经典牛仔色,更加大气。领口处白色的刺绣,浪漫精致。下摆破洞,独特个性。
测试2:
input:类型#裙*版型#显瘦*风格#文艺*风格#简约*图案#印花*图案#撞色*裙下摆#压褶*裙长#连衣裙*裙领型#圆领
Label: 文艺个性的印花连衣裙,藏青色底蕴,低调又大气,撞色太阳花分布整个裙身,绚丽而美好,带来时尚减龄的气质。基础款的舒适圆领,简约不失大方,勾勒精致脸庞。领后是一粒包布扣固定,穿脱十分方便。前片立体的打褶设计,搭配后片压褶的做工,增添层次和空间感,显瘦又有型。
微调前输出:这件上衣由牛仔布材质制成,采用了简约风格,图案为刺绣设计,衣样式为外套,衣款式为破洞。
微调后输出:这一款连衣裙,简约的白色系,搭配上撞色的印染,带来一种时髦的文艺风。修身的版型,勾勒出曼妙的身材曲线,显得高挑。
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!