4D毫米波雷达——FFT-RadNet 目标检测与可行驶区域分割 CVPR2022
前言
本文介绍使用4D毫米波雷达,实现目标检测与可行驶区域分割,它是来自CVPR2022的。
会讲解论文整体思路、输入数据分析、模型框架、设计理念、损失函数等,还有结合代码进行分析。
论文地址:Raw High-Definition Radar for Multi-Task Learning
代码地址:https://github.com/valeoai/RADIal/tree/main

1、模型框架
?FFT-RadNet只使用雷达信息,实现车辆检测和可行驶区域分割。
- 输入是“范围-多普勒”信息,即RD图;由4D毫米波雷达生成。
- 经过主干网络和FPN提取特征信息,并进一步编码形成“范围-角度”信息”。
- 然后接两个任务头:车辆检测任务、可行驶区域分割任务。
模型框架如下图所示

整体思路主要由6步组成:
- 输入RD图,表示“范围-多普勒谱”信息。
- 进入预处理模块。
- 然后经过FPN特征金字塔模型,提取多尺度特征信息。
- FPN输出的特征,进一步编码,形成范围-角度信息,得到RA特征图。
- RA特征图分别输入到两个任务头,可行驶区域分割头、车辆检测头。
- 输出车辆信息和可行驶区域信息。
2、输入信息
论文使用的4D毫米波雷达,是高清的,角度分辨率提升到小于一度,接近激光雷达的性能。
- 它使用密集的虚拟天线阵列,在水平方位角和垂直仰角上实现高角分辨率,产生更密集的点云。
- 这种高清雷达能够更精确地识别和定位物体。
- 所以它也称为“高清成像雷达”,High Definition (HD) Imaging radar。
模型输入的是“范围-多普勒”频谱,RD图。下面有两张RD图,先看一下是长这样的,有些抽象。

分析一下,如何生成这种“范围-多普勒”频谱图。
雷达通常由一组发射天线和接收天线组成。发射天线发射电磁波,这些波在撞击环境中的物体后反射回接收天线。
- 频率调制连续波(FMCW):在汽车行业标准的FMCW雷达发射一系列频率调制的信号。发射和接收的频率差异主要是由障碍物的径向距离造成的。
- 范围-快速傅里叶变换,range-FFT,通过沿FMCW序列的快速傅里叶变换(FFT)提取障碍物的距离。其中,快速傅里叶变换用FFT表示。
- 多普勒-快速傅里叶变换,Doppler-FFT,沿时间轴的另一次FFT提取相位差异,这能捕捉到反射物的径向速度。
- 这两个FFT的组合为每个接收天线提供了一个范围-多普勒(RD)频谱,并存储在RD张量中。
然后分析一下,为什么要用“范围-多普勒”RD图,作为模型的输入。
A、范围-方位角-多普勒(RAD),需要计算3D张量的开销,而且预处理成本高。
B、范围-方位(RA)
- 已经被用于多类别和自由空间分割的研究,大多数的研究利用雷达数据的范围-方位表示,包括极坐标还是笛卡尔坐标。
- 范围-方位这种表示类似于鸟瞰图,易于解释,并且可以通过平移和旋转进行简单的数据增强。
- 范围-方位表示缺点:RA雷达图的生成需要显著的处理成本(数十GOPS),这在嵌入式硬件上的可行性受到质疑。
- 尽管新型的高清雷达提供了更好的分辨率,但它们使这一计算复杂性问题更加严重。
C、点云(PC),雷达点云分割被探索过,用来估算占用情况,但是预处理成本高。
3、预处理模块
输入的“范围-多普勒”频谱,首先进入MIMO预处理编码模块。其中,MIMO是指多输入多输出。
论文使用的4D毫米波雷达,是高清的,称为“高清成像雷达”
- 它有多个发射天线Tx和接收天线Rx。
- 每个接收器都会生成一个范围-多普勒RD频谱,这就形成了一个三维数据张量。
- 这个数据张量的大小由雷达的范围分辨率BR,多普勒分辨率BD,和接收天线的数量NRx决定。
物体如何在RD频谱中显示:
- 一个反射物体,如前方的车辆,会在这个RD频谱中的特定位置出现。其位置取决于物体与雷达之间的相对距离和速度。
- 在高清成像雷达中,由于存在多个发射天线,同一个物体的反射信号会在频谱中重复出现,每个发射天线对应一次。
- 这样,物体的反射信号就在RD频谱中呈现多个副本。
- 如下图所示,雷达有2个接收天线,生成对应2张RD频谱图。同一个物体,可能都出现在2张RD频谱图中。
预编码器层的目的:
- 处理和压缩MIMO多输入多输出雷达系统产生的复杂信号
- 同时保留足够的信息以便后续能够恢复重要的参数,如方位角(azimuth angle)和仰角(elevation angle)。
预编码器的作用:
- 由于物体信息的重复,数据变得很复杂。预编码器的任务是重新排列和压缩这些数据,使其更加紧凑和易于处理。
- 预编码器使用扩张卷积方法(空洞卷积),这种方法能够有效地处理和组织数据,特别是沿着多普勒维度的数据。
?
预编码器的技术细节:
- 扩张卷积层的设计是基于发射天线的数量,它能够在正确的位置收集和组织来自不同发射天线和接收天线的信息。
- 预编码器还包括另一个卷积层,进一步组合和压缩这些信息。
方位角和仰角的恢复:
- 尽管RD信息本身不直接提供方位角或仰角信息,MIMO雷达系统可以通过分析从不同天线接收到的信号的相位差异来估计这些角度。
- 预编码器层在这里的作用是对接收到的原始MIMO信号进行初步处理,以便于后续步骤更有效地估计方位角和仰角。
- 在压缩RD数据的同时,预编码器层需要保留足够的信息以允许后续步骤准确恢复方位角和仰角信息。
端到端训练:
- 这个预编码器与整个系统一起进行训练,意味着它可以学习到如何最有效地处理特定的雷达数据。
FFT-RadNet架构中的预编码器
- 是用来处理和简化复杂的高清雷达数据的,它使这些数据更易于后续的分析和识别处理。
- 扩张卷积被用于预编码器中,帮助处理和重组复杂的雷达数据。
- 通过调整扩张率,可以有效地聚合来自不同天线的信息,同时保持网络的复杂度在合理的范围内。
- 这对于在有限的处理资源和内存的情况下有效使用高清雷达数据非常关键。
每个接收天线接收到的反射信号形成一个范围-多普勒(RD)频谱。这个频谱是一个二维数组,其中一个维度代表距离,另一个维度代表速度(多普勒)。
MIMO预处理模块的代码:
class MIMO_PreEncoder(nn.Module):
def __init__(self, in_layer,out_layer,kernel_size=(1,12),dilation=(1,16),use_bn = False):
super(MIMO_PreEncoder, self).__init__()
self.use_bn = use_bn
self.conv = nn.Conv2d(in_layer, out_layer, kernel_size,
stride=(1, 1), padding=0,dilation=dilation, bias= (not use_bn) )
self.bn = nn.BatchNorm2d(out_layer)
self.padding = int(NbVirtualAntenna/2)
def forward(self,x):
width = x.shape[-1]
x = torch.cat([x[...,-self.padding:],x,x[...,:self.padding]],axis=3)
x = self.conv(x)
x = x[...,int(x.shape[-1]/2-width/2):int(x.shape[-1]/2+width/2)]
if self.use_bn:
x = self.bn(x)
return x- 卷积核大小
kernel_size(默认为(1, 12)) - 扩张率
dilation(默认为(1, 16))
4、FPN特征金字塔模块
FPN金字塔结构是用来学习多尺度特征,同时捕获RD频谱图的粗略和细致特征,对于识别不同大小的对象非常重要。
- 包含4个块,分别由3个、6个、6个和3个残差层组成。这些残差层的特征图构成了特征金字塔。
- 在远距离,FPN提供高分辨率和狭窄的视场;在近距离,则提供低分辨率和更宽的视场。这有助于在不同距离捕获适当的细节级别。
- 为了防止在RD频谱中小物体(通常只有几个像素大小)的特征丢失,FPN编码器在每个块执行2x2下采样,从而在高度和宽度上将张量大小总共减少16倍。
- 使用3x3的卷积核有助于避免相邻发射天线(Tx)之间的重叠,同时保持足够的特征捕获能力。
FPN架构是针对雷达数据特性进行了优化的设计。
它在保持网络结构相对简单的同时,能够有效地处理雷达信号中的多尺度特征,这对于雷达数据中的对象检测和语义分割至关重要。
通过这种方式,FPN能够更好地捕捉到从远距离到近距离的不同尺度的物体特征,从而提高整体检测和分割的准确性。
FPN的部分代码:
class FPN_BackBone(nn.Module):
.......
def forward(self, x):
x = self.pre_enc(x)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
# Backbone
features = {}
x1 = self.block1(x)
x2 = self.block2(x1)
x3 = self.block3(x2)
x4 = self.block4(x3)
# 这里在逐步下采样过程中,生成的'x2'、'x3'、'x4',后面范围-方位角RA解码器会用到
features['x0'] = x
features['x1'] = x1
features['x2'] = x2
features['x3'] = x3
features['x4'] = x4
return features这里在逐步下采样过程中,生成的'x2'、'x3'、'x4',后面范围-方位角RA解码器会用到
5、范围-方位角编码器
范围-方位角编码器,RA解码器,从特征金字塔中输出的三个分支特征图,构建一个范围-方位角的潜在表示。
这一步骤通过模型学习,将RD数据转换成RA数据,更适合对象定位和空间分割任务。
这里建议看源码来理解,更为直接;感觉论文这里讲的有些牵强。
- 从FPN中得到了:逐步下采样过程中,生成的'x2'、'x3'、'x4'。对应FPN的下采样部分,金字塔结构。
- RA解码器,是做一个逐步上采样的过程,对应FPN的上采样部分,倒金字塔结构。
- 'x2'、'x3'、'x4'特征调整通道与宽度维度顺序,得到T2、T3、T4。
- 上采样T4,然后与T3拼接在一起,再经过卷积,得到S4。
- 上采样S4,然后与T2拼接在一起,再经过卷积,得到最终输出out
- 输出out表示范围-方位角信息。
class RangeAngle_Decoder(nn.Module):
def __init__(self, ):
super(RangeAngle_Decoder, self).__init__()
# 创建了上采样层(deconv4 和 deconv3)和卷积块(conv_block4 和 conv_block3)。
# 上采样层使用转置卷积(ConvTranspose2d)来增加特征映射的空间分辨率。
self.deconv4 = nn.ConvTranspose2d(16, 16, kernel_size=3, stride=(2,1), padding=1, output_padding=(1,0))
self.conv_block4 = BasicBlock(48,128)
self.deconv3 = nn.ConvTranspose2d(128, 128, kernel_size=3, stride=(2,1), padding=1, output_padding=(1,0))
self.conv_block3 = BasicBlock(192,256)
# L3 和 L2 是1x1卷积层,用于调整通道维度。
self.L3 = nn.Conv2d(192, 224, kernel_size=1, stride=1,padding=0)
self.L2 = nn.Conv2d(160, 224, kernel_size=1, stride=1,padding=0)
# 定义RA解码器的计算过程
def forward(self,features):
# 'x4'、'x3'、'x2'来自PFN的多分支输出,而且是下采样过程产生的
T4 = features['x4'].transpose(1, 3)
T3 = self.L3(features['x3']).transpose(1, 3)
T2 = self.L2(features['x2']).transpose(1, 3)
# 上采样T4,然后与T3拼接在一起,再经过卷积
S4 = torch.cat((self.deconv4(T4),T3),axis=1)
S4 = self.conv_block4(S4)
# 上采样S4,然后与T2拼接在一起,再经过卷积,得到最终输出out
S43 = torch.cat((self.deconv3(S4),T2),axis=1)
out = self.conv_block3(S43)
return out6、任务头1——检测任务
检测任务,主要用来检测车辆。
- 输入:范围-方位角(RA)潜在表示。
- 数据首先经过几层卷积层进行初步处理,这些层用来提取和增强特征。
- 卷积处理:使用四个连续的Conv-BatchNorm层来处理这些特征,这些层分别有144、96、96和96个滤波器。
分类部分:
- 用来判断每个像素点是否代表车辆。这是一个二分类问题:每个像素点要么被分类为“车辆”,要么被分类为“非车辆”。
- 输出是一个概率图,表示每个像素点是车辆的概率。
- 使用带有Sigmoid激活函数的卷积层来预测概率图,这个输出对应于将每个“像素”二分类为是否被车辆占据。
- 为了降低计算复杂度,它预测一个粗糙的RA映射,其中每个单元的分辨率为0.8米(范围)和0.8度(方位角),这是原始分辨率的1/4和1/8。
回归部分:
- 精确预测检测到的对象对应的范围和方位角值。
- 输出是每个检测到的车辆的范围和方位角的具体数值
- 使用一个3x3卷积层输出两个特征图,分别对应于最终的范围和方位角值。
7、任务头2——分割任务
分割任务,主要用来预测可行驶区域的。
- 分割任务被定义为一个像素级的二分类问题。目的是确定每个像素点是否为可驾驶区域。
- 分割掩膜(mask)的分辨率为0.4米(范围)和0.2度(方位角)。
- 这相当于原始范围和方位角分辨率的一半,同时只考虑了整个方位角视场的一半(-45度到45度)。
卷积处理:
- 范围-方位角(RA)潜在表示经过两组连续的Conv-BatchNorm-ReLU块进行处理,分别产生128和64个特征映射。
最终卷积输出:
- 最终卷积输出,使用一个1x1卷积层输出一个2D特征映射,然后通过Sigmoid激活函数来估计每个位置是可驾驶区域的概率。
8、损失函数
检测任务——损失函数设计:
- 该检测头部使用多任务损失进行训练,包括对所有位置应用的聚焦损失(focal loss)进行分类
- 以及仅对正检测应用的平滑L1损失(smooth L1 loss)进行回归
分割任务——损失函数设计:
- 分割任务使用二元交叉熵损失(Binary Cross Entropy loss)进行学习。
模型整体的损失如下公式所示:

9、实验测试与模型效果
论文提出了RADIal数据集,
- 它是一个收集了 2 小时车辆行驶数据的数据集,采集场景包括:城市街道、高速公路和乡村道路。
- 采集设备包括:摄像头、激光雷达和高清雷达等,并且还包括了车辆的 GPS 位置和行驶信息。
- 总共有 91 个视频序列,每个视频时长从 1 分钟到 4 分钟不等,加起来一共是 2 小时。这些视频详细记录了车辆在不同地点和环境下的行驶情况。
- 在大约 25,000 个录制的画面中,有 8,252 个画面被用来标记了 9,550 辆车。
公开可用的带雷达的驾驶数据集,如下表所示:
?
数据集规模被定义为“小”是指<15k 帧、“大”是指>130k 帧、“中等”是介于两者之间。
雷达分为低清晰度‘LD’、高清晰度‘HD’或扫描型‘S’,其数据以不同的表示形式发布,涉及不同的信号处理流程:
- 模拟至数字转换器‘ADC’信号
- 距离-方位-多普勒‘RAD’张量
- 距离-方位‘RA’视图
- 距离-多普勒‘RD’视图、点云‘PC’
多普勒信息的存在取决于雷达传感器。其他传感器模态包括相机‘C’、激光雷达‘L’和里程计‘O’。
RADIal 是唯一提供高清雷达的每种表示形式,并结合相机、激光雷达和里程计的数据集,同时在论文中提出检测和自由空间分割任务。
详细信息看我这篇博客:4D毫米波雷达——RADIal数据集、格式、可视化 CVPR2022_4d毫米波雷达数据-CSDN博客
?
在 RADIal 测试分割上的对象检测性能
- 比较了使用点云(‘PC’)或范围-方位(‘RA’)表示训练的 Pixor,以及仅需要范围-多普勒(‘RD’)作为输入的提出的 FFT-RadNet。
- FFT-RadNet方法在平均精度(‘AP’)和平均召回率(‘AR’)上获得了与基准相似或更好的整体性能,用于50%的交并比(IoU)阈值。
- 它还达到了相似或更好的范围(‘R’)和角度(‘A’)精度,表明它成功地学习了一个信号处理流程,能够以显著更少的操作估计到达角(AoA)。


?
?FFT-RadNet被设计用来摆脱将模数转换(ADC)数据转换为稀疏点云或更密集表示(RA或RAD)的信号处理链,同时不损害信号的丰富性。
由于输入数据仍然相当大,作者设计了一个紧凑的模型来限制操作数量方面的复杂性,作为性能和范围/角度精度之间的一种权衡。预编码器层显著压缩了输入数据。

多输入多输出(MIMO)雷达系统,可以通过对雷达信号的复杂处理来估计方位角和仰角。
这通常需要额外的信号处理步骤,比如利用不同雷达天线之间的相位差异来估计到达角(AoA)。
- 如上表所示,FFT-RadNet是唯一不需要到达角(AoA)估计的方法。
- 预编码器目标是处理和压缩MIMO(多输入多输出)雷达系统产生的复杂信号,同时保留足够的信息以便后续能够恢复重要的参数,如方位角和仰角
- 在MIMO雷达系统中,尽管输入的主要是RD信息,但通过复杂的信号处理方法,系统能够从这些数据中提取出方位角和仰角等重要空间信息。
- 预编码器层在这个过程中起着关键作用,它对原始信号进行了有效的预处理,为准确估计角度信息奠定了基础。
如上表所示:?
- 点云方法的AoA为稀疏云生成了大约1000点的3D坐标,平均而言,这导致了大约8 GFLOPS的计算量,然后才能应用Pixor进行对象检测。
- 为了产生RA或RAD张量,AoA对RD图的每个单独bin进行运行,但只考虑一个仰角。因此,这样的模型无法估计像桥梁或丢失货物(低物体)等物体的仰角。
- 对于一个仰角,复杂度大约是45 GFLOPS,但对于所有11个仰角,复杂度可能增加到495 GFLOPS。
- 作者已经证明FFT-RadNet可以在不损害估计质量的情况下削减这些处理成本。
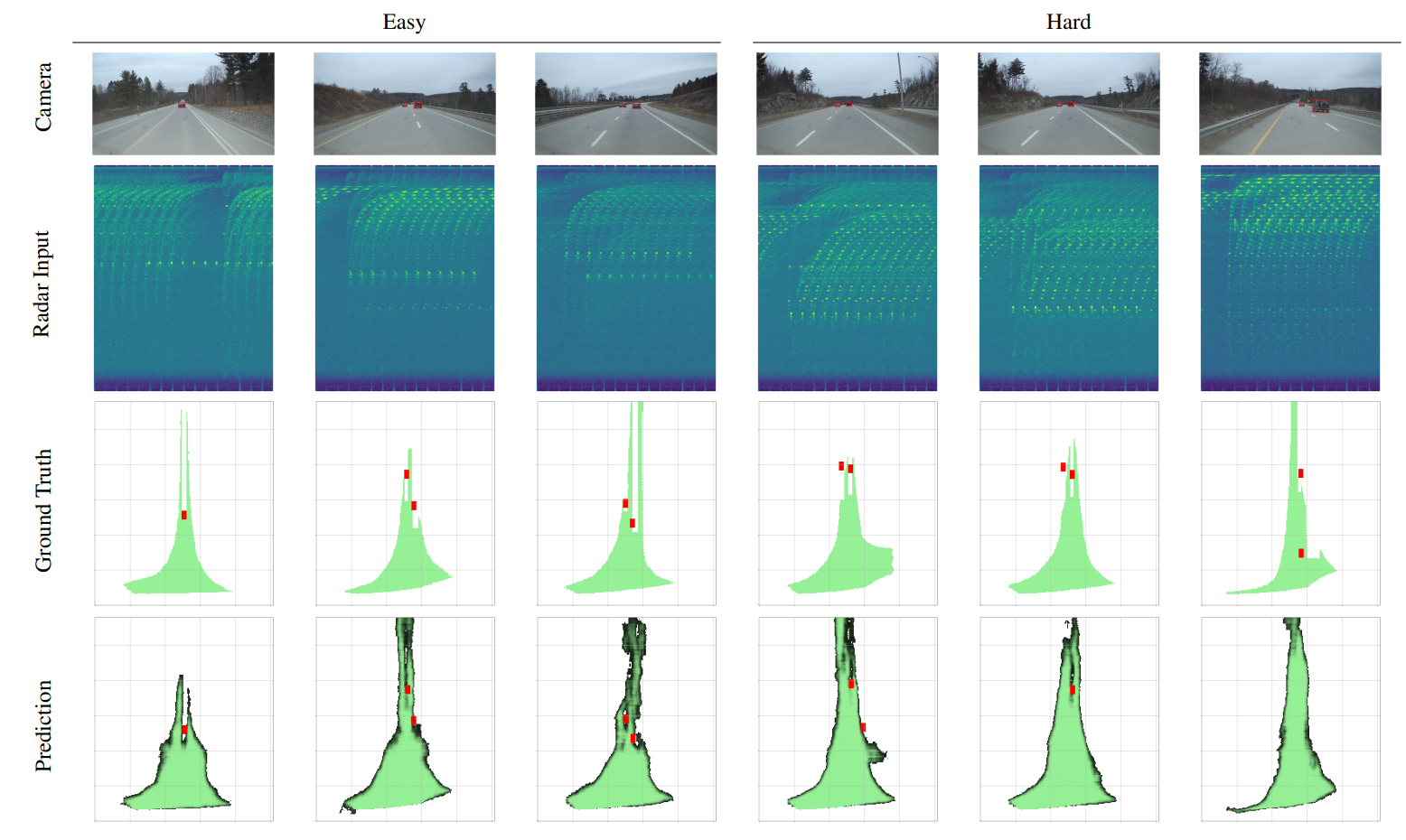
在简单样本和困难样本上,进行车辆检测和可行使区域分割分析
- 第一行:展示了摄像机视图。
- 第二行:范围-多普勒(RD)频谱是模型的唯一输入。
- 第三行:两项任务的真值。
- 第四行:预测结果。
- 需要注意,由于车辆俯仰变化,从摄像机到真实世界的自由驾驶空间可能存在投影误差。
本文先介绍到这里,后面会分享4D毫米波雷达的其它数据集、算法、代码、具体应用示例。
对于4D毫米波雷达的原理、对比、优势、行业现状,可以参考我这篇博客。
对于4D毫米波雷达——RADIal数据集、格式、可视化 CVPR2022,可以参考我这篇博客。
分享完成,本文只供大家参考与学习,谢谢~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用MATLAB连接USRP
- 【.NET后端工具系列】MediatR实现进程内消息通讯
- 2024 软件测试面试题(800道)【附带答案】持续更新...
- 度限制最小生成树和第K最短路算法
- Java版直播商城免 费 搭 建:平台规划与常见营销模式,电商源码、小程序、三级分销及详解
- 【玩转 TableAgent 数据智能分析】股票交易数据分析+预测
- computed 和 watch 的奇妙世界:让数据驱动你的 Vue 应用(上)
- 大型语言模型:SBERT — Sentence-BERT
- 【Python机器学习系列】建立随机森林模型预测心脏疾病(完整实现过程)
- C语言实现:判断回文数